Este é um problema bastante comum.
Simples
B-Tree índices não são bons para as consultas como esta:SELECT measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Um índice é bom para pesquisar os valores dentro dos limites fornecidos, assim:
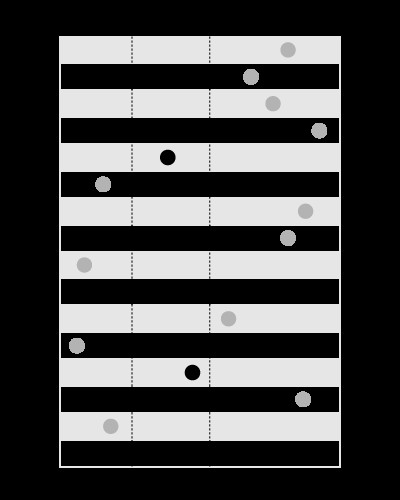
, mas não para pesquisar os limites que contêm o valor fornecido, assim:
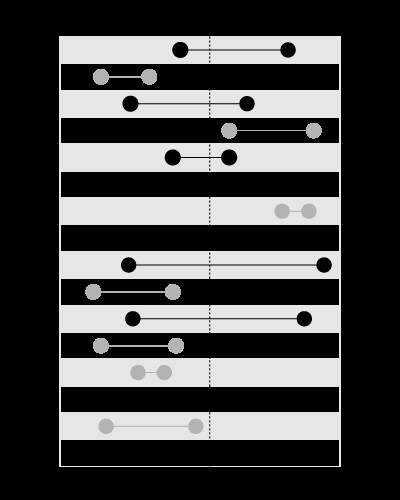
Este artigo no meu blog explica o problema com mais detalhes:
(o modelo de conjuntos aninhados lida com o tipo semelhante de predicado).
Você pode fazer o índice em
time , desta forma os intervals estará liderando a junção, o tempo variado será usado dentro dos loops aninhados. Isso exigirá a classificação em time . Você pode criar um índice espacial em
intervals (disponível em MySQL usando MyISAM storage) que incluiria start e end em uma coluna geométrica. Dessa forma, measures pode levar na junção e nenhuma classificação será necessária. Os índices espaciais, no entanto, são mais lentos, então isso só será eficiente se você tiver poucas medidas, mas muitos intervalos.
Como você tem poucos intervalos, mas muitas medidas, apenas certifique-se de ter um índice em
measures.time :CREATE INDEX ix_measures_time ON measures (time)
Atualização:
Aqui está um script de exemplo para testar:
BEGIN
DBMS_RANDOM.seed(20091223);
END;
/
CREATE TABLE intervals (
entry_time NOT NULL,
exit_time NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level,
TO_DATE('23.12.2009', 'dd.mm.yyyy') - level + DBMS_RANDOM.value
FROM dual
CONNECT BY
level <= 1500
/
CREATE UNIQUE INDEX ux_intervals_entry ON intervals (entry_time)
/
CREATE TABLE measures (
time NOT NULL,
measure NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level / 720,
CAST(DBMS_RANDOM.value * 10000 AS NUMBER(18, 2))
FROM dual
CONNECT BY
level <= 1080000
/
ALTER TABLE measures ADD CONSTRAINT pk_measures_time PRIMARY KEY (time)
/
CREATE INDEX ix_measures_time_measure ON measures (time, measure)
/
Esta consulta:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_NL(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
usa
NESTED LOOPS e retorna em 1.7 segundos. Esta consulta:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_MERGE(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
usa
MERGE JOIN e tive que parar depois de 5 minutos. Atualização 2:
Você provavelmente precisará forçar o mecanismo a usar a ordem de tabela correta na junção usando uma dica como esta:
SELECT /*+ LEADING (intervals) USE_NL(intervals, measures) */
measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
O
Oracle O otimizador de 's não é inteligente o suficiente para ver que os intervalos não se cruzam. É por isso que provavelmente usará measures como uma tabela principal (o que seria uma decisão sábia se os intervalos se cruzassem). Atualização 3:
WITH splits AS
(
SELECT /*+ MATERIALIZE */
entry_range, exit_range,
exit_range - entry_range + 1 AS range_span,
entry_time, exit_time
FROM (
SELECT TRUNC((entry_time - TO_DATE(1, 'J')) * 2) AS entry_range,
TRUNC((exit_time - TO_DATE(1, 'J')) * 2) AS exit_range,
entry_time,
exit_time
FROM intervals
)
),
upper AS
(
SELECT /*+ MATERIALIZE */
MAX(range_span) AS max_range
FROM splits
),
ranges AS
(
SELECT /*+ MATERIALIZE */
level AS chunk
FROM upper
CONNECT BY
level <= max_range
),
tiles AS
(
SELECT /*+ MATERIALIZE USE_MERGE (r s) */
entry_range + chunk - 1 AS tile,
entry_time,
exit_time
FROM ranges r
JOIN splits s
ON chunk <= range_span
)
SELECT /*+ LEADING(t) USE_HASH(m t) */
SUM(LENGTH(stuffing))
FROM tiles t
JOIN measures m
ON TRUNC((m.time - TO_DATE(1, 'J')) * 2) = tile
AND m.time BETWEEN t.entry_time AND t.exit_time
Esta consulta divide o eixo de tempo em intervalos e usa um
HASH JOIN para juntar as medidas e carimbos de data/hora nos valores do intervalo, com filtragem fina posteriormente. Veja este artigo no meu blog para explicações mais detalhadas sobre como funciona: