Gerenciar o tráfego para o banco de dados pode ficar cada vez mais difícil à medida que aumenta em quantidade e o banco de dados é realmente distribuído em vários servidores. Os clientes PostgreSQL geralmente conversam com um único endpoint. Quando um nó primário falha, os clientes de banco de dados continuarão tentando novamente o mesmo IP. Caso você tenha feito failover para um nó secundário, o aplicativo precisa ser atualizado com o novo endpoint. É aqui que você deseja colocar um balanceador de carga entre os aplicativos e as instâncias de banco de dados. Ele pode direcionar aplicativos para nós de banco de dados disponíveis/íntegros e fazer failover quando necessário. Outro benefício seria aumentar o desempenho de leitura usando réplicas de forma eficaz. É possível criar uma porta somente leitura que equilibre as leituras entre as réplicas. Neste blog, abordaremos o HAProxy. Veremos o que é, como funciona e como implantá-lo no PostgreSQL.
O que é HAProxy?
O HAProxy é um proxy de código aberto que pode ser usado para implementar alta disponibilidade, balanceamento de carga e proxy para aplicativos baseados em TCP e HTTP.
Como balanceador de carga, o HAProxy distribui o tráfego de uma origem para um ou mais destinos e pode definir regras e/ou protocolos específicos para essa tarefa. Se algum dos destinos parar de responder, ele será marcado como off-line e o tráfego será enviado para o restante dos destinos disponíveis.
Como instalar e configurar o HAProxy manualmente
Para instalar o HAProxy no Linux, você pode usar os seguintes comandos:
No sistema operacional Ubuntu/Debian:
$ apt-get install haproxy -yNo sistema operacional CentOS/RedHat:
$ yum install haproxy -yE então precisamos editar o seguinte arquivo de configuração para gerenciar nossa configuração do HAProxy:
$ /etc/haproxy/haproxy.cfgConfigurar nosso HAProxy não é complicado, mas precisamos saber o que estamos fazendo. Temos vários parâmetros para configurar, dependendo de como queremos que o HAProxy funcione. Para mais informações, podemos seguir a documentação sobre a configuração do HAProxy.
Vejamos um exemplo de configuração básica. Suponha que você tenha a seguinte topologia de banco de dados:
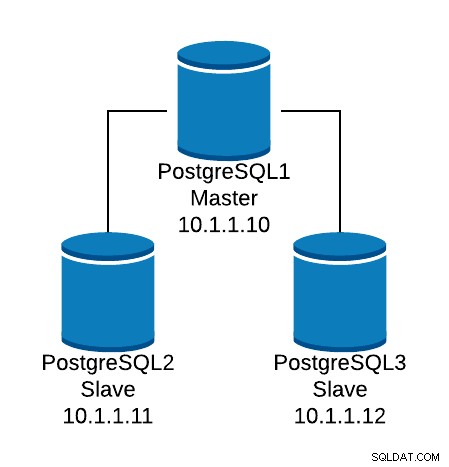 Exemplo de topologia de banco de dados
Exemplo de topologia de banco de dados Queremos criar um ouvinte HAProxy para equilibrar o tráfego de leitura entre os três nós.
listen haproxy_read
bind *:5434
balance roundrobin
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkComo mencionamos anteriormente, existem vários parâmetros para configurar aqui, e essa configuração depende do que queremos fazer. Por exemplo:
listen haproxy_read
bind *:5434
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running
balance leastconn
option tcp-check
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkComo o HAProxy funciona no ClusterControl
Para o PostgreSQL, o HAProxy é configurado pelo ClusterControl com duas portas diferentes por padrão, uma de leitura e gravação e outra somente leitura.
