Esta postagem de blog é uma continuação da parte 1 anterior, na qual abordamos os fundamentos da integração SNMP com o ClusterControl.
Nesta postagem do blog, vamos nos concentrar nas armadilhas e alertas SNMP. As armadilhas SNMP são as mensagens de alerta usadas com mais frequência enviadas de um dispositivo remoto habilitado para SNMP (um agente) para um coletor central, o “gerenciador SNMP”. No caso do ClusterControl, uma armadilha pode ser um alerta depois que o alarme crítico para um cluster não for 0, indicando que algo ruim está acontecendo.
Conforme mostrado na postagem anterior do blog, para fins desta prova de conceito, temos duas definições de notificações de trap SNMP:
criticalAlarmNotification NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification if critical alarm is not 0"
::= { alarmNotification 1 }
criticalAlarmNotificationEnded NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification ended - Critical alarm is 0"
::= { alarmNotification 2 }As notificações (ou traps) são criticalAlarmNotification e criticalAlarmNotificationEnded. Ambos os eventos de notificação podem ser usados para sinalizar nosso serviço Nagios, se o cluster está tendo alarmes críticos ativamente ou não. No Nagios, o termo para isso é verificação passiva, em que o Nagios não tenta determinar se o host/serviço está DOWN ou UNREACHABLE. Também configuraremos as verificações ativas, onde as verificações são iniciadas pela lógica de verificação no daemon do Nagios usando a definição do serviço para também monitorar os alarmes críticos/avisos relatados pelo nosso cluster.
Observe que esta postagem de blog requer o agente MIB e SNMP da Multiplenines configurado corretamente, conforme mostrado na primeira parte desta série de blogs.
Instalando o Nagios Core
Nagios Core é a versão gratuita do pacote de monitoramento Nagios. Em primeiro lugar, temos que instalá-lo e todos os pacotes necessários, seguidos pelos plugins do Nagios, snmptrapd e snmptt. Observe que as instruções nesta postagem de blog pressupõem que todos os nós estão sendo executados no CentOS 7.
Instale os pacotes necessários para rodar o Nagios:
$ yum -y install httpd php gcc glibc glibc-common wget perl gd gd-devel unzip zip sendmail net-snmp-utils net-snmp-perlCrie um usuário nagios e um grupo nagcmd para permitir que os comandos externos sejam executados através da interface web, adicione o usuário nagios e apache para fazer parte do grupo nagcmd:
$ useradd nagios
$ groupadd nagcmd
$ usermod -a -G nagcmd nagios
$ usermod -a -G nagcmd apacheBaixe a versão mais recente do Nagios Core aqui, compile e instale:
$ cd ~
$ wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.6.tar.gz
$ tar -zxvf nagios-4.4.6.tar.gz
$ cd nagios-4.4.6
$ ./configure --with-nagios-group=nagios --with-command-group=nagcmd
$ make all
$ make install
$ make install-init
$ make install-config
$ make install-commandmodeInstale a configuração web do Nagios:
$ make install-webconfOpcionalmente, instale o tema de esfoliação do Nagios (ou você pode ficar com o tema padrão):
$ make install-exfoliationCrie uma conta de usuário (nagiosadmin) para fazer login na interface web do Nagios. Lembre-se da senha que você atribui a este usuário:
$ htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminReinicie o servidor web Apache para que as novas configurações tenham efeito:
$ systemctl restart httpd
$ systemctl enable httpdBaixe os plugins do Nagios aqui, compile e instale:
$ cd ~
$ wget https://nagios-plugins.org/download/nagios-plugins-2.3.3.tar.gz
$ tar -zxvf nagios-plugins-2.3.3.tar.gz
$ cd nagios-plugins-2.3.3
$ ./configure --with-nagios-user=nagios --with-nagios-group=nagios
$ make
$ make installVerifique os arquivos de configuração padrão do Nagios:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
Nagios Core 4.4.6
Copyright (c) 2009-present Nagios Core Development Team and Community Contributors
Copyright (c) 1999-2009 Ethan Galstad
Last Modified: 2020-04-28
License: GPL
Website: https://www.nagios.org
Reading configuration data...
Read main config file okay...
Read object config files okay...
Running pre-flight check on configuration data...
Checking objects...
Checked 8 services.
Checked 1 hosts.
Checked 1 host groups.
Checked 0 service groups.
Checked 1 contacts.
Checked 1 contact groups.
Checked 24 commands.
Checked 5 time periods.
Checked 0 host escalations.
