Em meu artigo anterior, começamos a descrever o básico do comando EXPLAIN e analisamos o que acontece no PostgreSQL ao executar uma consulta.
Vou continuar escrevendo sobre os fundamentos do EXPLAIN no PostgreSQL. A informação é uma breve revisão de Understanding EXPLAIN por Guillaume Lelarge. Eu recomendo a leitura do original, pois algumas informações são perdidas.
Cache
O que acontece no nível físico ao executar nossa consulta? Vamos descobrir. Implantei meu servidor no Ubuntu 13.10 e usei caches de disco do nível do sistema operacional.
Eu paro o PostgreSQL, confirmo as alterações no sistema de arquivos, limpo o cache e executo o PostgreSQL:
> sudo service postgresql-9.3 stop > sudo sync > sudo su - # echo 3 > /proc/sys/vm/drop_caches # exit > sudo service postgresql-9.3 start
Quando o cache for limpo, execute a consulta com a opção BUFFERS
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Lemos a tabela por blocos. O cache está vazio. Tivemos que acessar 8334 blocos para ler a tabela inteira do disco.
Buffers:leitura compartilhada é o número de blocos que o PostgreSQL lê do disco.
Execute a consulta anterior
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Buffers:o hit compartilhado é o número de blocos recuperados do cache do PostgreSQL.
A cada consulta, o PostgreSQL retira cada vez mais dados do cache, preenchendo assim seu próprio cache.
As operações de leitura de cache são mais rápidas do que as operações de leitura de disco. Você pode ver essa tendência rastreando o valor total do tempo de execução.
O tamanho do armazenamento em cache é definido pela constante shared_buffers no arquivo postgresql.conf.
ONDE
Adicione a condição à consulta
EXPLAIN SELECT * FROM foo WHERE c1 > 500;
Não há índices na tabela. Ao executar a consulta, cada registro da tabela é escaneado sequencialmente (Seq Scan) e comparado com a condição c1> 500. Se a condição for atendida, o registro será adicionado ao resultado. Caso contrário, é descartado. Filtro indica esse comportamento, assim como o valor do custo aumenta.
O número estimado de linhas diminui.
O artigo original explica por que o custo assume esse valor e como o número estimado de linhas é calculado.
É hora de criar índices.
CREATE INDEX ON foo(c1); EXPLAIN SELECT * FROM foo WHERE c1 > 500;

O número estimado de linhas foi alterado. E o índice?
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

Apenas 510 linhas de mais de 1 milhão são filtradas. O PostgreSQL teve que ler mais de 99,9% da tabela.
Vamos forçar o uso do índice desabilitando Seq Scan:
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

Em Index Scan e Index Cond, o índice foo_c1_idx é usado em vez de Filter.
Ao selecionar a tabela inteira, o uso do índice aumentará o custo e o tempo de execução da consulta.
Ativar Seq Scan:
SET enable_seqscan TO on;
Modifique a consulta:
EXPLAIN SELECT * FROM foo WHERE c1 < 500;
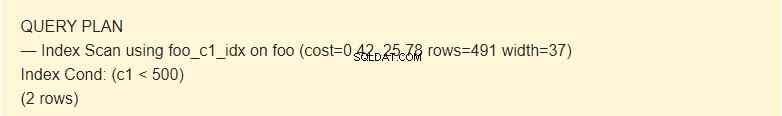
Aqui o planejador usa o índice.
Agora, vamos complicar o valor adicionando o campo de texto.
EXPLAIN SELECT * FROM foo
WHERE c1 < 500 AND c2 LIKE 'abcd%'; 
Como você pode ver, o índice foo_c1_idx é usado para c1 <500. Para executar c2 ~~ 'abcd%'::text, use o filtro.
Deve-se notar que o formato POSIX do operador LIKE é usado na saída dos resultados. Se houver apenas o campo de texto na condição:
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Seq Scan é aplicado.
Construa o índice por c2:
CREATE INDEX ON foo(c2); EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

O índice não é aplicado porque meu banco de dados para campos de teste usa a codificação UTF-8.
Ao construir o índice, é necessário especificar a classe do operador text_pattern_ops:
CREATE INDEX ON foo(c2 text_pattern_ops); EXPLAIN SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Excelente! Funcionou!
A varredura de índice de bitmap usa o índice foo_c2_idx1 para determinar os registros de que precisamos. Em seguida, o PostgreSQL vai para a tabela (Bitmap Heap Scan) para certificar-se de que esses registros realmente existem. Esse comportamento se refere ao versionamento do PostgreSQL.
Se você selecionar apenas o campo no qual o índice é construído, em vez de toda a linha:
EXPLAIN SELECT c1 FROM foo WHERE c1 < 500;

Index Only Scan será executado mais rápido do que Index Scan devido ao fato de que não é necessário ler a linha da tabela:largura=4.
Conclusão
- Seq Scan lê a tabela inteira
- O Index Scan usa o índice para as instruções WHERE e lê a tabela ao selecionar linhas
- Bitmap Index Scan usa Index Scan e controle de seleção por meio da tabela. Eficaz para um grande número de linhas.
- A varredura somente índice é o bloco mais rápido, que lê apenas o índice.
Leitura adicional:
Otimização de consultas no PostgreSQL. EXPLIQUE Noções básicas - Parte 3