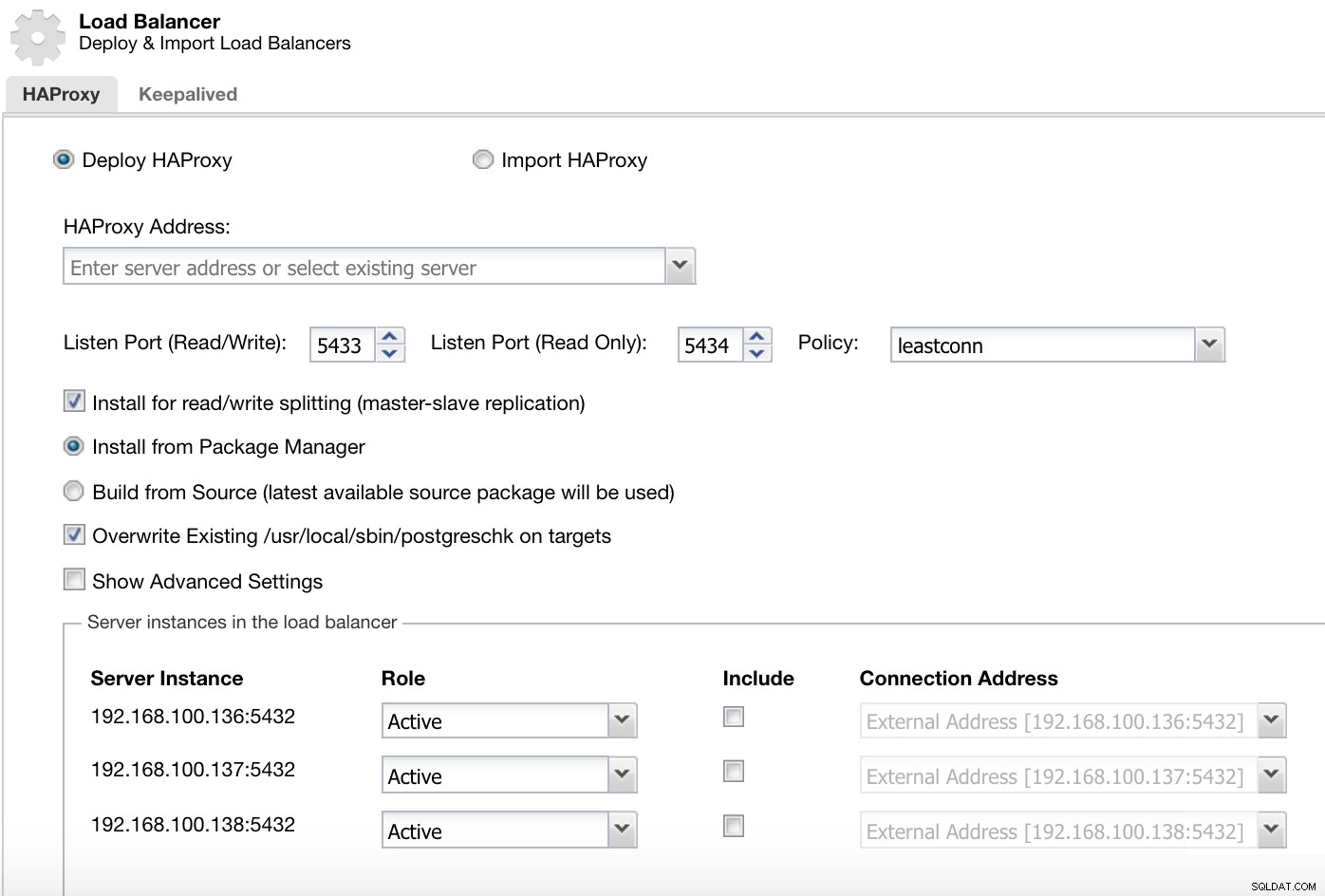 ClusterControl Load Balancer Deploy Information 1
ClusterControl Load Balancer Deploy Information 1 Em nossa porta de leitura e gravação, temos nosso servidor mestre como online e o restante de nossos nós como offline, e na porta somente leitura, temos o mestre e os escravos online.
