Neste artigo, vamos construir um scraper para um real show freelance em que o cliente deseja que um programa Python extraia dados do Stack Overflow para obter novas perguntas (título e URL da pergunta). Os dados raspados devem ser armazenados no MongoDB. Vale a pena notar que o Stack Overflow possui uma API, que pode ser usada para acessar o exato mesmos dados. No entanto, o cliente queria um raspador, então um raspador é o que ele conseguiu.
Bônus grátis: Clique aqui para baixar um esqueleto de projeto Python + MongoDB com código-fonte completo que mostra como acessar o MongoDB a partir do Python.
Atualizações:
- 01/03/2014 - Refatorou a aranha. Obrigado, @kissgyorgy.
- 18/02/2015 - Adicionada parte 2.
- 09/06/2015 - Atualizado para a versão mais recente do Scrapy e do PyMongo - parabéns!
Como sempre, certifique-se de revisar os termos de uso/serviço do site e respeitar o robots.txt arquivo antes de iniciar qualquer trabalho de raspagem. Certifique-se de aderir às práticas éticas de raspagem, não inundando o site com inúmeras solicitações em um curto período de tempo. Trate qualquer site que você criar como se fosse seu .
Instalação
Precisamos da biblioteca Scrapy (v1.0.3) junto com o PyMongo (v3.0.3) para armazenar os dados no MongoDB. Você também precisa instalar o MongoDB (não coberto).
Scrapy
Se você estiver executando o OSX ou uma versão do Linux, instale o Scrapy com pip (com seu virtualenv ativado):
$ pip install Scrapy==1.0.3
$ pip freeze > requirements.txt
Se você estiver em uma máquina Windows, precisará instalar manualmente várias dependências. Consulte a documentação oficial para obter instruções detalhadas, bem como este vídeo do Youtube que criei.
Depois que o Scrapy estiver configurado, verifique sua instalação executando este comando no shell do Python:
>>>
>>> import scrapy
>>>
Se você não receber um erro, então você está pronto para ir!
PyMongo
Em seguida, instale o PyMongo com pip:
$ pip install pymongo
$ pip freeze > requirements.txt
Agora podemos começar a construir o rastreador.
Projeto Scrapy
Vamos iniciar um novo projeto Scrapy:
$ scrapy startproject stack
2015-09-05 20:56:40 [scrapy] INFO: Scrapy 1.0.3 started (bot: scrapybot)
2015-09-05 20:56:40 [scrapy] INFO: Optional features available: ssl, http11
2015-09-05 20:56:40 [scrapy] INFO: Overridden settings: {}
New Scrapy project 'stack' created in:
/stack-spider/stack
You can start your first spider with:
cd stack
scrapy genspider example example.com
Isso cria vários arquivos e pastas que incluem um clichê básico para você começar rapidamente:
├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
Especificar dados
O items.py file é usado para definir “contêineres” de armazenamento para os dados que planejamos extrair.
O
StackItem() classe herda de Item (docs), que basicamente possui vários objetos pré-definidos que o Scrapy já construiu para nós:import scrapy
class StackItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
Vamos adicionar alguns itens que realmente queremos coletar. Para cada pergunta, o cliente precisa do título e da URL. Portanto, atualize items.py igual a:
from scrapy.item import Item, Field
class StackItem(Item):
title = Field()
url = Field()
Criar a Aranha
Crie um arquivo chamado stack_spider.py no diretório "aranhas". É aqui que a mágica acontece – por exemplo, onde diremos ao Scrapy como encontrar o exato dados que procuramos. Como você pode imaginar, isso é específico para cada página da web individual que você deseja extrair.
Comece definindo uma classe que herda do
Spider do Scrapy e, em seguida, adicionando atributos conforme necessário:from scrapy import Spider
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
As primeiras variáveis são autoexplicativas (docs):
namedefine o nome do Spider.allowed_domainscontém os URLs base dos domínios permitidos para rastreamento do spider.start_urlsé uma lista de URLs para o spider começar a rastrear. Todos os URLs subsequentes começarão a partir dos dados que o spider baixa dos URLS emstart_urls.
