Em um artigo anterior, exploramos os requisitos de índice do SQL Server e as considerações de desempenho. Quando se trata de desempenho de banco de dados, o ajuste de desempenho é, sem dúvida, uma das funções mais importantes e complexas. Ele consiste em muitas áreas diferentes, como otimização de consulta SQL, ajuste de índice e ajuste de recursos do sistema, todos os quais precisam ser executados corretamente para recuperar dados rapidamente.
Há várias áreas importantes a serem consideradas quando se trata de índices do SQL Server, pois eles podem ter um impacto significativo em seus esforços de ajuste de desempenho e no desempenho geral do banco de dados. Abaixo estão alguns detalhes sobre cada um e os papéis críticos que eles desempenham.
Práticas recomendadas de índice do SQL Server
1. Entenda como o design do banco de dados afeta os índices do SQL Server
Os requisitos de indexação variam entre bancos de dados de processamento de transações online (OLTP) e processamento analítico online (OLAP).
Em um banco de dados OLTP, os usuários realizam operações de leitura e gravação frequentes, inserindo novos dados e modificando dados existentes. Eles usam consultas de linguagem de manipulação de dados (Inserir, Atualizar, Excluir) juntamente com instruções Select para recuperação e modificações de dados. Para bancos de dados OLTP, é melhor criar índices na coluna Selected de uma tabela. Vários índices podem ter um impacto negativo no desempenho e sobrecarregar os recursos do sistema. Em vez disso, é recomendável criar o número mínimo de índices que pode atender aos seus requisitos de indexação. Em bancos de dados OLAP, por outro lado, você usa principalmente instruções Select para recuperar dados para fins analíticos adicionais. Nesse caso, você pode adicionar mais índices com várias colunas de chave por índice. Você também pode aproveitar os índices columnstore para recuperação de dados mais rápida em consultas de data warehouse
2. Crie índices para seus requisitos de carga de trabalho
Ao criar uma nova tabela em seu banco de dados, não basta adicionar índices cegamente. Às vezes, os desenvolvedores colocam um índice clusterizado e alguns índices não clusterizados nele sem procurar as consultas que usam esses índices. Pode haver um índice que não satisfaça o requisito do otimizador de consulta; portanto, você deve analisar adequadamente sua carga de trabalho e consultas SQL (procedimentos armazenados, funções, visualizações e consultas ad-hoc). Você pode capturar a carga de trabalho usando o SQL Profiler, eventos estendidos e exibições de gerenciamento dinâmico e, em seguida, criar índices para otimizar consultas com uso intensivo de recursos.
3. Crie índices para as consultas usadas com mais frequência
É importante agrupar cargas de trabalho para as consultas mais usadas em seu sistema. Ao criar os melhores índices para essas consultas, isso causará o mínimo de esforço em seu sistema.
4. Aplicar as práticas recomendadas de coluna de chave de índice do SQL Server
Como você pode ter várias colunas em uma tabela, aqui estão algumas considerações para colunas de chave de índice.
- Colunas com text, image, ntext, varchar(max), nvarchar(max) e varbinary(max) não podem ser usadas nas colunas de chave de índice.
- Recomenda-se usar um tipo de dados inteiro na coluna de chave de índice. Tem um requisito de espaço reduzido e funciona de forma eficiente. Por isso, convém criar a coluna de chave primária, geralmente em um tipo de dados inteiro.
- Você só pode usar o tipo de dados XML em um índice XML.
- Você deve considerar a criação de uma chave primária para a coluna com valores exclusivos. Se uma tabela não tiver colunas de valor exclusivo, você poderá definir uma coluna de identidade para um tipo de dados inteiro. Uma chave primária também cria um índice clusterizado para a distribuição de linhas.
- Você pode considerar uma coluna com os valores Unique e Not NULL como um candidato de chave de índice útil.