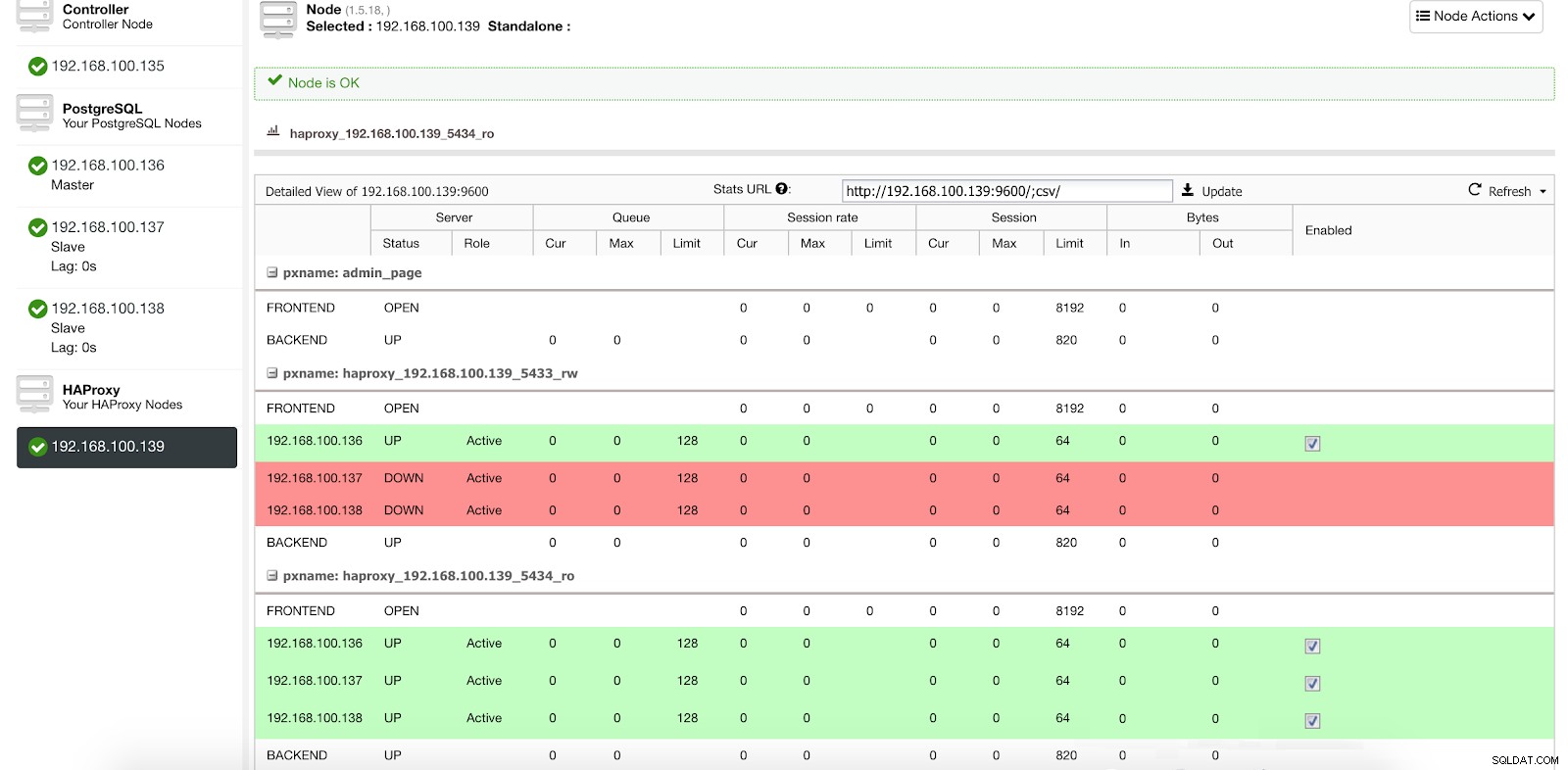 Estatísticas do balanceador de carga do ClusterControl 1
Estatísticas do balanceador de carga do ClusterControl 1 Quando o HAProxy detecta que um de nossos nós, mestre ou escravo, não está acessível, ele automaticamente o marca como offline e não o leva em consideração ao enviar o tráfego. A detecção é feita por scripts de verificação de integridade configurados pelo ClusterControl no momento da implantação. Eles verificam se as instâncias estão ativas, se estão em recuperação ou são somente leitura.
Quando o ClusterControl promove um slave para master, nosso HAProxy marca o master antigo como offline (para ambas as portas) e coloca o nó promovido online (na porta de leitura/gravação).