Checked 0 service escalations.
Checking for circular paths...
Checked 1 hosts
Checked 0 service dependencies
Checked 0 host dependencies
Checked 5 timeperiods
Checking global event handlers...
Checking obsessive compulsive processor commands...
Checking misc settings...
Total Warnings: 0
Total Errors: 0
Things look okay - No serious problems were detected during the pre-flight check
If everything looks okay, start Nagios and configure it to start on boot:
$ systemctl start nagios
$ systemctl enable nagiosAbra o navegador e vá para https://{endereço IP}/nagios e você deve ver uma autenticação básica HTTP aparecendo onde você precisa especificar o nome de usuário como nagiosadmin com sua senha escolhida criada anteriormente.
Adicionando o servidor ClusterControl no Nagios
Crie um arquivo de definição de host Nagios para ClusterControl:
$ vim /usr/local/nagios/etc/objects/clustercontrol.cfgE adicione as seguintes linhas:
define host {
use linux-server
host_name clustercontrol.local
alias clustercontrol.mydomain.org
address 192.168.10.50
}
define service {
use generic-service
host_name clustercontrol.local
service_description Critical alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.2 -c0
}
define service {
use generic-service
host_name clustercontrol.local
service_description Warning alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.3 -w0
}
define service {
use snmp_trap_template
host_name clustercontrol.local
service_description Critical alarm traps
check_interval 60 ; Don't clear for 1 hour
}
Algumas explicações:
-
Na primeira seção, definimos nosso host, com o nome do host e o endereço do servidor ClusterControl.
-
As seções de serviço onde colocamos nossas definições de serviço para serem monitoradas pelo Nagios. Os dois primeiros estão basicamente dizendo ao serviço para verificar a saída SNMP para um ID de objeto específico. O primeiro serviço é sobre o alarme crítico, portanto adicionamos -c0 no comando check_snmp para indicar que deve ser um alerta crítico no Nagios se o valor for além de 0. Já para os alarmes de aviso, indicaremos com um aviso se o valor é 1 e superior.
-
A última definição de serviço é sobre os traps SNMP que esperaríamos vindo do servidor ClusterControl se o alarme crítico levantada é maior que 0. Esta seção usará a definição snmp_trap_template, conforme mostrado na próxima etapa.
Configure o snmp_trap_template adicionando as seguintes linhas em /usr/local/nagios/etc/objects/templates.cfg:
define service {
name snmp_trap_template
service_description SNMP Trap Template
active_checks_enabled 1 ; Active service checks are enabled
passive_checks_enabled 1 ; Passive service checks are enabled/accepted
parallelize_check 1 ; Active service checks should be parallelized
process_perf_data 0
obsess_over_service 0 ; We should obsess over this service (if necessary)
check_freshness 0 ; Default is to NOT check service 'freshness'
notifications_enabled 1 ; Service notifications are enabled
