JOIN é um dos principais recursos distintos entre bancos de dados SQL e NoSQL. Em bancos de dados SQL, podemos realizar um JOIN entre duas tabelas dentro de bancos de dados iguais ou diferentes. No entanto, este não é o caso do MongoDB, pois permite operações JOIN entre duas coleções no mesmo banco de dados.
A forma como os dados são apresentados no MongoDB torna quase impossível relacioná-los de uma coleção para outra, exceto ao usar funções básicas de consulta de script. O MongoDB desnormaliza os dados armazenando itens relacionados em um documento separado ou relaciona os dados em algum outro documento separado.
Pode-se relacionar esses dados usando referências manuais, como o campo _id de um documento que é salvo em outro documento como referência. No entanto, é preciso fazer várias consultas para buscar alguns dados necessários, tornando o processo um pouco tedioso.
Resolvemos assim utilizar o conceito JOIN que facilita a relação dos dados. A operação JOIN no MongoDB é obtida através do uso do operador $lookup, que foi introduzido na versão 3.2.
Operador $lookup
A ideia principal por trás do conceito JOIN é obter correlação entre os dados de uma coleção para outra. A sintaxe básica do operador $lookup é:
{
$lookup:
{
from: <collection to join>,
localField: <field from the input documents>,
foreignField: <field from the documents of the "from" collection>,
as: <output array field>
}
}Em relação ao conhecimento de SQL, sempre sabemos que o resultado de uma operação JOIN é uma linha separada ligando todos os campos da tabela local e estrangeira. Para o MongoDB, esse é um caso diferente, pois os documentos de resultado são adicionados como uma matriz de documentos de coleção local. Por exemplo, vamos ter duas coleções; 'alunos' e 'unidades'
alunos
{"_id" : 1,"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5}
{"_id" : 2,"name" : "Clinton Ariango","age" : 14.0,"grade" : "B","score" : 7.5}
{"_id" : 3,"name" : "Mary Muthoni","age" : 16.0,"grade" : "A","score" : 11.5}Unidades
{"_id" : 1,"Maths" : "A","English" : "A","Science" : "A","History" : "B"}
{"_id" : 2,"Maths" : "B","English" : "B","Science" : "A","History" : "B"}
{"_id" : 3,"Maths" : "A","English" : "A","Science" : "A","History" : "A"}Podemos recuperar as unidades dos alunos com as respectivas notas usando o operador $lookup com a abordagem JOIN .i.e
db.getCollection('students').aggregate([{
$lookup:
{
from: "units",
localField: "_id",
foreignField : "_id",
as: "studentUnits"
}
}])O que nos dará os resultados abaixo:
{"_id" : 1,"name" : "James Washington","age" : 15,"grade" : "A","score" : 10.5,
"studentUnits" : [{"_id" : 1,"Maths" : "A","English" : "A","Science" : "A","History" : "B"}]}
{"_id" : 2,"name" : "Clinton Ariango","age" : 14,"grade" : "B","score" : 7.5,
"studentUnits" : [{"_id" : 2,"Maths" : "B","English" : "B","Science" : "A","History" : "B"}]}
{"_id" : 3,"name" : "Mary Muthoni","age" : 16,"grade" : "A","score" : 11.5,
"studentUnits" : [{"_id" : 3,"Maths" : "A","English" : "A","Science" : "A","History" : "A"}]}Como mencionado anteriormente, se fizermos um JOIN usando o conceito SQL, retornaremos com documentos separados na plataforma Studio3T.
