O uso de replicação para seus bancos de dados PostgreSQL pode ser útil não apenas para ter um ambiente de alta disponibilidade e tolerante a falhas, mas também para melhorar o desempenho em seu sistema, equilibrando o tráfego entre os nós de espera. Nesta primeira parte do blog de duas partes, veremos alguns conceitos relacionados à replicação do PostgreSQL.
Métodos de replicação no PostgreSQL
Existem diferentes métodos para replicar dados no PostgreSQL, mas aqui vamos nos concentrar nos dois métodos principais:Replicação de Streaming e Replicação Lógica.
Replicação de streaming
PostgreSQL Streaming Replication, a Replicação PostgreSQL mais comum, é uma replicação física que replica as alterações em nível de byte a byte, criando uma cópia idêntica do banco de dados em outro servidor. É baseado no método de envio de logs. Os registros WAL são movidos diretamente de um servidor de banco de dados para outro para serem aplicados. Podemos dizer que é uma espécie de PITR contínuo.
Essa transferência WAL é realizada de duas maneiras diferentes, transferindo os registros WAL um arquivo (segmento WAL) de cada vez (transferência de log baseado em arquivo) e transferindo registros WAL (um arquivo WAL é composto de registros WAL) em tempo real (envio de log baseado em registro), entre um servidor primário e um ou mais servidores em espera, sem esperar que o arquivo WAL seja preenchido.
Na prática, um processo chamado receptor WAL, executado no servidor em espera, se conectará ao servidor primário usando uma conexão TCP/IP. No servidor primário, existe outro processo, denominado WAL remetente, e é responsável por enviar os registros WAL ao servidor em espera à medida que ocorrem.
Uma replicação de streaming básica pode ser representada da seguinte forma:
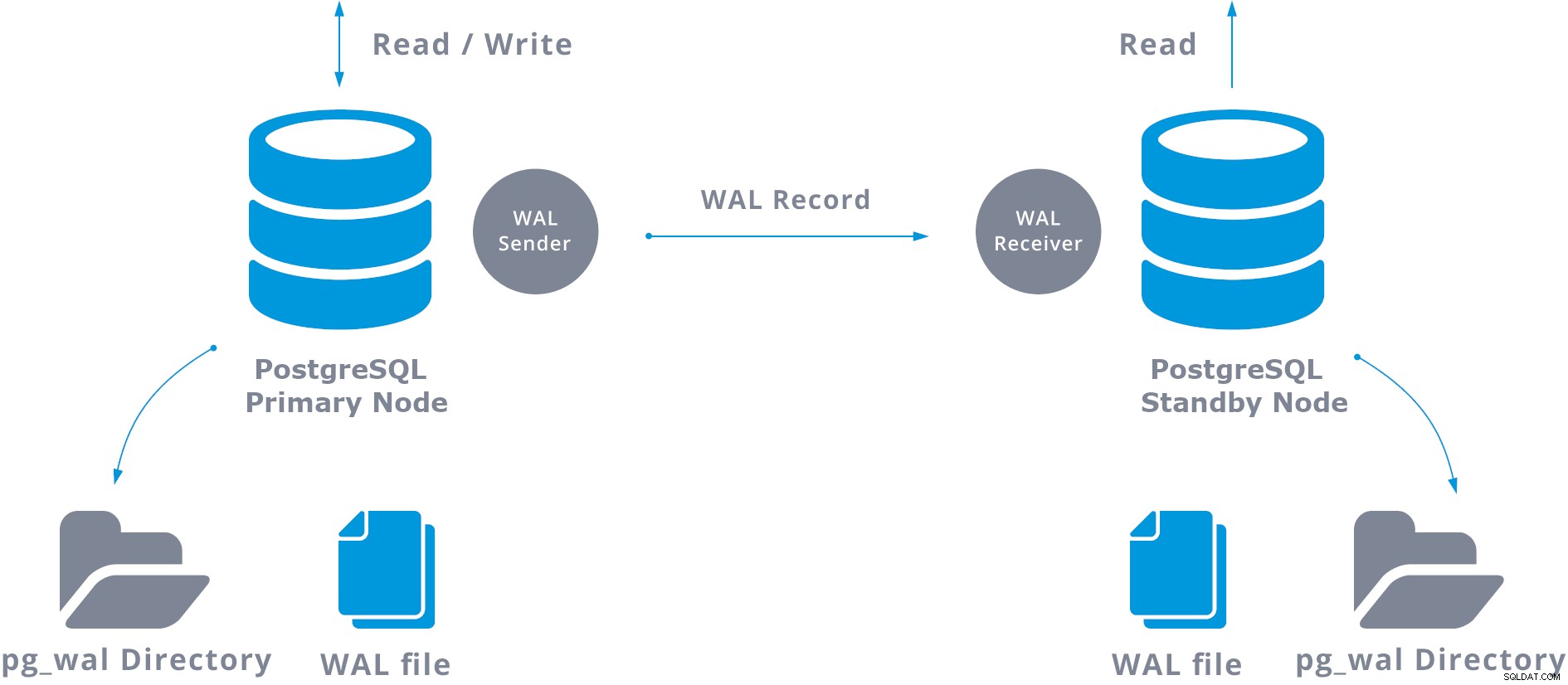