- Você deve criar um índice com base nos predicados da cláusula Where. Por exemplo, você pode considerar as colunas usadas na cláusula Where, junções SQL, como ordenar por, agrupar por predicados e assim por diante.
- Você deve unir tabelas de uma forma que reduza o número de linhas para o restante da consulta. Isso ajudará o otimizador de consultas a preparar o plano de execução com recursos mínimos do sistema.
- Se você usar várias colunas para uma chave de índice, também é essencial considerar sua posição na chave de índice.
- Você também deve considerar o uso de colunas incluídas em seus índices.
5. Analise a distribuição de dados de suas colunas de índice do SQL Server
Você deve examinar a distribuição de dados nas colunas de chave de índice do SQL Server. Uma coluna com valores não exclusivos pode causar um atraso na recuperação dos dados e resultar em uma transação de longa duração. Você pode analisar a distribuição de dados usando o histograma nas estatísticas.
6. Usar ordem de classificação de dados
Você também deve considerar os requisitos de classificação de dados em suas consultas e índices. Por padrão, o SQL Server classifica os dados em ordem crescente em um índice. Suponha que você crie um índice em ordem crescente, mas suas consultas usam a cláusula Order By para classificar os dados em ordem decrescente.
Por exemplo, observe o plano de execução real da consulta a seguir.
SELECT [SalesOrderID],
[UnitPrice]
FROM [AdventureWorks].[Sales].[SalesOrderDetail]
ORDER BY UnitPrice DESC,
SalesOrderID ASC; 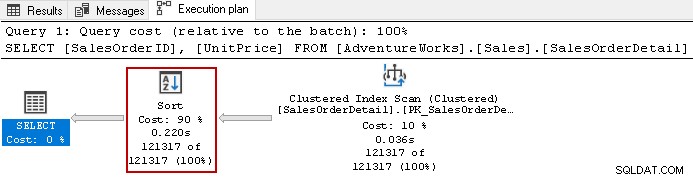
Ele usa o caro operador de classificação com um custo geral de 90% nesta consulta. Decidimos construir um índice não clusterizado em [UnitPrice] e [SalesOrderID]. Ele usa uma ordem de classificação padrão para ambas as colunas no índice.
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice
ON [AdventureWorks].[Sales].[SalesOrderDetail]
(UnitPrice ASC, SalesOrderID ASC); Executamos novamente a instrução Select e o otimizador de consulta ainda usa o operador de classificação. Ele pode usar o índice não clusterizado, mas classifica os dados para preparar o resultado.
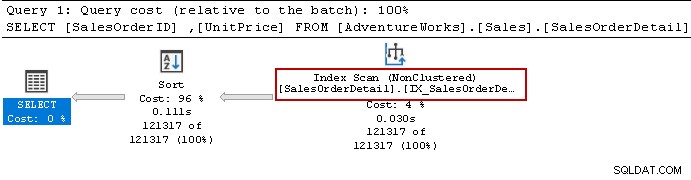
Vamos recriar o índice usando a seguinte consulta. Desta vez, ele classifica os dados em ordem decrescente para [Unitprice] na definição do índice.
DROP INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail];
Go CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail](UnitPrice DESC, SalesOrderID ASC);
Go Ele não requer nenhum operador de classificação agora porque o índice atende aos requisitos de consulta.
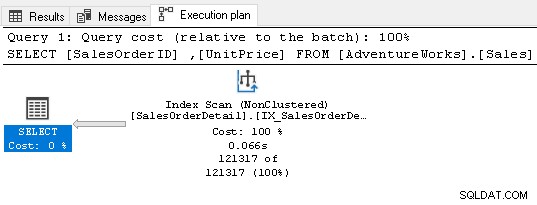
7. Use chaves estrangeiras para seu índice do SQL Server
Você deve criar um índice nas colunas de chaves estrangeiras. É aconselhável criar um índice clusterizado na chave estrangeira para melhorar o desempenho da consulta.
