Quando você instala o ClusterControl, ele tem uma configuração padrão que talvez não atenda aos seus requisitos, então provavelmente você precisará personalizar esta instalação. Para isso, você pode modificar os arquivos de configuração, mas também pode verificar ou modificar as configurações do ClusterControl em tempo de execução. Neste blog, mostraremos onde você pode ver essa configuração e quais são as opções disponíveis para usar aqui.
Onde você pode ver a configuração do ClusterControl Runtime?
Existem duas maneiras diferentes de verificar isso. Primeiro, você pode ir para ClusterControl -> Configurações globais -> Configurações de tempo de execução e escolher seu cluster.
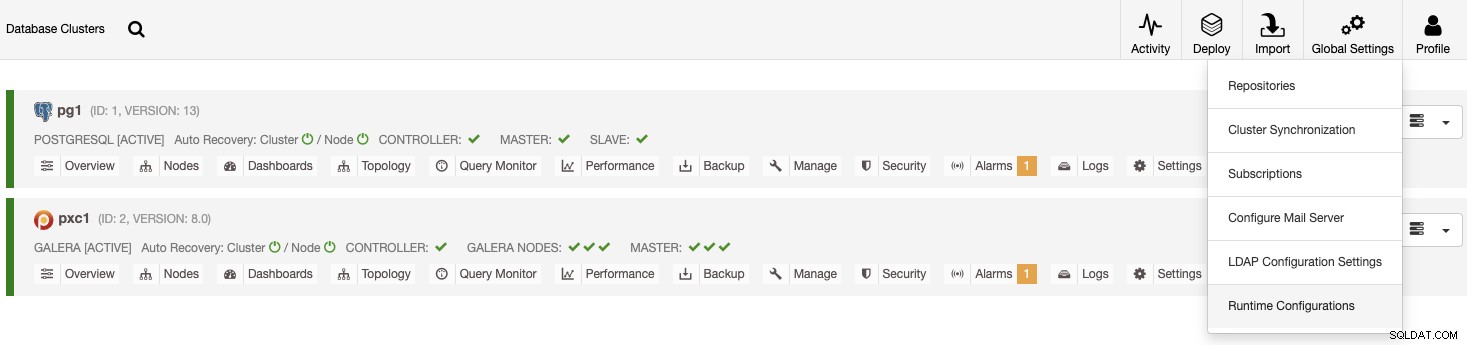
Outra maneira é ClusterControl -> Select Cluster -> Settings -> Runtime Configurations .
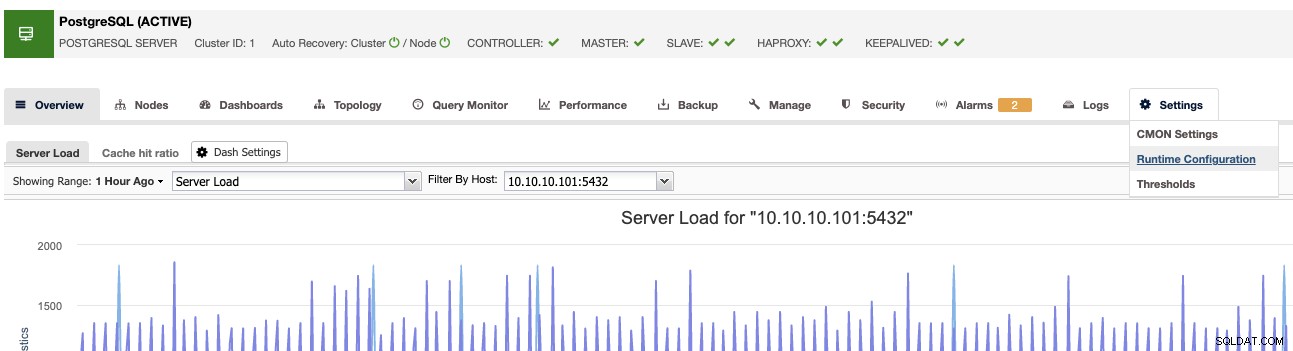
Em ambos os casos, você irá para o mesmo local, o Runtime Configuration seção.