event_handler_enabled 1 ; Service event handler is enabled
flap_detection_enabled 1 ; Flap detection is enabled
process_perf_data 1 ; Process performance data
retain_status_information 1 ; Retain status information across program restarts
retain_nonstatus_information 1 ; Retain non-status information across program restarts
check_command check-host-alive ; This will be used to reset the service to "OK"
is_volatile 1
check_period 24x7
max_check_attempts 1
normal_check_interval 1
retry_check_interval 1
notification_interval 60
notification_period 24x7
notification_options w,u,c,r
contact_groups admins ; Modify this to match your Nagios contactgroup definitions
register 0
}
Inclua o arquivo de configuração ClusterControl no Nagios, adicionando a seguinte linha dentro
/usr/local/nagios/etc/nagios.cfg:
cfg_file=/usr/local/nagios/etc/objects/clustercontrol.cfgExecute uma verificação de configuração pré-voo:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgCertifique-se de obter a seguinte linha no final da saída:
"Things look okay - No serious problems were detected during the pre-flight check"Reinicie o Nagios para carregar a mudança:
$ systemctl restart nagiosAgora, se olharmos para a página do Nagios na seção Serviço (menu do lado esquerdo), veremos algo assim:
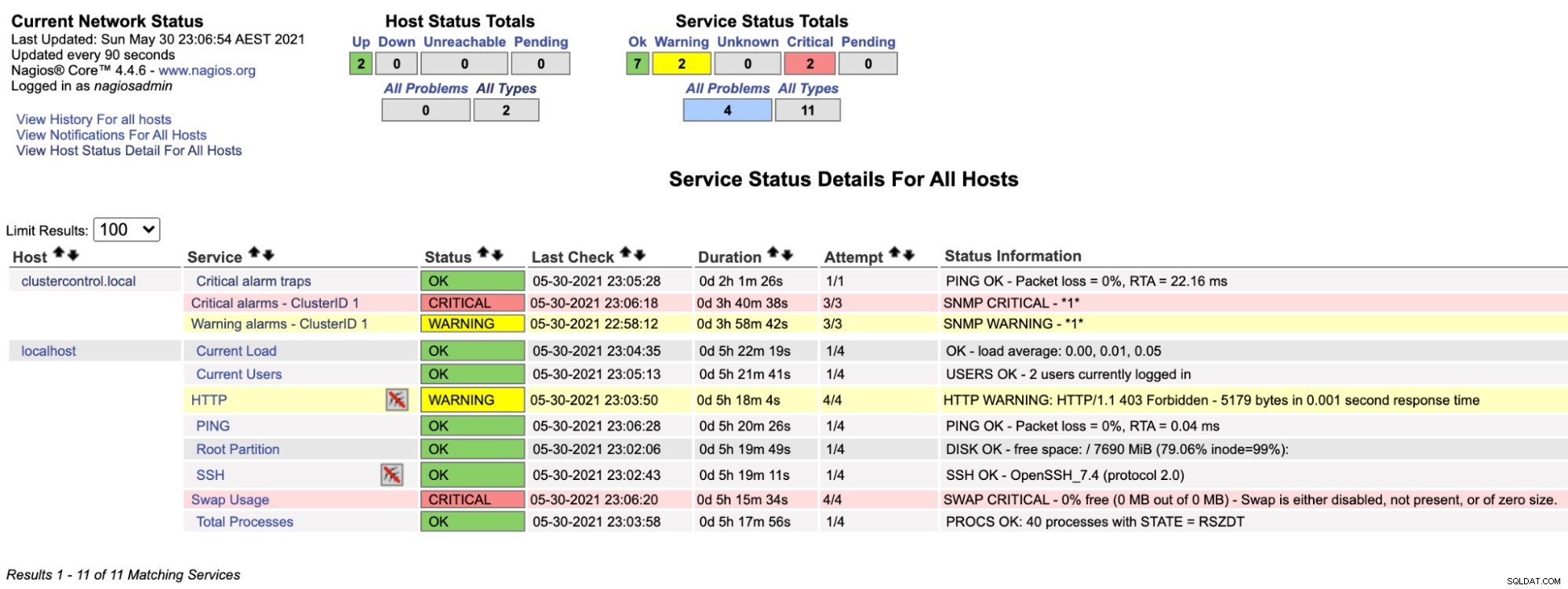
Observe que a linha "Critical alarms - ClusterID 1" fica vermelha se o valor do alarme crítico relatado pelo ClusterControl for maior que 0, enquanto o "Warning alarms - ClusterID 1" fica amarelo, indicando que há um alarme de aviso gerado. Caso nada de interessante aconteça, você verá tudo verde para clustercontrol.local.
Configurando o Nagios para receber uma armadilha
Traps são enviados por dispositivos remotos para o servidor Nagios, isso é chamado de verificação passiva. Idealmente, não sabemos quando uma interceptação será enviada, pois depende do dispositivo de envio decidir enviar uma interceptação. Por exemplo, com um UPS (backup de bateria), assim que o dispositivo perder energia, ele enviará uma armadilha para dizer "ei, perdi energia". Desta forma o Nagios é informado imediatamente.
Para receber traps SNMP, precisamos configurar o servidor Nagios com as seguintes coisas:
-
snmptrapd (daemon do receptor de trap SNMP)
-
snmptt (SNMP Trap Translator, o daemon do manipulador de traps)
Após o snmptrapd receber um trap, ele o passará para o snmptt onde iremos configurá-lo para atualizar o sistema Nagios e então o Nagios enviará o alerta de acordo com a configuração do grupo de contatos.
Instale o repositório EPEL, seguido dos pacotes necessários:
$ yum -y install epel-release
$ yum -y install net-snmp snmptt net-snmp-perl perl-Sys-SyslogConfigure o daemon de trap SNMP em /etc/snmp/snmptrapd.conf e defina as seguintes linhas:
disableAuthorization yes
traphandle default /usr/sbin/snmptthandlerO acima significa simplesmente que as traps recebidas pelo daemon snmptrapd serão passadas para /usr/sbin/snmptthandler.
