Como todos esses dados de opinião pública são armazenados? Verificamos um modelo de dados de pesquisa de opinião.
Todos querem saber o que o público pensa, desde políticos e empresas até indivíduos que querem saber o que os outros pensam sobre determinado assunto. Esse tipo de trabalho geralmente é realizado por agências especializadas nesse tipo de pesquisa.
Hoje, vamos dar uma olhada em um modelo de dados que tal agência pode usar para armazenar todos os dados relevantes da pesquisa, desde perguntas e respostas predefinidas até o feedback real. Esses dados seriam usados posteriormente para criar vários relatórios. Então vamos começar.
Ideia
As enquetes podem ser criadas em qualquer lugar. Eles podem ser bem planejados e incluir uma amostra representativa do público (com base na demografia). Ou você pode fazê-los no local, por exemplo. se você quiser prever os resultados das eleições com base em uma amostra (como uma pesquisa de boca de urna), provavelmente perguntará às pessoas na assembleia de voto como elas votaram.
Por outro lado, se você deseja criar a mesma enquete antes da eleição, provavelmente selecionaria uma amostra e entraria em contato com indivíduos por telefone ou pessoalmente. Normalmente, há apenas algumas perguntas para esse tipo de pesquisa – algumas para cobrir dados demográficos e outras para cobrir o que realmente nos interessa.
As pesquisas também podem ser muito mais complexas, por exemplo. se você quiser saber a opinião do público sobre um determinado produto, abrangendo desde seu desempenho até sua embalagem.
Neste artigo, não discutirei como selecionar um conjunto de amostra de pessoas; em vez disso, vou me concentrar na pesquisa em si, suas perguntas e respostas.
Modelo de dados
Modelo de dados da agência de opinião pública
O modelo consiste em três áreas temáticas:
PollsQuestions & AnswersResult
Descreveremos cada área de assunto na ordem em que está listada.
Enquetes
Antes de começarmos a fazer perguntas, precisamos definir em que estamos interessados. Definiremos pesquisas e questionários nesta seção e adicionaremos perguntas e respostas na próxima.
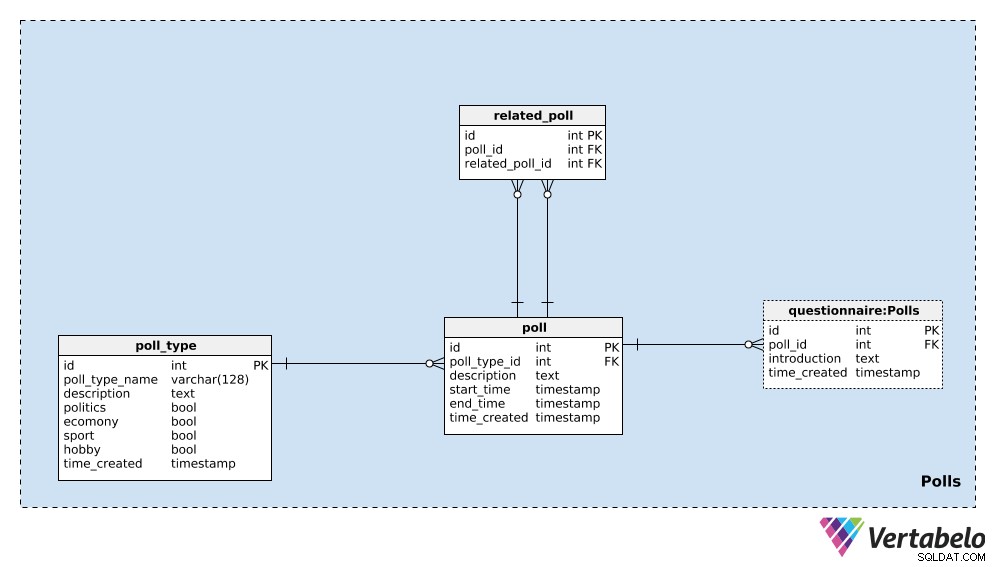
Começaremos com o
poll_type dicionário. Podemos esperar que repetiremos principalmente pesquisas do mesmo tipo. O tipo mais comum é provavelmente as pesquisas eleitorais, mas queremos poder adicionar novos tipos de pesquisas ao longo do caminho. Para cada tipo de enquete, armazenaremos um poll_type_name ÚNICO e use a description atributo para fornecer detalhes adicionais. Quatro bandeiras –
politics , economy , sport e hobby – são usados para denotar o tipo de pesquisa. Uma pesquisa pode abranger um ou mais desses tópicos; se necessário, podemos dividir essas categorias em um dicionário separado e ter uma relação de muitos para muitos entre esse dicionário e o poll_type tabela. O último atributo nesta tabela é
time_created . Denota o momento em que uma linha é inserida nesta tabela. A próxima coisa que precisamos fazer é definir uma única
poll . Esta é uma instância única, e. “Eleições presidenciais dos Estados Unidos em 2020 – pesquisa de abril de 2020” . Para cada enquete, armazenaremos os seguintes detalhes:poll_type_id– Uma referência aopoll_type.description– Todos os detalhes relacionados a esta enquete, em formato textual.start_timeeend_time– Os horários de início e término definidos, durante os quais esta pesquisa é realizada.time_created– O momento real em que esta enquete foi criada.
