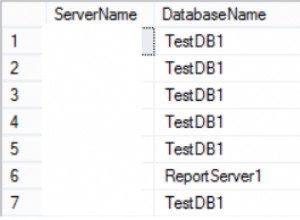
Até que a estrutura da tabela e os dados de amostra de resultados esperados não sejam fornecidos, aqui estão algumas coisas rápidas que vejo que podem ser melhoradas (algumas delas já foram mencionadas por outros acima):
- WHILE Loop também é um cursor. Portanto, mudar para o loop while não tornará as coisas mais rápidas.
- Use o cursor LOCAL FAST_FORWARD, a menos que você precise rastrear um registro. Isso tornaria a execução muito mais rápida.
-
Sim, concordo que ter uma abordagem baseada em SET seria a mais rápida na maioria dos casos, no entanto, se você precisar armazenar um conjunto de resultados intermediário em algum lugar, sugiro usar uma tabela temporária em vez de uma variável de tabela. A tabela temporária é 'menor mal' entre essas 2 opções. Aqui estão algumas razões pelas quais você deve tentar evitar o uso de uma variável de tabela:
- Como o SQL Server não teria nenhuma estatística anterior na variável de tabela durante a construção do Plano de Execução, ele sempre considerará que apenas um registro seria retornado pela variável de tabela durante a construção do plano de execução. E, consequentemente, o Storage Engine atribuiria apenas a mesma quantidade de memória RAM para execução da consulta. Mas, na realidade, pode haver milhões de registros que a variável de tabela pode conter durante a execução. Se isso acontecer, o SQL Server será forçado a derramar os dados no disco rígido durante a execução (e você verá muitos PAGEIOLATCH em sys.dm_os_wait_stats), tornando as consultas muito mais lentas.
- Uma maneira de se livrar do problema acima seria fornecer uma dica de nível de instrução OPTION (RECOMPILE) no final de cada consulta em que um valor de tabela é usado. Isso forçaria o SQL Server a construir o Plano de Execução dessas consultas todas as vezes durante o tempo de execução e o problema de alocação de menos memória pode ser evitado. No entanto, a desvantagem disso é:o SQL Server não poderá mais aproveitar um plano de execução já armazenado em cache para esse procedimento armazenado e exigiria recompilação todas as vezes, o que deterioraria o desempenho em certa medida. Portanto, a menos que você saiba que os dados na tabela subjacente mudam com frequência ou que o próprio procedimento armazenado não é executado com frequência, essa abordagem não é recomendada pelos MVPs da Microsoft.