O otimizador do SQL Server contém lógica para remover junções redundantes, mas há restrições, e as junções devem ser provavelmente redundante . Para resumir, uma junção pode ter quatro efeitos:
- Pode adicionar colunas extras (da tabela unida)
- Pode adicionar linhas extras (a tabela unida pode corresponder a uma linha de origem mais de uma vez)
- Ele pode remover linhas (a tabela unida pode não ter uma correspondência)
- Pode introduzir
NULLs (para umRIGHTouFULL JOIN)
Para remover com sucesso uma junção redundante, a consulta (ou exibição) deve levar em conta todas as quatro possibilidades. Quando isso é feito, corretamente, o efeito pode ser surpreendente. Por exemplo:
USE AdventureWorks2012;
GO
CREATE VIEW dbo.ComplexView
AS
SELECT
pc.ProductCategoryID, pc.Name AS CatName,
ps.ProductSubcategoryID, ps.Name AS SubCatName,
p.ProductID, p.Name AS ProductName,
p.Color, p.ListPrice, p.ReorderPoint,
pm.Name AS ModelName, pm.ModifiedDate
FROM Production.ProductCategory AS pc
FULL JOIN Production.ProductSubcategory AS ps ON
ps.ProductCategoryID = pc.ProductCategoryID
FULL JOIN Production.Product AS p ON
p.ProductSubcategoryID = ps.ProductSubcategoryID
FULL JOIN Production.ProductModel AS pm ON
pm.ProductModelID = p.ProductModelID
O otimizador pode simplificar com sucesso a seguinte consulta:
SELECT
c.ProductID,
c.ProductName
FROM dbo.ComplexView AS c
WHERE
c.ProductName LIKE N'G%';
Para:

Rob Farley escreveu sobre essas ideias em profundidade no livro original MVP Deep Dives , e há uma gravação dele apresentando sobre o tema em SQLBits.
As principais restrições são que os relacionamentos de chave estrangeira deve ser baseado em uma única chave para contribuir para o processo de simplificação, e o tempo de compilação para as consultas em tal visão pode se tornar bastante longo, especialmente à medida que o número de junções aumenta. Pode ser um grande desafio escrever uma visão de 100 tabelas que tenha toda a semântica exatamente correta. Eu estaria inclinado a encontrar uma solução alternativa, talvez usando SQL dinâmico .
Dito isso, as qualidades particulares de sua tabela desnormalizada podem significar que a visualização é bastante simples de montar, exigindo apenas
FOREIGN KEYs obrigatórias não-NULL colunas referenciadas capazes e UNIQUE apropriados restrições para fazer esta solução funcionar como você espera, sem a sobrecarga de 100 operadores de junção física no plano. Exemplo
Usando dez tabelas em vez de cem:
-- Referenced tables
CREATE TABLE dbo.Ref01 (col01 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref02 (col02 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref03 (col03 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref04 (col04 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref05 (col05 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref06 (col06 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref07 (col07 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref08 (col08 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref09 (col09 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref10 (col10 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
A definição da tabela pai (com compactação de página):
CREATE TABLE dbo.Normalized
(
pk integer IDENTITY NOT NULL,