8. Esteja atento às considerações de armazenamento de índice do SQL Server
O armazenamento de índice também é um aspecto útil a ser considerado. O SQL Server cria todos os índices no mesmo grupo de arquivos da tabela. Você pode considerar um grupo de arquivos separado para índices e separar o arquivo físico em um disco separado. Isso aumentará o desempenho e a taxa de transferência de E/S.
Da mesma forma, você pode usar o particionamento de tabela para segregar dados em vários discos e grupos de arquivos. Você pode projetar índices particionados para essas partições de tabela para melhorar o acesso simultâneo a dados.
Outra opção é definir o FILLFACTOR ao criar ou reconstruir um índice. Um FILLFACTOR define o espaço livre nas páginas de dados do nó folha. É útil para outras inserções de dados. Se seus dados são estáticos e não mudam com frequência, você pode considerar um valor alto de FILLFACTOR. Por outro lado, para dados que mudam com frequência, você pode deixar espaço suficiente para novas inserções de dados.
9. Encontrar índices ausentes
Às vezes, você obtém informações sobre um índice do SQL Server ausente no plano de execução da consulta. Você também pode executar as exibições de gerenciamento dinâmico para localizar esses índices ausentes. Você não deve criar esses índices cegamente. É apenas uma sugestão de otimizador de consulta, mas não considera o índice existente ou seus requisitos de carga de trabalho. Ele também pode incluir várias colunas na definição do índice, portanto, revise essas sugestões antes de implementá-lo.
10. Sempre crie um índice clusterizado antes de um índice não clusterizado
Como diretriz geral, você deve criar um índice clusterizado antes de criar índices não clusterizados. Se uma tabela não tiver um índice, um índice não clusterizado consiste em identificadores de linha. Depois de criar um índice clusterizado, o SQL Server precisa reconstruir esses índices não clusterizados para que possam apontar para a chave de índice clusterizado em vez dos identificadores de linha.
11. Monitore a manutenção do índice e atualize as estatísticas
Abaixo estão várias áreas de manutenção para monitorar quando se trata de índices do SQL Server.
- Remover fragmentação de índice :você deve revisar regularmente as fragmentações internas e externas, especialmente para as tabelas de alta transação. Suas consultas podem responder lentamente mesmo se você tiver índices adequados para suas cargas de trabalho. Um índice altamente fragmentado pode degradar o desempenho porque requer E/S adicional. Você pode realizar uma reorganização ou reconstruir um índice com base em seus valores de fragmentação. Normalmente, você deve reconstruir o índice se ele tiver uma fragmentação maior que 30% e reorganizá-lo se tiver menos de 30% de fragmentação.
- Remover índices não utilizados: Você deve sempre revisar os índices não utilizados (ociosos) em seu banco de dados porque o otimizador de consulta precisa considerá-los para cada consulta. Um índice não utilizado também consome armazenamento e aumenta a sobrecarga de manutenção.
- Atualizar estatísticas: Você deve atualizar periodicamente as estatísticas mesmo se tiver definido as estatísticas de atualização automática na configuração do banco de dados. O otimizador de consulta pode preparar um plano de execução incorreto se as estatísticas de índice não forem atualizadas. Você pode agendar um trabalho de agente para atualizar as estatísticas do SQL Server com uma verificação completa após o horário comercial.
Você pode consultar a manutenção do índice SQL para obter mais informações sobre este tópico.
Aplicando as práticas recomendadas de índice do SQL Server
Embora nem sempre haja uma maneira direta de projetar um índice ideal do SQL Server, a aplicação das recomendações especificadas nesta postagem ajudará você a navegar pelos diversos requisitos de indexação que você encontrará com cada tipo de banco de dados e suas cargas de trabalho. Essas práticas recomendadas ajudarão a otimizar seus índices para melhorar o desempenho do banco de dados e garantir um processo de ajuste de desempenho mais tranquilo ao longo do caminho.