Seletores XPath
Em seguida, o Scrapy usa seletores XPath para extrair dados de um site. Em outras palavras, podemos selecionar certas partes dos dados HTML com base em um determinado XPath. Conforme declarado na documentação do Scrapy, “XPath é uma linguagem para selecionar nós em documentos XML, que também podem ser usados com HTML”.
Você pode encontrar facilmente um Xpath específico usando as Ferramentas do desenvolvedor do Chrome. Simplesmente inspecione um elemento HTML específico, copie o XPath e ajuste (conforme necessário):
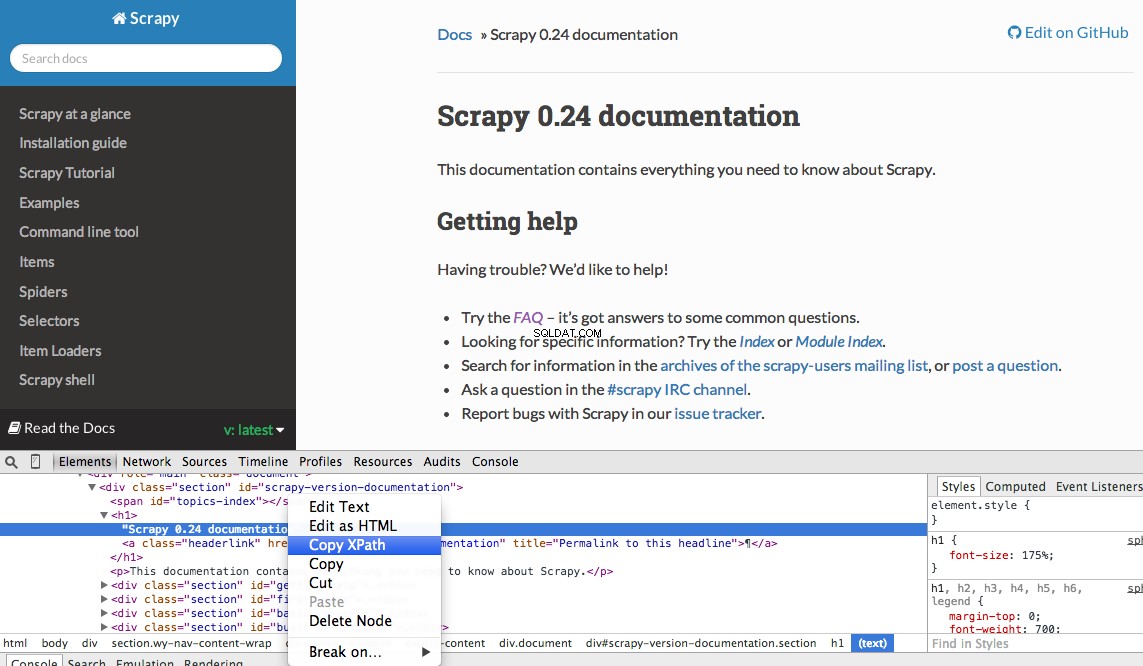
As Ferramentas do Desenvolvedor também permitem testar seletores XPath no Console JavaScript usando
$x - ou seja, $x("//img") :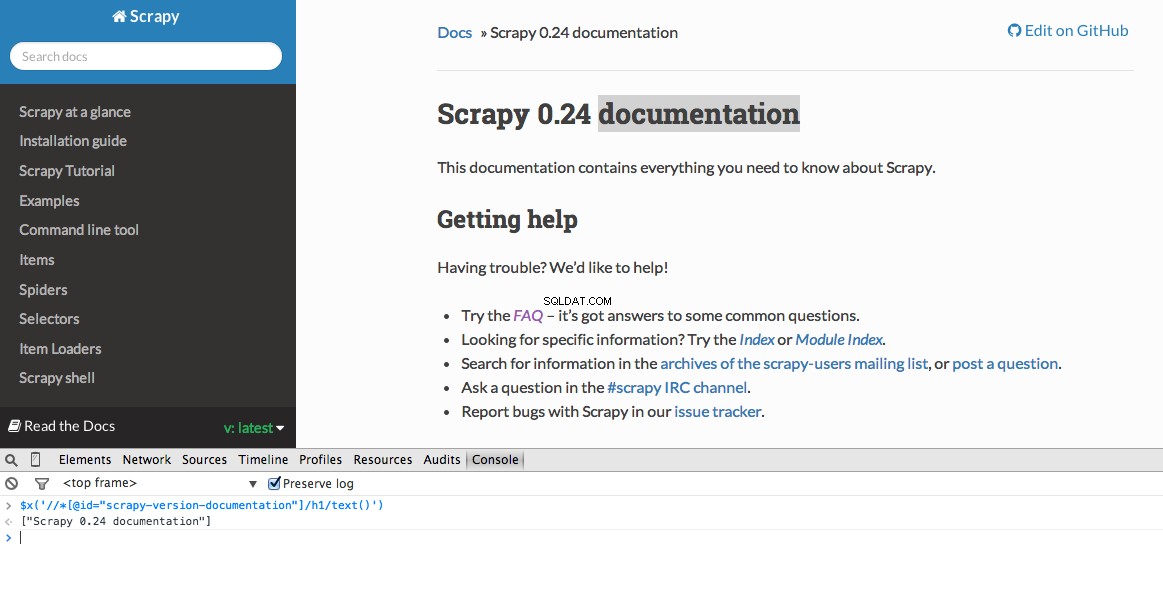
Novamente, basicamente informamos ao Scrapy onde começar a procurar informações com base em um XPath definido. Vamos navegar até o site do Stack Overflow no Chrome e encontrar os seletores XPath.
Clique com o botão direito na primeira pergunta e selecione “Inspecionar Elemento”:
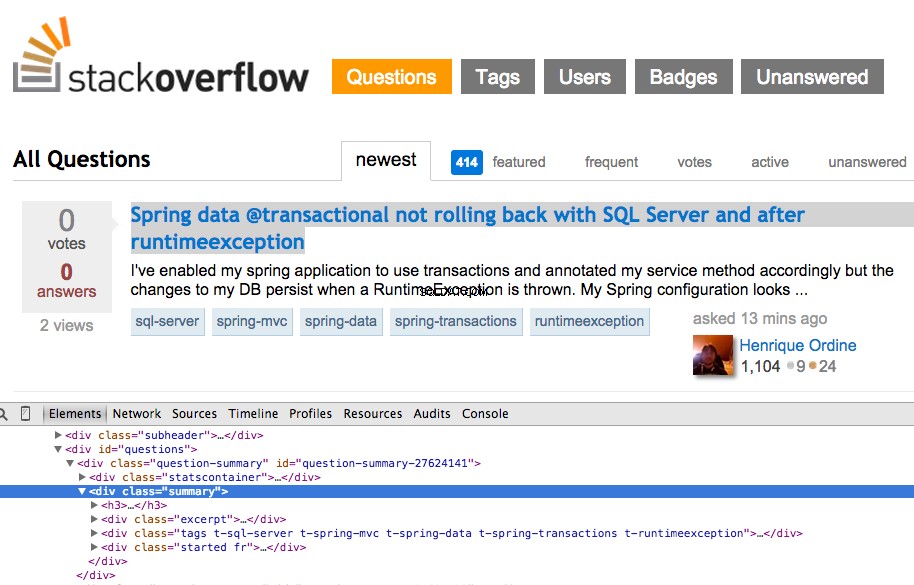
Agora pegue o XPath para o
<div class="summary"> , //*[@id="question-summary-27624141"]/div[2] , e teste-o no Console JavaScript: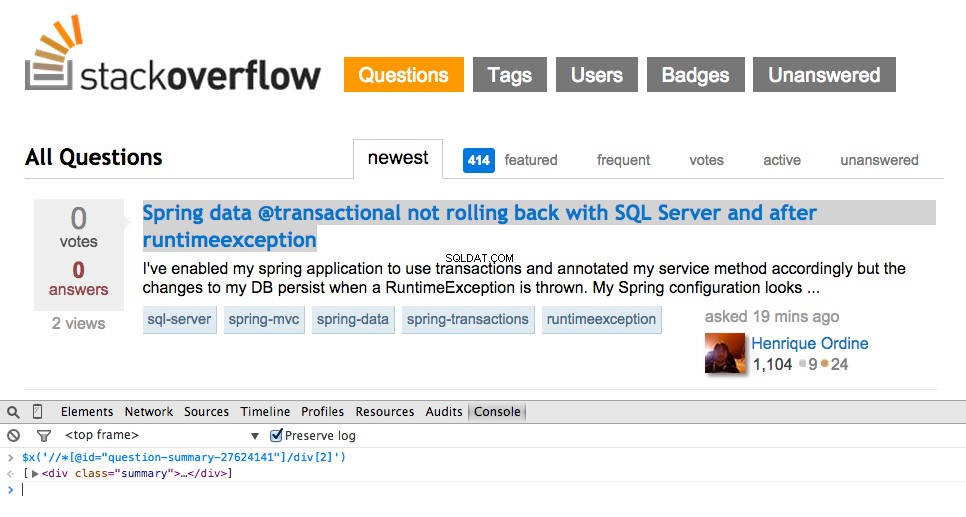
Como você pode ver, ele apenas seleciona aquele um pergunta. Então, precisamos alterar o XPath para pegar todos questões. Alguma ideia? É simples:
//div[@class="summary"]/h3 . O que isto significa? Essencialmente, este XPath afirma:Pegue todos os <h3> elementos que são filhos de um <div> que tem uma classe de summary . Teste este XPath no Console JavaScript.
Observe como não estamos usando a saída XPath real das Ferramentas do desenvolvedor do Chrome. Na maioria dos casos, a saída é apenas um aparte útil, que geralmente indica a direção certa para encontrar o XPath em funcionamento.
Agora vamos atualizar o stack_spider.py roteiro:
from scrapy import Spider
from scrapy.selector import Selector
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
Extraia os dados
Ainda precisamos analisar e extrair os dados que queremos, que se enquadram em
<div class="summary"><h3> . Novamente, atualize stack_spider.py igual a:from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
yield item
````
We are iterating through the `questions` and assigning the `title` and `url` values from the scraped data. Be sure to test out the XPath selectors in the JavaScript Console within Chrome Developer Tools - e.g., `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/text()')` and `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/@href')`.
## Test
Ready for the first test? Simply run the following command within the "stack" directory:
```console
$ scrapy crawl stack
Junto com o rastreamento de pilha do Scrapy, você deve ver 50 títulos de perguntas e URLs gerados. Você pode renderizar a saída para um arquivo JSON com este pequeno comando:
$ scrapy crawl stack -o items.json -t json