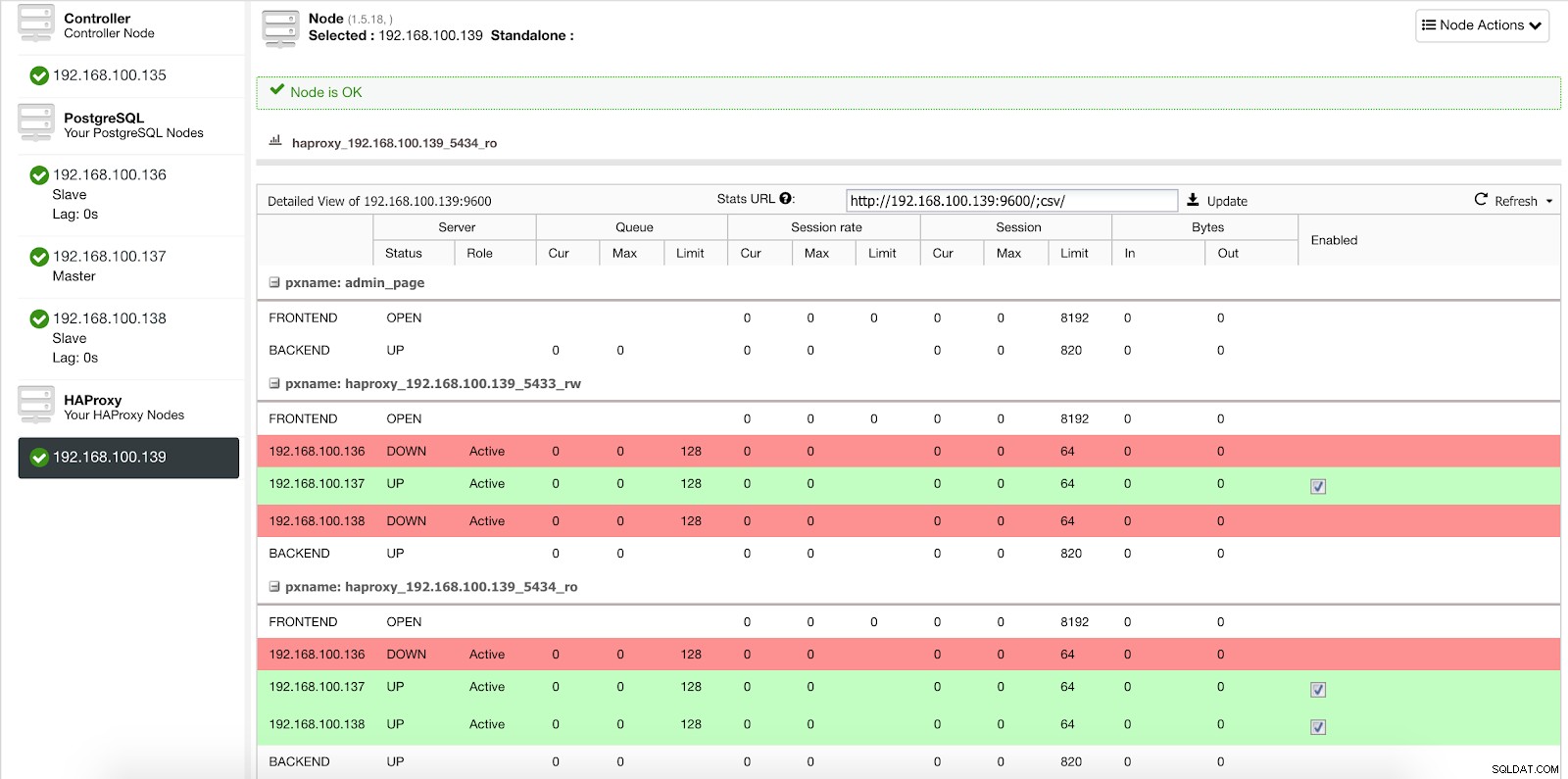 ClusterControl Load Balancer Stats 2
ClusterControl Load Balancer Stats 2 Desta forma, nossos sistemas continuam operando normalmente e sem nossa intervenção.
Como implantar o HAProxy com ClusterControl
Em nosso exemplo, criamos um ambiente com 1 master e 2 slaves - veja uma captura de tela da Topology View no ClusterControl. Agora adicionaremos nosso balanceador de carga HAProxy.
