Recovery Time Objective (RTO) é o período de tempo dentro do qual um serviço deve ser restaurado para evitar consequências inaceitáveis. Ao calcular quanto tempo pode levar para se recuperar de uma falha no banco de dados, podemos saber qual o nível de preparação necessário. Se o RTO for de alguns minutos, será necessário um investimento significativo em failover. Um RTO de 36 horas requer um investimento significativamente menor. É aí que entra a automação de failover.
Em nossos blogs anteriores, discutimos o failover para MongoDB, MySQL/MariaDB/Percona, PostgreSQL ou TimeScaleDB. Para resumir, "Failover " é a capacidade de um sistema continuar funcionando mesmo se ocorrer alguma falha. Ela sugere que as funções do sistema são assumidas por componentes secundários se os componentes primários falharem. Failover é uma parte natural de qualquer sistema de alta disponibilidade e, em alguns casos, , ele ainda precisa ser automatizado. Failovers manuais demoram muito, mas há casos em que a automação não funcionará bem - por exemplo, no caso de um cérebro dividido em que a replicação do banco de dados é interrompida e as duas 'metades' continuam recebendo atualizações, efetivamente levando a conjuntos de dados divergentes e inconsistência.
Anteriormente, escrevemos sobre os princípios orientadores por trás dos procedimentos de failover automático do ClusterControl. Sempre que possível, o failover automatizado fornece eficiência, pois permite a recuperação rápida de falhas. Neste blog, veremos como obter failover automático em uma configuração de replicação mestre-escravo (ou em espera primária) usando o ClusterControl.
Requisitos de pilha de tecnologia
Uma pilha pode ser montada a partir de componentes de software de código aberto e há várias opções disponíveis - algumas mais apropriadas que outras, dependendo das características de failover e também do nível de conhecimento disponível para gerenciar e manter a solução. Hardware e rede também são aspectos importantes.
Software
Há muitas opções disponíveis no ecossistema de código aberto que você pode usar para implementar o failover. Para MySQL, você pode aproveitar MHA, MMM, Maxscale/MRM, mysqlfailover ou Orchestrator. Este blog anterior compara o MaxScale ao MHA ao Maxscale/MRM. O PostgreSQL tem repmgr, Patroni, PostgreSQL Automatic Failover (PAF), pglookout, pgPool-II ou stolon. Essas diferentes opções de alta disponibilidade foram abordadas anteriormente. O MongoDB possui conjuntos de réplicas com suporte para failover automatizado.
O ClusterControl fornece funcionalidade de failover automático para MySQL, MariaDB, PostgreSQL e MongoDB, que abordaremos mais adiante. Vale a pena notar que também possui funcionalidade para recuperar automaticamente nós ou clusters quebrados.
Hardware
O failover automático geralmente é executado por um servidor daemon separado que é configurado em seu próprio hardware - separado dos nós do banco de dados. Ele está monitorando o status dos bancos de dados e usa as informações para tomar decisões sobre como reagir em caso de falha.
Os servidores de commodities podem funcionar bem, a menos que o servidor esteja monitorando um grande número de instâncias. Normalmente, as verificações do sistema e a análise de integridade são leves em termos de processamento. No entanto, se você tiver um grande número de nós para verificar, uma CPU e memória grandes são essenciais, especialmente quando as verificações precisam ser enfileiradas enquanto tenta executar ping e coletar informações dos servidores. Os nós que estão sendo monitorados e supervisionados podem parar às vezes devido a problemas de rede, carga alta ou, na pior das hipóteses, podem estar inativos devido a uma falha de hardware ou a alguma corrupção do host da VM. Portanto, o servidor que executa as verificações de integridade e sistema deve ser capaz de suportar tais paralisações, pois as chances são de que o processamento de filas possa subir, pois as respostas a cada um dos nós monitorados podem levar algum tempo até que seja verificado que não está mais disponível ou um tempo limite foi foi alcançado.
Para ambientes baseados em nuvem, existem serviços que oferecem failover automático. Por exemplo, o Amazon RDS usa o DRBD para replicar o armazenamento para um nó em espera. Ou se você estiver armazenando seus volumes no EBS, eles serão replicados em várias zonas.
Rede
O software de failover automatizado geralmente depende de agentes configurados nos nós do banco de dados. O agente coleta informações localmente da instância do banco de dados e as envia ao servidor, sempre que solicitado.