Agora implementamos nosso Spider com base em nossos dados que estamos procurando. Agora precisamos armazenar os dados raspados no MongoDB.
Armazenar os dados no MongoDB
Cada vez que um item é retornado, queremos validar os dados e adicioná-los a uma coleção do Mongo.
A etapa inicial é criar o banco de dados que planejamos usar para salvar todos os nossos dados rastreados. Abra configurações.py e especifique o pipeline e adicione as configurações do banco de dados:
ITEM_PIPELINES = ['stack.pipelines.MongoDBPipeline', ]
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"
Gerenciamento de pipeline
Configuramos nosso spider para rastrear e analisar o HTML e configuramos nossas configurações de banco de dados. Agora temos que conectar os dois por meio de um pipeline em pipelines.py .
Conectar ao banco de dados
Primeiro, vamos definir um método para realmente se conectar ao banco de dados:
import pymongo
from scrapy.conf import settings
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
Aqui, criamos uma classe,
MongoDBPipeline() , e temos uma função construtora para inicializar a classe definindo as configurações do Mongo e conectando-se ao banco de dados. Processar os dados
Em seguida, precisamos definir um método para processar os dados analisados:
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
Estabelecemos uma conexão com o banco de dados, descompactamos os dados e os salvamos no banco de dados. Agora podemos testar novamente!