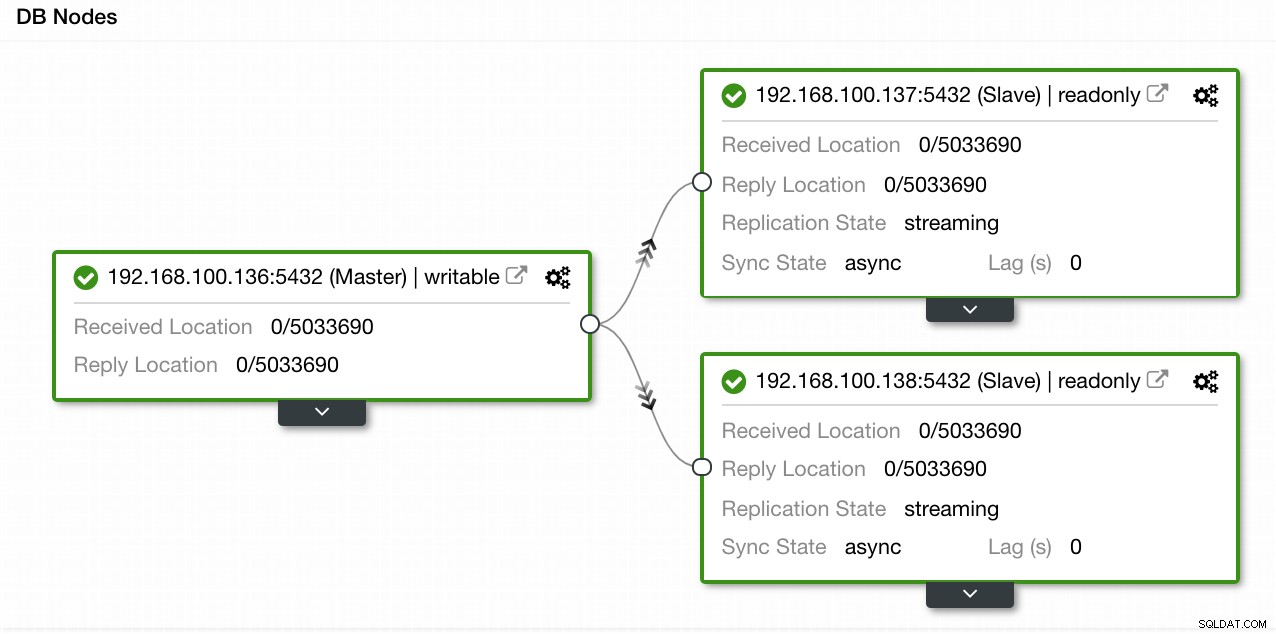 Visualização de topologia de controle de cluster 1
Visualização de topologia de controle de cluster 1 Para esta tarefa, precisamos ir para ClusterControl -> PostgreSQL Cluster Actions -> Add Load Balancer
 Menu de ações do cluster ClusterControl
Menu de ações do cluster ClusterControl Aqui devemos adicionar as informações que o ClusterControl usará para instalar e configurar nosso balanceador de carga HAProxy.
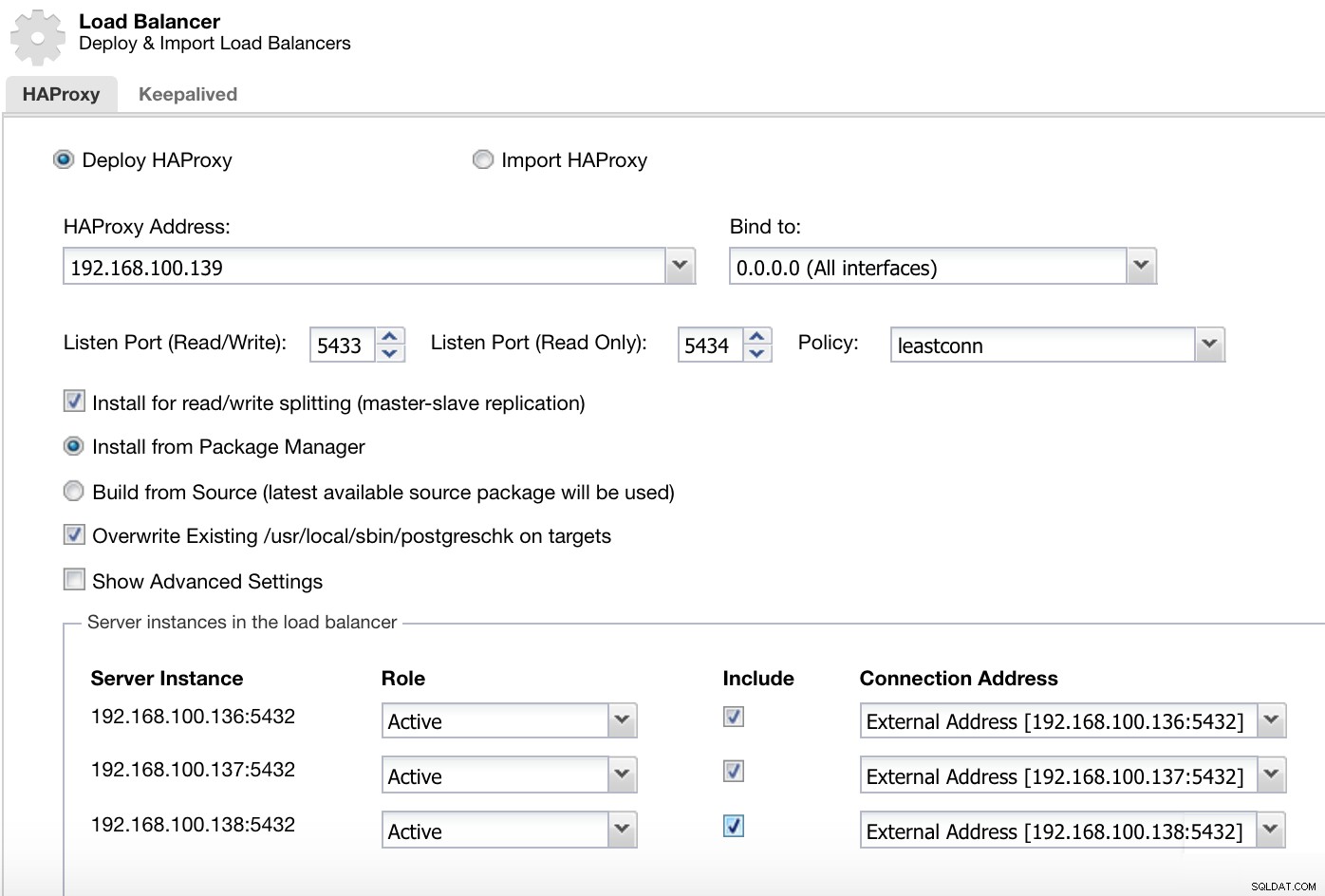 ClusterControl Load Balancer Deploy Information 2
ClusterControl Load Balancer Deploy Information 2 As informações que precisamos apresentar são:
Ação:Implemente ou Importe.
Endereço HAProxy:Endereço IP do nosso servidor HAProxy.
Vincular a:Interface ou endereço IP onde o HAProxy escutará.
Porta de escuta (leitura/gravação):Porta para modo de leitura/gravação.
Porta de escuta (somente leitura):Porta para modo somente leitura.
Política:Pode ser:
- leastconn:o servidor com o menor número de conexões recebe a conexão.
- roundrobin:cada servidor é usado em turnos, de acordo com seus pesos.
- origem:o endereço IP de origem é codificado e dividido pelo peso total dos servidores em execução para designar qual servidor receberá a solicitação.
Instalar para divisão de leitura/gravação:para replicação mestre-escravo.
Fonte:Podemos escolher Instalar a partir de um gerenciador de pacotes ou compilar a partir da fonte.
Substitua o postgreschk existente nos destinos.
E precisamos selecionar quais servidores você deseja adicionar à configuração do HAProxy e algumas informações adicionais como:
Função:Pode ser Ativo ou Backup.
Incluir:Sim ou Não.
Informações de endereço de conexão.
Além disso, podemos definir configurações avançadas como usuário administrador, nome de back-end, tempos limite e muito mais.
