No meu blog anterior, discutimos várias maneiras de selecionar ou verificar dados de uma única tabela. Mas na prática, buscar dados de uma única tabela não é suficiente. Requer a seleção de dados de várias tabelas e, em seguida, a correlação entre elas. A correlação desses dados entre as tabelas é chamada de junção de tabelas e pode ser feita de várias maneiras. Como a junção de tabelas requer dados de entrada (por exemplo, da varredura da tabela), nunca pode ser um nó folha no plano gerado.
Ex. considere um exemplo de consulta simples como SELECT * FROM TBL1, TBL2 onde TBL1.ID> TBL2.ID; e suponha que o plano gerado seja o seguinte:
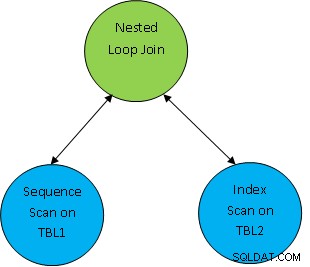
Aqui as duas primeiras tabelas são verificadas e, em seguida, unidas como pela condição de correlação como TBL.ID> TBL2.ID
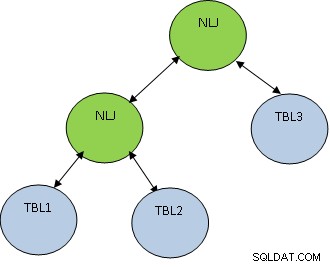
Além do método de junção, a ordem de junção também é muito importante. Considere o exemplo abaixo:
SELECT * DE TBL1, TBL2, TBL3 ONDE TBL1.ID=TBL2.ID E TBL2.ID=TBL3.ID;
Considere que TBL1, TBL2 E TBL3 possuem 10, 100 e 1000 registros respectivamente.
A condição TBL1.ID=TBL2.ID retorna apenas 5 registros, enquanto TBL2.ID=TBL3.ID retorna 100 registros, então é melhor juntar TBL1 e TBL2 primeiro para que um número menor de registros seja juntou-se ao TBL3. O plano será como mostrado abaixo:
O PostgreSQL suporta os seguintes tipos de junções:
- União de loop aninhado
- Juntar com hash
- Mesclar associação
Cada um desses métodos Join são igualmente úteis dependendo da consulta e de outros parâmetros, por exemplo, consulta, dados de tabela, cláusula de junção, seletividade, memória etc. Esses métodos de junção são implementados pela maioria dos bancos de dados relacionais.
Vamos criar uma tabela de pré-configuração e preenchê-la com alguns dados, que serão usados com frequência para explicar melhor esses métodos de verificação.
postgres=# create table blogtable1(id1 int, id2 int);
CREATE TABLE
postgres=# create table blogtable2(id1 int, id2 int);
CREATE TABLE
postgres=# insert into blogtable1 values(generate_series(1,10000),3);
INSERT 0 10000
postgres=# insert into blogtable2 values(generate_series(1,1000),3);
INSERT 0 1000
postgres=# analyze;
ANALYZEEm todos os nossos exemplos subsequentes, consideramos o parâmetro de configuração padrão, a menos que especificado de outra forma.
União de loop aninhado
Nested Loop Join (NLJ) é o algoritmo de junção mais simples em que cada registro da relação externa é correspondido com cada registro da relação interna. O Join entre a relação A e B com condição A.ID Nested Loop Join (NLJ) é o método de junção mais comum e pode ser usado em praticamente qualquer conjunto de dados com qualquer tipo de cláusula de junção. Como esse algoritmo varre todas as tuplas da relação interna e externa, é considerada a operação de junção mais cara. De acordo com a tabela e os dados acima, a consulta a seguir resultará em uma junção de loop aninhada conforme mostrado abaixo: Como a cláusula de junção é “<”, o único método de junção possível aqui é Junção de Loop Aninhado. Observe aqui um novo tipo de nó como Materialize; este nó atua como cache de resultado intermediário, ou seja, em vez de buscar todas as tuplas de uma relação várias vezes, o primeiro resultado buscado é armazenado na memória e na próxima solicitação para obter a tupla será servido da memória em vez de buscar novamente nas páginas de relação . No caso, se todas as tuplas não puderem caber na memória, as tuplas de transbordamento vão para um arquivo temporário. É principalmente útil no caso de Junção de Loop Aninhado e, até certo ponto, no caso de Junção de Mesclagem, pois eles dependem da nova varredura da relação interna. Materialize Node não se limita apenas a armazenar em cache o resultado da relação, mas pode armazenar em cache os resultados de qualquer nó abaixo na árvore de planos. DICA:Caso a cláusula de junção seja “=” e a junção de loop aninhado seja escolhida entre uma relação, então é realmente importante investigar se um método de junção mais eficiente, como hash ou junção de mesclagem, pode ser escolhido por ajuste de configuração (por exemplo, work_mem, mas não limitado a ) ou adicionando um índice, etc. Algumas das consultas podem não ter cláusula de junção, nesse caso também a única opção de junção é Junção de Loop Aninhado. Por exemplo. considere as consultas abaixo de acordo com os dados de pré-configuração: A junção no exemplo acima é apenas um produto cartesiano de ambas as tabelas. Este algoritmo funciona em duas fases: A junção entre a relação A e B com condição A.ID =B.ID pode ser representada como abaixo: De acordo com a tabela e os dados de pré-configuração acima, a consulta a seguir resultará em um Hash Join, conforme mostrado abaixo: Aqui a tabela de hash é criada na tabela blogtable2 porque é a tabela menor, portanto, a memória mínima necessária para a tabela de hash e toda a tabela de hash pode caber na memória. Merge Join é um algoritmo em que cada registro de relação externa é correspondido com cada registro de relação interna até que haja a possibilidade de correspondência de cláusula de junção. Este algoritmo de junção só é usado se ambas as relações estiverem ordenadas e o operador da cláusula de junção for “=”. A junção entre a relação A e B com condição A.ID =B.ID pode ser representada da seguinte forma: A consulta de exemplo que resultou em um Hash Join, como mostrado acima, pode resultar em um Merge Join se o índice for criado em ambas as tabelas. Isso ocorre porque os dados da tabela podem ser recuperados