Teste
Novamente, execute o seguinte comando dentro do diretório “stack”:
$ scrapy crawl stack
OBSERVAÇÃO :Certifique-se de ter o daemon Mongo -mongod- rodando em uma janela de terminal diferente.
Viva! Armazenamos com sucesso nossos dados rastreados no banco de dados:
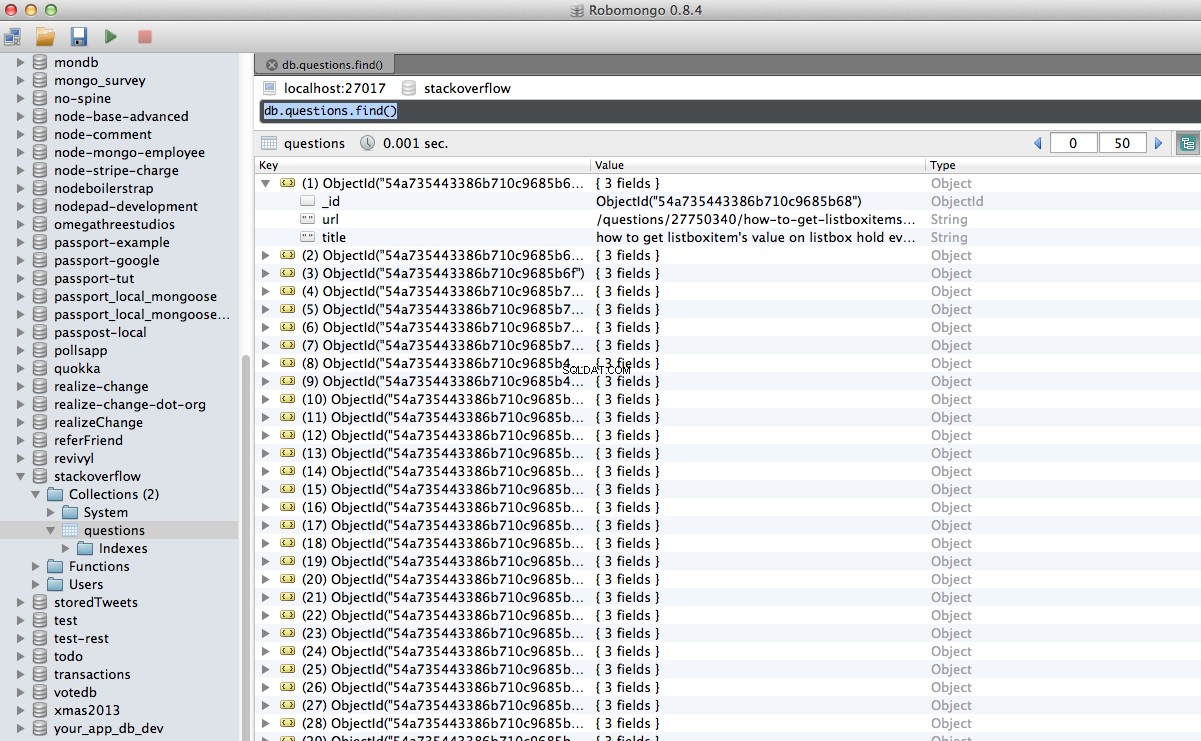
Conclusão
Este é um exemplo bastante simples de usar o Scrapy para rastrear e raspar uma página da web. O projeto freelance real exigia que o script seguisse os links de paginação e raspasse cada página usando o
CrawlSpider (docs), que é super fácil de implementar. Tente implementar isso por conta própria e deixe um comentário abaixo com o link para o repositório do Github para uma revisão rápida do código. Preciso de ajuda? Comece com este script, que está quase completo. Então veja a Parte 2 para ver a solução completa!
Bônus grátis: Clique aqui para baixar um esqueleto de projeto Python + MongoDB com código-fonte completo que mostra como acessar o MongoDB a partir do Python.
Você pode baixar todo o código-fonte do repositório do Github. Comente abaixo com perguntas. Obrigado por Ler!



