O PostgreSQL, também conhecido como o banco de dados de código aberto mais avançado do mundo, tem uma nova versão de lançamento desde o último dia 24 de setembro de 2020, e agora está maduro, podemos conferir o que há de novo lá para começar a pensar em um plano de migração. O PostgreSQL 13 está disponível com muitos novos recursos e aprimoramentos. Neste blog, mencionaremos alguns desses novos recursos e veremos como implantar ou atualizar sua versão atual do PostgreSQL.
Novos recursos e melhorias do PostgreSQL 13
Vamos começar mencionando alguns dos novos recursos e melhorias desta versão do PostgreSQL 13 que você pode ver na Documentação Oficial.
Particionamento
-
Permitir que a remoção de partições e junções de partição ocorram em mais casos
-
Suporte a gatilhos de nível de linha ANTES em tabelas particionadas
-
Permitir que tabelas particionadas sejam replicadas logicamente por meio de publicação
-
Permitir replicação lógica em tabelas particionadas em assinantes
-
Permitir que variáveis de linha inteira sejam usadas em expressões de particionamento
Índices
-
Armazene duplicatas com mais eficiência em índices de árvore B
-
Permitir que os índices GiST e SP-GiST nas colunas de caixa suportem consultas de ponto ORDER BY <->
-
Permitir que os índices GIN manipulem ! (NOT) cláusulas em pesquisas tsquery
-
Permitir que classes de operadores de índice recebam parâmetros
Otimizador
-
Melhore a estimativa de seletividade do otimizador para operadores de contenção/correspondência
-
Permitir definir a meta de estatísticas para estatísticas estendidas
-
Permitir o uso de vários objetos de estatísticas estendidas em uma única consulta
-
Permitir o uso de objetos de estatísticas estendidas para cláusulas OR e listas de constantes IN/ANY
-
Permitir que funções em cláusulas FROM sejam puxadas (embutidas) se forem avaliadas como constantes
Desempenho
-
Implementar a classificação incremental e melhorar o desempenho da classificação de valores inet
-
Permitir que a agregação de hash use o armazenamento em disco para grandes conjuntos de resultados de agregação
-
Permitir que inserções, não apenas atualizações e exclusões, acionem a atividade de aspiração no autovacuum
-
Adicione o parâmetro maintenance_io_concurrency para controlar a simultaneidade de E/S para operações de manutenção
-
Permitir que as gravações WAL sejam ignoradas durante uma transação que cria ou reescreve uma relação, se wal_level for mínimo
-
Melhore o desempenho ao reproduzir comandos DROP DATABASE quando muitos tablespaces estão em uso
-
Acelerar as conversões de números inteiros para texto
-
Reduza o uso de memória para strings de consulta e scripts de extensão que contêm muitas instruções SQL
Monitoramento
-
Permitir que EXPLAIN, auto_explain, autovacuum e pg_stat_statements acompanhem as estatísticas de uso do WAL
-
Permitir que uma amostra de instruções SQL, em vez de todas as instruções, seja registrada
-
Adicione o tipo de back-end ao csvlog e, opcionalmente, log_line_prefix saída de log
-
Melhorar o controle do registro de parâmetro de instrução preparada
-
Adicione leader_pid a pg_stat_activity para relatar o processo de líder de um trabalhador paralelo
-
Adicione a visualização do sistema pg_stat_progress_basebackup para relatar o progresso dos backups de base de streaming
-
Adicione a visualização do sistema pg_stat_progress_analyze para relatar o progresso do ANALYZE
-
Adicione a visualização do sistema pg_shmem_allocations para exibir o uso de memória compartilhada
Replicação e recuperação
-
Permitir que as configurações de replicação de streaming sejam alteradas recarregando
-
Permitir que os receptores WAL usem um slot de replicação temporário quando um permanente não for especificado
-
Permitir que o armazenamento WAL para slots de replicação seja limitado por max_slot_wal_keep_size
-
Permitir que a promoção de espera cancele qualquer pausa solicitada
-
Gerar um erro se a recuperação não atingir o destino de recuperação especificado
-
Permitir o controle sobre quanta memória é usada pela decodificação lógica antes de ser derramada no disco
-
Permitir que a recuperação continue mesmo que páginas inválidas sejam referenciadas pelo WAL
Comandos de utilitário
-
Permitir que VACUUM processe os índices de uma tabela em paralelo
-
Relatar o uso de buffer de tempo de planejamento na saída BUFFER do EXPLAIN
-
Faça CREATE TABLE LIKE propagar a propriedade NO INHERIT de uma restrição CHECK para a tabela criada
-
Adicione ALTER TABLE ... DROP EXPRESSION para permitir a remoção da propriedade GENERATED de uma coluna
-
Adicione a sintaxe ALTER VIEW para renomear colunas de visualização
-
Adicionar opções ALTER TYPE para modificar as propriedades TOAST e funções de suporte de um tipo base
-
Adicionar opção CREATE DATABASE LOCALE
-
Permitir que DROP DATABASE desconecte sessões usando o banco de dados de destino, permitindo que o descarte seja bem-sucedido
E muitas outras mudanças. Acabamos de mencionar alguns deles para evitar uma postagem maior no blog. Agora, vamos ver como implantar esta nova versão.
