(Eu trabalho no Heroku Postgres)
Usamos UUIDs como chaves primárias em alguns sistemas e funciona muito bem.
Eu recomendo que você use o
uuid-ossp extensão e até mesmo fazer com que o postgres gere UUIDs para você:heroku pg:psql
psql (9.1.4, server 9.1.6)
SSL connection (cipher: DHE-RSA-AES256-SHA, bits: 256)
Type "help" for help.
dcvgo3fvfmbl44=> CREATE EXTENSION "uuid-ossp";
CREATE EXTENSION
dcvgo3fvfmbl44=> CREATE TABLE test (id uuid primary key default uuid_generate_v4(), name text);
NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "test_pkey" for table "test"
CREATE TABLE
dcvgo3fvfmbl44=> \d test
Table "public.test"
Column | Type | Modifiers
--------+------+-------------------------------------
id | uuid | not null default uuid_generate_v4() name | text |
Indexes:
"test_pkey" PRIMARY KEY, btree (id)
dcvgo3fvfmbl44=> insert into test (name) values ('hgmnz');
INSERT 0 1
dcvgo3fvfmbl44=> select * from test;
id | name
--------------------------------------+-------
e535d271-91be-4291-832f-f7883a2d374f | hgmnz
(1 row)
EDIT implicações de desempenho
Será sempre dependem de sua carga de trabalho.
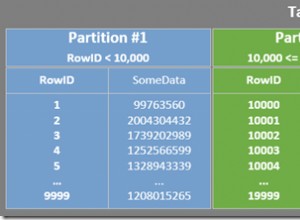
A chave primária inteira tem a vantagem da localidade onde os dados semelhantes ficam mais próximos. Isso pode ser útil para, por exemplo:consultas de tipo de intervalo, como
WHERE id between 1 and 10000 embora a contenção de bloqueio seja pior. Se sua carga de trabalho de leitura for totalmente aleatória, pois você sempre faz pesquisas de chave primária, não deve haver nenhuma degradação de desempenho mensurável:você paga apenas pelo tipo de dados maior.
Você escreve muito nesta mesa, e esta mesa é muito grande? É possível, embora eu não tenha medido isso, que haja implicações na manutenção desse índice. Para muitos conjuntos de dados, UUIDs são bons, e usar UUIDs como identificadores tem algumas propriedades interessantes.
Finalmente, posso não ser a pessoa mais qualificada para discutir ou aconselhar sobre isso, pois nunca executei uma tabela grande o suficiente com um UUID PK onde isso se tornou um problema. YMMV. (Tendo dito isso, eu adoraria ouvir de pessoas que têm problemas com a abordagem!)