O ClusterControl é programado com vários algoritmos de recuperação para responder automaticamente a diferentes tipos de falhas comuns que afetam seus sistemas de banco de dados. Ele compreende diferentes tipos de topologias de banco de dados e gerenciamento de processos relacionados ao banco de dados para ajudá-lo a determinar a melhor maneira de recuperar o cluster. De certa forma, o ClusterControl melhora a disponibilidade do seu banco de dados.
Alguns gerenciadores de topologia cobrem apenas a recuperação de cluster como MHA, Orchestrator e mysqlfailover, mas você tem que lidar com a recuperação do nó por conta própria. O ClusterControl oferece suporte à recuperação em nível de cluster e nó.
Opções de configuração
Existem dois componentes de recuperação suportados pelo ClusterControl, a saber:
- Cluster - Tentativa de recuperar um cluster para um estado operacional
- Nó - Tentativa de recuperar um nó para um estado operacional
Esses dois componentes são os mais importantes para garantir que a disponibilidade do serviço seja a mais alta possível. Se você já tem um gerenciador de topologia sobre o ClusterControl, você pode desabilitar o recurso de recuperação automática e deixar que outro gerenciador de topologia cuide disso para você. Você tem todas as possibilidades com o ClusterControl.
O recurso de recuperação automática pode ser habilitado e desabilitado com uma simples alternância de LIGADO/DESLIGADO e funciona para recuperação de cluster ou nó. Os ícones verdes significam habilitados e os ícones vermelhos significam desabilitados. A captura de tela a seguir mostra onde você pode encontrá-lo na lista de clusters de banco de dados:
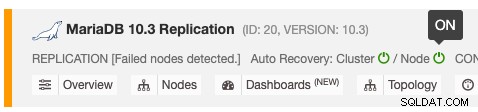
Existem 3 parâmetros ClusterControl que podem ser usados para controlar o comportamento de recuperação. Todos os parâmetros são padrão para true (definidos com inteiro booleano 0 ou 1):
- enable_autorecovery - Ativa a recuperação de cluster e nó. Este parâmetro é o superconjunto de enable_cluster_recovery e enable_node_recovery. Se estiver definido como 0, os parâmetros do subconjunto serão desativados.
- enable_cluster_recovery - O ClusterControl realizará a recuperação do cluster se ativado.
- enable_node_recovery - O ClusterControl realizará a recuperação do nó se ativado.
A recuperação de cluster abrange a tentativa de recuperação de trazer a topologia de cluster inteira. Por exemplo, uma replicação mestre-escravo deve ter pelo menos um mestre ativo em um determinado momento, independentemente do número de escravos disponíveis. O ClusterControl tenta corrigir a topologia pelo menos uma vez para clusters de replicação, mas infinitamente para replicação multimestre como NDB Cluster e Galera Cluster.
A recuperação do nó cobre o problema de recuperação do nó, como se um nó estivesse sendo interrompido sem o conhecimento do ClusterControl, por exemplo, por meio do comando de parada do sistema do console SSH ou sendo eliminado pelo processo OOM.
Recuperação de nós
O ClusterControl é capaz de recuperar um nó de banco de dados em caso de falha intermitente, monitorando o processo e a conectividade com os nós do banco de dados. Para o processo, ele funciona de maneira semelhante ao systemd, onde garantirá que o serviço MySQL seja iniciado e executado, a menos que você o tenha interrompido intencionalmente por meio da interface do usuário do ClusterControl.
Se o nó voltar a ficar online, o ClusterControl estabelecerá uma conexão de volta com o nó do banco de dados e executará as ações necessárias. Veja a seguir o que o ClusterControl faria para recuperar um nó:
- Ele aguardará o systemd/chkconfig/init iniciar os serviços/processos monitorados por 30 segundos
- Se os serviços/processos monitorados ainda estiverem inativos, o ClusterControl tentará iniciar o serviço de banco de dados automaticamente.
- Se o ClusterControl não conseguir recuperar os serviços/processos monitorados, um alarme será acionado.
Observe que, se um desligamento do banco de dados for iniciado pelo usuário, o ClusterControl não tentará recuperar o nó específico. Ele espera que o usuário o inicie novamente por meio da interface do usuário do ClusterControl indo para Nó -> Ações do nó -> Iniciar Nó ou use o comando do SO explicitamente.