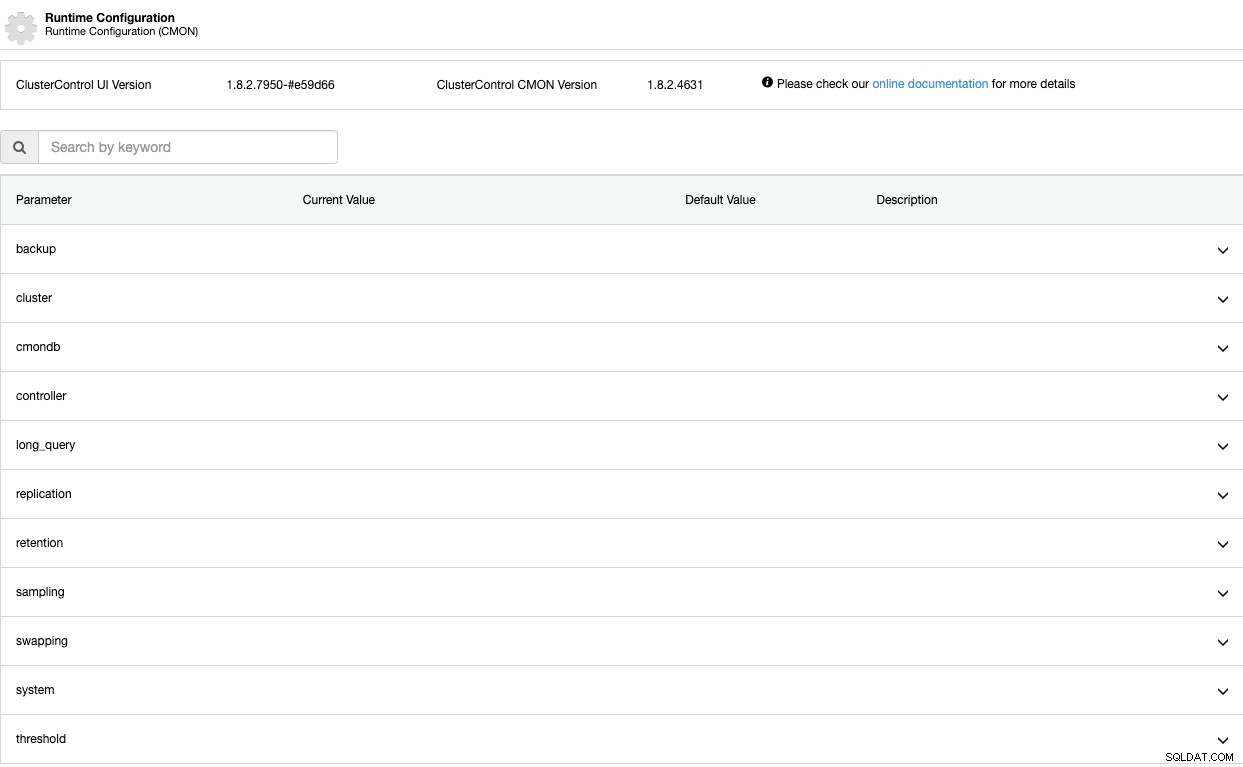
Parâmetros de configuração de tempo de execução
Agora, vamos ver esses parâmetros um por um. Lembre-se de que esses parâmetros dependem da tecnologia de banco de dados que você está usando, portanto, provavelmente você não verá todos eles ao mesmo tempo no mesmo cluster.
Backup
| Nome | Valor padrão | Descrição |
|---|---|---|
| disable_backup_email | falso | Esta configuração controla se os e-mails são enviados ou não se um backup foi concluído ou falhou. |
| usuário_backup | usuário de backup | O nome de usuário da conta do banco de dados usada para gerenciar backups. |
| backup_create_hash | verdadeiro | Configura o ClusterControl se tiver que calcular md5hash nos arquivos de backup criados e verificá-los. |
| pitr_retention_hours | 0 | Horas de retenção (para apagar logs de arquivo WAL antigos) para PITR. |
| netcat_port | 9999,9990-9998 | Lista de portas Netcat e intervalos de portas usados para transmitir backups. Os padrões para '9999,9990-9998' e a porta 9999 serão preferidos, se disponíveis. |
| diretório de backup | /home/user/backups | O diretório de backup padrão, a ser pré-preenchido no Frontend. |
| backup_subdir | BACKUP-%I | Defina o nome do subdiretório de backup. Essa string pode conter separadores de campo padrão "%X", o "%06I", por exemplo, será substituído pela ID numérica do backup em formato de 6 campos que usa '0' como caracteres de preenchimento à esquerda. Aqui está a lista de campos que o backend suporta atualmente:- B A data e hora em que a criação do backup estava começando. - H O nome do host de backup, o host que criou o backup. - i O ID numérico do cluster. - I O ID numérico do backup. - J A ID numérica da tarefa que criou o backup. - M O método de backup (por exemplo, "mysqldump"). - O O nome do usuário que iniciou o trabalho de backup. - S O nome do host de armazenamento, o host que armazena os arquivos de backup. - % O próprio sinal de porcentagem. Use dois sinais de porcentagem, "%%" da mesma forma que a função printf() padrão interpreta como um sinal de porcentagem. |
| backup_retention | 31 | A configuração de quantos dias manter os backups. Os backups correspondentes ao período de retenção são removidos. |
| backup_cloud_retention | 180 | A configuração de quantos dias manter os backups carregados em uma nuvem. Os backups correspondentes ao período de retenção são removidos. |
| backup_n_safety_copies | 1 | A configuração de quantos backups completos concluídos serão mantidos, independentemente de seu status de retenção. |
Agrupamento
| Nome | Valor padrão | Descrição |
|---|---|---|
| cluster_name | O nome do cluster para facilitar a identificação. | |
| enable_node_autorecovery | verdadeiro | Configuração de recuperação automática do nó. |
| enable_cluster_autorecovery | verdadeiro | Se verdadeiro, o ClusterControl realizará a recuperação automática do cluster, se falso, nenhuma recuperação do cluster será feita automaticamente. |
| configuração | /etc/ | O diretório de configuração do servidor de banco de dados. |
| criado_por_trabalho | O ID do trabalho que criou este cluster. | |
| ssh_keypath | /home/user/.ssh/id_rsa | O arquivo de chave SSH usado para conexão com nós. |
| server_selection_try_once | verdadeiro | Opção de URI de conexão do MongoDB. Define se a seleção do servidor deve ser repetida em caso de falha até que o tempo limite de seleção do servidor expire ou apenas retorne com falha de uma vez. |
| server_selection_timeout_ms | 30.000 | Opção de URI de conexão do MongoDB. Define o valor do tempo limite até que o mongodriver tente fazer uma operação de seleção de servidor bem-sucedida. |
| proprietário | O ID do usuário ClusterControl do proprietário do objeto de cluster. | |