Ao configurar a replicação de streaming, você tem a opção de habilitar o arquivamento WAL. Isso não é obrigatório, mas é extremamente importante para uma configuração de replicação robusta, pois é necessário evitar que o servidor principal recicle arquivos WAL antigos que ainda não foram aplicados ao servidor em espera. Se isso ocorrer, você precisará recriar a réplica do zero.
Replicação lógica
A Replicação Lógica do PostgreSQL é um método de replicação de objetos de dados e suas alterações, com base em sua identidade de replicação (geralmente uma chave primária). É baseado em um modo de publicação e assinatura, onde um ou mais assinantes assinam uma ou mais publicações em um nó publicador.
Uma publicação é um conjunto de alterações geradas a partir de uma tabela ou grupo de tabelas. O nó onde uma publicação é definida é referido como publicador. Uma assinatura é o lado downstream da replicação lógica. O nó onde uma assinatura é definida é chamado de assinante e define a conexão com outro banco de dados e conjunto de publicações (uma ou mais) que deseja assinar. Os assinantes extraem dados das publicações que assinam.
A replicação lógica é construída com uma arquitetura semelhante à replicação de streaming físico. É implementado pelos processos "walsender" e "apply". O processo walsender inicia a decodificação lógica do WAL e carrega o plug-in de decodificação lógica padrão. O plugin transforma as alterações lidas do WAL para o protocolo de replicação lógica e filtra os dados de acordo com a especificação da publicação. Os dados são então transferidos continuamente usando o protocolo de replicação de streaming para o operador de aplicação, que mapeia os dados para tabelas locais e aplica as alterações individuais à medida que são recebidas, em uma ordem transacional correta.
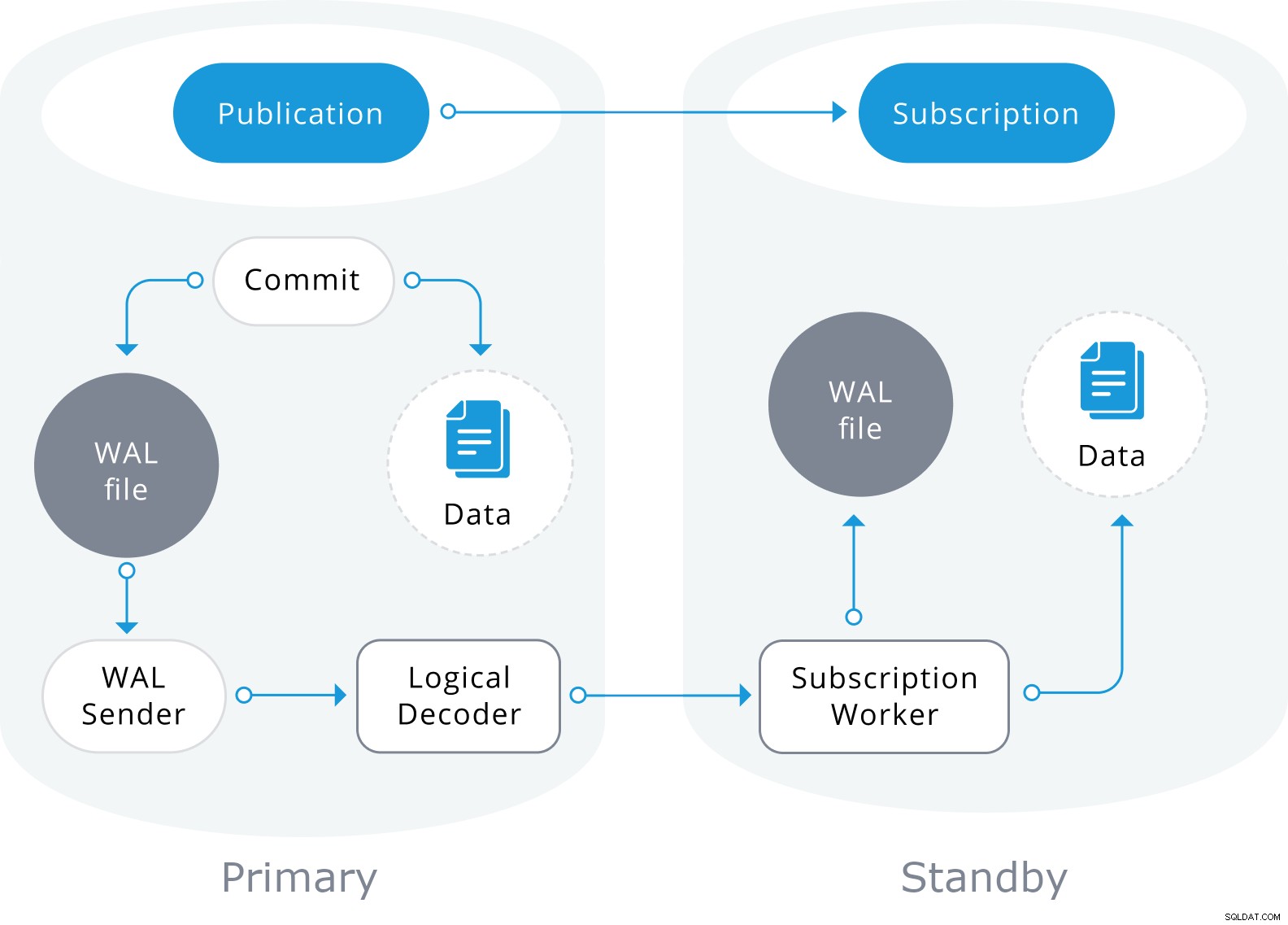