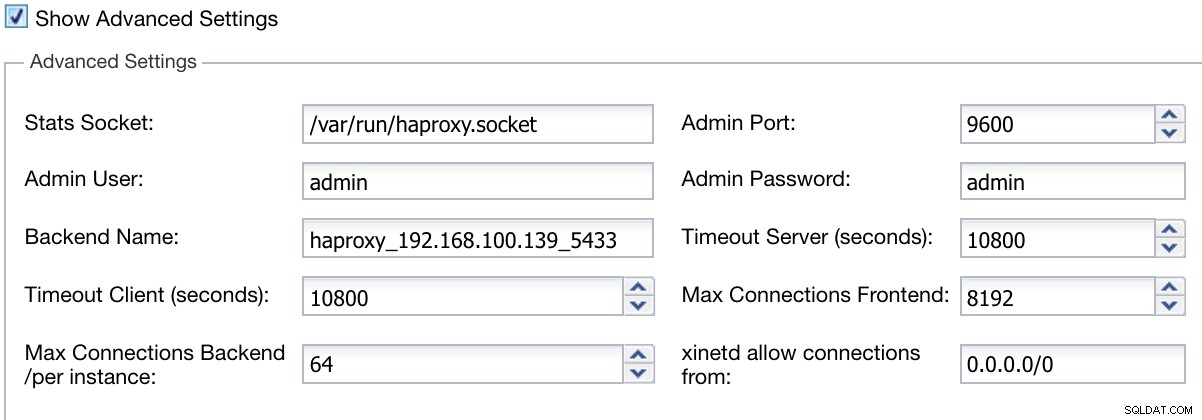 Informações de implantação do balanceador de carga ClusterControl Avançadas
Informações de implantação do balanceador de carga ClusterControl Avançadas Ao concluir a configuração e confirmar a implantação, podemos acompanhar o progresso na seção Atividade na interface do usuário do ClusterControl.
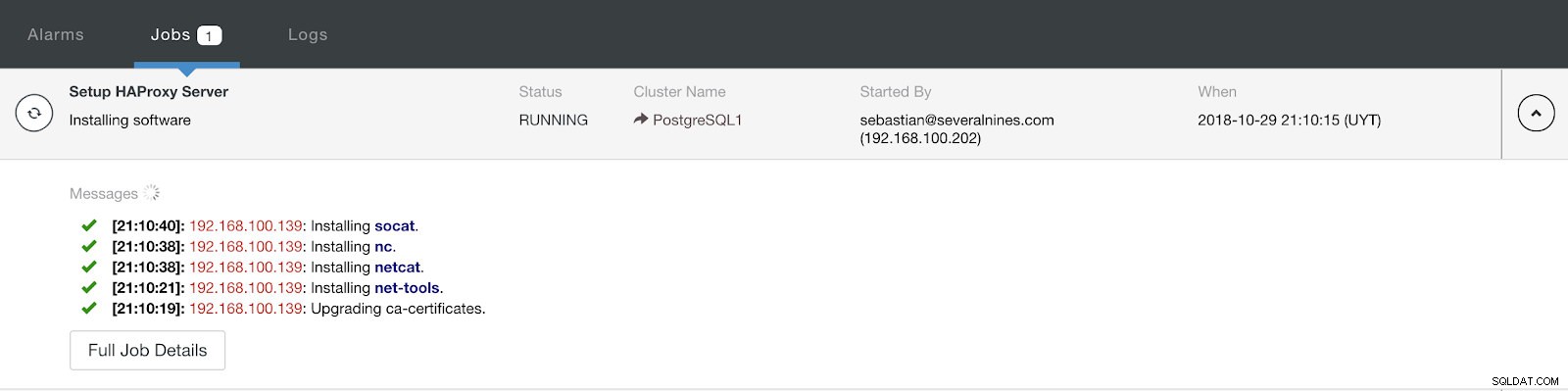 Seção de atividade de controle de cluster
Seção de atividade de controle de cluster Quando terminar, devemos ter a seguinte topologia:
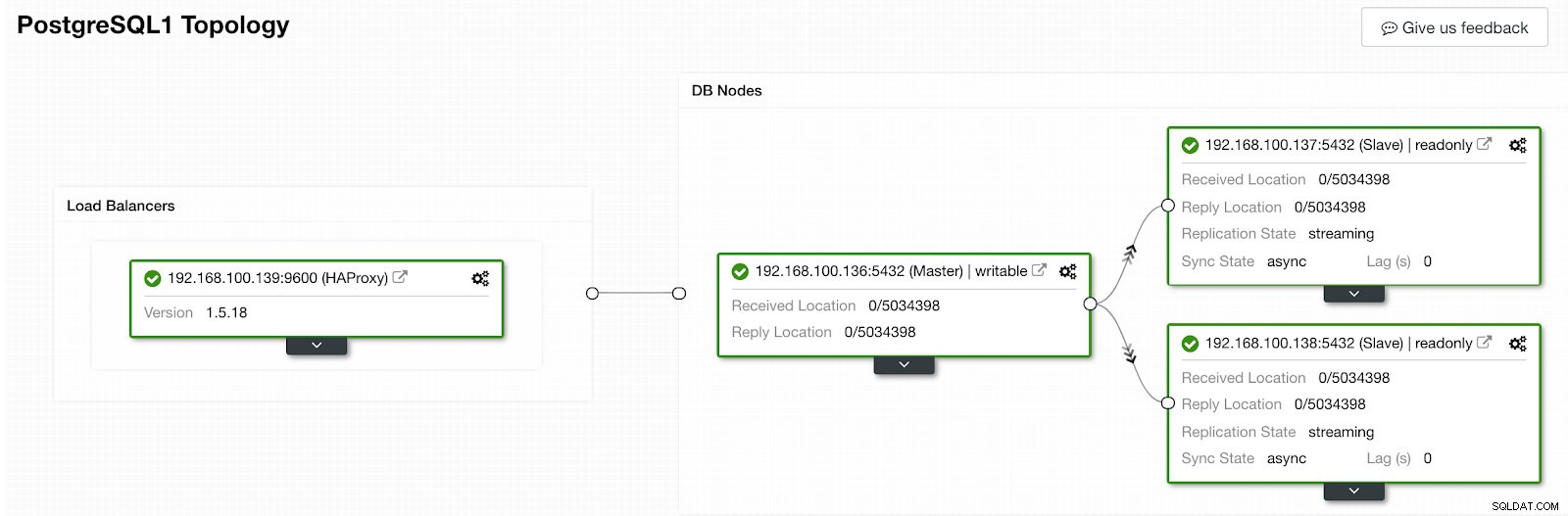 Visualização de topologia de ClusterControl 2
Visualização de topologia de ClusterControl 2 Podemos melhorar nosso design de HA adicionando um novo nó HAProxy e configurando o serviço Keepalived entre eles. Tudo isso pode ser feito pelo ClusterControl. Para mais informações, você pode conferir nosso blog anterior sobre PostgreSQL e HA.
Usando a CLI do ClusterControl para adicionar um balanceador de carga HAProxy
Também conhecido como s9s-tools, este pacote opcional foi introduzido no ClusterControl versão 1.4.1, que contém um binário chamado s9s. É uma ferramenta de linha de comando para interagir, controlar e gerenciar sua infraestrutura de banco de dados usando o ClusterControl. O projeto de linha de comando s9s é de código aberto e pode ser encontrado no GitHub.
A partir da versão 1.4.1, o script do instalador instalará automaticamente o pacote (s9s-tools) no nó ClusterControl.