| group_owner | O ID do grupo ClusterControl do grupo que possui o objeto de cluster. | |
| caminho_cdt | A localização do objeto de cluster na Árvore de diretórios ClusterControl. | |
| etiquetas | / | Um conjunto de strings que o usuário pode especificar. |
| acl | A Lista de Controle de Acesso como uma string que controla o acesso ao objeto de cluster. | |
| mongodb_user | admindb | O nome de usuário do MongoDB. |
| mongodb_basedir | /usr/ | O basedir para instalação do MongoDB. |
| mysql_basedir | /usr/ | O basedir para instalação do MySQL. |
| diretório de script | /usr/bin/ | O diretório de scripts da instalação do MySQL. |
| staging_dir | /home/user/s9s_tmp | Um caminho de teste para arquivos temporários. |
| bindir | /usr/bin | O diretório /bin da instalação do MySQL. |
| monitored_mysql_port | 3306 | O número da porta do servidor MySQL monitorado. |
| ndb_connectstring | 127.0.0.1:1186 | A configuração da string de conexão do NDB para o MySQL Cluster. |
| ndbd_datadir | O datadir dos nós NDBD. | |
| mgmd_datadir | O datadir dos nós NDB MGMD. | |
| os_user | O nome de usuário SSH usado para acessar os nós. | |
| repl_user | cmon_replication | O nome de usuário de replicação. |
| fornecedor | O nome do fornecedor do banco de dados usado para implantações. | |
| versão_galera | O número de versão do Galera usado. | |
| server_version | A versão do servidor de banco de dados usada para implantações. | |
| postgresql_user | admindb | O nome de usuário do PostgreSQL. |
| porta_galera | 4567 | A porta galera a ser usada ao adicionar nodes/garbd e construir wsrep_cluster_address. Não altere em tempo de execução. |
| auto_manage_readonly | verdadeiro | Permitir que o ClusterControl gerencie o sinalizador somente leitura dos servidores MySQL gerenciados. |
| node_recovery_lock_file | Especifique um arquivo de bloqueio e, se estiver presente em um nó, o nó não será recuperado. É responsabilidade do administrador criar/remover o arquivo. |
Cmondb
| Nome | Valor padrão | Descrição |
|---|---|---|
| cmon_db | cmon | O nome do banco de dados ClusterControl local. |
| cmondb_hostname | 127.0.0.1 | O nome de host do servidor MySQL do banco de dados ClusterControl local. |
| mysql_port | 3306 | A porta do servidor MySQL do banco de dados ClusterControl local. |
| cmon_user | cmon | O nome da conta para acessar o banco de dados ClusterControl local. |
Controlador
| Nome | Valor padrão | Descrição |
|---|---|---|
| controller_id | 5a3a993d-xxxx | Uma string identificadora arbitrária desta instância do controlador. |
| cmon_hostname | 192.168.xx.xx | O nome do host do controlador. |
| error_report_dir | /home/user/s9s_tmp | Local de armazenamento dos relatórios de erros. |
Long_query
| Nome | Valor padrão | Descrição |
|---|---|---|
| long_query_time | 0,5 | Valor limite para verificação de consulta lenta. |
| query_monitor_alert_long_running_query | verdadeiro | Aciona um alarme se uma consulta for executada por mais tempo que query_monitor_long_running_query_ms. |
| query_monitor_kill_long_running_query | falso | Eliminar a consulta se a consulta for executada por mais tempo que query_monitor_long_running_query_ms. |
| query_monitor_long_running_query_time_ms | 30.000 | Aciona um alarme se uma consulta for executada por mais tempo que query_monitor_long_running_query_ms. O valor mínimo é 1000. |
| query_monitor_long_running_query_matching_info | Faça corresponder apenas consultas com um 'Info' que corresponda apenas a esta regex POSIX. Nenhum valor padrão, corresponde a qualquer informação. | |
| query_monitor_long_running_query_matching_info_negate | falso | Negar o resultado de query_monitor_long_running_query_matching_info. |
| query_monitor_long_running_query_matching_host | Faça corresponder apenas consultas com um 'Host' que corresponda apenas a esta regex POSIX. Nenhum valor padrão, corresponde a qualquer Host. | |
