Esta é a versão escrita do meu novo vídeo do youtube ✍️ 🙂
Neste tutorial do Redis, você aprenderá sobre o Redis e como o Redis pode ser usado como um banco de dados principal para aplicativos complexos que precisam armazenar dados em vários formatos.
Visão geral 📝
- O que é o Redis e seus usos e por que ele é adequado para aplicativos modernos de microsserviços complexos?
- Como o Redis suporta o armazenamento de vários formatos de dados para diferentes finalidades por meio de seus módulos ?
- Como o Redis como um banco de dados na memória pode persistir os dados e se recuperar da perda de dados ?
- Como escalar e replicar o Redis ?
- Por fim, como uma das plataformas mais populares para executar microsserviços é o Kubernetes e como executar aplicativos com estado no Kubernetes é um pouco desafiador, veremos como você pode facilmente executar o Redis no Kubernetes
O que é Redis?
Redis significa re mote dic s cionários sempre
Redis é um banco de dados na memória . Então, muitas pessoas o usaram como cache em cima de outros bancos de dados para melhorar o desempenho do aplicativo. 🤓
No entanto, o que muitas pessoas não sabem é que o Redis é um banco de dados primário completo que pode ser usado para armazenar e persistir vários formatos de dados para aplicativos complexos. 😎
Então, vamos ver os casos de uso para isso.
Por que banco de dados multimodelo?
Vejamos uma configuração comum para um aplicativo de microsserviços.
Digamos que temos um aplicativo de mídia social complexo com milhões de usuários. Para isso, podemos precisar armazenar diferentes formatos de dados em diferentes bancos de dados:
- Banco de dados relacional , como o Mysql, para armazenar nossos dados
- ElasticSearch para pesquisa e filtragem rápidas
- Banco de dados de gráficos para representar as conexões dos usuários
- Banco de dados de documentos , como o MongoDB para armazenar conteúdo de mídia compartilhado por nossos usuários diariamente
- Serviço de cache para um melhor desempenho do aplicativo
É óbvio que esta é uma configuração bastante complexa.
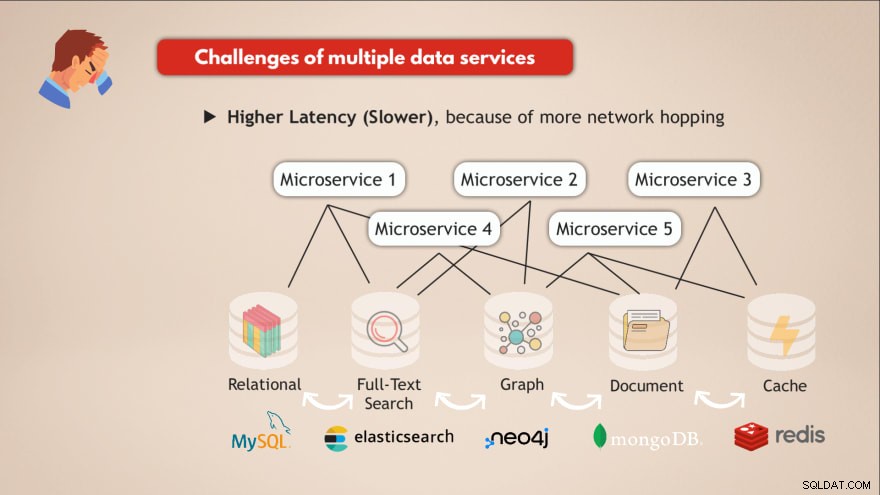
Desafios de ter vários serviços de dados
- ❌ Cada serviço de dados precisa ser implantado e mantido
- ❌ Conhecimento necessário para cada serviço de dados
- ❌ Diferentes requisitos de dimensionamento e infraestrutura
- ❌ Código de aplicativo mais complexo para interagir com todos esses diferentes bancos de dados
- ❌ Maior latência (mais lenta), devido a mais saltos de rede
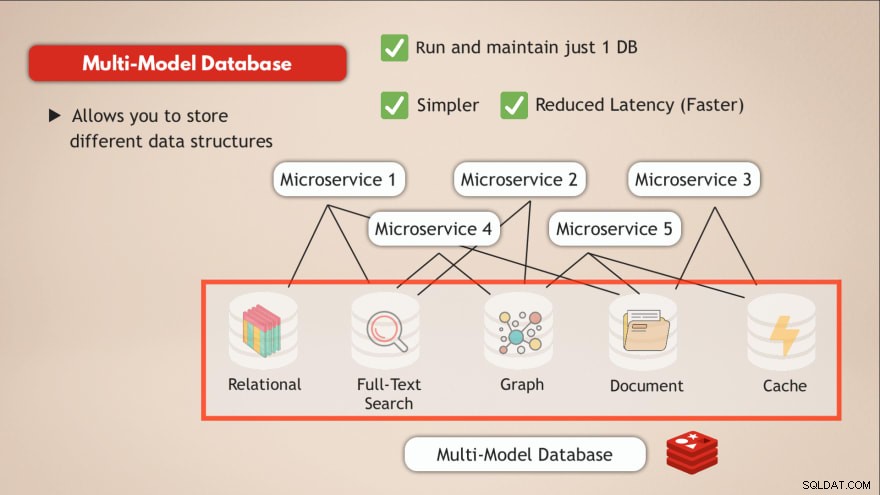
Ter um banco de dados multimodelo
Em comparação com um banco de dados multimodelo, você resolve a maioria desses desafios. Em primeiro lugar, você executa e mantém apenas 1 serviço de dados . Portanto, seu aplicativo também precisa se comunicar com um único armazenamento de dados e isso requer apenas uma interface programática para esse serviço de dados.