A recuperação inclui todos os serviços relacionados ao banco de dados, como ProxySQL, HAProxy, MaxScale, Keepalived, exportadores Prometheus e garbd. Atenção especial aos exportadores do Prometheus onde o ClusterControl usa um programa chamado "daemon" para daemonizar o processo do exportador. O ClusterControl tentará se conectar à porta de escuta do exportador para verificação e verificação de integridade. Assim, é recomendável abrir as portas do exportador do servidor ClusterControl e Prometheus para garantir que não haja alarmes falsos durante a recuperação.
Recuperação de cluster
O ClusterControl entende a topologia do banco de dados e segue as práticas recomendadas na execução da recuperação. Para um cluster de banco de dados que vem com tolerância a falhas integrada, como Galera Cluster, NDB Cluster e MongoDB Replicaset, o processo de failover será executado automaticamente pelo servidor de banco de dados por meio de cálculo de quorum, heartbeat e alternância de função (se houver). O ClusterControl monitora o processo e faz os ajustes necessários na visualização, como refletir as alterações na visualização Topologia e ajustar o componente de monitoramento e gerenciamento para a nova função, por exemplo, novo nó primário em um conjunto de réplicas.
Para tecnologias de banco de dados que não possuem tolerância a falhas integrada com recuperação automática como MySQL/MariaDB Replication e PostgreSQL/TimescaleDB Streaming Replication, o ClusterControl realizará os procedimentos de recuperação seguindo as melhores práticas fornecidas pelo fornecedor de banco de dados. Se a recuperação falhar, é necessária a intervenção do usuário e, é claro, você receberá uma notificação de alarme sobre isso.
Em uma topologia mista/híbrida, por exemplo, um escravo assíncrono que está conectado a um Galera Cluster ou NDB Cluster, o nó será recuperado pelo ClusterControl se a recuperação do cluster estiver habilitada.
A recuperação de cluster não se aplica ao servidor MySQL autônomo. No entanto, é recomendável ativar as recuperações de nó e cluster para esse tipo de cluster na interface do usuário do ClusterControl.
Replicação MySQL/MariaDB
ClusterControl suporta a recuperação da seguinte configuração de replicação MySQL/MariaDB:
- Mestre-escravo com MySQL GTID
- Mestre-escravo com MariaDB GTID
- Mestre-escravo sem GTID (ambos MySQL e MariaDB)
- Mestre-mestre com MySQL GTID
- Mestre-mestre com MariaDB GTID
- Escravo assíncrono anexado a um Galera Cluster
ClusterControl respeitará os seguintes parâmetros ao realizar a recuperação do cluster:
- enable_cluster_autorecovery
- auto_manage_readonly
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- replication_post_failover_script
- replication_post_switchover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_pre_switchover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
Para obter mais detalhes sobre cada parâmetro, consulte a página de documentação.
O ClusterControl obedecerá às seguintes regras ao monitorar e gerenciar uma replicação mestre-escravo:
- Todos os nós serão iniciados com read_only=ON e super_read_only=ON (independentemente de sua função).
- Apenas um mestre (read_only=OFF) pode operar a qualquer momento.
- Confie na variável MySQL report_host para mapear a topologia.
- Se houver dois ou mais nós que tenham read_only=OFF por vez, o ClusterControl definirá automaticamente read_only=ON em ambos os mestres, para protegê-los contra gravações acidentais. A intervenção do usuário é necessária para escolher o mestre real desabilitando o somente leitura. Vá para Nós -> Ações do nó -> Desativar somente leitura.
Caso o mestre ativo fique inativo, o ClusterControl tentará realizar o failover do mestre na seguinte ordem:
- Após 3 segundos de inacessibilidade do mestre, o ClusterControl acionará um alarme.
- Verifique a disponibilidade do escravo, pelo menos um dos escravos deve ser acessível pelo ClusterControl.
- Escolha o escravo como candidato a mestre.
- O ClusterControl calculará a probabilidade de transações errôneas se o GTID estiver ativado.
- Se nenhuma transação errônea for detectada, o escolhido será promovido como o novo mestre.
- Criar e conceder usuário de replicação para ser usado por escravos.
- Altere o mestre de todos os escravos que apontavam para o antigo mestre para o mestre recém-promovido.
- Inicie o slave e ative somente leitura.
- Libere os logs em todos os nós.
- Se a promoção do escravo falhar, o ClusterControl abortará o trabalho de recuperação. A intervenção do usuário ou uma reinicialização do serviço cmon é necessária para acionar o trabalho de recuperação novamente.
- Quando o mestre antigo estiver disponível novamente, ele será iniciado como somente leitura e não fará parte da replicação. A intervenção do usuário é necessária.