| query_monitor_long_running_query_matching_db | Faça corresponder apenas consultas com um 'Db' que corresponda apenas a esta regex POSIX. Nenhum valor padrão, corresponde a qualquer Db. | |
| query_monitor_long_running_query_matching_user | Faça corresponder apenas consultas com um 'Usuário' que corresponda apenas a esta regex POSIX. Nenhum valor padrão, corresponde a qualquer usuário. | |
| query_monitor_long_running_query_matching_user_negate | falso | Negar o resultado de query_monitor_long_running_query_matching_user. |
| query_monitor_long_running_query_matching_command | Consulta | Faça corresponder apenas consultas com um 'Comando' que corresponda apenas a esta regex POSIX. O padrão é 'Consulta'. |
Replicação
| Nome | Valor padrão | Descrição |
|---|---|---|
| max_replication_lag | 10 | Máximo de atraso de replicação permitido em segundos antes de enviar um alarme. |
| replication_stop_on_error | verdadeiro | Controla se os procedimentos de failover/switchover devem falhar se forem encontrados erros que possam causar perda de dados. |
| replication_auto_rebuild_slave | falso | Se o SQL THREAD for interrompido e o código de erro for diferente de zero, o escravo será reconstruído automaticamente. |
| replication_failover_blacklist | Lista separada por vírgulas de nomes de host:pares de portas. Os servidores na lista negra não serão considerados candidatos durante o failover. A replicação_failover_blacklist será ignorada se a replicação_failover_whitelist estiver definida. | |
| replication_failover_whitelist | Lista separada por vírgulas de nomes de host:pares de portas. Somente servidores na lista de permissões serão considerados candidatos durante o failover. Se nenhum servidor na lista branca estiver disponível (ativo/conectado), o failover falhará. A replicação_failover_blacklist será ignorada se a replicação_failover_whitelist estiver definida. | |
| replication_onfail_failover_script | Este script é executado assim que for descoberto que o failover é necessário. Se o script retornar diferente de zero ou não existir, o failover será abortado. Quatro argumentos são fornecidos ao script e definidos se forem conhecidos, senão vazio:arg1='all servers' arg2='failed master' arg3='selected candidate', arg4='slaves of oldmaster (the candidate)' e passados como this:'scripname arg1 arg2 arg3 arg4' O script deve ser acessível no controlador e executável. | |
| replication_pre_failover_script | Este script é executado antes do failover, mas após a eleição de um candidato e é possível continuar o processo de failover. Se o script retornar diferente de zero ou não existir, o failover será abortado. Quatro argumentos são fornecidos ao script e definidos se forem conhecidos, senão vazio:arg1='all servers' arg2='failed master' arg3='selected candidate', arg4='slaves of oldmaster (the candidate)' e passados como this:'scripname arg1 arg2 arg3 arg4' O script deve ser acessível no controlador e executável. | |
| replication_post_failover_script | Este script é executado após o failover acontecer (um novo mestre é eleito e está funcionando). Se o script retornar diferente de zero ou não existir, o failover será abortado. Quatro argumentos são fornecidos ao script e definidos se forem conhecidos, senão vazio.:arg1='todos os servidores' arg2='mestre falhou' arg3='candidato selecionado', arg4='escravos do antigo mestre (os candidatos)' e passou assim:'scripname arg1 arg2 arg3 arg4' O script deve ser acessível no controlador e executável. | |