ClusterControl CLI abre uma nova porta para automação de cluster, onde você pode integrá-lo facilmente com ferramentas de automação de implantação existentes, como Ansible, Puppet, Chef ou Salt.
Vejamos um exemplo de como criar um balanceador de carga HAProxy com o endereço IP 192.168.100.142 no cluster ID 1:
[example@sqldat.com ~]# s9s cluster --add-node --cluster-id=1 --nodes="haproxy://192.168.100.142" --wait
Add HaProxy to Cluster
/ Job 7 FINISHED [██████████] 100% Job finished.E então podemos verificar todos os nossos nós na linha de comando:
[example@sqldat.com ~]# s9s node --cluster-id=1 --list --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PostgreSQL1 192.168.100.135 9500 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.136 5432 Up and running.
poM- 10.5 1 PostgreSQL1 192.168.100.137 5432 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.138 5432 Up and running.
ho-- 1.5.18 1 PostgreSQL1 192.168.100.142 9600 Process 'haproxy' is running.
Total: 5Para mais informações sobre o s9s e como usá-lo, você pode verificar a documentação oficial ou este blog sobre este tópico.
Conclusão
Neste blog, analisamos como o HAProxy pode nos ajudar a gerenciar o tráfego proveniente do aplicativo em nosso banco de dados PostgreSQL. Verificamos como ele pode ser implantado e configurado manualmente e, em seguida, vimos como ele pode ser automatizado com o ClusterControl. Para evitar que o HAProxy se torne um ponto único de falha (SPOF), certifique-se de implantar pelo menos duas instâncias do HAProxy e implementar algo como Keepalived e IP virtual em cima delas.