Como implantar o PostgreSQL 13
Para isso, vamos supor que você tenha o ClusterControl instalado, caso contrário, você pode seguir a documentação correspondente para instalá-lo.
Para realizar uma implantação a partir do ClusterControl, basta selecionar a opção Deploy e seguir as instruções que aparecem.
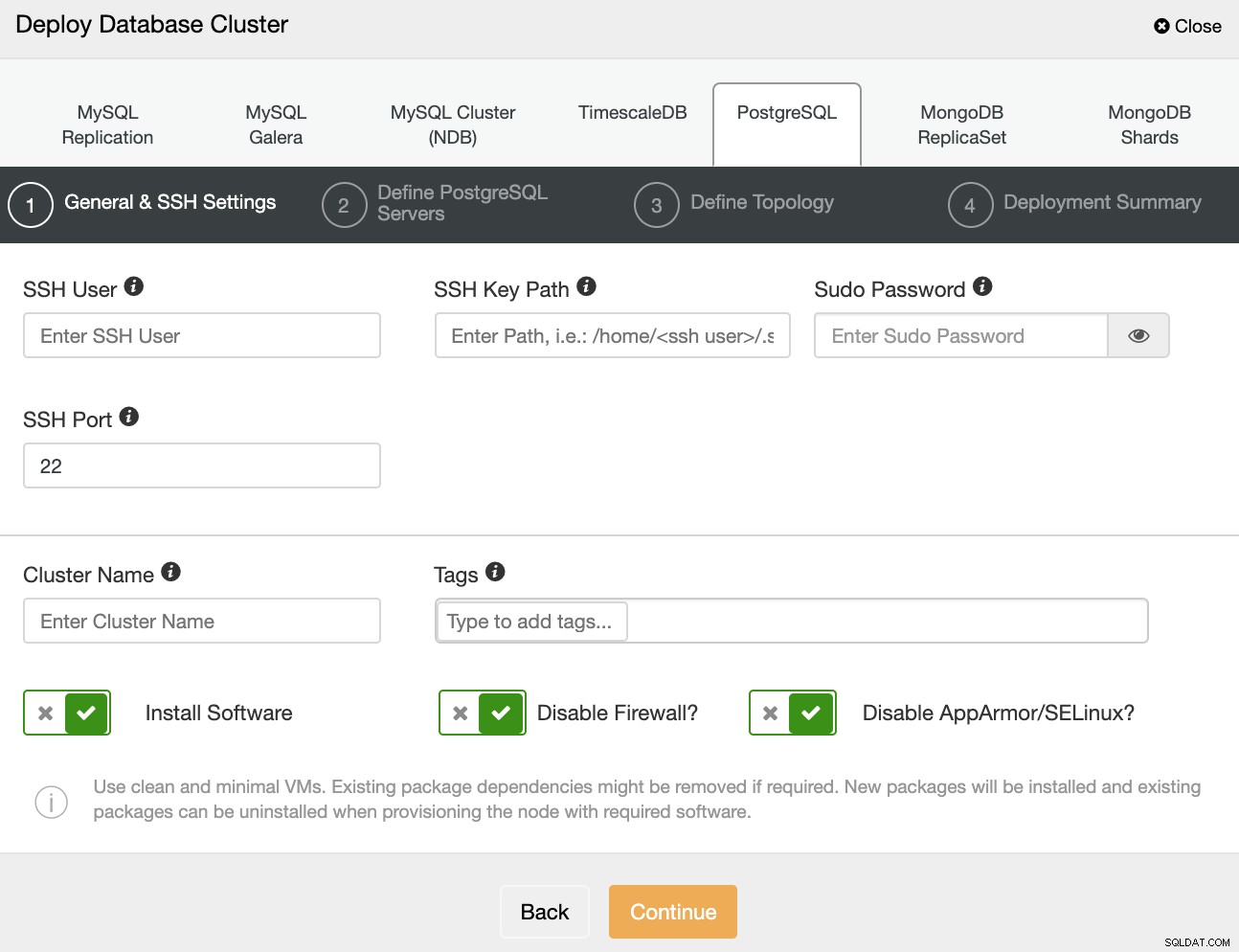
Ao selecionar PostgreSQL, você deve especificar Usuário, Chave ou Senha e Porta para se conectar por SSH aos seus servidores. Você também pode adicionar um nome para seu novo cluster e se desejar que o ClusterControl instale o software e as configurações correspondentes para você.