| replication_post_unsuccessful_failover_script | Este script é executado se a tentativa de failover falhar. Se o script retornar diferente de zero ou não existir, o failover será abortado. Quatro argumentos são fornecidos ao script e definidos se forem conhecidos, senão vazio.:arg1='todos os servidores' arg2='mestre falhou' arg3='candidato selecionado', arg4='escravos do antigo mestre (os candidatos)' e passou assim:'scripname arg1 arg2 arg3 arg4' O script deve ser acessível no controlador e executável. |
Retenção
| Nome | Valor padrão | Descrição |
|---|---|---|
| ops_report_retention | 31 | A configuração de quantos dias manter os relatórios operacionais. Os relatórios correspondentes ao período de retenção são removidos. |
Amostragem
| Nome | Valor padrão | Descrição |
|---|---|---|
| enable_icmp_ping | verdadeiro | Alterna se o ClusterControl deve medir os tempos de ping ICMP para o host. |
| host_stats_collection_interval | 30 | Configuração do intervalo de coleta do host (CPU, memória, etc.). |
| host_stats_window_size | 180 | Configurando o tamanho da janela (em segundos) para examinar as estatísticas para aumentar/limpar alarmes de estatísticas do host. |
| db_stats_collection_interval | 30 | Configuração do intervalo de coleta de estatísticas do banco de dados. |
| db_proc_stats_collection_interval | 5 | Configuração do intervalo de coleta de estatísticas do processo do banco de dados. O valor mínimo permitido é 1 segundo. Requer uma reinicialização do serviço cmon. |
| lb_stats_collection_interval | 15 | Configuração do intervalo de coleta de estatísticas do balanceador de carga. |
| db_schema_stats_collection_interval | 108000 | Configuração do intervalo de monitoramento de estatísticas do esquema. |
| db_deadlock_check_interval | 0 | Com que frequência verificar impasses. Especificado em segundos. A detecção de deadlock afetará o uso da CPU nos nós do banco de dados. |
| log_collection_interval | 600 | Controla o intervalo entre as coleções de arquivos de log. |
| db_hourly_stats_collection_interval | 5 | Controla quantos segundos há entre cada amostra individual nas estatísticas de intervalo de hora. |
| monitored_mountpoints | A lista de pontos de montagem a serem monitorados. | |
| monitor_cpu_temperature | falso | Monitore a temperatura da CPU. |
| log_queries_not_using_indexes | falso | Defina o monitor de consulta para detectar consultas que não usam índices. |
| query_sample_interval | 1 | Controla o intervalo do monitor de consulta em segundos, -1 significa que não há monitoramento de consulta. |
| query_monitor_auto_purge_ps | falso | Se habilitada, a tabela P_S events_statements_summary_by_digest será removida automaticamente (TRUNCATE TABLE) a cada hora. |
| schema_change_detection_address | As verificações serão executadas (usando SHOW TABLES/SHOW CREATE TABLE) para determinar se o esquema foi alterado. As verificações são executadas no endereço especificado e estão no formato HOSTNAME:PORT. Os schema_change_detection_databases também devem ser configurados. Um diff de uma tabela alterada é criado. | |
| schema_change_detection_databases | Lista separada por vírgulas de bancos de dados para monitorar alterações de esquema. Se estiver vazio, nenhuma verificação é feita. | |
| schema_change_detection_pause_time_ms | 0 | Tempo de pausa em ms entre cada SHOW CREATE TABLE. O tempo de pausa afetará a duração do processo de detecção. |
| enable_is_queries | verdadeiro | Especifica se as consultas ao information_schema serão executadas ou não. As consultas ao information_schema podem não ser adequadas quando há muitos objetos de esquema (100s de bancos de dados, 100s de tabelas em cada banco de dados, gatilhos, usuários, eventos, sprocs). Se desabilitada, a consulta que seria executada será registrada para que se possa determinar se a consulta é adequada ao seu ambiente. |
Trocando
| Nome | Valor padrão | Descrição |
|---|---|---|