SELECT *
FROM students
INNER JOIN units
ON students._id = units._idÉ um equivalente de
db.getCollection("students").aggregate(
[
{
"$project" : {
"_id" : NumberInt(0),
"students" : "$$ROOT"
}
},
{
"$lookup" : {
"localField" : "students._id",
"from" : "units",
"foreignField" : "_id",
"as" : "units"
}
},
{
"$unwind" : {
"path" : "$units",
"preserveNullAndEmptyArrays" : false
}
}
]
);A consulta SQL acima retornará os resultados abaixo:
{ "students" : {"_id" : NumberInt(1),"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5},
"units" : {"_id" : NumberInt(1),"Maths" : "A","English" : "A","Science" : "A","History" : "B"}}
{ "students" : {"_id" : NumberInt(2), "name" : "Clinton Ariango","age" : 14.0,"grade" : "B","score" : 7.5 },
"units" : {"_id" : NumberInt(2),"Maths" : "B","English" : "B","Science" : "A","History" : "B"}}
{ "students" : {"_id" : NumberInt(3),"name" : "Mary Muthoni","age" : 16.0,"grade" : "A","score" : 11.5},
"units" : {"_id" : NumberInt(3),"Maths" : "A","English" : "A","Science" : "A","History" : "A"}}A duração do desempenho obviamente dependerá da estrutura de sua consulta. Por exemplo, se você tiver muitos documentos em uma coleção sobre a outra, você deve fazer a agregação da coleção com menos documentos e depois pesquisar aquela com mais documentos. Dessa forma, uma pesquisa para o campo escolhido da coleção de documentos menor é bastante ideal e leva menos tempo do que fazer várias pesquisas para um campo escolhido na coleção com mais documentos. Portanto, é aconselhável colocar a coleção menor primeiro.
Para um banco de dados relacional, a ordem dos bancos de dados não importa, pois a maioria dos interpretadores SQL possui otimizadores, que têm acesso a informações extras para decidir qual deles deve ser o primeiro.
No caso do MongoDB, precisaremos usar um índice para facilitar a operação JOIN. Todos nós sabemos que todos os documentos do MongoDB têm uma chave _id que para um DBM relacional pode ser considerada como a chave primária. Um índice fornece uma chance melhor de reduzir a quantidade de dados que precisam ser acessados, além de oferecer suporte à operação quando usado na chave estrangeira $lookup.
No pipeline de agregação, para usar um índice, devemos garantir que o $match seja feito no primeiro estágio para filtrar os documentos que não correspondem aos critérios. Por exemplo, se quisermos recuperar o resultado do aluno com o valor do campo _id igual a 1:
select *
from students
INNER JOIN units
ON students._id = units._id
WHERE students._id = 1;O código MongoDB equivalente que você obterá neste caso é:
db.getCollection("students").aggregate(
[{"$project" : { "_id" : NumberInt(0), "students" : "$$ROOT" }},
{ "$lookup" : {"localField" : "students._id", "from" : "units", "foreignField" : "_id", "as" : "units"} },
{ "$unwind" : { "path" : "$units","preserveNullAndEmptyArrays" : false } },
{ "$match" : {"students._id" : NumberLong(1) }}
]);O resultado retornado para a consulta acima será:
{"_id" : 1,"name" : "James Washington","age" : 15,"grade" : "A","score" : 10.5,
"studentUnits" : [{"_id" : 1,"Maths" : "A","English" : "A","Science" : "A","History" : "B"}]}Quando não usamos o estágio $match, ou melhor, não no primeiro estágio, se verificarmos com a função de explicação, teremos o estágio COLLSCAN também incluído. Fazer um COLLSCAN para um grande conjunto de documentos geralmente leva muito tempo. Assim, resolvemos usar um campo de índice que na função de explicação envolve apenas o estágio IXSCAN. Este último tem uma vantagem, pois estamos verificando um índice nos documentos e não digitalizando todos os documentos; não demorará muito para retornar os resultados. Você pode ter uma estrutura de dados diferente como:
{ "_id" : NumberInt(1),
"grades" : {"Maths" : "A", "English" : "A", "Science" : "A", "History" : "B"
}
}Podemos querer retornar as notas como entidades diferentes em uma matriz em vez de um campo de notas incorporado inteiro.
Depois de escrever a consulta SQL acima, precisamos modificar o código MongoDB resultante. Para isso, clique no ícone de cópia à direita conforme abaixo para copiar o código de agregação:
Em seguida, vá para a guia de agregação e no painel apresentado, há um ícone de colar, clique nele para colar o código.
