Trabalhando no setor de TI, provavelmente já ouvimos a palavra "failover" muitas vezes, mas também pode levantar questões como:O que é realmente um failover? Para que podemos usá-lo? É importante tê-lo? Como podemos fazer isso?
Embora possam parecer perguntas bastante básicas, é importante levá-las em consideração em qualquer ambiente de banco de dados. E, na maioria das vezes, não levamos em conta o básico...
Para começar, vejamos alguns conceitos básicos.
O que é Failover?
Failover é a capacidade de um sistema continuar funcionando mesmo que ocorra alguma falha. Sugere que as funções do sistema são assumidas por componentes secundários se os componentes primários falharem.
No caso do PostgreSQL, existem diferentes ferramentas que permitem implementar um cluster de banco de dados resiliente a falhas. Um mecanismo de redundância disponível nativamente no PostgreSQL é a replicação. E a novidade no PostgreSQL 10 é a implementação da replicação lógica.
O que é replicação?
É o processo de copiar e manter os dados atualizados em um ou mais nós do banco de dados. Ele usa um conceito de nó mestre que recebe as modificações e nós escravos onde elas são replicadas.
Temos várias maneiras de categorizar a replicação:
- Replicação síncrona:não há perda de dados mesmo que nosso nó mestre seja perdido, mas os commits no mestre devem aguardar uma confirmação do escravo, o que pode afetar o desempenho.
- Replicação Assíncrona:Existe a possibilidade de perda de dados caso percamos nosso nó mestre. Se a réplica por algum motivo não for atualizada no momento do incidente, as informações que não foram copiadas poderão ser perdidas.
- Replicação física:os blocos de disco são copiados.
- Replicação lógica:streaming das alterações de dados.
- Warm Standby Slaves:eles não suportam conexões.
- Hot Standby Slaves:suporta conexões somente leitura, úteis para relatórios ou consultas.
Para que é usado o Failover?
Há vários usos possíveis de failover. Vamos ver alguns exemplos.
Migração
Se quisermos migrar de um datacenter para outro minimizando nosso tempo de inatividade, podemos usar o failover.
Suponha que nosso mestre esteja no datacenter A e queiramos migrar nossos sistemas para o datacenter B.
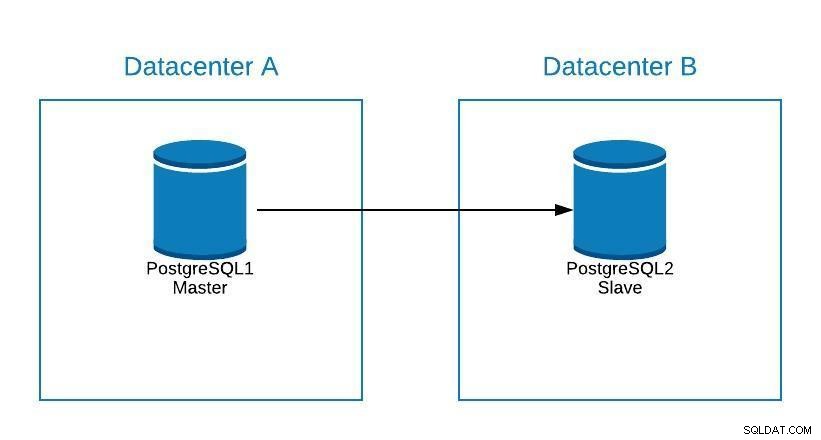 Diagrama de migração 1
Diagrama de migração 1 Podemos criar uma réplica no datacenter B. Uma vez sincronizado, devemos parar nosso sistema, promover nossa réplica para novo master e failover, antes de apontarmos nosso sistema para o novo master no datacenter B.