| swap_warning | 20 | Limite de alarme de aviso para uso de troca. |
| swap_critical | 90 | Limite crítico de alarme para uso de troca. |
| swap_inout_period | 0 | O intervalo para alarmes de E/S de troca (<=0 desabilita). |
| swap_inout_warning | 10240 | O número de páginas trocadas de E/S no intervalo especificado (swap_inout_period, por padrão 10 minutos) para aviso. |
| swap_inout_critical | 102400 | O número de páginas trocadas de E/S no intervalo especificado (swap_inout_period, por padrão 10 minutos) para crítico. |
Sistema
| Nome | Valor padrão | Descrição |
|---|---|---|
| cmon_config_path | /etc/cmon.d/cmon_x.cnf | O caminho do arquivo de configuração. Este valor de configuração é somente leitura. |
| os | debian/redhat | O tipo de SO. Os valores possíveis são 'debian' ou 'redhat'. |
| libssh_timeout | 30 | O valor de tempo limite da rede para conexões SSH. |
| sudo | sudo -n 2>/dev/null | O comando usado para obter privilégios de superusuário. |
| ssh_port | 22 | A porta para conexões SSH com os nós. |
| local_repo_name | Os nomes de repositórios locais usados para implantação de cluster. | |
| url_frontend | A URL enviada nos e-mails para direcionar o destinatário à interface web do ClusterControl. | |
| limpar | 7 | Por quanto tempo o ClusterControl deve manter os dados. Medido em dias, trabalhos, mensagens de trabalho, alarmes, logs coletados, relatórios operacionais, informações de crescimento do banco de dados mais antigas que isso serão excluídas. |
| os_user_home | /home/usuário | O diretório HOME do usuário usado nos nós. |
| cmon_mail_sender | O remetente de e-mail usado para e-mails enviados. | |
| plugin_dir | O caminho do diretório de plugins. | |
| use_internal_repos | falso | Configuração que desabilitou o repositório de terceiros a ser configurado. |
| cmon_use_mail | falso | Configuração para usar o comando 'mail' para envio de e-mail. |
| enable_html_emails | verdadeiro | Ativa o envio de emails HTML. |
| send_clear_alarm | verdadeiro | Alterna o envio de e-mail no caso de alarmes de cluster serem apagados. |
| software_packagedir | Este é o local de armazenamento dos pacotes de software, ou seja, todos os arquivos necessários para instalar um nó com sucesso, caso não haja repositório yum/apt disponível, devem ser colocados aqui. Aplica-se principalmente ao MySQL Cluster ou a instalações mais antigas do Codership/Galera. |
Limite
| Nome | Valor padrão | Descrição |
|---|---|---|
| ram_warning | 80 | Limite de alarme de aviso para uso de RAM. |
| ram_critical | 90 | Limite crítico de alarme para uso de RAM. |
| diskspace_warning | 80 | Limite de alarme de aviso para uso do disco. |
| diskspace_critical | 90 | Limite crítico de alarme para uso do disco. |
| cpu_warning | 80 | Limite de alarme de aviso para uso da CPU. |
| cpu_critical | 90 | Limite crítico de alarme para uso da CPU. |
| cpu_steal_warning | 10 | Limite de alarme de aviso para roubo de CPU. |
| cpu_steal_critical | 20 | Limite crítico de alarme para roubo de CPU. |
| cpu_iowait_warning | 50 | Limite de alarme de aviso para CPU IO Wait. |
| cpu_iowait_critical | 60 | Limite crítico de alarme para CPU IO Wait. |
| slow_ssh_warning | 6 | Um alarme de Aviso será acionado se demorar mais do que o tempo especificado para configurar uma conexão SSH (segundos). |
| slow_ssh_critical | 12 | Um alarme Crítico será gerado se demorar mais do que o tempo especificado para configurar uma conexão SSH (segundos). |
Conclusão
Como você pode ver, há muitos parâmetros a serem alterados se você precisar adaptar o ClusterControl à sua carga de trabalho ou negócio. Pode ser uma tarefa demorada revisar todos os valores e alterá-los de acordo, mas no final do dia, economizará tempo, pois você poderá aproveitar ao máximo todos os recursos do ClusterControl.



