Por que leva tanto tempo para executar uma consulta? Por que não há índices? Provavelmente, você já ouviu falar sobre EXPLAIN no PostgreSQL. No entanto, ainda existem muitas pessoas que não têm ideia de como usá-lo. Espero que este artigo ajude os usuários a lidar com esta ótima ferramenta.
Este artigo é a revisão do autor de Understanding EXPLAIN de Guillaume Lelarge. Como perdi algumas informações, recomendo que você se familiarize com o original.
O diabo não é tão preto quanto é pintado
É importante entender a lógica do kernel do PostgreSQL para otimizar as consultas. vou tentar explicar. Realmente não é tão complicado.
EXPLAIN exibe as informações necessárias que explicam o que o kernel faz para cada consulta específica.
Vamos dar uma olhada no que o comando EXPLAIN exibe e entender o que exatamente acontece dentro do PostgreSQL. Você pode aplicar essas informações ao PostgreSQL 9.2 e versões superiores.
Nossas tarefas:
- Saiba como ler e entender a saída do comando EXPLAIN
- Entenda o que acontece no PostgreSQL quando uma consulta é executada
Primeiros passos
Estaremos praticando em uma tabela de teste com um milhão de linhas.
CREATE TABLE foo (c1 integer, c2 text); INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 1000000) AS i;
Tente ler os dados
EXPLAIN SELECT * FROM foo;
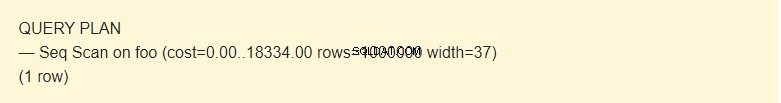
É possível ler dados de uma tabela de várias maneiras. No nosso caso, EXPLAIN notifica que um Seq Scan é usado — um dado sequencial, bloco a bloco, da tabela Foo lida.
O que é custo ?
Bem, não é um tempo, mas um conceito projetado para estimar o custo de uma operação. O primeiro valor 0,00 é o custo para obter a primeira linha. O segundo valor 18334,00 é o custo para obter todas as linhas.
Linhas são o número aproximado de linhas retornadas quando uma operação Seq Scan é executada. O agendador retorna esse valor. No meu caso, corresponde ao número real de linhas na tabela.
Largura é um tamanho médio de uma linha em bytes.
Vamos tentar adicionar 10 linhas.
INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 10) AS i; EXPLAIN SELECT * FROM foo;

O valor das linhas não foi alterado. As estatísticas da tabela são antigas. Para atualizar as estatísticas, chame o comando ANALYZE.
Agora, linhas exibir o número correto de linhas.
O que acontece ao executar ANALYZE?
- Aleatoriamente, várias linhas são selecionadas e lidas na tabela.
- As estatísticas de valores de cada coluna são coletadas.
O número de linhas que ANALYZE lê depende do parâmetro default_statistics_target.
Dados reais
Tudo o que vimos acima na saída do comando EXPLAIN é o que o planejador espera obter. Vamos tentar compará-los com os resultados em dados reais. Para fazer isso, use EXPLAIN (ANALISAR).
EXPLAIN (ANALYZE) SELECT * FROM foo;

Tal consulta será realizada de fato. Portanto, se você executar EXPLAIN (ANALYZE) para as instruções INSERT, DELETE ou UPDATE, seus dados serão alterados. Tome cuidado! Nesses casos, use o comando ROLLBACK.
O comando exibe os seguintes parâmetros adicionais:
- tempo real é o tempo real em milissegundos gasto para obter a primeira linha e todas as linhas, respectivamente.
- linhas é o número real de linhas recebidas com Seq Scan.
- loops é o número de vezes que a operação Seq Scan teve que ser executada.
- Total runtime é o tempo total de execução da consulta.
Leitura adicional:
Otimização de consultas no PostgreSQL. EXPLIQUE Noções básicas - Parte 2
Otimização de consultas no PostgreSQL. EXPLIQUE Noções básicas - Parte 3