Em termos de requisitos de rede, certifique-se de ter uma boa largura de banda e uma conexão de rede estável. As verificações precisam ser feitas com frequência e as pulsações perdidas devido a uma rede instável podem levar o software de failover a (erroneamente) deduzir que um nó está inativo.
O ClusterControl não requer nenhum agente instalado nos nós do banco de dados, pois fará SSH em cada nó do banco de dados em intervalos regulares e realizará várias verificações.
Failover automatizado com ClusterControl
O ClusterControl oferece a capacidade de realizar failovers manuais e automatizados. Vamos ver como isso pode ser feito.
O failover no ClusterControl pode ser configurado para ser automático ou não. Se preferir cuidar do failover manualmente, você pode desabilitar a recuperação automatizada de cluster. Ao fazer um failover manual, você pode ir para Cluster → Topologia em ClusterControl. Veja a imagem abaixo:
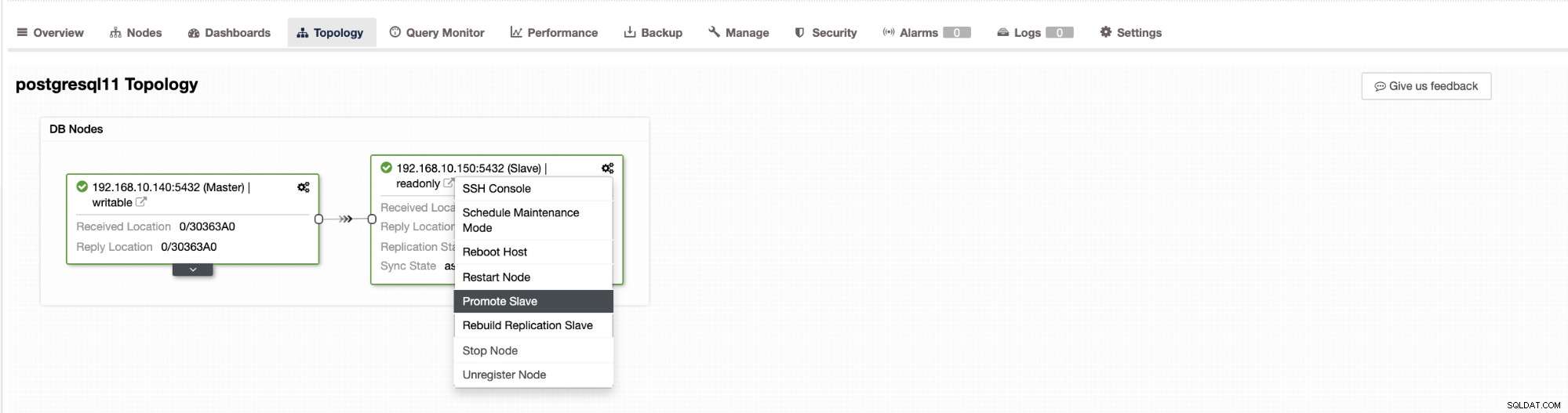
Por padrão, a recuperação de cluster é habilitada e o failover automatizado é usado. Depois de fazer alterações na interface do usuário, a configuração do tempo de execução é alterada. Se você quiser que a configuração sobreviva a uma reinicialização do controlador, certifique-se de também fazer a alteração na configuração do cmon, ou seja, /etc/cmon.d/cmon_

No servidor MySQL/MariaDB/Percona, o failover automático é iniciado pelo ClusterControl quando detecta que não há host com read_only bandeira desabilitada. Isso pode acontecer porque master (que tem read_only definido como 0) não está disponível ou pode ser acionado por um usuário ou algum software externo que alterou este sinalizador no mestre. Se você fizer alterações manuais nos nós do banco de dados ou tiver um software que possa mexer nas configurações read_only, desative o failover automático. O failover automatizado do ClusterControl é tentado apenas uma vez, portanto, um failover com falha não será seguido novamente por um failover subsequente - não até que o cmon seja reiniciado.
Para o PostgreSQL, o ClusterControl escolherá o slave mais avançado, utilizando para isso o pg_current_xlog_location (PostgreSQL 9+) ou pg_current_wal_lsn (PostgreSQL 10+) dependendo da versão do nosso banco de dados. O ClusterControl também realiza várias verificações sobre o processo de failover, a fim de evitar alguns erros comuns. Um exemplo é que se conseguirmos recuperar nosso antigo mestre com falha, ele "não " ser reintroduzido automaticamente no cluster, nem como mestre nem como escravo. Precisamos fazê-lo manualmente. Isso evitará a possibilidade de perda de dados ou inconsistência no caso de nosso escravo (que promovemos) estar atrasado no momento Também podemos analisar o problema em detalhes antes de reintroduzi-lo na configuração de replicação, para preservar as informações de diagnóstico.
