O desempenho do banco de dados afeta o desempenho organizacional e tendemos a procurar uma solução rápida. Existem muitos caminhos diferentes para melhorar o desempenho no MongoDB. Neste blog, ajudaremos você a entender melhor a carga de trabalho do seu banco de dados e as coisas que podem causar danos a ele. O conhecimento de como usar recursos limitados é essencial para qualquer pessoa que gerencia um banco de dados de produção.
Mostraremos como identificar os fatores que limitam o desempenho do banco de dados. Para garantir que o banco de dados funcione conforme o esperado, começaremos com a ferramenta gratuita de monitoramento MongoDB Cloud. Em seguida, verificaremos como gerenciar arquivos de log e como examinar consultas. Para obter o uso ideal dos recursos de hardware, examinaremos a otimização do kernel e outras configurações cruciais do sistema operacional. Por fim, examinaremos a replicação do MongoDB e como examinar o desempenho.
Monitoramento gratuito de desempenho
O MongoDB introduziu uma ferramenta gratuita de monitoramento de desempenho na nuvem para instâncias independentes e conjuntos de réplicas. Quando ativado, os dados monitorados são carregados periodicamente no serviço de nuvem do fornecedor. Isso não requer nenhum agente adicional, a funcionalidade é incorporada ao novo MongoDB 4.0+. O processo é bastante simples de configurar e gerenciar. Após a ativação do comando único, você receberá um endereço da Web exclusivo para acessar suas estatísticas de desempenho recentes. Você só pode acessar dados monitorados que foram carregados nas últimas 24 horas.
Veja como ativar esse recurso. Você pode ativar/desativar o monitoramento gratuito durante o tempo de execução usando:
-- Enable Free Monitoring
db.enableFreeMonitoring()
-- Disable Free Monitoring
db.disableFreeMonitoring()Você também pode ativar ou desativar o monitoramento gratuito durante a inicialização do mongod usando a configuração do arquivo de configuração cloud.monitoring.free.state ou a opção de linha de comando --enableFreeMonitoring
db.enableFreeMonitoring()Após a ativação, você verá uma mensagem com o status real.
{
"state" : "enabled",
"message" : "To see your monitoring data, navigate to the unique URL below. Anyone you share the URL with will also be able to view this page. You can disable monitoring at any time by running db.disableFreeMonitoring().",
"url" : "https://cloud.mongodb.com/freemonitoring/cluster/XEARVO6RB2OTXEAHKHLKJ5V6KV3FAM6B",
"userReminder" : "",
"ok" : 1