Além disso, a latência será reduzida indo para um único endpoint de dados e eliminando vários hubs de rede internos.
Portanto, ter um banco de dados, como o Redis, que permite armazenar diferentes tipos de dados ou basicamente permite ter vários tipos de bancos de dados em um, além de atuar como um cache, resolve esses desafios.
- ✅ Execute e mantenha apenas 1 banco de dados
- ✅ Mais simples
- ✅ Latência reduzida (mais rápida)
Como o Redis funciona?
Módulos Redis 📦
A maneira como funciona é que você tem o Redis Core, que é um armazenamento de valor-chave que já suporta o armazenamento de vários tipos de dados e, em seguida, você pode estender esse núcleo com os chamados módulos para diferentes tipos de dados , que seu aplicativo precisa para diferentes propósitos. Por exemplo, RediSearch para funcionalidade de pesquisa como ElasticSearch ou Redis Graph para armazenamento de dados de gráfico e assim por diante:

E o melhor disso é que é modular . Portanto, esses diferentes tipos de funcionalidades de banco de dados não são totalmente integrados em um banco de dados, mas você pode escolher exatamente qual funcionalidade de serviço de dados você precisa para seu aplicativo e, basicamente, adicionar esse módulo.
Cache pronto para uso ⚡️
É claro que ao usar o Redis como banco de dados primário, você não precisa de um cache adicional, porque você o tem automaticamente pronto para uso com o Redis. Isso significa novamente menos complexidade em seu aplicativo, porque você não precisa implementar a lógica para gerenciar o preenchimento e a invalidação do cache.
O Redis é rápido 🚀
Como um banco de dados na memória (os dados são armazenados na RAM), o Redis é super rápido e de alto desempenho, o que obviamente torna o aplicativo mais rápido.
Mas neste momento você deve estar se perguntando:
Como um banco de dados na memória pode manter os dados? 🤔
Como o Redis pode manter os dados e se recuperar da perda de dados? 🧐
Se o processo do Redis ou o servidor no qual o Redis está sendo executado falhar, todos os dados na memória desaparecerão, certo? Então, como os dados são mantidos e, basicamente, como posso ter certeza de que meus dados estão seguros? 👀
Replicando o Redis?
Bem, a maneira mais simples de fazer backups de dados é replicar o Redis . Portanto, se a instância mestre do Redis ficar inativa, as réplicas ainda estarão em execução e terão todos os dados. Portanto, se você tiver um Redis replicado, as réplicas terão os dados.
Mas é claro que se todas as instâncias do Redis ficarem inativas, você perderá os dados, porque não haverá réplica restante. 🤯Então precisamos de persistência real .
Instantâneo e AOF
O Redis tem vários mecanismos para persistir os dados e mantê-los seguros.
Instantâneos
Primeiro:os instantâneos, que você pode configurar com base no tempo, número de solicitações etc. Assim, instantâneos de seus dados serão armazenados em um disco , que você pode usar para recuperar seus dados se todo o banco de dados Redis desaparecer.
Mas observe que você perderá os últimos minutos de dados , porque você costuma fazer snapshots a cada cinco minutos ou uma hora, dependendo de suas necessidades. 😐
AOF
Então, como alternativa, o Redis usa algo chamado AOF , que significa A anexar O apenas F ile.
Nesse caso, todas as alterações são salvas no disco para persistência contínua . E ao reiniciar o Redis ou após uma interrupção, o Redis reproduzirá os logs de arquivo somente anexado para reconstruir o estado.
Portanto, AOF é mais durável , mas pode ser mais lento que o snapshot.
Melhor opção 💡 :Use uma combinação de AOF e instantâneos, onde o AOF está persistindo dados da memória para o disco continuamente, além de ter instantâneos regulares entre eles para salvar o estado dos dados caso precise recuperá-lo:

Como dimensionar um banco de dados Redis?
