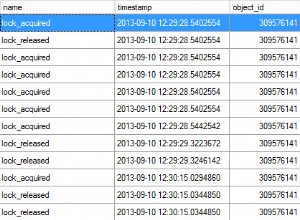
Isso é completamente previsível e esperado devido à precedência de tipo de dados
Para isso, a coluna da interface do usuário será alterada para decimal(25,0)
where UI = 2011040773395012950010370
Este está quase correto. O lado direito é varchar e é alterado para nvarchar
where UI = '2011040773395012950010370'
Este é o realmente versão correta onde ambos os tipos são os mesmos
where UI = N'2011040773395012950010370'
Os erros terão começado porque a coluna da interface do usuário agora contém um valor que não será CAST para decimal(25,0).
Algumas notas não relacionadas:
- se você tiver um índice na coluna da interface do usuário, ele será ignorado na primeira versão devido ao CAST implícito obrigatório
- você precisa de unicode para armazenar dígitos numéricos? Há uma sobrecarga séria com tipos de dados unicode em armazenamento e desempenho
- por que não usar
char(25)ounchar(25)os valores são sempre de comprimento fixo? Suas consultas usam muito memória como o otimizador assume um comprimento médio de 128 caracteres com base emnvarchar(256)
Editar, após comentário
Não assuma "por que isso funciona às vezes" quando você não sabe que isso funciona
Exemplos:
- O valor pode ter sido excluído e adicionado posteriormente
- Uma cláusula TOP ou SET ROWCOUNT pode significar que o valor incorreto não foi alcançado
- A consulta nunca foi executada, portanto não pode falhar
- O erro é ignorado silenciosamente por algum outro código?
Edite 2 para obter mais clareza
Conversar
gbn:
Aleatório:
gbn
Como Tao menciona , é importante entender que outro não relacionado pode interromper a consulta, mesmo que este esteja OK.