em ordem de classificação devido ao índice, que é um dos principais critérios para o método Merge Join: Assim, como vemos, ambas as tabelas estão usando varredura de índice em vez de varredura sequencial, pois ambas as tabelas emitirão registros classificados. O PostgreSQL suporta várias configurações relacionadas ao planejador, que podem ser usadas para sugerir ao otimizador de consulta que não selecione algum tipo particular de métodos de junção. Se o método de junção escolhido pelo otimizador não for o ideal, esses parâmetros de configuração podem ser desativados para forçar o otimizador de consulta a escolher um tipo diferente de métodos de junção. Todos esses parâmetros de configuração estão “ligados” por padrão. Abaixo estão os parâmetros de configuração do planejador específicos para os métodos de junção. Existem muitos parâmetros de configuração relacionados ao plano usados para vários propósitos. Neste blog, mantendo-o restrito apenas a métodos de junção. Esses parâmetros podem ser modificados a partir de uma sessão específica. Portanto, caso queiramos experimentar o plano de uma sessão específica, esses parâmetros de configuração podem ser manipulados e outras sessões continuarão funcionando como estão. Agora, considere os exemplos acima de junção de mesclagem e junção de hash. Sem um índice, o otimizador de consulta selecionou um Hash Join para a consulta abaixo, conforme mostrado abaixo, mas depois de usar a configuração, ele alterna para mesclar junção mesmo sem índice: Inicialmente, o Hash Join é escolhido porque os dados das tabelas não são classificados. Para escolher o plano de junção de mesclagem, ele precisa primeiro classificar todos os registros recuperados de ambas as tabelas e, em seguida, aplicar a junção de mesclagem. Assim, o custo de triagem será adicional e, portanto, o custo total aumentará. Então, possivelmente, neste caso, o custo total (incluindo o aumento) é maior que o custo total do Hash Join, então o Hash Join é escolhido. Uma vez que o parâmetro de configuração enable_hashjoin é alterado para “off”, isso significa que o otimizador de consulta atribui diretamente um custo para junção de hash como custo de desabilitação (=1.0e10, ou seja, 10000000000.00). O custo de qualquer junção possível será menor do que isso. Portanto, o mesmo resultado da consulta em Merge Join após enable_hashjoin ser alterado para “off”, pois mesmo incluindo o custo de classificação, o custo total da junção de mesclagem é menor que o custo de desabilitação. Agora considere o exemplo abaixo: Como podemos ver acima, mesmo que o parâmetro de configuração relacionado à junção de loop aninhado seja alterado para “off”, ele ainda escolhe Junção de Loop Aninhado, pois não há possibilidade alternativa de qualquer outro tipo de método de junção para obter selecionado. Em termos mais simples, como Nested Loop Join é a única junção possível, então, custe o que custar, será sempre o vencedor (o mesmo que eu costumava ser o vencedor na corrida de 100m se eu corresse sozinho…:-)). Além disso, observe a diferença de custo no primeiro e segundo plano. O primeiro plano mostra o custo real do Nested Loop Join, mas o segundo mostra o custo de desabilitação do mesmo. Todos os tipos de métodos de junção do PostgreSQL são úteis e são selecionados com base na natureza da consulta, dados, cláusula de junção, etc. selecionado conforme o esperado, o usuário pode brincar com os diferentes parâmetros de configuração do plano disponíveis e ver se algo está faltando. For each tuple r in A
For each tuple s in B
If (r.ID < s.ID)
Emit output tuple (r,s)
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 < bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (bt1.id1 < bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# explain select * from blogtable1, blogtable2;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..125162.50 rows=10000000 width=16)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(4 rows)
União de hash
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (bt1.id1 = bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
Mesclar junção
For each tuple r in A
For each tuple s in B
If (r.ID = s.ID)
Emit output tuple (r,s)
Break;
If (r.ID > s.ID)
Continue;
Else
Break;
postgres=# create index idx1 on blogtable1(id1);
CREATE INDEX
postgres=# create index idx2 on blogtable2(id1);
CREATE INDEX
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
---------------------------------------------------------------------------------------
Merge Join (cost=0.56..90.36 rows=1000 width=16)
Merge Cond: (bt1.id1 = bt2.id1)
-> Index Scan using idx1 on blogtable1 bt1 (cost=0.29..318.29 rows=10000 width=8)
-> Index Scan using idx2 on blogtable2 bt2 (cost=0.28..43.27 rows=1000 width=8)
(4 rows)
Configuração
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (blogtable1.id1 = blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_hashjoin to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
----------------------------------------------------------------------------
Merge Join (cost=874.21..894.21 rows=1000 width=16)
Merge Cond: (blogtable1.id1 = blogtable2.id1)
-> Sort (cost=809.39..834.39 rows=10000 width=8)
Sort Key: blogtable1.id1
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: blogtable2.id1
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(8 rows)
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_nestloop to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=10000000000.00..10000150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
Conclusão