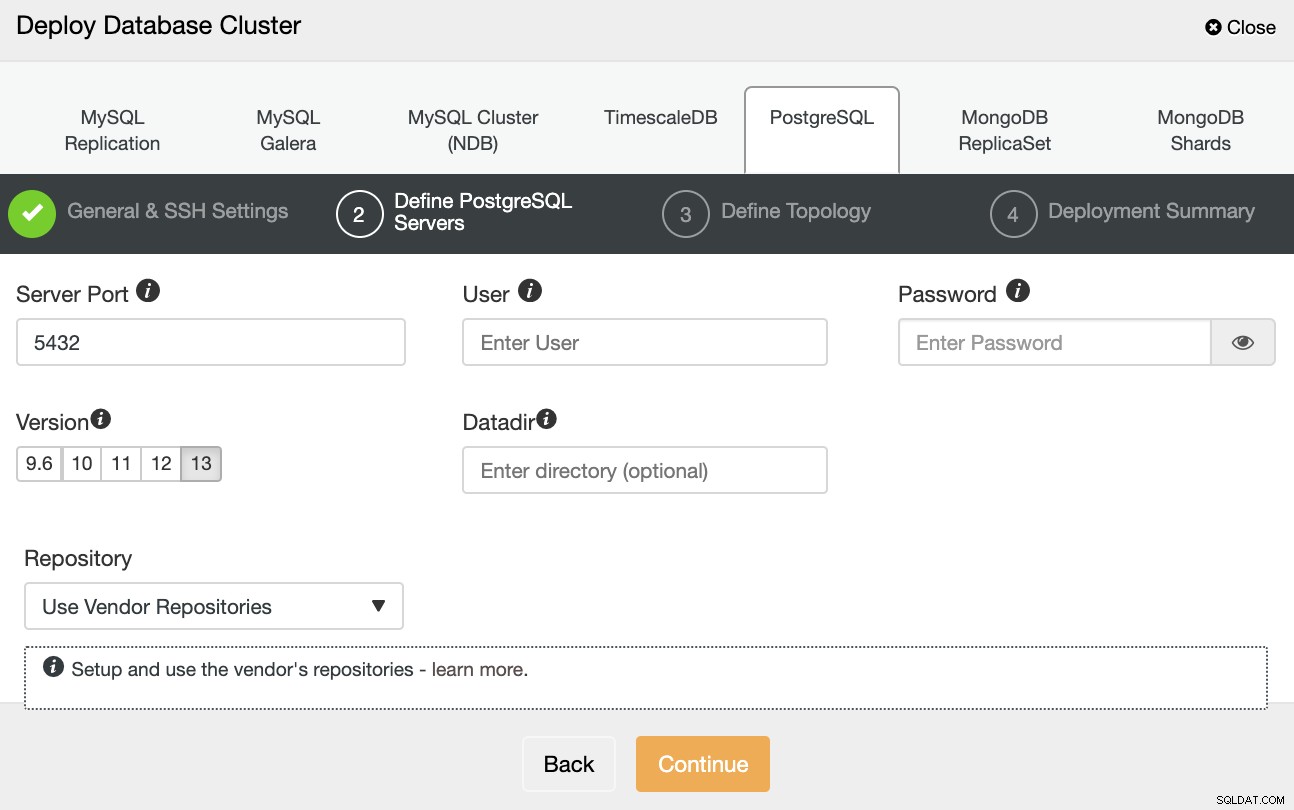
Depois de configurar as informações de acesso SSH, você precisa definir as credenciais do banco de dados , versão e datadir (opcional). Você também pode especificar qual repositório usar.