Além disso, se o failover falhar, nenhuma tentativa adicional será feita (isso se aplica a clusters baseados em PostgreSQL e MySQL), a intervenção manual é necessária para analisar o problema e executar as ações correspondentes. Isso é para evitar a situação em que o ClusterControl, que trata do failover automático, tenta promover o próximo escravo e o próximo. Pode haver um problema e não queremos piorar as coisas tentando vários failovers.
O ClusterControl oferece whitelisting e blacklisting de um conjunto de servidores que você deseja que participem do failover ou excluam como candidatos.
Para clusters do tipo MySQL, o ClusterControl cria uma lista de escravos que podem ser promovidos a mestres. Na maioria das vezes, conterá todos os escravos na topologia, mas o usuário tem algum controle adicional sobre ela. Existem duas variáveis que você pode definir na configuração do cmon:
replication_failover_whiteliste
replication_failover_blacklistPara a variável de configuração replication_failover_whitelist, ela contém uma lista de IPs ou nomes de host de escravos que devem ser usados como potenciais candidatos a mestres. Se esta variável for definida, apenas esses hosts serão considerados. Para a variável replication_failover_blacklist, ela contém uma lista de hosts que nunca serão considerados um candidato mestre. Você pode usá-lo para listar escravos que são usados para backups ou consultas analíticas. Se o hardware varia entre os escravos, você pode querer colocar aqui os escravos que usam hardware mais lento.
replication_failover_whitelist tem precedência, o que significa que replication_failover_blacklist é ignorado se replication_failover_whitelist estiver definido.
Uma vez que a lista de escravos que podem ser promovidos a mestres está pronta, o ClusterControl começa a comparar seus estados, procurando o escravo mais atualizado. Aqui, o manuseio de configurações baseadas em MariaDB e MySQL é diferente. Para configurações do MariaDB, o ClusterControl escolhe um escravo que tenha o menor atraso de replicação de todos os escravos disponíveis. Para configurações do MySQL, o ClusterControl também escolhe esse escravo, mas verifica se há transações adicionais ausentes que podem ter sido executadas em alguns dos escravos restantes. Se tal transação for encontrada, o ClusterControl escraviza o candidato mestre desse host para recuperar todas as transações ausentes. Você pode pular esse processo e usar apenas o slave mais avançado definindo a variável replication_skip_apply_missing_txs em sua configuração CMON:
por exemplo.
replication_skip_apply_missing_txs=1Consulte nossa documentação aqui para obter mais informações com variáveis.
A advertência é que você só deve definir isso se souber o que está fazendo, pois pode haver transações errôneas. Isso pode causar falhas na replicação, bem como inconsistência de dados no cluster. Se a transação errônea aconteceu no passado, ela pode não estar mais disponível em logs binários. Nesse caso, a replicação será interrompida porque os escravos não poderão recuperar os dados ausentes. Portanto, o ClusterControl, por padrão, verifica todas as transações errôneas antes de promover um candidato a mestre a se tornar um mestre. Se tal problema for detectado, o switch mestre é abortado e o ClusterControl permite que o usuário corrija o problema manualmente.
Se você quiser ter 100% de certeza de que o ClusterControl promoverá um novo mestre mesmo que alguns problemas sejam detectados, você pode fazer isso usando a variável replication_stop_on_error. Ver abaixo:
por exemplo.
replication_stop_on_error=0Defina esta variável em seu arquivo de configuração cmon. Como mencionado anteriormente, isso pode levar a problemas com a replicação, pois os escravos podem começar a solicitar um evento de log binário que não está mais disponível. Para lidar com esses casos, adicionamos suporte experimental para reconstrução de escravos. Se você definir a variável
replication_auto_rebuild_slave=1na configuração do cmon e se o seu slave estiver marcado como inativo com o seguinte erro no MySQL:
Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'O ClusterControl tentará reconstruir o escravo usando dados do mestre. Essa configuração pode nem sempre ser apropriada, pois o processo de reconstrução induzirá um aumento de carga no mestre. Também pode ser que seu conjunto de dados seja muito grande e uma reconstrução regular não seja uma opção - é por isso que esse comportamento está desabilitado por padrão.