}Basta copiar/colar o URL da saída de status para o navegador e você pode começar a verificar as métricas de desempenho.
O monitoramento MongoDB Free fornece informações sobre as seguintes métricas:
- Tempos de execução da operação (LER, ESCREVER, COMANDOS)
- Utilização do disco (% UTIL MÁXIMA DE QUALQUER UNIDADE, % UTIL MÉDIA DE TODAS AS UNIDADES)
- Memória (RESIDENTE, VIRTUAL, MAPEADA)
- Rede - Entrada/Saída (BYTES IN, BYTES OUT)
- Rede - Número de solicitações (NUM REQUESTS)
- Opcounters (INSERT, QUERY, UPDATE, DELETE, GETMORE, COMMAND)
- Opcounters - Replicação (INSERT, QUERY, UPDATE, DELETE, GETMORE, COMMAND)
- Segmentação de consulta (VERIFICADA/RETORNADA, OBJETOS VERIFICADOS/RETORNADA)
- Filas (LEITORES, ESCRITORES, TOTAL)
- Uso de CPU do sistema (USER, NICE, KERNEL, IOWAIT, IRQ, SOFT IRQ, STEAL, GUEST)
 MongoDB Free Monitoring primeiro uso
MongoDB Free Monitoring primeiro uso  MongoDB Free Monitoring System CPU Uso
MongoDB Free Monitoring System CPU Uso 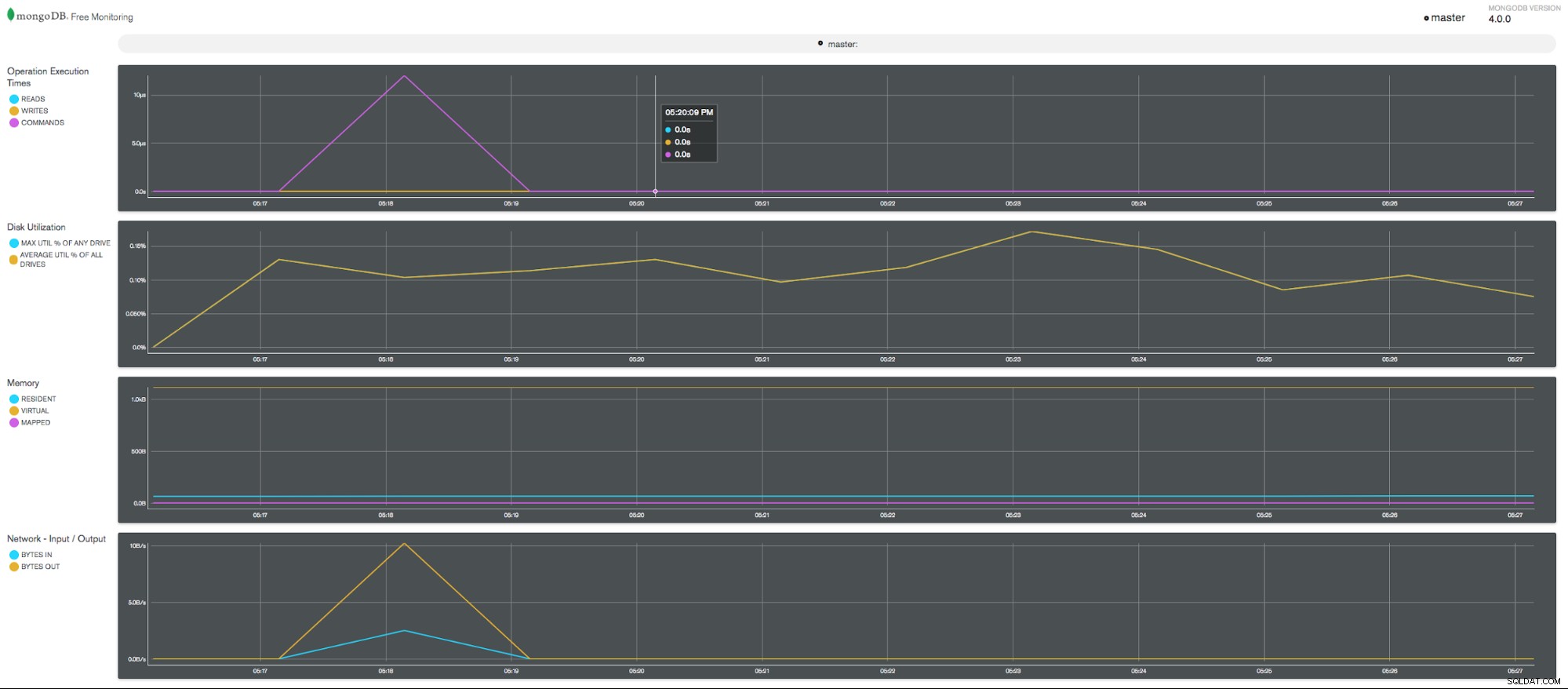 MongoDB Free Monitoring Charts
MongoDB Free Monitoring Charts Para visualizar o estado do seu serviço de monitoramento gratuito, use o seguinte método:
db.getFreeMonitoringStatus()O serverStatus e o auxiliar db.serverStatus() também incluem estatísticas de monitoramento gratuito no campo Monitoramento gratuito.
Ao executar com controle de acesso, o usuário deve ter os seguintes privilégios para habilitar o monitoramento gratuito e obter status:
{ resource: { cluster : true }, actions: [ "setFreeMonitoring", "checkFreeMonitoringStatus" ] }Essa ferramenta pode ser um bom começo para aqueles que acham difícil ler a saída de status do servidor MongoDB na linha de comando:
db.serverStatus()O Free Monitoring é um bom começo, mas tem opções muito limitadas, se você precisar de uma ferramenta mais avançada, verifique o MongoDB Ops Manager ou o ClusterControl.
Registrando operações do banco de dados
Drivers MongoDB e aplicativos cliente podem enviar informações para o arquivo de log do servidor. Essas informações dependem do tipo do evento. Para verificar as configurações atuais, faça login como administrador e execute:
db.getLogComponents()As mensagens de log incluem muitos componentes. Isso é para fornecer uma categorização funcional das mensagens. Para cada componente, você pode definir um detalhamento de log diferente. A lista atual de componentes é:
ACCESS, COMMAND, CONTROL, FTD, GEO, INDEX, NETWORK, QUERY, REPL_HB, REPL, ROLLBACK, REPL, SHARDING, STORAGE, RECOVERY, JOURNAL, STORAGE, WRITE.Para mais detalhes sobre cada um dos componentes, consulte a documentação.