Na próxima etapa, você precisa adicionar seus servidores ao cluster que você criará usando o endereço IP ou o nome do host.
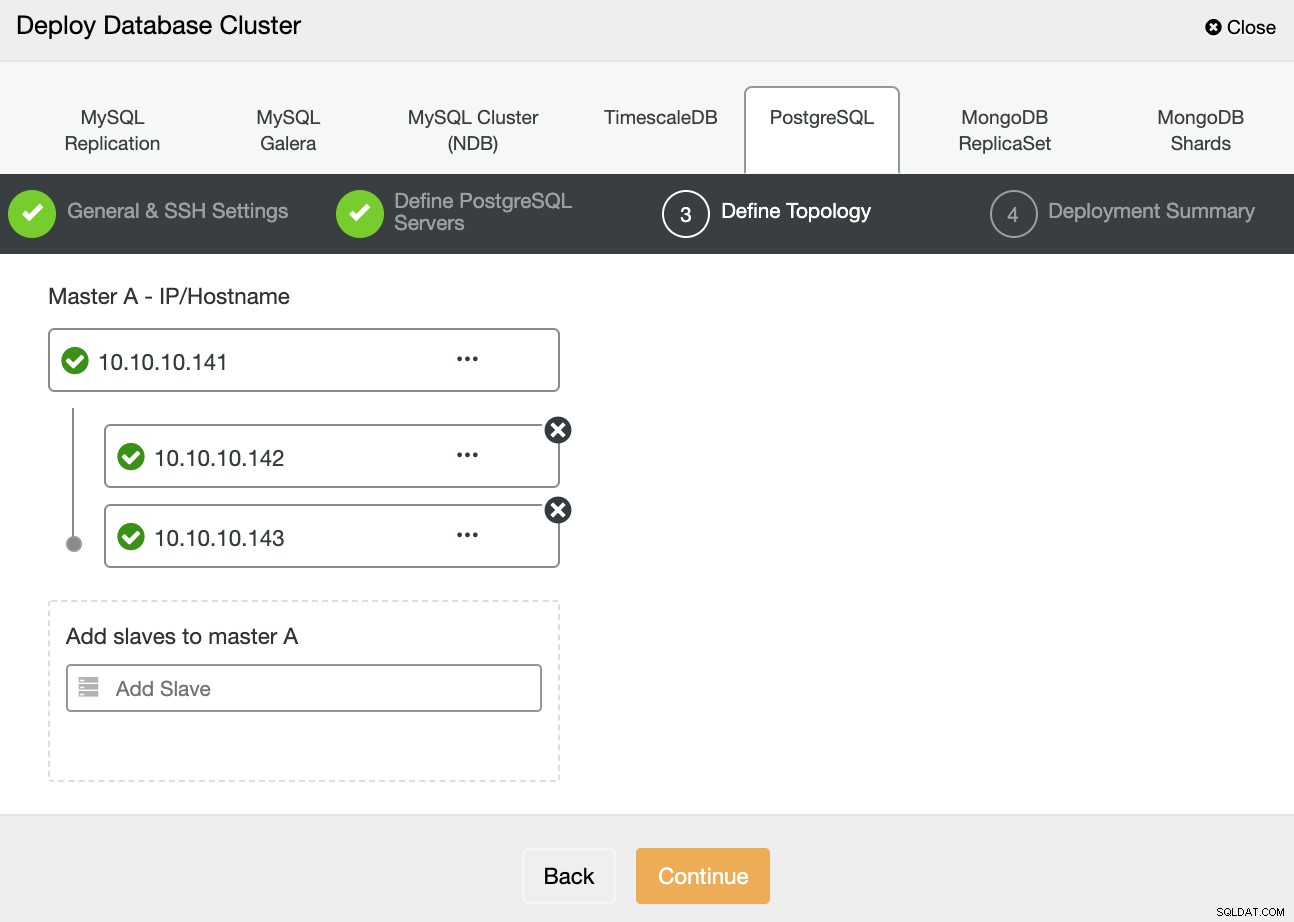
Na última etapa, você pode escolher se sua replicação será síncrona ou Assíncrono e, em seguida, basta pressionar Implantar.