A replicação lógica começa tirando um instantâneo dos dados no banco de dados do editor e copiando isso para o assinante. Os dados iniciais nas tabelas assinadas existentes são capturados e copiados em uma instância paralela de um tipo especial de processo de aplicação. Esse processo criará seu próprio slot de replicação temporário e copiará os dados existentes. Depois que os dados existentes são copiados, o trabalhador entra no modo de sincronização, o que garante que a tabela seja colocada em um estado sincronizado com o processo de aplicação principal, transmitindo todas as alterações ocorridas durante a cópia de dados inicial usando a replicação lógica padrão. Uma vez que a sincronização é feita, o controle da replicação da tabela é devolvido ao processo de aplicação principal onde a replicação continua normalmente. As alterações no editor são enviadas ao assinante à medida que ocorrem em tempo real.
Modos de replicação no PostgreSQL
A replicação no PostgreSQL pode ser síncrona ou assíncrona.
Replicação assíncrona
É o modo padrão. Aqui é possível ter algumas transações confirmadas no nó primário que ainda não foram replicadas para o servidor em espera. Isso significa que existe a possibilidade de alguma perda potencial de dados. Esse atraso no processo de confirmação deve ser muito pequeno se o servidor em espera for poderoso o suficiente para acompanhar a carga. Se esse pequeno risco de perda de dados não for aceitável na empresa, você poderá usar a replicação síncrona.
Replicação Síncrona
Cada confirmação de uma transação de gravação aguardará até a confirmação de que a confirmação foi gravada no log de gravação antecipada no disco do servidor primário e de espera. Este método minimiza a possibilidade de perda de dados. Para que ocorra a perda de dados, você precisa que o primário e o standby falhem ao mesmo tempo.