Capturando consultas - Criador de perfil de banco de dados
O MongoDB Database Profiler coleta informações sobre operações executadas em uma instância do mongod. Por padrão, o criador de perfil não coleta nenhum dado. Você pode optar por coletar todas as operações (valor 2) ou aquelas que demoram mais do que o valor de slowms . Este último é um parâmetro de instância que pode ser controlado através do arquivo de configuração do mongodb. Para verificar o nível atual:
db.getProfilingLevel()Para capturar todas as consultas definidas:
db.setProfilingLevel(2)No arquivo de configuração, você pode definir:
profile = <0/1/2>
slowms = <value>Essa configuração será aplicada em uma única instância e não será propagada em um conjunto de réplicas ou cluster compartilhado, portanto, você precisa repetir esse comando de todos os nós se desejar capturar todas as atividades. A criação de perfil do banco de dados pode afetar o desempenho do banco de dados. Habilite esta opção somente após uma análise cuidadosa.
Então, para listar os 10 mais recentes:
db.system.profile.find().limit(10).sort(
{ ts : -1 }
).pretty()Para listar todos:
db.system.profile.find( { op:
{ $ne : 'command' }
} ).pretty()E para listar para uma coleção específica:
db.system.profile.find(
{ ns : 'mydb.test' }
).pretty()Registro do MongoDB
O local do log do MongoDB é definido na configuração do caminho de log da sua configuração e geralmente é /var/log/mongodb/mongod.log. Você pode encontrar o arquivo de configuração do MongoDB em /etc/mongod.conf.
Aqui estão os dados de exemplo:
2018-07-01T23:09:27.101+0000 I ASIO [NetworkInterfaceASIO-Replication-0] Connecting to node1:27017
2018-07-01T23:09:27.102+0000 I ASIO [NetworkInterfaceASIO-Replication-0] Failed to connect to node1:27017 - HostUnreachable: Connection refused
2018-07-01T23:09:27.102+0000 I ASIO [NetworkInterfaceASIO-Replication-0] Dropping all pooled connections to node1:27017 due to failed operation on a connection
2018-07-01T23:09:27.102+0000 I REPL_HB [replexec-2] Error in heartbeat (requestId: 21589) to node1:27017, response status: HostUnreachable: Connection refused
2018-07-01T23:09:27.102+0000 I ASIO [NetworkInterfaceASIO-Replication-0] Connecting to node1:27017Você pode modificar o detalhamento do log do componente definindo (exemplo de consulta):
db.setLogLevel(2, "query")O arquivo de log pode ser significativo, portanto, você pode limpá-lo antes da criação de perfil. No console de linha de comando do MongoDB, digite:
db.runCommand({ logRotate : 1 });Verificando os parâmetros do sistema operacional
Limites de memória
Para ver os limites associados ao seu login, use o comando ulimit -a. Os seguintes limites e configurações são particularmente importantes para implantações de mongod e mongos:
-f (file size): unlimited
-t (cpu time): unlimited
-v (virtual memory): unlimited
-n (open files): 64000
-m (memory size): unlimited [1]
-u (processes/threads): 32000A versão mais recente do script de inicialização do mongod (/etc/init.d/mongod) tem as configurações padrão incorporadas à opção de inicialização:
start()
{
# Make sure the default pidfile directory exists
if [ ! -d $PIDDIR ]; then
install -d -m 0755 -o $MONGO_USER -g $MONGO_GROUP $PIDDIR
fi
# Make sure the pidfile does not exist
if [ -f "$PIDFILEPATH" ]; then
echo "Error starting mongod. $PIDFILEPATH exists."
RETVAL=1
return
fi
# Recommended ulimit values for mongod or mongos
# See https://docs.mongodb.org/manual/reference/ulimit/#recommended-settings
#
ulimit -f unlimited
ulimit -t unlimited
ulimit -v unlimited
ulimit -n 64000
ulimit -m unlimited
ulimit -u 64000
ulimit -l unlimited
echo -n $"Starting mongod: "
daemon --user "$MONGO_USER" --check $mongod "$NUMACTL $mongod $OPTIONS >/dev/null 2>&1"
RETVAL=$?
echo
[ $RETVAL -eq 0 ] && touch /var/lock/subsys/mongod
}A função do subsistema de gerenciamento de memória, também chamado de gerenciador de memória virtual, é gerenciar a alocação de memória física (RAM) para todo o kernel e programas de usuário. Isso é controlado pelos parâmetros vm.*. Há dois que você deve considerar em primeiro lugar para ajustar o desempenho do MongoDB - vm.dirty_ratio e vm.dirty_background_ratio .
vm.dirty_ratio é a quantidade máxima absoluta de memória do sistema que pode ser preenchida com páginas sujas antes que tudo seja confirmado no disco. Quando o sistema chega a esse ponto, todos os novos blocos de E/S até que as páginas sujas sejam gravadas no disco. Isso geralmente é a fonte de longas pausas de E/S. O padrão é 30, que geralmente é muito alto. vm.dirty_background_ratio é a porcentagem de memória do sistema que pode ser preenchida com páginas “sujas” — páginas de memória que ainda precisam ser gravadas no disco. O bom começo é partir do 10 e medir o desempenho. Para um ambiente com pouca memória, 20 é um bom começo. Uma configuração recomendada para proporções sujas em servidores de banco de dados de memória grande é vm.dirty_ratio =15 e vm.dirty_background_ratio =5 ou possivelmente menos.
