Vejo muitos conselhos por aí que dizem algo como "Mude seu cursor para uma operação baseada em conjunto; isso o tornará mais rápido". Embora isso muitas vezes possa ser o caso, nem sempre é verdade. Um caso de uso que vejo em que um cursor supera repetidamente a abordagem típica baseada em conjunto é o cálculo de totais em execução. Isso ocorre porque a abordagem baseada em conjunto geralmente precisa examinar alguma parte dos dados subjacentes mais de uma vez, o que pode ser uma coisa exponencialmente ruim à medida que os dados aumentam; enquanto um cursor – por mais doloroso que possa parecer – pode percorrer cada linha/valor exatamente uma vez.
Essas são nossas opções básicas nas versões mais comuns do SQL Server. No SQL Server 2012, no entanto, houve vários aprimoramentos feitos nas funções de janela e na cláusula OVER, principalmente decorrentes de várias ótimas sugestões enviadas pelo colega MVP Itzik Ben-Gan (aqui está uma de suas sugestões). Na verdade, Itzik tem um novo livro MS-Press que cobre todos esses aprimoramentos com muito mais detalhes, intitulado "Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions".
Então, naturalmente, eu estava curioso; a nova funcionalidade de janelas tornaria obsoletas as técnicas de cursor e auto-junção? Seriam mais fáceis de codificar? Eles seriam mais rápidos em algum (não importa em todos) casos? Que outras abordagens podem ser válidas?
A configuração
Para fazer alguns testes, vamos configurar um banco de dados:
USE [master];
GO
IF DB_ID('RunningTotals') IS NOT NULL
BEGIN
ALTER DATABASE RunningTotals SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE RunningTotals;
END
GO
CREATE DATABASE RunningTotals;
GO
USE RunningTotals;
GO
SET NOCOUNT ON;
GO E, em seguida, preencha uma tabela com 10.000 linhas que podemos usar para realizar alguns totais em execução. Nada muito complicado, apenas uma tabela de resumo com uma linha para cada data e um número representando quantas multas por excesso de velocidade foram emitidas. Eu não tenho uma multa por excesso de velocidade há alguns anos, então não sei por que essa foi minha escolha subconsciente para um modelo de dados simplista, mas aí está.
CREATE TABLE dbo.SpeedingTickets ( [Date] DATE NOT NULL, TicketCount INT ); GO ALTER TABLE dbo.SpeedingTickets ADD CONSTRAINT pk PRIMARY KEY CLUSTERED ([Date]); GO ;WITH x(d,h) AS ( SELECT TOP (250) ROW_NUMBER() OVER (ORDER BY [object_id]), CONVERT(INT, RIGHT([object_id], 2)) FROM sys.all_objects ORDER BY [object_id] ) INSERT dbo.SpeedingTickets([Date], TicketCount) SELECT TOP (10000) d = DATEADD(DAY, x2.d + ((x.d-1)*250), '19831231'), x2.h FROM x CROSS JOIN x AS x2 ORDER BY d; GO SELECT [Date], TicketCount FROM dbo.SpeedingTickets ORDER BY [Date]; GO
Resultados resumidos:
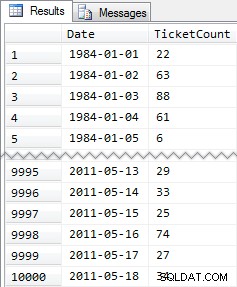
Então, novamente, 10.000 linhas de dados bastante simples – pequenos valores INT e uma série de datas de 1984 a maio de 2011.
