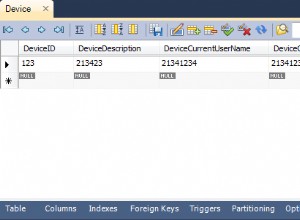
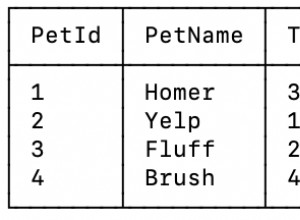
Se entendi corretamente, você deseja contar entradas distintas para um status específico em seu período de tempo... se for assim, você deve usar o
DISTINCT cláusula em seu count() mudando de count(*) para count(distinto Entry_id) with c (Status_Id, Entry_Id, Start_Date) AS (
select Status_Id, Entry_Id, Start_Date from tbl where
(End_Date BETWEEN '19000101' AND '21000101')
AND ((Start_Date BETWEEN '19000101' AND '21000101')
OR End_Date <= '21000101'))
select Status_Id, count(distinct Entry_Id) as cnt from
(select Entry_Id, max(start_date) as start_date from c
group by Entry_Id) d inner join
c on c.Entry_Id = d.Entry_Id
and c.start_date = d.start_date
GROUP BY Status_Id WITH ROLLUP
EDITAR
Contanto que você não se importe com qual status é retornado para uma determinada entrada, acho que você pode modificar a consulta interna para retornar o primeiro status e ingressar no status também
with c (Status_Id, Entry_Id, Start_Date) AS (
select Status_Id, Entry_Id, Start_Date from tbl where
(End_Date BETWEEN '19000101' AND '21000101')
AND ((Start_Date BETWEEN '19000101' AND '21000101')
OR End_Date <= '21000101'))
select c.Status_Id, count(c.Entry_Id) as cnt from
(select Entry_Id, Start_Date, (select top 1 Status_id from c where Entry_Id = CC.Entry_Id and Start_Date = CC.Start_Date) as Status_Id
from (select Entry_Id, max(start_date) as start_date from c
group by Entry_Id) as CC) d inner join
c on c.Entry_Id = d.Entry_Id
and c.start_date = d.start_date
and c.status_id = d.status_id
GROUP BY c.Status_Id
Resultado
Status_id Count
489 2
492 1
495 1