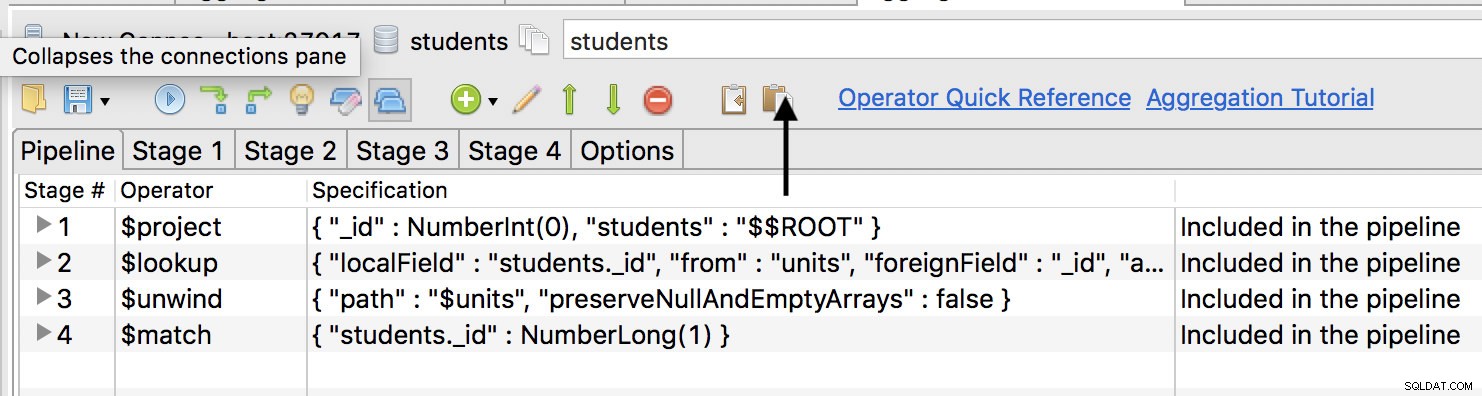
Clique na linha $match e depois na seta verde para cima para mover o estágio para o topo como o primeiro estágio. No entanto, você precisará criar um índice em sua coleção primeiro, como:
db.students.createIndex(
{ _id: 1 },
{ name: studentId }
)Você obterá o exemplo de código abaixo:
db.getCollection("students").aggregate(
[{ "$match" : {"_id" : 1.0}},
{ "$project" : {"_id" : NumberInt(0),"students" : "$$ROOT"}},
{ "$lookup" : {"localField" : "students._id","from" : "units","foreignField" : "_id","as" : "units"}},
{ "$unwind" : {"path" : "$units", "preserveNullAndEmptyArrays" : false}}
]Com este código teremos o resultado abaixo:
{ "students" : {"_id" : NumberInt(1), "name" : "James Washington","age" : 15.0,"grade" : "A", "score" : 10.5},
"units" : {"_id" : NumberInt(1), "grades" : {"Maths" : "A", "English" : "A", "Science" : "A", "History" : "B"}}}Mas tudo o que precisamos é ter as notas como uma entidade de documento separada no documento retornado e não como no exemplo acima. Portanto, adicionaremos o estágio $ addfields, portanto, o código abaixo.
db.getCollection("students").aggregate(
[{ "$match" : {"_id" : 1.0}},
{ "$project" : {"_id" : NumberInt(0),"students" : "$$ROOT"}},
{ "$lookup" : {"localField" : "students._id","from" : "units","foreignField" : "_id","as" : "units"}},
{ "$unwind" : {"path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$addFields" : {"units" : "$units.grades"} }]Os documentos resultantes serão então:
{
"students" : {"_id" : NumberInt(1), "name" : "James Washington", "grade" : "A","score" : 10.5},
"units" : {"Maths" : "A", "English" : "A", "Science" : "A", "History" : "B"}
}Os dados retornados são bastante organizados, pois eliminamos os documentos incorporados da coleção das unidades como um campo separado.
Em nosso próximo tutorial, examinaremos consultas com várias junções.