As abordagens
Agora, minha tarefa é relativamente simples e típica de muitos aplicativos:retornar um conjunto de resultados que tenha todas as 10.000 datas, juntamente com o total acumulado de todas as multas por excesso de velocidade até e incluindo essa data. A maioria das pessoas tentaria primeiro algo assim (chamaremos isso de "junção interna " método):
SELECT st1.[Date], st1.TicketCount, RunningTotal = SUM(st2.TicketCount) FROM dbo.SpeedingTickets AS st1 INNER JOIN dbo.SpeedingTickets AS st2 ON st2.[Date] <= st1.[Date] GROUP BY st1.[Date], st1.TicketCount ORDER BY st1.[Date];
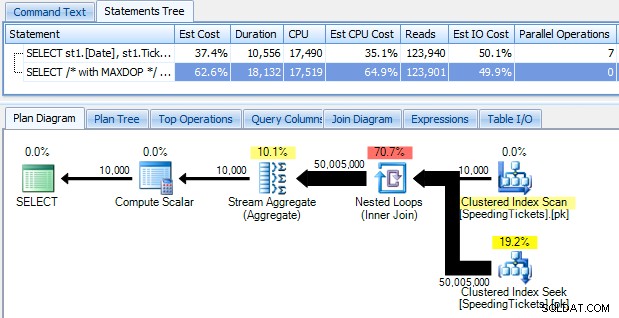
…e fique chocado ao descobrir que leva quase 10 segundos para ser executado. Vamos examinar rapidamente o motivo visualizando o plano de execução gráfico, usando o SQL Sentry Plan Explorer:

As setas grandes e grossas devem fornecer uma indicação imediata do que está acontecendo:o loop aninhado lê uma linha para a primeira agregação, duas linhas para a segunda, três linhas para a terceira e assim por diante por todo o conjunto de 10.000 linhas. Isso significa que devemos ver aproximadamente ((10.000 * (10.000 + 1)) / 2) linhas processadas assim que todo o conjunto for percorrido, e isso parece corresponder ao número de linhas mostradas no plano.
Observe que executar a consulta sem paralelismo (usando a dica de consulta OPTION (MAXDOP 1)) torna a forma do plano um pouco mais simples, mas não ajuda em nada no tempo de execução ou na E/S; como mostrado no plano, a duração na verdade quase dobra e as leituras diminuem apenas em uma porcentagem muito pequena. Comparando com o plano anterior:
Existem muitas outras abordagens que as pessoas tentaram obter totais de execução eficientes. Um exemplo é o "método de subconsulta " que usa apenas uma subconsulta correlacionada da mesma maneira que o método de junção interna descrito acima:
SELECT [Date], TicketCount, RunningTotal = TicketCount + COALESCE( ( SELECT SUM(TicketCount) FROM dbo.SpeedingTickets AS s WHERE s.[Date] < o.[Date]), 0 ) FROM dbo.SpeedingTickets AS o ORDER BY [Date];
Comparando esses dois planos:
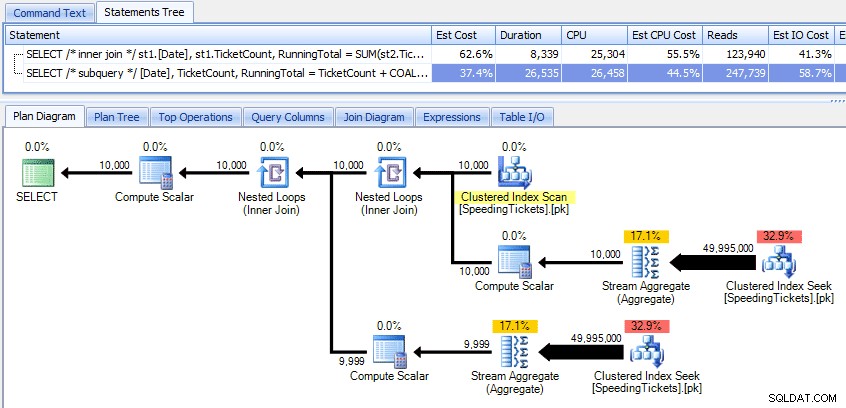
Portanto, embora o método de subconsulta pareça ter um plano geral mais eficiente, é pior onde importa:duração e E/S. Podemos ver o que contribui para isso aprofundando os planos um pouco mais. Movendo-se para a guia Top Operations, podemos ver que no método inner join, a busca de índice clusterizado é executada 10.000 vezes, e todas as outras operações são executadas apenas algumas vezes. No entanto, várias operações são executadas 9.999 ou 10.000 vezes no método de subconsulta:
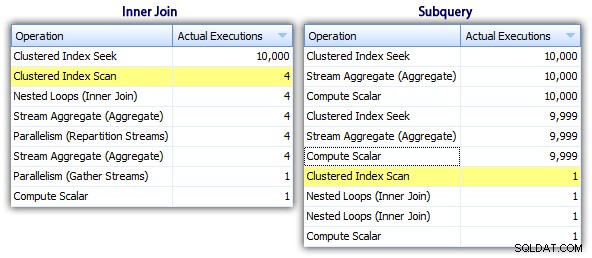
Portanto, a abordagem de subconsulta parece ser pior, não melhor. O próximo método que tentaremos, chamarei de "atualização peculiar ". Não é exatamente garantido que funcione, e eu nunca o recomendaria para código de produção, mas estou incluindo-o para ser completo. Basicamente, a atualização peculiar aproveita o fato de que durante uma atualização você pode redirecionar a atribuição e a matemática para que a variável é incrementada nos bastidores à medida que cada linha é atualizada.