Uma vez que garantimos que não existe nenhuma transação errônea e estamos prontos, ainda há mais um problema que precisamos resolver de alguma forma - pode acontecer que todos os escravos estejam atrasados em relação ao mestre.
Como você provavelmente sabe, a replicação no MySQL funciona de maneira bastante simples. O mestre armazena gravações em logs binários. O encadeamento de E/S do escravo se conecta ao mestre e extrai quaisquer eventos de log binários que estejam faltando. Em seguida, ele os armazena na forma de logs de retransmissão. O thread SQL os analisa e aplica eventos. O atraso do escravo é uma condição na qual o thread (ou threads) SQL não consegue lidar com o número de eventos e não consegue aplicá-los assim que são puxados do mestre pelo thread de E/S. Tal situação pode acontecer independentemente do tipo de replicação que você está usando. Mesmo se você usar a replicação semi-síncrona, ela só pode garantir que todos os eventos do mestre sejam armazenados em um dos escravos no log de retransmissão. Não diz nada sobre a aplicação desses eventos a um escravo.
O problema aqui é que, se um escravo for promovido a mestre, os logs de retransmissão serão apagados. Se um escravo estiver atrasado e não tiver aplicado todas as transações, ele perderá dados - os eventos que ainda não foram aplicados dos logs de retransmissão serão perdidos para sempre.
Não existe uma forma única de resolver esta situação. ClusterControl dá aos usuários controle sobre como isso deve ser feito, mantendo padrões seguros. Isso é feito na configuração cmon usando a seguinte configuração:
replication_failover_wait_to_apply_timeout=-1Por padrão, ele assume um valor de '-1', o que significa que o failover não acontecerá imediatamente se um candidato mestre estiver atrasado, portanto, é configurado para aguardar para sempre, a menos que o candidato tenha alcançado. O ClusterControl aguardará indefinidamente para que ele aplique todas as transações ausentes de seus logs de retransmissão. Isso é seguro, mas, se por algum motivo, o slave mais atualizado estiver com um atraso muito grande, o failover pode levar horas para ser concluído. Do outro lado do espectro está definindo-o como '0' - significa que o failover acontece imediatamente, não importa se o candidato mestre está atrasado ou não. Você também pode seguir o caminho do meio e configurá-lo para algum valor. Isso definirá um tempo em segundos, por exemplo, 30 segundos, então defina a variável para,
replication_failover_wait_to_apply_timeout=30Quando definido como> 0, o ClusterControl aguardará que um candidato mestre aplique transações ausentes de seus logs de retransmissão até que o valor seja atingido (que é de 30 segundos no exemplo). O failover ocorre após o tempo definido ou quando o candidato mestre alcançará a replicação, o que ocorrer primeiro. Essa pode ser uma boa escolha se sua aplicação tiver requisitos específicos em relação ao tempo de inatividade e você precisar eleger um novo mestre em um curto período de tempo.
Para obter mais detalhes sobre como o ClusterControl funciona com failover automático no PostgreSQL e MySQL, confira nossos blogs anteriores intitulados "Failover for PostgreSQL Replication 101" e "Failover automático de MySQL Replication - New in ClusterControl 1.4".
Conclusão
O Failover automatizado é um recurso valioso, especialmente para empresas que exigem operações 24 horas por dia, 7 dias por semana, com tempo de inatividade mínimo. A empresa deve definir quanto controle é dado ao processo de automação durante interrupções não planejadas. Uma solução de alta disponibilidade como o ClusterControl oferece um nível personalizável de interação no processamento de failover. Para algumas organizações, o failover automatizado pode não ser uma opção, mesmo que a interação do usuário durante o failover possa consumir tempo e afetar o RTO. A suposição é que é muito arriscado caso o failover automatizado não funcione corretamente ou, pior ainda, resulte em dados confusos e parcialmente ausentes (embora se possa argumentar que um humano também pode cometer erros desastrosos que levam a consequências semelhantes). Aqueles que preferem manter o controle sobre seu banco de dados podem optar por ignorar o failover automatizado e usar um processo manual. Esse processo leva mais tempo, mas permite que um administrador experiente avalie o estado de um sistema e tome ações corretivas com base no que aconteceu.



