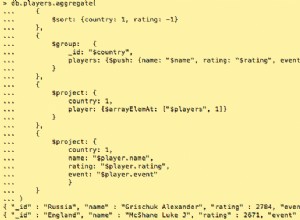
Considere usar um índice de texto com um
$text pesquisar
. Pode ser uma solução muito melhor do que usar expressões regulares. No entanto, a pesquisa de texto retorna documentos com base em um algoritmo de pontuação, portanto, você pode obter alguns resultados que não contêm todas as palavras-chave que está procurando. Se você não puder ou não quiser adicionar um índice de texto a esse campo, usar uma única expressão regular seria bastante trabalhoso porque você não sabe a ordem em que essas palavras aparecem. Eu não afirmo que é impossível escrever, mas você vai acabar com uma abominação horrível mesmo para os padrões regex. Seria muito mais fácil usar o operador regex várias vezes usando o
$and operador. Além disso, usar um espaço como delimitador falhará quando a palavra estiver no início ou no final da string ou seguida por um ponto ou vírgula. Use o token de limite de palavra (
\b ) em vez de. collection.find(
{ $and : [
{'documenttextfield': {'$regex': '\b' +keyword1+'\b'}},
{'documenttextfield': {'$regex': '\b' +keyword2+'\b'}},
{'documenttextfield': {'$regex': '\b' +keyword3+'\b'}},
]
});
Tenha em mente que esta é uma consulta muito lenta, porque ela executará essas três expressões regulares em cada documento da coleção. Quando esta é uma consulta crítica ao desempenho, considere seriamente se um índice de texto realmente não funcionará. Caso contrário, a última gota a ser compreendida seria extrair quaisquer palavras-chave do
documenttextfield campo que alguém poderia pesquisar (que pode ser cada palavra única nele) em um novo campo de matriz documenttextfield_keywords , crie um índice normal nesse campo e pesquise nesse campo com o $all operador
(nenhuma expressão regular necessária nesse caso).