As enquetes podem ser relacionadas entre si. No exemplo da “Eleições presidenciais dos Estados Unidos de 2020 – pesquisa de abril de 2020” , poderíamos fazer a mesma enquete no próximo mês para ver as opiniões mais atuais. Chamaríamos isso de “Eleições presidenciais dos Estados Unidos de 2020 – pesquisa de maio de 2020” . Essas duas pesquisas estão relacionadas porque seus resultados mostram tendências. Para estabelecer essa relação, usaremos a
related_poll tabela em nosso modelo. Ele contém apenas o par ÚNICO de poll_id – related_poll_id , denotando a votação e seu antecessor. Observe que podemos usar esta tabela para armazenar todas as pesquisas relacionadas de alguma maneira, não apenas predecessoras/sucessoras. Se quiséssemos definir relações diferentes, precisaríamos adicionar outro dicionário – mas não vamos fazer isso neste artigo.
A última tabela nesta área de assunto é o
questionnaire tabela. Na maioria dos casos, cada enquete terá exatamente um questionário, mas quero deixar a opção de que poderíamos ter mais de um, se necessário. Portanto, usei uma tabela separada. Nesta tabela, armazenaremos apenas o ID da enquete relacionada (poll_id ), uma introduction descrevendo aquele questionário, e o timestamp quando o registro foi inserido (time_created ). Perguntas e respostas
Agora estamos prontos para criar todos os detalhes do questionário. Também podemos listar todas as perguntas que queremos fazer, bem como todas as respostas predefinidas.
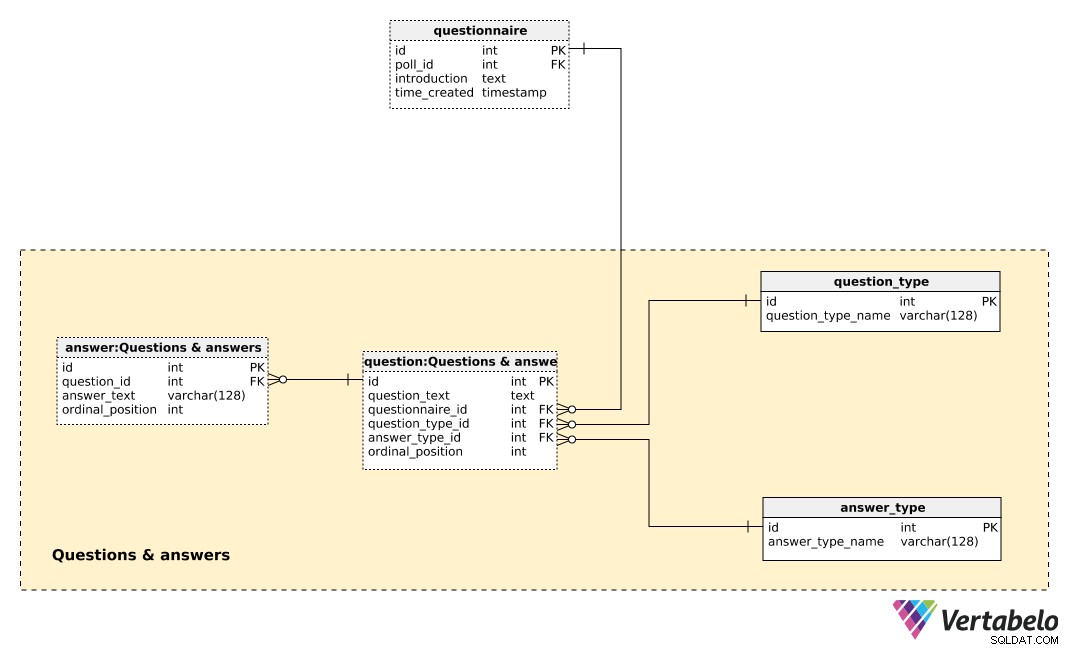
A tabela central nesta área de assunto é a
question tabela. Cada questão é definida pelos seguintes detalhes:question_text– Um texto que será exibido para cada indivíduo pesquisado.questionnaire_id– Uma referência indicando o questionário desta pergunta.question_type_id– Uma referência que denota oquestion_type, que é indicado EXCLUSIVAMENTE peloquestion_type_name. Estas são basicamente categorias, por exemplo. “demografia”, “opinião”, “controle”, etc. Isso nos permitiria separar questões demográficas e de opinião e encontrar uma correlação entre elas.answer_type_id– Uma referência ao tipo