O failover automático para MySQL Replication tem sido objeto de debate por muitos anos.
É uma coisa boa ou ruim?
Para aqueles com memória longa no mundo MySQL, eles podem se lembrar da interrupção do GitHub em 2012, que foi causada principalmente por software que tomou as decisões erradas.
O GitHub acabou de migrar para uma combinação de MySQL Replication, Corosync, Pacemaker e Percona Replication Manager. O PRM decidiu fazer um failover após falhar nas verificações de integridade do mestre, que estava sobrecarregado durante uma migração de esquema. Um novo mestre foi selecionado, mas teve um desempenho ruim devido aos caches frios. A alta carga de consulta do site ocupado fez com que as pulsações do PRM falhem novamente no mestre frio e o PRM acionou outro failover para o mestre original. E os problemas continuaram, conforme resumido abaixo.
 Fonte:Henrik Ingo e Massimo Brignoli no Percona Live 2013
Fonte:Henrik Ingo e Massimo Brignoli no Percona Live 2013 Avance alguns anos e o GitHub está de volta com uma estrutura bastante sofisticada para gerenciar a replicação do MySQL e o failover automatizado! Como Shlomi Noach coloca:
“Para isso, empregamos failovers mestre automatizados. O tempo que um humano levaria para acordar e consertar um mestre com falha está além de nossa expectativa de disponibilidade, e operar esse failover às vezes não é trivial. Esperamos que as falhas do mestre sejam detectadas e recuperadas automaticamente em 30 segundos ou menos, e esperamos que o failover resulte em perda mínima de hosts disponíveis.”
A maioria das empresas não é GitHub, mas pode-se argumentar que nenhuma empresa gosta de interrupções. As interrupções são disruptivas para qualquer negócio e também custam dinheiro. Meu palpite é que a maioria das empresas provavelmente gostaria de ter algum tipo de failover automatizado, e os motivos para não implementá-lo são provavelmente a complexidade das soluções existentes, a falta de competência na implementação de tais soluções ou a falta de confiança no software para tomar uma decisão tão importante.
Existem várias soluções de failover automatizadas, incluindo (e não se limitando a) MHA, MMM, MRM, mysqlfailover, Orchestrator e ClusterControl. Alguns deles estão no mercado há vários anos, outros são mais recentes. Isso é um bom sinal, várias soluções significam que o mercado existe e as pessoas estão tentando resolver o problema.
Quando projetamos o failover automático no ClusterControl, usamos alguns princípios orientadores:
-
Certifique-se de que o mestre esteja realmente morto antes do failover
No caso de uma partição de rede, onde o software de failover perde contato com o mestre, ele deixará de vê-lo. Mas o mestre pode estar funcionando bem e pode ser visto pelo restante da topologia de replicação.
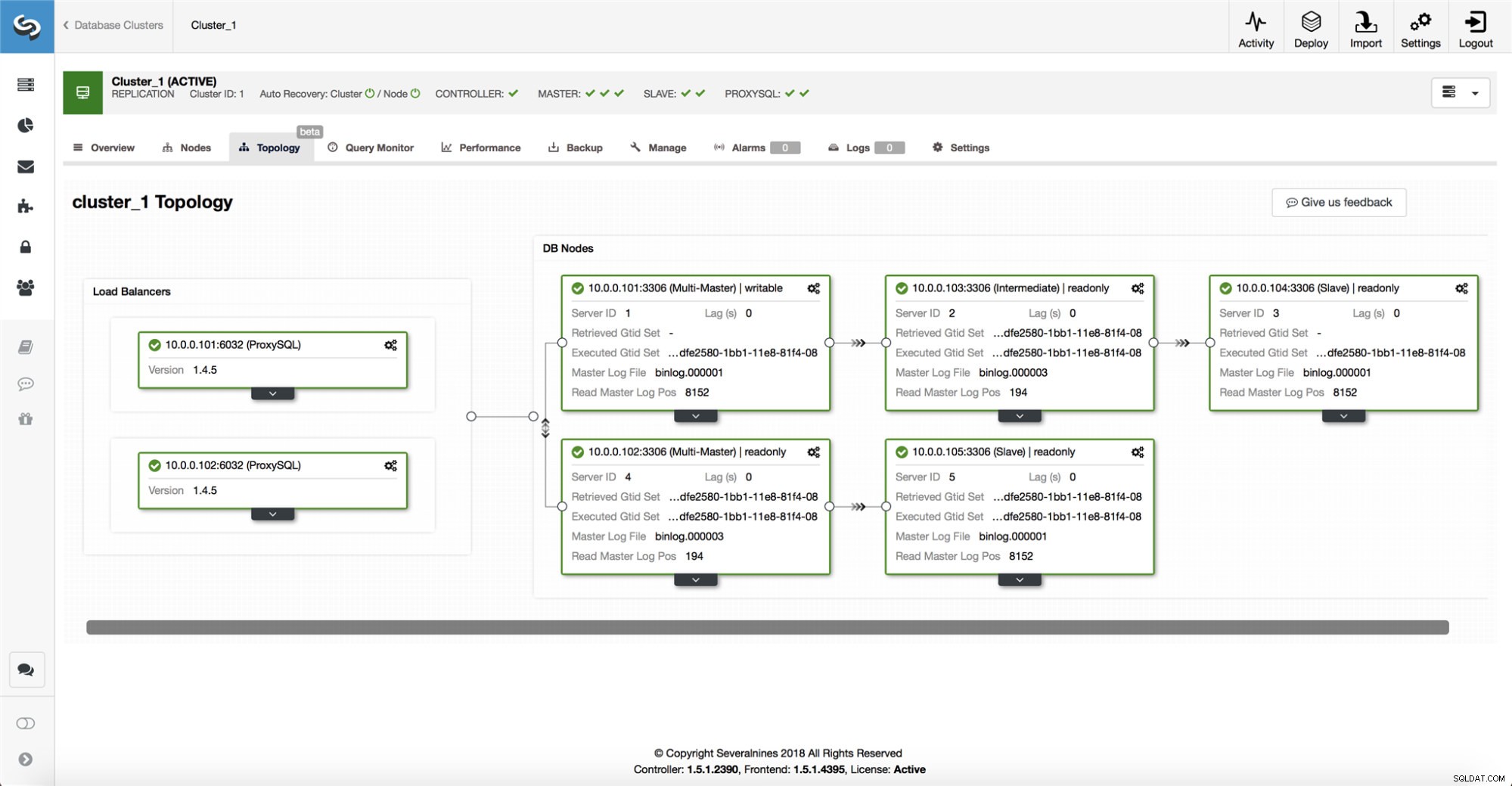
O ClusterControl reúne informações de todos os nós de banco de dados, bem como de quaisquer proxies de banco de dados/balanceadores de carga usados e, em seguida, cria uma representação da topologia. Ele não tentará um failover se os escravos puderem ver o mestre, nem se o ClusterControl não tiver 100% de certeza sobre o estado do mestre.