Adicione SEVERALNINES-CLUSTERCONTROL-MIB.txt em /usr/share/snmp/mibs criando /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt:
$ ll /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt
-rw-r--r-- 1 root root 4029 May 30 20:08 /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txtCrie /etc/snmp/snmp.conf (aviso sem o "d") e adicione nosso MIB personalizado lá:
mibs +SEVERALNINES-CLUSTERCONTROL-MIBInicie o serviço snmptrapd:
$ systemctl start snmptrapd
$ systemctl enable snmptrapdEm seguida, precisamos configurar as seguintes linhas de configuração dentro de /etc/snmp/snmptt.ini:
net_snmp_perl_enable = 1
snmptt_conf_files = <<END
/etc/snmp/snmptt.conf
/etc/snmp/snmptt-cc.conf
ENDObserve que habilitamos o módulo net_snmp_perl e adicionamos outro caminho de configuração, /etc/snmp/snmptt-cc.conf dentro de snmptt.ini. Precisamos definir os eventos snmptt do ClusterControl aqui para que eles possam ser passados para o Nagios. Crie um novo arquivo em /etc/snmp/snmptt-cc.conf e adicione as seguintes linhas:
MIB: SEVERALNINES-CLUSTERCONTROL-MIB (file:/usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt) converted on Sun May 30 19:17:33 2021 using snmpttconvertmib v1.4.2
EVENT criticalAlarmNotification .1.3.6.1.4.1.57397.1.1.3.1 "Status Events" Critical
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 2 "Critical - Critical alarm is $1 for cluster ID $2"
SDESC
Notification if critical alarm is not 0
Variables:
1: totalCritical
2: clusterId
EDESC
EVENT criticalAlarmNotificationEnded .1.3.6.1.4.1.57397.1.1.3.2 "Status Events" Normal
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 0 "Normal - Critical alarm is $1 for cluster ID $2"
SDESC
Notification ended - critical alarm is 0
Variables:
1: totalCritical
2: clusterId
EDESCAlgumas explicações:
-
Temos duas armadilhas definidas - criticalAlarmNotification e criticalAlarmNotificationEnded.
-
O criticalAlarmNotification simplesmente gera um alerta crítico e o passa para o serviço "Critical alarm traps" definido no Nagios. O $aA significa retornar o endereço IP do agente trap. O valor 2 é o valor do resultado da verificação que neste caso é crítico (0=OK, 1=AVISO, 2=CRÍTICO, 3=DESCONHECIDO).
-
O criticalAlarmNotificationEnded simplesmente gera um alerta OK e o passa para o serviço "Critical alarm traps", para cancelar o armadilha anterior depois que tudo voltar ao normal. O $aA significa retornar o endereço IP do agente trap. O valor 0 é o valor do resultado da verificação que, neste caso, está OK. Para obter mais detalhes sobre substituições de strings reconhecidas pelo snmptt, confira este artigo na seção "FORMAT".
-
Você pode usar o snmpttconvertmib para gerar o arquivo manipulador de eventos snmptt para um MIB específico.
Observe que, por padrão, o caminho dos manipuladores de eventos não é fornecido pelo Nagios Core. Portanto, temos que copiar esse diretório eventhandlers da fonte do Nagios no diretório contrib, conforme mostrado abaixo:
$ cp -Rf nagios-4.4.6/contrib/eventhandlers /usr/local/nagios/share/
$ chown -Rf nagios:nagios /usr/local/nagios/share/eventhandlersTambém precisamos atribuir o grupo snmptt como parte do grupo nagcmd, para que ele possa executar o nagios.cmd dentro do script submit_check_result:
$ usermod -a -G nagcmd snmpttInicie o serviço snmptt:
$ systemctl start snmptt
$ systemctl enable snmpttO SNMP Manager (servidor Nagios) agora está pronto para aceitar e processar nossos traps SNMP de entrada.
Enviando um trap do servidor ClusterControl
Suponha que alguém queira enviar uma interceptação SNMP para o gerenciador SNMP, 192.168.10.11 (servidor Nagios) porque o número total de alarmes críticos atingiu 2 para o ID de cluster 1, seria executado o seguinte comando em o servidor ClusterControl (lado do cliente), 192.168.10.50:
$ snmptrap -v2c -c private 192.168.10.11 '' SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification \
SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical i 2 \
SEVERALNINES-CLUSTERCONTROL-MIB::clusterId i 1Ou, no formato OID (recomendado):
$ snmptrap -v2c -c private 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.1 \
.1.3.6.1.4.1.57397.1.1.1.2 i 2 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Onde, .1.3.6.1.4.1.57397.1.1.3.1 é igual ao evento de interceptação criticalAlarmNotification e os OIDs subsequentes são representações do número total dos alarmes críticos atuais e do ID do cluster, respectivamente .