de resposta que será usada para esta pergunta. Cadaanswer_typeé definido EXCLUSIVAMENTE peloanswer_type_namee denota como a resposta é exibida. Alguns tipos esperados são "aberto", "lista", "caixa de seleção" e "múltiplo".ordinal_position– Este valor denota a posição desta questão no questionário. Junto com oquestionnaire_id, ele forma a chave alternativa desta tabela.
Uma lista de todas as respostas predefinidas é armazenada em
answer tabela. Se o tipo de pergunta não for aberto (ou seja, o texto não será inserido pelo indivíduo), teremos um conjunto de respostas predefinidas. Para cada resposta, definiremos a pergunta à qual ela pertence (question_id ), o answer_text , e a ordinal_position dessa resposta dentro dessa pergunta. Mais uma vez, um par ÚNICO – desta vez question_id – ordinal_position – forma a chave alternativa desta tabela. Resultado
Nas duas áreas de assunto anteriores, definimos tudo o que precisamos para criar a enquete e começar a fazer perguntas. Agora precisamos definir uma estrutura de dados para armazenar respostas reais.
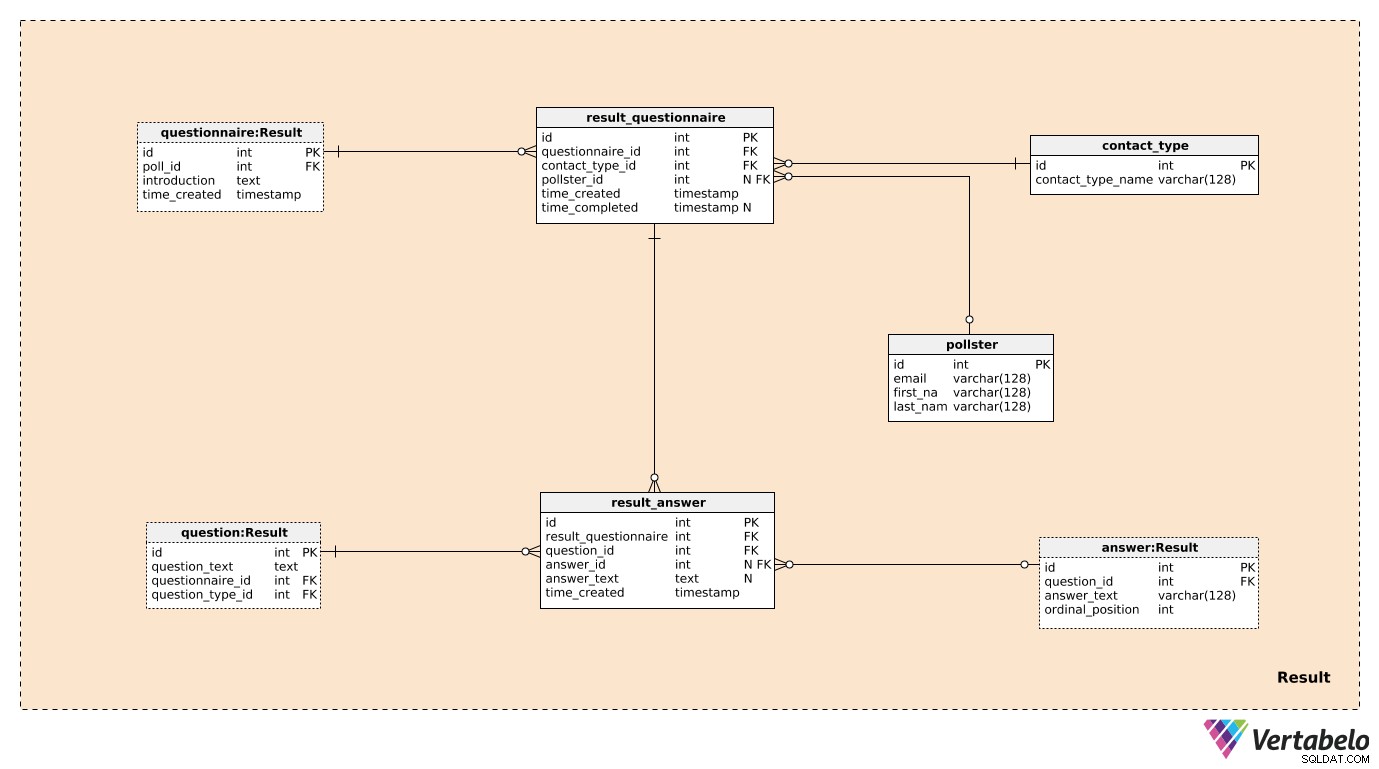
Três das sete tabelas no
Result área temática foram previamente mencionadas e descritas. Estes são questionnaire , question e answer . As quatro tabelas restantes são usadas para armazenar o que realmente nos interessa. Criaremos um registro no
result_questionnaire mesa para cada participante da votação. O questionnaire_id fornecer esus com todas as informações sobre a pesquisa relevante. O contact_type_id é uma referência ao contact_type dicionário. Os valores nesta tabela descrevem a maneira como interagimos com essa pessoa. Esses valores são definidos EXCLUSIVAMENTE pelo contact_type_name valor e pode ser algo como “telefone”, “presencial”, “e-mail”, “formulário da web”, etc. O
pollster_id atributo é uma referência ao pollster tabela, que fornece as informações de quem realizou essa pesquisa real. Para cada pollster , armazenaremos apenas seu e-mail ÚNICO e seu first_name e last_name . O time_created O atributo denota a hora real em que este registro foi criado, enquanto o atributo time_completed será definido no momento em que esta pesquisa for concluída. (Até esse momento, será NULL). A última tabela no modelo é a