col01 tinyint NOT NULL REFERENCES dbo.Ref01,
col02 tinyint NOT NULL REFERENCES dbo.Ref02,
col03 tinyint NOT NULL REFERENCES dbo.Ref03,
col04 tinyint NOT NULL REFERENCES dbo.Ref04,
col05 tinyint NOT NULL REFERENCES dbo.Ref05,
col06 tinyint NOT NULL REFERENCES dbo.Ref06,
col07 tinyint NOT NULL REFERENCES dbo.Ref07,
col08 tinyint NOT NULL REFERENCES dbo.Ref08,
col09 tinyint NOT NULL REFERENCES dbo.Ref09,
col10 tinyint NOT NULL REFERENCES dbo.Ref10,
CONSTRAINT PK_Normalized
PRIMARY KEY CLUSTERED (pk)
WITH (DATA_COMPRESSION = PAGE)
);
A vista:
CREATE VIEW dbo.Denormalized
WITH SCHEMABINDING AS
SELECT
item01 = r01.item,
item02 = r02.item,
item03 = r03.item,
item04 = r04.item,
item05 = r05.item,
item06 = r06.item,
item07 = r07.item,
item08 = r08.item,
item09 = r09.item,
item10 = r10.item
FROM dbo.Normalized AS n
JOIN dbo.Ref01 AS r01 ON r01.col01 = n.col01
JOIN dbo.Ref02 AS r02 ON r02.col02 = n.col02
JOIN dbo.Ref03 AS r03 ON r03.col03 = n.col03
JOIN dbo.Ref04 AS r04 ON r04.col04 = n.col04
JOIN dbo.Ref05 AS r05 ON r05.col05 = n.col05
JOIN dbo.Ref06 AS r06 ON r06.col06 = n.col06
JOIN dbo.Ref07 AS r07 ON r07.col07 = n.col07
JOIN dbo.Ref08 AS r08 ON r08.col08 = n.col08
JOIN dbo.Ref09 AS r09 ON r09.col09 = n.col09
JOIN dbo.Ref10 AS r10 ON r10.col10 = n.col10;
Hackeie as estatísticas para fazer o otimizador pensar que a tabela é muito grande:
UPDATE STATISTICS dbo.Normalized WITH ROWCOUNT = 100000000, PAGECOUNT = 5000000;
Exemplo de consulta do usuário:
SELECT
d.item06,
d.item07
FROM dbo.Denormalized AS d
WHERE
d.item08 = 'Banana'
AND d.item01 = 'Green';
Nos dá este plano de execução:
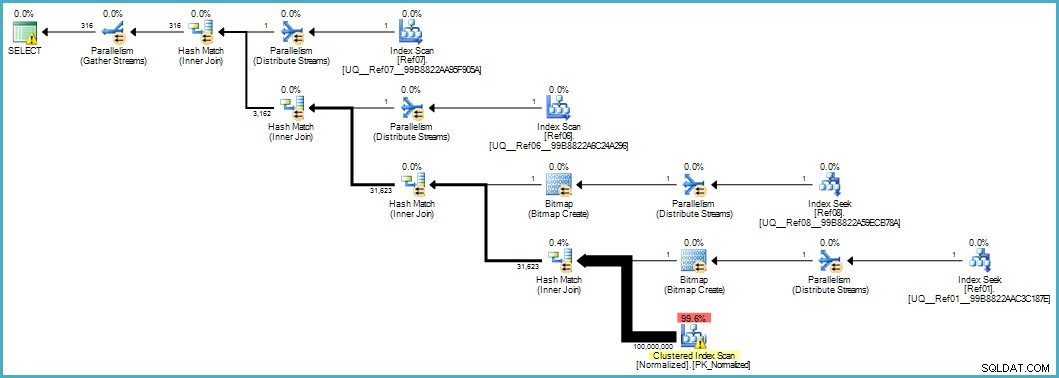
A verificação da tabela Normalizada parece ruim, mas ambos os bitmaps do filtro Bloom são aplicados durante a verificação pelo mecanismo de armazenamento (assim, as linhas que não podem corresponder nem chegam ao processador de consulta). Isso pode ser suficiente para fornecer um desempenho aceitável no seu caso e certamente melhor do que digitalizar a tabela original com suas colunas transbordantes.
Se você conseguir atualizar para o SQL Server 2012 Enterprise em algum momento, terá outra opção:criar um índice de armazenamento de colunas na tabela Normalizada:
CREATE NONCLUSTERED COLUMNSTORE INDEX cs
ON dbo.Normalized (col01,col02,col03,col04,col05,col06,col07,col08,col09,col10);
O plano de execução é:
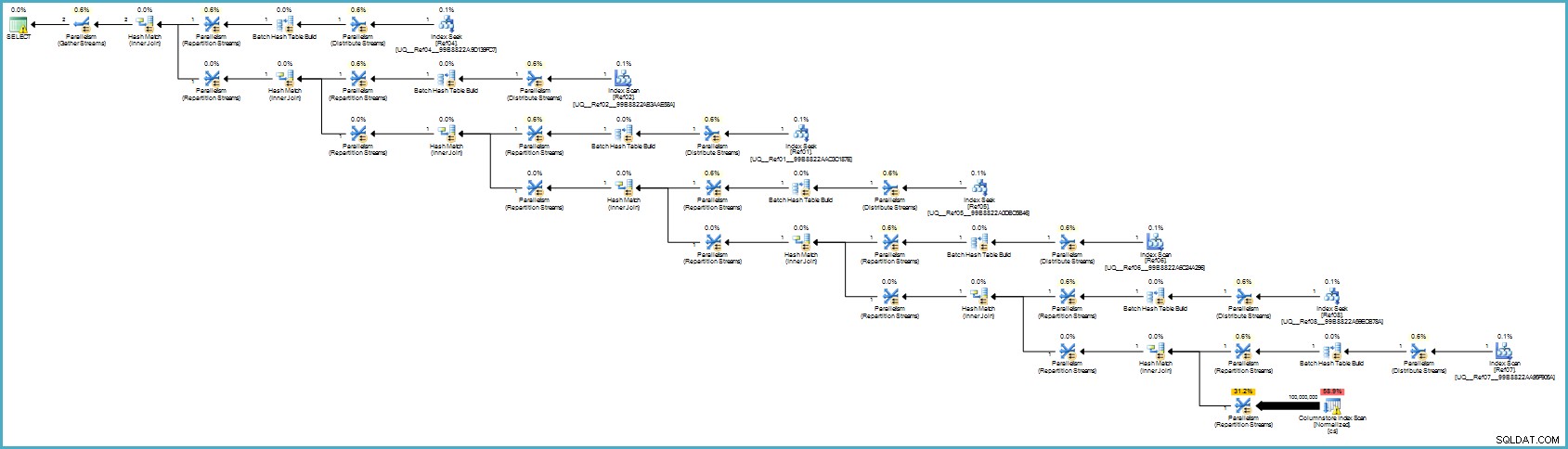
Isso provavelmente parece pior para você, mas o armazenamento de colunas fornece compactação excepcional e todo o plano de execução é executado no modo de lote com filtros para todas as colunas de contribuição. Se o servidor tiver threads e memória adequados disponíveis, essa alternativa pode realmente voar.
Por fim, não tenho certeza se essa normalização é a abordagem correta, considerando o número de tabelas e as chances de obter um plano de execução ruim ou exigir tempo de compilação excessivo. Eu provavelmente corrigiria primeiro o esquema da tabela desnormalizada (tipos de dados adequados e assim por diante), possivelmente aplicaria a compactação de dados... as coisas usuais.
Se os dados realmente pertencem a um esquema em estrela, ele provavelmente precisa de mais trabalho de design do que apenas dividir elementos de dados repetidos em tabelas separadas.