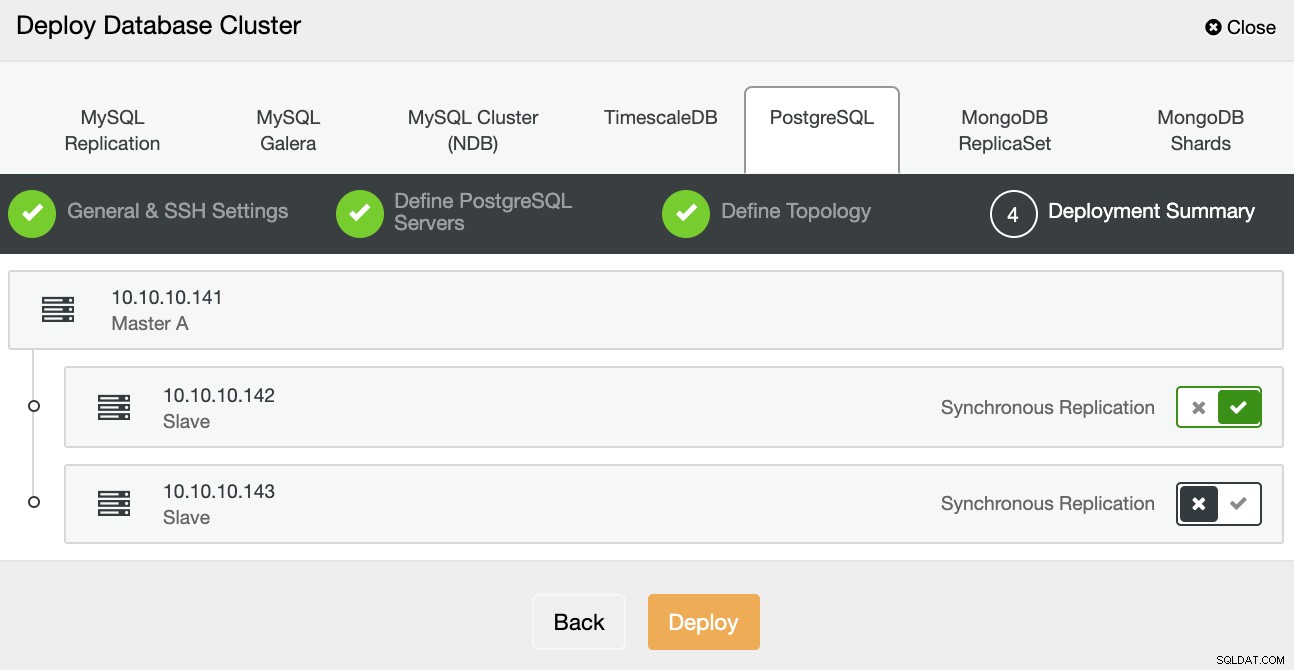
Quando a tarefa for concluída, você poderá ver seu novo cluster PostgreSQL no tela principal do ClusterControl.

Agora que você criou seu cluster, pode executar várias tarefas nele, como adicionar balanceadores de carga (HAProxy), pools de conexão (PgBouncer) ou novos escravos de replicação da mesma interface do usuário do ClusterControl.
Atualizando para o PostgreSQL 13
Se você deseja atualizar sua versão atual do PostgreSQL para esta nova, você tem três opções principais que realizarão esta tarefa.
-
Pg_dump:É uma ferramenta de backup lógico que permite despejar seus dados e restaurá-los no novo PostgreSQL versão. Aqui você terá um período de inatividade que irá variar de acordo com o tamanho dos seus dados. Você precisa parar o sistema ou evitar novos dados no nó primário, executar o pg_dump, mover o dump gerado para o novo nó do banco de dados e restaurá-lo. Durante esse tempo, você não pode escrever em seu banco de dados PostgreSQL primário para evitar inconsistência de dados.
-
Pg_upgrade:É uma ferramenta do PostgreSQL para atualizar sua versão do PostgreSQL no local. Pode ser perigoso em um ambiente de produção e não recomendamos esse método nesse caso. Usando este método, você também terá tempo de inatividade, mas provavelmente será consideravelmente menor do que usando o método pg_dump anterior.
-
Replicação lógica:desde o PostgreSQL 10, você pode usar este método de replicação que permite realizar atualizações de versão principais com tempo de inatividade zero (ou quase zero). Dessa forma, você pode adicionar um nó de espera na última versão do PostgreSQL e, quando a replicação estiver atualizada, poderá realizar um processo de failover para promover o novo nó do PostgreSQL.
Para informações mais detalhadas sobre os novos recursos do PostgreSQL 13, você pode consultar a Documentação Oficial.