No servidor Nagios, você deve notar que o serviço trap ficou vermelho:
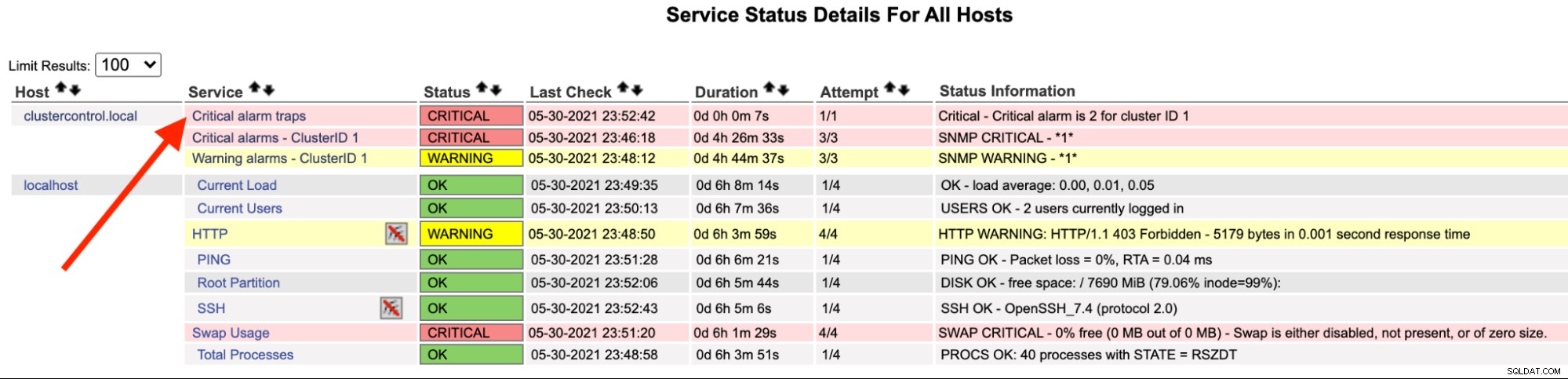
Você também pode vê-lo no /var/log/messages da seguinte linha:
May 30 23:52:39 ip-10-15-2-148 snmptrapd[27080]: 2021-05-30 23:52:39 UDP: [192.168.10.50]:33151->[192.168.10.11]:162 [UDP: [192.168.10.50]:33151->[192.168.10.11]:162]:#012DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (2423020) 6:43:50.20#011SNMPv2-MIB::snmpTrapOID.0 = OID: SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification#011SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical = INTEGER: 2#011SEVERALNINES-CLUSTERCONTROL-MIB::clusterId = INTEGER: 1
May 30 23:52:42 nagios.local snmptt[29557]: .1.3.6.1.4.1.57397.1.1.3.1 Critical "Status Events" UDP192.168.10.5033151-192.168.10.11162 - Notification if critical alarm is not 0
May 30 23:52:42 nagios.local nagios: EXTERNAL COMMAND: PROCESS_SERVICE_CHECK_RESULT;192.168.10.50;Critical alarm traps;2;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: PASSIVE SERVICE CHECK: clustercontrol.local;Critical alarm traps;0;PING OK - Packet loss = 0%, RTA = 22.16 ms
May 30 23:52:42 nagios.local nagios: SERVICE NOTIFICATION: nagiosadmin;clustercontrol.local;Critical alarm traps;CRITICAL;notify-service-by-email;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: SERVICE ALERT: clustercontrol.local;Critical alarm traps;CRITICAL;HARD;1;Critical - Critical alarm is 2 for cluster ID 1Uma vez resolvido o alarme, para enviar um trap normal, podemos executar o seguinte comando:
$ snmptrap -c private -v2c 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.2 \
.1.3.6.1.4.1.57397.1.1.1.2 i 0 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Onde, .1.3.6.1.4.1.57397.1.1.3.2 é igual ao evento criticalAlarmNotificationEnded e os OIDs subsequentes são representações do número total dos alarmes críticos atuais (deve ser 0 para este caso ) e o ID do cluster, respectivamente.
