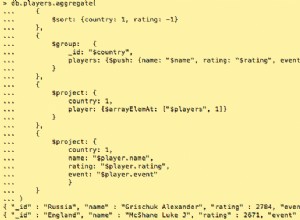
Você pode tentar o
mongo.find.exhaust opção cursor <- mongo.find(mongo, query, options=[mongo.find.exhaust])
Esta seria a correção mais fácil se realmente funcionasse para o seu caso de uso.
No entanto, o driver rmongodb parece estar faltando alguns recursos extras disponíveis em outros drivers. Por exemplo, o driver JavaScript tem um
Cursor.toArray método. Que despeja diretamente todos os resultados de busca em uma matriz. O driver R tem um mongo.bson.to.list função, mas um mongo.cursor.to.list é provavelmente o que você quer. Provavelmente vale a pena entrar em contato com o desenvolvedor do driver para obter conselhos. Uma solução hacky poderia ser criar uma nova coleção cujos documentos são "pedaços" de dados de 100.000 dos documentos originais cada. Então, cada um deles pode ser lido eficientemente com
mongo.bson.to.list . A coleção em partes pode ser construída usando a funcionalidade MapReduce do servidor mongo.