Ao mesmo tempo, os seguintes alarmes serão acionados:
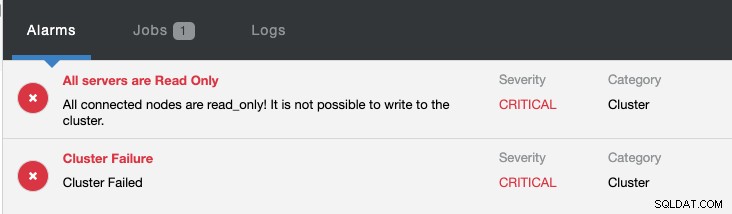
Confira Introduction to Failover for MySQL Replication - the 101 Blog and Automatic Failover of MySQL Replication - New in ClusterControl 1.4 para obter mais informações sobre como configurar e gerenciar o failover de replicação MySQL com ClusterControl.
Replicação de streaming PostgreSQL/TimescaleDB
O ClusterControl oferece suporte à recuperação da seguinte configuração de replicação do PostgreSQL:
- Replicação de streaming do PostgreSQL
- Replicação de streaming do TimescaleDB
ClusterControl respeitará os seguintes parâmetros ao realizar a recuperação do cluster:
- enable_cluster_autorecovery
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_failover_whitelist
- replication_failover_blacklist
Para obter mais detalhes sobre cada parâmetro, consulte a página de documentação.
O ClusterControl obedecerá às seguintes regras para gerenciar e monitorar uma configuração de replicação de streaming do PostgreSQL:
- wal_level está definido como "replica" (ou "hot_standby" dependendo da versão do PostgreSQL).
- A variável archive_mode está definida como ATIVA no mestre.
- Defina o arquivo recovery.conf nos nós escravos, o que transforma o nó em um hot standby com somente leitura habilitado.
Caso o mestre ativo fique inativo, o ClusterControl tentará realizar a recuperação do cluster na seguinte ordem:
- Após 10 segundos de inacessibilidade do mestre, o ClusterControl acionará um alarme.
- Após 10 segundos de tempo limite de espera normal, o ClusterControl iniciará o trabalho de failover mestre.
- Experimente o replayLocation e o receiveLocation em todos os nós disponíveis para determinar o nó mais avançado.
- Promova o nó mais avançado como o novo mestre.
- Parar escravos.
- Verifique o estado de sincronização com pg_rewind.
- Reiniciando slaves com o novo master.
- Se a promoção do escravo falhar, o ClusterControl abortará o trabalho de recuperação. A intervenção do usuário ou uma reinicialização do serviço cmon é necessária para acionar o trabalho de recuperação novamente.
- Quando o mestre antigo estiver disponível novamente, ele será forçado a encerrar e não fará parte da replicação. A intervenção do usuário é necessária. Veja mais abaixo.
Quando o antigo mestre voltar a ficar online, se o serviço PostgreSQL estiver em execução, o ClusterControl forçará o desligamento do serviço PostgreSQL. Isso é para proteger o servidor de gravações acidentais, pois ele seria iniciado sem um arquivo de recuperação (recovery.conf), o que significa que seria gravável. Você deve esperar que as seguintes linhas apareçam em postgresql-{day}.log:
2019-11-27 05:06:10.091 UTC [2392] LOG: database system is ready to accept connections
2019-11-27 05:06:27.696 UTC [2392] LOG: received fast shutdown request
2019-11-27 05:06:27.700 UTC [2392] LOG: aborting any active transactions
2019-11-27 05:06:27.703 UTC [2766] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.704 UTC [2758] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.709 UTC [2392] LOG: background worker "logical replication launcher" (PID 2419) exited with exit code 1
2019-11-27 05:06:27.709 UTC [2414] LOG: shutting down
2019-11-27 05:06:27.735 UTC [2392] LOG: database system is shut downO PostgreSQL foi iniciado depois que o servidor voltou a ficar online por volta das 05:06:10, mas o ClusterControl executa um desligamento rápido 17 segundos depois disso, por volta das 05:06:27. Se isso for algo que você não gostaria que fosse, você pode desabilitar a recuperação de nó para este cluster momentaneamente.
Confira Failover Automático de Replicação Postgres e Failover para Replicação PostgreSQL 101 para obter mais informações sobre como configurar e gerenciar failover de replicação PostgreSQL com ClusterControl.
Conclusão
A recuperação automática do ClusterControl compreende a topologia de cluster de banco de dados e é capaz de recuperar um cluster inativo ou degradado para um cluster totalmente operacional, o que melhorará tremendamente o tempo de atividade do serviço de banco de dados. Experimente o ClusterControl agora e alcance seus noves em SLA e disponibilidade de banco de dados. Não sabe seus noves? Confira esta calculadora de noves legal.