No servidor Nagios, você deve observar que o serviço trap está de volta ao verde:
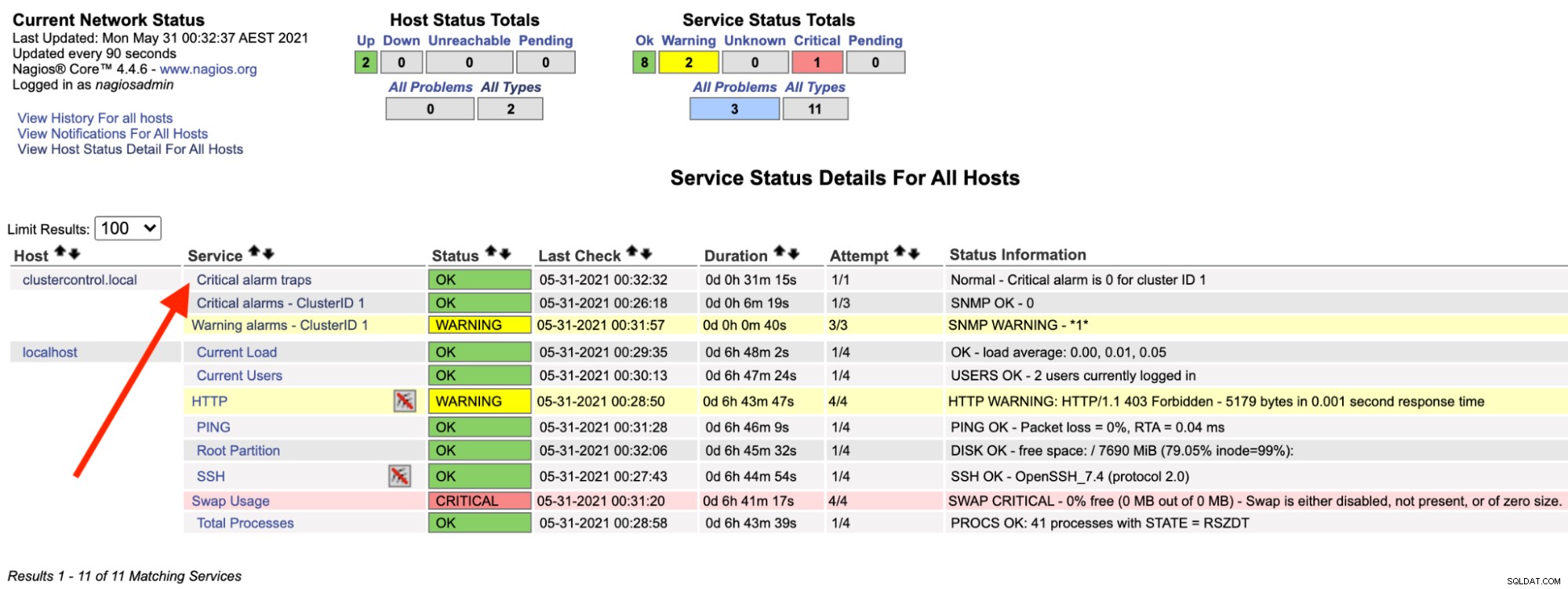
O acima pode ser automatizado com um simples script bash:
#!/bin/bash
# alarmtrapper.bash - SNMP trapper for ClusterControl alarms
CLUSTER_ID=1
SNMP_MANAGER=192.168.10.11
INTERVAL=10
send_critical_snmp_trap() {
# send critical trap
local val=$1
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.1 .1.3.6.1.4.1.57397.1.1.1.1 i ${val} .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
send_zero_critical_snmp_trap() {
# send OK trap
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.2 .1.3.6.1.4.1.57397.1.1.1.1 i 0 .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
while true; do
count=$(s9s alarm --list --long --cluster-id=${CLUSTER_ID} --batch | grep CRITICAL | wc -l)
[ $count -ne 0 ] && send_critical_snmp_trap $count || send_zero_critical_snmp_trap
sleep $INTERVAL
donePara executar o script em segundo plano, basta fazer:
$ bash alarmtrapper.bash &Neste ponto, devemos ser capazes de ver o serviço "Critical alarm traps" do Nagios em ação se houver uma falha em nosso cluster automaticamente.
Considerações finais
Nesta série de blogs, mostramos uma prova de conceito sobre como o ClusterControl pode ser configurado para monitoramento, geração/processamento de traps e alertas usando o protocolo SNMP. Isso também marca o início de nossa jornada para incorporar o SNMP em nossos lançamentos futuros. Fique atento, pois traremos mais atualizações sobre esse recurso interessante.