DECLARE @st TABLE ( [Date] DATE PRIMARY KEY, TicketCount INT, RunningTotal INT ); DECLARE @RunningTotal INT = 0; INSERT @st([Date], TicketCount, RunningTotal) SELECT [Date], TicketCount, RunningTotal = 0 FROM dbo.SpeedingTickets ORDER BY [Date]; UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st; SELECT [Date], TicketCount, RunningTotal FROM @st ORDER BY [Date];
Vou reafirmar que não acredito que essa abordagem seja segura para a produção, independentemente do testemunho que você ouvirá de pessoas indicando que ela "nunca falha". A menos que o comportamento seja documentado e garantido, tento ficar longe de suposições baseadas no comportamento observado. Você nunca sabe quando alguma alteração no caminho de decisão do otimizador (com base em uma alteração de estatísticas, alteração de dados, service pack, sinalizador de rastreamento, dica de consulta, o que você tem) alterará drasticamente o plano e potencialmente levará a um pedido diferente. Se você realmente gosta dessa abordagem pouco intuitiva, pode se sentir um pouco melhor usando a opção de consulta FORCE ORDER (e isso tentará usar uma varredura ordenada do PK, pois esse é o único índice elegível na variável da tabela):
UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st OPTION (FORCE ORDER);
Para um pouco mais de confiança a um custo de E/S um pouco mais alto, você pode trazer a mesa original de volta ao jogo e garantir que o PK na mesa base seja usado:
UPDATE st SET @RunningTotal = st.RunningTotal = @RunningTotal + t.TicketCount FROM dbo.SpeedingTickets AS t WITH (INDEX = pk) INNER JOIN @st AS st ON t.[Date] = st.[Date] OPTION (FORCE ORDER);
Pessoalmente, não acho que seja muito mais garantido, pois a parte SET da operação poderia influenciar o otimizador independentemente do restante da consulta. Novamente, não estou recomendando essa abordagem, estou apenas incluindo a comparação para completar. Aqui está o plano desta consulta:
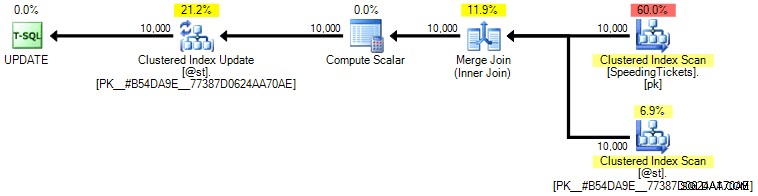
Com base no número de execuções que vemos na guia Top Operations (vou poupar a captura de tela; é 1 para cada operação), fica claro que, mesmo que façamos uma junção para nos sentirmos melhor sobre o pedido, o peculiar A atualização permite que os totais em execução sejam calculados em uma única passagem dos dados. Comparando-o com as consultas anteriores, é muito mais eficiente, embora primeiro despeje os dados em uma variável de tabela e seja separado em várias operações:

Isso nos leva a um "CTE recursivo ". Esse método usa o valor de data e se baseia na suposição de que não há lacunas. Como preenchemos esses dados acima, sabemos que é uma série totalmente contígua, mas em muitos cenários você não pode fazer isso Assim, embora eu a tenha incluído para completar, essa abordagem nem sempre será válida. Em qualquer caso, ela usa uma CTE recursiva com a primeira data (conhecida) na tabela como âncora e a recursiva parte determinada pela adição de um dia (adicionando a opção MAXRECURSION, pois sabemos exatamente quantas linhas temos):
;WITH x AS ( SELECT [Date], TicketCount, RunningTotal = TicketCount FROM dbo.SpeedingTickets WHERE [Date] = '19840101' UNION ALL SELECT y.[Date], y.TicketCount, x.RunningTotal + y.TicketCount FROM x INNER JOIN dbo.SpeedingTickets AS y ON y.[Date] = DATEADD(DAY, 1, x.[Date]) ) SELECT [Date], TicketCount, RunningTotal FROM x ORDER BY [Date] OPTION (MAXRECURSION 10000);
Essa consulta funciona tão eficientemente quanto o método de atualização peculiar. Podemos compará-lo com os métodos de subconsulta e junção interna:

Assim como o método de atualização peculiar, eu não recomendaria essa abordagem CTE em produção, a menos que você possa garantir absolutamente que sua coluna de chave não tenha lacunas. Se houver lacunas em seus dados, você pode construir algo semelhante usando ROW_NUMBER(), mas não será mais eficiente do que o método de auto-junção acima.