result_answer tabela. Como o próprio nome sugere, é aqui que armazenaremos as respostas reais que recebemos dos respondentes. Para cada registro nesta tabela, teremos:result_questionnaire_id– Uma referência ao questionário relevante.question_id– Uma referência indicando a pergunta respondida por esta resposta.answer_id– Uma referência à resposta que foi utilizada para responder a esta pergunta. Este atributo conterá um valor NULL quando a pergunta for do tipo “aberto” (porque não havia respostas predefinidas para escolher).answer_text– O texto que foi inserido para responder a esta pergunta. Este atributo conterá um valor quando a questão for “aberta”; em todos os outros casos, será NULL.time_created– A hora real em que esta resposta foi inserida em nosso sistema.
Possíveis melhorias
Até agora, abordamos como podemos armazenar dados de pesquisa. Não discutimos o que faríamos com os dados após o encerramento da pesquisa. Podemos esperar que não precisaremos dos dados antigos no futuro, pelo menos não em nosso banco de dados operacional. Portanto, poderíamos fazer duas coisas:
- Armazene um resumo de pesquisa em uma tabela separada no banco de dados operacional. Isso manteria essas informações à nossa disposição se quiséssemos ver o que aconteceu com uma pesquisa semelhante.
- Armazene todos os dados de pesquisa em um banco de dados de backup que tenha a mesma estrutura do banco de dados operacional. Isso nos permitiria acessar os detalhes quando precisássemos deles.
Também poderíamos criar um data warehouse para armazenar os resultados da pesquisa, mas isso não seria necessário se já tivéssemos feito as tarefas descritas nos dois pontos.
O que você acha do nosso modelo de dados de pesquisa de opinião?
Gostaríamos de ouvir sua opinião sobre o que podemos mudar para melhorar o modelo de dados da pesquisa de opinião. Você tem experiência no setor? Você acha que perdemos alguma coisa? Você adicionaria ou removeria algo? Ansioso para ouvir suas opiniões.