Digamos que minha instância 1 do Redis fique sem memória, então os dados se tornam muito grandes para armazenar na memória ou o Redis se torna um gargalo e não pode lidar com mais solicitações. Nesse caso, como faço para aumentar a capacidade e o tamanho da memória para meu banco de dados Redis? 🤔
Temos várias opções para isso:
1. Agrupamento
Em primeiro lugar, o Redis suporta clustering . Isso significa que você pode ter uma instância primária ou mestre do Redis, que pode ser usada para ler e gravar dados, e você pode ter várias réplicas dessa instância primária para ler os dados :
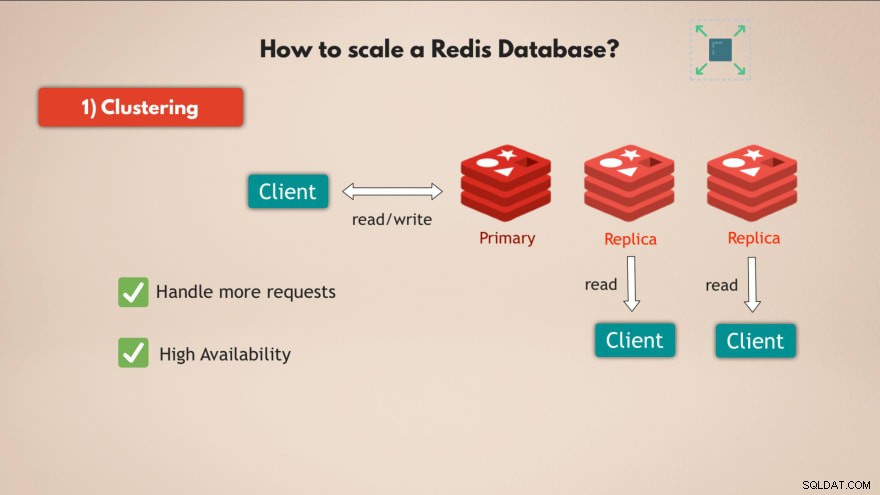
Dessa forma, você pode dimensionar o Redis para lidar com mais solicitações e, além disso, aumentar a alta disponibilidade do seu banco de dados, porque se o mestre falhar, 1 das réplicas pode assumir e seu banco de dados Redis basicamente pode continuar funcionando sem problemas.
2. Fragmentação
Bem, isso parece bom o suficiente, mas e se
- seu conjunto de dados fica muito grande para caber em uma memória em um único servidor .
- Além disso, escalamos as leituras no banco de dados, para todas as solicitações que basicamente consultam os dados. Mas nossa instância mestre ainda está sozinha e ainda precisa lidar com todas as gravações .
Então, qual é a solução aqui? 🤔
Para isso usamos o conceito de sharding , que é um conceito geral em bancos de dados e que o Redis também suporta.
Então fragmentação basicamente significa que você pega seu conjunto de dados completo e o divide em partes menores ou subconjuntos de dados , em que cada estilhaço é responsável por seu próprio subconjunto de dados.
Isso significa que, em vez de ter uma instância mestre que lida com todas as gravações no conjunto de dados completo, você pode dividi-lo em, digamos, 4 fragmentos, cada um deles responsável por leituras e gravações em um subconjunto dos dados . 💡
E cada fragmento também precisa de menos capacidade de memória , porque eles têm apenas um quarto dos dados. Isso significa que você pode distribuir e executar estilhaços em nós menores e basicamente dimensionar seu cluster horizontalmente:
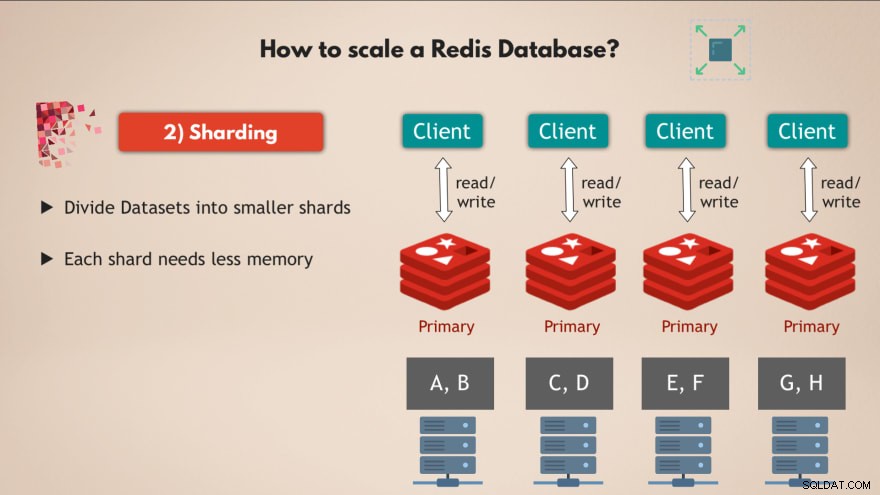
Portanto, ter vários nós , que executam várias réplicas do Redis que são todos fragmentados oferece um banco de dados Redis de alto desempenho e alta disponibilidade que pode lidar com muito mais solicitações sem criar gargalos 👍
Mais tópicos...
Confira meu vídeo abaixo para os últimos 2 tópicos e cenários:
- Aplicativos que precisam de disponibilidade e desempenho ainda maiores em várias localizações geográficas
- O novo padrão para executar microsserviços é a plataforma Kubernetes, então executar Redis no Kubernetes é um caso de uso muito interessante e comum
O vídeo completo está disponível aqui:🤓
Espero que tenha sido útil e interessante para alguns de vocês! 😊
Curta, compartilhe e siga-me 😍 para mais conteúdo:
- Instagram - Postando muitas coisas de bastidores
- Grupo privado do Facebook