E então temos o "cursor " abordagem:
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
DECLARE
@Date DATE,
@TicketCount INT,
@RunningTotal INT = 0;
DECLARE c CURSOR
LOCAL STATIC FORWARD_ONLY READ_ONLY
FOR
SELECT [Date], TicketCount
FROM dbo.SpeedingTickets
ORDER BY [Date];
OPEN c;
FETCH NEXT FROM c INTO @Date, @TicketCount;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @RunningTotal = @RunningTotal + @TicketCount;
INSERT @st([Date], TicketCount, RunningTotal)
SELECT @Date, @TicketCount, @RunningTotal;
FETCH NEXT FROM c INTO @Date, @TicketCount;
END
CLOSE c;
DEALLOCATE c;
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date]; …que é muito mais código, mas ao contrário do que a opinião popular pode sugerir, retorna em 1 segundo. Podemos ver o porquê de alguns dos detalhes do plano acima:a maioria das outras abordagens acaba lendo os mesmos dados repetidamente, enquanto a abordagem do cursor lê cada linha uma vez e mantém o total em uma variável em vez de calcular a soma sobre e de novo. Podemos ver isso observando as declarações capturadas ao gerar um plano real no Plan Explorer:
Podemos ver que mais de 20.000 instruções foram coletadas, mas se classificarmos por Linhas Estimadas ou Reais decrescentes, descobriremos que existem apenas duas operações que lidam com mais de uma linha. O que está muito longe de alguns dos métodos acima que causam leituras exponenciais devido à leitura das mesmas linhas anteriores repetidamente para cada nova linha.
Agora, vamos dar uma olhada nos novos aprimoramentos de janelas no SQL Server 2012. Em particular, agora podemos calcular SUM OVER() e especificar um conjunto de linhas em relação à linha atual. Assim, por exemplo:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] RANGE UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date]; SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] ROWS UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date];
Essas duas consultas dão a mesma resposta, com totais de execução corretos. Mas eles funcionam exatamente da mesma forma? Os planos sugerem que não. A versão com ROWS tem um operador adicional, um projeto de sequência de 10.000 linhas:
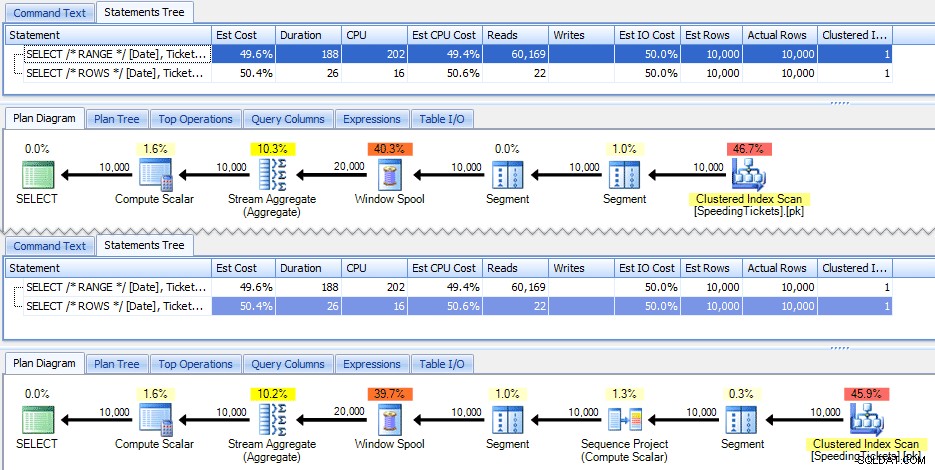
E isso é sobre a extensão da diferença no plano gráfico. Mas se você olhar um pouco mais de perto as métricas reais de tempo de execução, verá pequenas diferenças na duração e na CPU e uma enorme diferença nas leituras. Por que é isso? Bem, isso ocorre porque RANGE usa um spool no disco, enquanto ROWS usa um spool na memória. Com conjuntos pequenos, a diferença provavelmente é insignificante, mas o custo do carretel no disco certamente pode se tornar mais aparente à medida que os conjuntos aumentam. Não quero estragar o final, mas você pode suspeitar que uma dessas soluções terá um desempenho melhor que a outra em um teste mais completo.