A desvantagem desse método é a mesma para todos os métodos síncronos, pois com esse método o tempo de resposta para cada transação de gravação aumenta. Isso se deve à necessidade de aguardar até todas as confirmações de que a transação foi confirmada. Felizmente, as transações somente leitura não serão afetadas por isso, mas; apenas as transações de gravação.
Alta disponibilidade para replicação do PostgreSQL
Alta disponibilidade é um requisito para muitos sistemas, independentemente da tecnologia que usamos, e existem diferentes abordagens para conseguir isso usando ferramentas diferentes.
Balanceamento de carga
Load balancers são ferramentas que podem ser usadas para gerenciar o tráfego de seu aplicativo para obter o máximo de sua arquitetura de banco de dados. Não só é útil para equilibrar a carga de nossos bancos de dados, mas também ajuda os aplicativos a serem redirecionados para os nós disponíveis/saudáveis e até mesmo especificar portas com funções diferentes.
HAProxy é um balanceador de carga que distribui o tráfego de uma origem para um ou mais destinos e pode definir regras e/ou protocolos específicos para esta tarefa. Se algum dos destinos parar de responder, ele será marcado como off-line e o tráfego será enviado para o restante dos destinos disponíveis. Ter apenas um nó do Load Balancer gerará um único ponto de falha, portanto, para evitar isso, você deve implantar pelo menos dois nós HAProxy e configurar o Keepalived entre eles.
Keepalived é um serviço que permite configurar um IP virtual dentro de um grupo ativo/passivo de servidores. Este IP virtual é atribuído a um servidor ativo. Caso este servidor falhe, o IP é migrado automaticamente para o servidor passivo “Secundário”, permitindo que ele continue trabalhando com o mesmo IP de forma transparente para os sistemas.
Melhorando o desempenho na replicação do PostgreSQL
O desempenho é sempre importante em qualquer sistema. Você precisará fazer bom uso dos recursos disponíveis para garantir o melhor tempo de resposta possível e existem diferentes maneiras de fazer isso. Cada conexão com um banco de dados consome recursos, portanto, uma das maneiras de melhorar o desempenho do banco de dados PostgreSQL é ter um bom pool de conexões entre seu aplicativo e os servidores de banco de dados.
Conexão Poolers
Um pool de conexões é um método de criar um pool de conexões e reutilizá-las, evitando sempre abrir novas conexões com o banco de dados, o que aumentará consideravelmente o desempenho de suas aplicações. O PgBouncer é um popular pooler de conexões projetado para PostgreSQL.
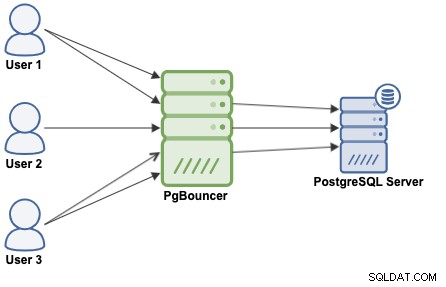
PgBouncer atua como um servidor PostgreSQL, então você só precisa acessar seu banco de dados usando as informações do PgBouncer (Endereço IP/Nome do Host e Porta), e o PgBouncer criará uma conexão com o servidor PostgreSQL, ou reutilizará uma se existir.
Quando o PgBouncer recebe uma conexão, ele realiza a autenticação, que depende do método especificado no arquivo de configuração. O PgBouncer suporta todos os mecanismos de autenticação que o servidor PostgreSQL suporta. Depois disso, o PgBouncer verifica se há uma conexão em cache, com a mesma combinação de nome de usuário + banco de dados. Se uma conexão em cache for encontrada, ele retorna a conexão ao cliente, caso contrário, cria uma nova conexão. Dependendo da configuração do PgBouncer e do número de conexões ativas, pode ser possível que a nova conexão seja enfileirada até que possa ser criada, ou mesmo abortada.
Com todos esses conceitos mencionados, na segunda parte deste blog, veremos como você pode combiná-los para ter um bom ambiente de replicação no PostgreSQL.