Continuo uma série de artigos sobre os fundamentos do EXPLAIN no PostgreSQL, que é uma breve revisão de Understanding EXPLAIN de Guillaume Lelarge.
Para entender melhor o assunto, recomendo rever o original “Understanding EXPLAIN” de Guillaume Lelarge e leia meu primeiro e segundo artigos.
ORENDER POR
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Primeiramente, você executa uma varredura sequencial (Seq Scan) da tabela foo e, em seguida, faz a ordenação (Sort). O sinal -> do comando EXPLAIN indica a hierarquia das etapas (nó). Quanto mais cedo a etapa for executada, maior será o recuo.
Chave de classificação é uma condição de classificação.
Sort Method:External merge Disk um arquivo temporário no disco com capacidade de 4592 kB é usado na ordenação.
Verifique com a opção BUFFERS:
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;
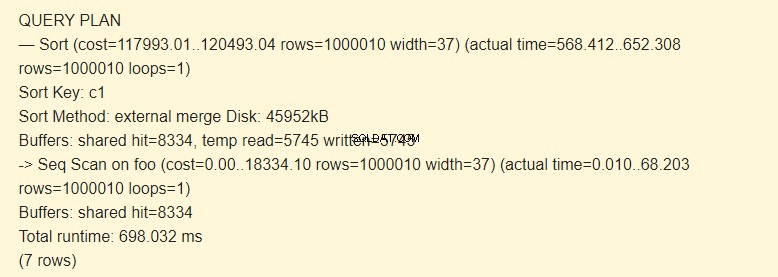
De fato, a linha temp read=5745 write=5745 significa que 45960Kb (5745 blocos de 8 Kb cada) foram armazenados e lidos no arquivo temporário. As operações com 8334 blocos foram executadas no cache.
As operações com o sistema de arquivos são mais lentas do que as operações na RAM.
Vamos tentar aumentar a capacidade de memória do work_mem:
SET work_mem TO '200MB'; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Método de Ordenação:quicksort Memória:102702kB – toda a ordenação foi executada na RAM.
O índice é o seguinte:
CREATE INDEX ON foo(c1); EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Temos apenas Index Scan restante, o que afetou significativamente a velocidade da consulta.
LIMITE
Exclua o índice criado anteriormente:
DROP INDEX foo_c2_idx1; EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%';
Como esperado, Seq Scan e Filter são usados.
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%' LIMIT 10;

Seq Scan lê as linhas da tabela e as compara (Filter) com a condição. Assim que houver 10 registros que atendam à condição, a verificação será encerrada. No nosso caso, para obter 10 linhas de resultado, tivemos que ler apenas 3063 registros em vez de toda a tabela. 3053 linhas deste número foram rejeitadas (Linhas Removidas pelo Filtro).
O mesmo acontece com o Index Scan.
PARTICIPE
Crie uma nova tabela e gere estatísticas para ela:
CREATE TABLE bar (c1 integer, c2 boolean); INSERT INTO bar SELECT i, i%2=1 FROM generate_series(1, 500000) AS i; ANALYZE bar;
A consulta para duas tabelas é a seguinte:
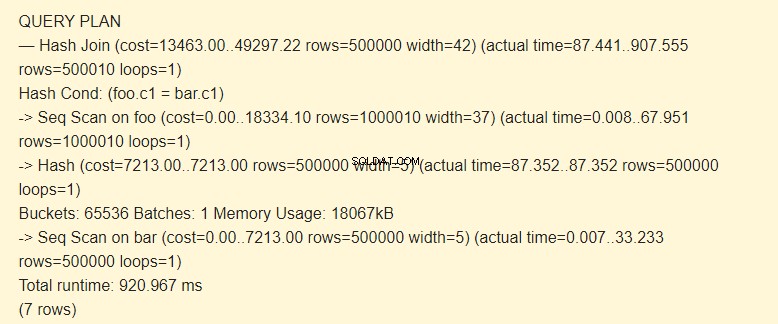
EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;
Primeiro, a varredura sequencial (Seq Scan) lê a tabela de barras. Um hash (Hash) é calculado para cada linha.
Em seguida, ele varre a tabela foo e, para cada linha, é calculado um hash que é comparado (Hash Join) com o hash da tabela bar pela condição Hash Cond. Se eles corresponderem, uma string resultante será emitida.
18067kB de memória são usados para armazenar hashes para a barra.
Adicione o índice:
CREATE INDEX ON bar(c1); EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;

Hash não é mais usado. Merge Join e Index Scan nos índices de ambas as tabelas melhoram muito o desempenho.
LEFT JOIN:
EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
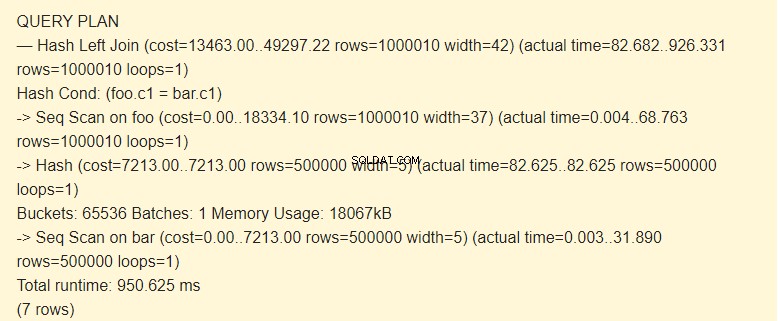
Seq Scan?
Vamos ver qual resultado teremos se desabilitarmos o Seq Scan.
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

De acordo com o escalonador, usar índices é mais caro do que usar hashes. Isso é possível com uma quantidade suficientemente grande de memória alocada. Você se lembra de nós aumentando work_mem?
No entanto, se você não tiver memória suficiente, o agendador se comportará de maneira diferente:
SET work_mem TO '15MB'; SET enable_seqscan TO ON; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Se desabilitarmos a Varredura de Índice, qual resultado EXPLAIN será exibido?
SET work_mem TO '15MB'; SET enable_indexscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
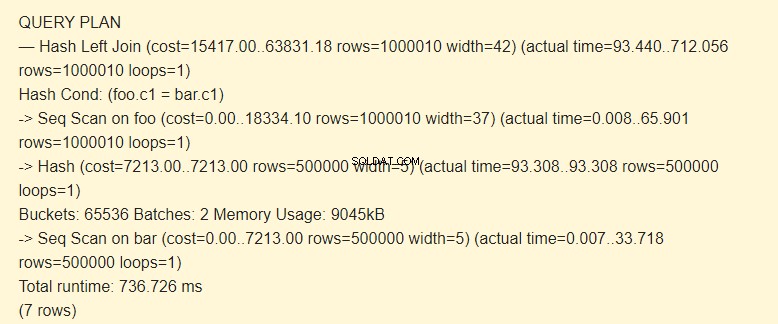
Lotes:2 aumentou o custo. O hash inteiro não coube na memória; tivemos que dividi-lo em dois pacotes de 9045kB.
Obrigado por ler meus artigos! Espero que tenham sido úteis. Se você tiver algum comentário ou feedback, sinta-se à vontade para me informar.