Como um aparte, a seguinte versão da consulta produz os mesmos resultados, mas funciona como a versão RANGE mais lenta acima:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date]) FROM dbo.SpeedingTickets ORDER BY [Date];
Então, enquanto você está brincando com as novas funções de janela, você vai querer manter pequenos detalhes como este em mente:a versão abreviada de uma consulta, ou aquela que você escreveu primeiro, não é necessariamente a que você deseja para empurrar para a produção.
Os testes reais
Para realizar testes justos, criei um procedimento armazenado para cada abordagem e medi os resultados capturando declarações em um servidor onde já estava monitorando com o SQL Sentry (se você não estiver usando nossa ferramenta, poderá coletar eventos SQL:BatchCompleted de maneira semelhante usando o SQL Server Profiler).
Por "testes justos" quero dizer que, por exemplo, o método de atualização peculiar requer uma atualização real de dados estáticos, o que significa alterar o esquema subjacente ou usar uma tabela temporária / variável de tabela. Então eu estruturei os procedimentos armazenados para cada um criar sua própria variável de tabela e armazenar os resultados lá ou armazenar os dados brutos e atualizar o resultado. O outro problema que eu queria eliminar era retornar os dados para o cliente – então cada procedimento tem um parâmetro de depuração especificando se não deve retornar nenhum resultado (o padrão), top/bottom 5 ou todos. Nos testes de desempenho, configurei para não retornar nenhum resultado, mas é claro que validei cada um para garantir que eles estivessem retornando os resultados corretos.
Os procedimentos armazenados são todos modelados dessa maneira (anexei um script que cria o banco de dados e os procedimentos armazenados, então estou incluindo um modelo aqui para abreviar):
CREATE PROCEDURE [dbo].[RunningTotals_]
@debug TINYINT = 0
-- @debug = 1 : show top/bottom 3
-- @debug = 2 : show all 50k
AS
BEGIN
SET NOCOUNT ON;
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
INSERT @st([Date], TicketCount, RunningTotal)
-- one of seven approaches used to populate @t
IF @debug = 1 -- show top 3 and last 3 to verify results
BEGIN
;WITH d AS
(
SELECT [Date], TicketCount, RunningTotal,
rn = ROW_NUMBER() OVER (ORDER BY [Date])
FROM @st
)
SELECT [Date], TicketCount, RunningTotal
FROM d
WHERE rn < 4 OR rn > 9997
ORDER BY [Date];
END
IF @debug = 2 -- show all
BEGIN
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date];
END
END
GO E eu os chamei em um lote da seguinte forma:
EXEC dbo.RunningTotals_DateCTE @debug = 0; GO EXEC dbo.RunningTotals_Cursor @debug = 0; GO EXEC dbo.RunningTotals_Subquery @debug = 0; GO EXEC dbo.RunningTotals_InnerJoin @debug = 0; GO EXEC dbo.RunningTotals_QuirkyUpdate @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Range @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; GO
Percebi rapidamente que algumas dessas chamadas não estavam aparecendo no Top SQL porque o limite padrão é de 5 segundos. Mudei para 100 milissegundos (algo que você nunca vai querer fazer em um sistema de produção!) da seguinte forma:
Vou repetir:esse comportamento não é tolerado para sistemas de produção!