O ClusterControl também facilita a visualização da topologia da configuração, bem como o status dos diferentes nós (este é o entendimento do ClusterControl sobre o estado do sistema, com base nas informações que ele coleta).
-
Failover apenas uma vez
Muito tem sido escrito sobre o flapping. Pode ficar muito confuso se a ferramenta de disponibilidade decidir fazer vários failovers. Essa é uma situação perigosa. Cada mestre eleito, por mais breve que tenha sido o período em que ocupou a função de mestre, pode ter seus próprios conjuntos de alterações que nunca foram replicados para nenhum servidor. Então você pode acabar com inconsistência em todos os mestres eleitos.
-
Não faça failover para um escravo inconsistente
Ao selecionar um escravo para promover como mestre, garantimos que o escravo não tenha inconsistências, por exemplo, transações errôneas, pois isso pode muito bem quebrar a replicação.
-
Escrever apenas para o mestre
A replicação vai do mestre para o(s) escravo(s). Gravar diretamente em um escravo criaria um conjunto de dados divergente e isso pode ser uma fonte potencial de problemas. Definimos os escravos como read_only e super_read_only nas versões mais recentes do MySQL ou MariaDB. Também aconselhamos o uso de um balanceador de carga, por exemplo, ProxySQL ou MaxScale, para proteger a camada de aplicativo da topologia de banco de dados subjacente e de quaisquer alterações nela. O balanceador de carga também impõe gravações no mestre atual.
-
Não recupere automaticamente o mestre com falha
Se o mestre falhou e um novo mestre foi eleito, o ClusterControl não tentará recuperar o mestre com falha. Por quê? Esse servidor pode ter dados que ainda não foram replicados e o administrador precisaria fazer alguma investigação sobre a falha. Ok, você ainda pode configurar o ClusterControl para apagar os dados no mestre com falha e fazer com que ele se junte como escravo ao novo mestre - se você estiver bem com a perda de alguns dados. Mas, por padrão, o ClusterControl deixará o mestre com falha, até que alguém olhe para ele e decida reintroduzi-lo na topologia.
Então, você deve automatizar o failover? Depende de como você configurou a replicação. As configurações de replicação circular com vários mestres graváveis ou topologias complexas provavelmente não são bons candidatos para failover automático. Seguiríamos os princípios acima ao projetar uma solução de replicação.
No PostgreSQL
Quando se trata de replicação de streaming PostgreSQL, o ClusterControl usa princípios semelhantes para automatizar o failover. Para PostgreSQL, o ClusterControl suporta modelos de replicação assíncrona e síncrona entre o mestre e os escravos. Em ambos os casos e em caso de falha, o escravo com os dados mais atualizados é eleito como novo mestre. Os mestres com falha não são recuperados/corrigidos automaticamente para reingressar na configuração de replicação.
Existem algumas medidas de proteção tomadas para garantir que o mestre com falha esteja inativo e permaneça inativo, por exemplo, ele é removido do balanceamento de carga definido no proxy e é eliminado se, por exemplo, o usuário iria reiniciá-lo manualmente. É um pouco mais desafiador detectar divisões de rede entre o ClusterControl e o mestre, pois os escravos não fornecem nenhuma informação sobre o status do mestre do qual estão replicando. Portanto, um proxy na frente da configuração do banco de dados é importante, pois pode fornecer outro caminho para o mestre.
No MongoDB
A replicação do MongoDB em um replicaset por meio do oplog é muito semelhante à replicação do binlog, então como o MongoDB recupera automaticamente um mestre com falha? O problema ainda está lá, e o MongoDB resolve isso revertendo todas as alterações que não foram replicadas para os escravos no momento da falha. Esses dados são removidos e colocados em uma pasta de ‘reversão’, portanto, cabe ao administrador restaurá-los.
Para saber mais, confira ClusterControl; e sinta-se à vontade para comentar ou fazer perguntas abaixo.