Para verificar a relação suja, execute:
sysctl -a | grep dirtyVocê pode definir isso adicionando as seguintes linhas a “/etc/sysctl.conf”:
Troca
Em servidores onde o MongoDB é o único serviço em execução, é uma boa prática definir vm.swapiness =1. A configuração padrão é definida como 60, o que não é apropriado para um sistema de banco de dados.
vi /etc/sysctl.conf
vm.swappiness = 1Páginas enormes transparentes
Se você estiver executando seu MongoDB no RedHat, certifique-se de que Transparent Huge Pages esteja desabilitado.
Isso pode ser verificado pelo comando:
cat /proc/sys/vm/nr_hugepages
00 significa que as páginas transparentes enormes estão desabilitadas.
Opções do sistema de arquivos
ext4 rw,seclabel,noatime,data=ordered 0 0NUMA (Acesso Não Uniforme à Memória)
O MongoDB não suporta NUMA, desative-o no BIOS.
Pilha de rede
net.core.somaxconn = 4096
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_time = 120
net.ipv4.tcp_max_syn_backlog = 4096Demônio NTP
Para instalar o demônio do servidor de horário NTP, use um dos seguintes comandos do sistema.
#Red Hat
sudo yum install ntp
#Debian
sudo apt-get install ntpVocê pode encontrar mais detalhes sobre o desempenho do SO para MongoDB em outro blog.
Explique o plano
Semelhante a outros sistemas de banco de dados populares, o MongoDB fornece um recurso de explicação que revela como uma operação de banco de dados foi executada. Os resultados de explicação exibem os planos de consulta como uma árvore de estágios. Cada estágio passa seus eventos (ou seja, documentos ou chaves de índice) para o nó pai. Os nós folha acessam a coleção ou os índices. Você pode adicionar explain('executionStats') a uma consulta.
db.inventory.find( {
status: "A",
$or: [ { qty: { $lt: 30 } }, { item: /^p/ } ]
} ).explain('executionStats');
or append it to the collection:
db.inventory.explain('executionStats').find( {
status: "A",
$or: [ { qty: { $lt: 30 } }, { item: /^p/ } ]
} );As chaves cujos valores você deve observar na saída da execução do comando acima:
- totalKeysExamined:o número total de entradas de índice verificadas para retornar a consulta.
- totalDocsExamined:o número total de documentos digitalizados para encontrar os resultados.
- executionTimeMillis:tempo total em milissegundos necessário para a seleção do plano de consulta e execução da consulta.
Medindo o desempenho do atraso de replicação
O atraso de replicação é um atraso entre uma operação no primário e a aplicação dessa operação do oplog para o secundário. Em outras palavras, define o quanto o secundário está atrás do nó primário, que no melhor cenário, deve estar o mais próximo possível de 0.
O processo de replicação pode ser afetado por vários motivos. Um dos principais problemas pode ser que os membros secundários estejam ficando sem capacidade do servidor. Grandes operações de gravação no membro primário que fazem com que os membros secundários não consigam reproduzir os oplogs ou que o índice seja construído no membro primário.
Para verificar o atraso de replicação atual, execute em um shell do MongoDB:
db.getReplicationInfo()
db.getReplicationInfo()
{
"logSizeMB" : 2157.1845703125,
"usedMB" : 0.05,
"timeDiff" : 4787,
"timeDiffHours" : 1.33,
"tFirst" : "Sun Jul 01 2018 21:40:32 GMT+0000 (UTC)",
"tLast" : "Sun Jul 01 2018 23:00:19 GMT+0000 (UTC)",
"now" : "Sun Jul 01 2018 23:00:26 GMT+0000 (UTC)"A saída de status de replicação pode ser usada para avaliar o estado atual da replicação e determinar se há algum atraso de replicação não intencional.
rs.printSlaveReplicationInfo()Ele mostra o atraso de tempo entre os membros secundários em relação ao primário.
rs.status()Ele mostra os detalhes detalhados para replicação. Podemos reunir informações suficientes sobre replicação usando esses comandos. Felizmente, essas dicas fornecem uma visão geral rápida de como revisar o desempenho do MongoDB. Deixe-nos saber se perdemos alguma coisa.