Ainda descobri que um dos comandos acima não estava sendo capturado pelo limite do Top SQL; era a versão Window_Rows. Então, adicionei o seguinte apenas a esse lote:
EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; WAITFOR DELAY '00:00:01'; GO
E agora eu estava recebendo todas as 7 linhas retornadas no Top SQL. Aqui eles são ordenados por uso de CPU decrescente:
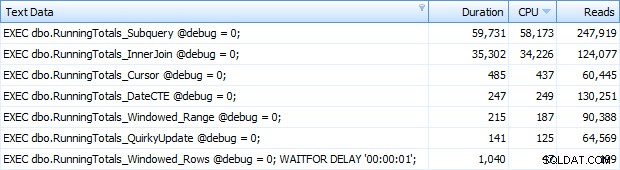
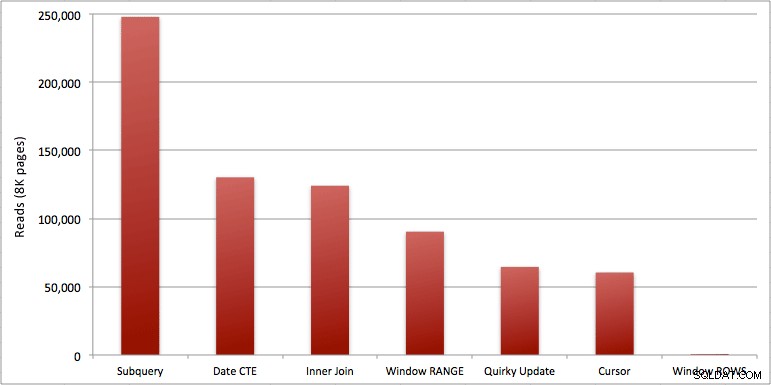
Você pode ver o segundo extra que adicionei ao lote Windowed_Rows; ele não estava sendo pego pelo limite do Top SQL porque foi concluído em apenas 40 milissegundos! Este é claramente o nosso melhor desempenho e, se tivermos o SQL Server 2012 disponível, deve ser o método que usamos. O cursor também não é tão ruim, dado o desempenho ou outros problemas com as soluções restantes. Traçar a duração em um gráfico não tem sentido – dois pontos altos e cinco pontos baixos indistinguíveis. Mas se a E/S for seu gargalo, você pode achar interessante a visualização das leituras:
Conclusão
Destes resultados podemos tirar algumas conclusões:
- Agregados de janela no SQL Server 2012 tornam os problemas de desempenho com cálculos de totais em execução (e muitos outros problemas de linha(s) seguinte(s)/linha(s) anterior(es)) de forma alarmante mais eficiente. Quando vi o baixo número de leituras pensei com certeza que havia algum tipo de erro, que devo ter esquecido de realmente realizar algum trabalho. Mas não, você obtém o mesmo número de leituras se seu procedimento armazenado apenas executar um SELECT comum da tabela SpeedingTickets. (Sinta-se à vontade para testar isso você mesmo com STATISTICS IO.)
- Os problemas que apontei anteriormente sobre RANGE vs. ROWS produzem tempos de execução ligeiramente diferentes (diferença de duração de cerca de 6x – lembre-se de ignorar o segundo que adicionei com WAITFOR), mas as diferenças de leitura são astronômicas devido ao carretel no disco. Se o seu agregado em janela puder ser resolvido usando ROWS, evite RANGE, mas você deve testar se ambos dão o mesmo resultado (ou pelo menos que ROWS dá a resposta certa). Você também deve observar que, se estiver usando uma consulta semelhante e não especificar RANGE nem ROWS, o plano funcionará como se você tivesse especificado RANGE).
- Os métodos de subconsulta e junção interna são relativamente ruins. 35 segundos a um minuto para gerar esses totais em execução? E isso em uma única mesa magrinha sem retornar resultados para o cliente. Essas comparações podem ser usadas para mostrar às pessoas por que uma solução puramente baseada em conjuntos nem sempre é a melhor resposta.
- Das abordagens mais rápidas, supondo que você ainda não esteja pronto para o SQL Server 2012 e supondo que você descarte o método de atualização peculiar (sem suporte) e o método de data CTE (não pode garantir uma sequência contígua), apenas o cursor executa aceitavelmente. Tem a maior duração das soluções "mais rápidas", mas a menor quantidade de leituras.
Espero que esses testes ajudem a avaliar melhor os aprimoramentos de janelas que a Microsoft adicionou ao SQL Server 2012. Certifique-se de agradecer a Itzik se você o vir online ou pessoalmente, pois ele foi a força motriz por trás dessas mudanças. Além disso, espero que isso ajude a abrir algumas mentes de que um cursor nem sempre pode ser a solução maligna e temida que muitas vezes é descrita.
(Como adendo, testei a função CLR oferecida por Pavel Pawlowski e as características de desempenho eram quase idênticas à solução SQL Server 2012 usando ROWS. As leituras eram idênticas, a CPU era 78 vs. 47 e a duração geral era 73 em vez de 40. Portanto, se você não estiver migrando para o SQL Server 2012 em um futuro próximo, convém adicionar a solução do Pavel aos seus testes.)
Anexos:RunningTotals_Demo.sql.zip (2kb)