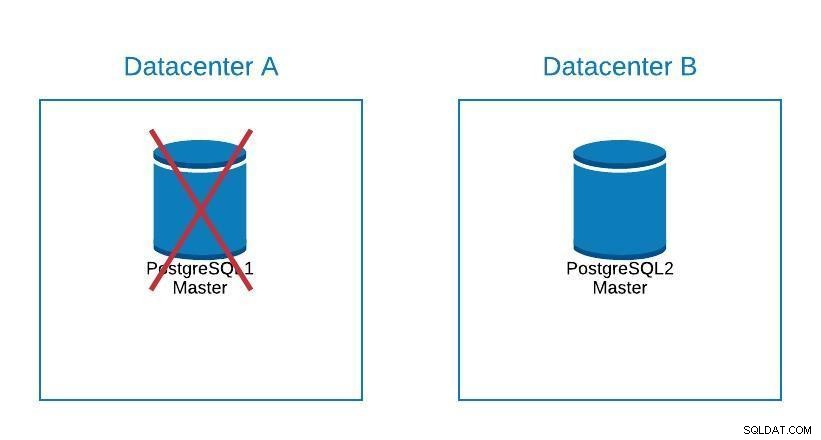 Diagrama de migração 2
Diagrama de migração 2 Failover não é apenas sobre o banco de dados, mas também sobre o(s) aplicativo(s). Como eles sabem a qual banco de dados se conectar? Certamente não queremos ter que modificar nosso aplicativo, pois isso apenas prolongará nosso tempo de inatividade. Assim, podemos configurar um balanceador de carga para que, quando derrubarmos nosso mestre, ele aponte automaticamente para o próximo servidor que for promovido.
Outra opção é o uso de DNS. Ao promover a réplica mestre no novo datacenter, modificamos diretamente o endereço IP do nome do host que aponta para o mestre. Dessa forma, evitamos ter que modificar nosso aplicativo e, embora não possa ser feito automaticamente, é uma alternativa se não quisermos implementar um balanceador de carga.
Ter uma única instância do balanceador de carga não é ótimo, pois pode se tornar um único ponto de falha. Portanto, você também pode implementar o failover para o balanceador de carga, usando um serviço como keepalived. Dessa forma, caso tenhamos algum problema com nosso load balancer primário, o keepalived é responsável por migrar o IP para nosso load balancer secundário, e tudo continua funcionando de forma transparente.
Manutenção
Se precisarmos realizar alguma manutenção em nosso servidor de banco de dados mestre postgreSQL, podemos promover nosso escravo, executar a tarefa e reconstruir um escravo em nosso antigo mestre.
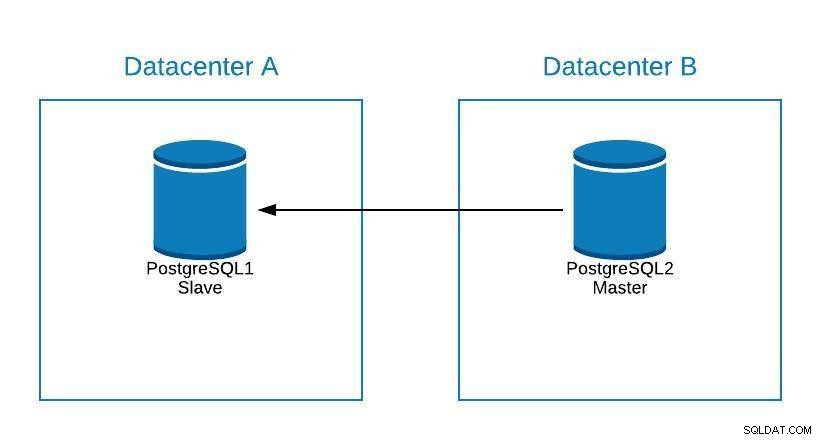 Diagrama de manutenção 1
Diagrama de manutenção 1 Depois disso, podemos re-promover o antigo mestre e repetir o processo de reconstrução do escravo, retornando ao estado inicial.
Diagrama de manutenção 2 Dessa forma, poderíamos trabalhar em nosso servidor, sem correr o risco de ficar offline ou perder informações durante a manutenção.
Atualizar
Embora o PostgreSQL 11 ainda não esteja disponível, tecnicamente seria possível atualizar do PostgreSQL versão 10, usando replicação lógica, como pode ser feito com outros mecanismos.
Os passos seriam os mesmos para migrar para um novo datacenter (ver seção Migração), só que nosso slave estaria no PostgreSQL 11.
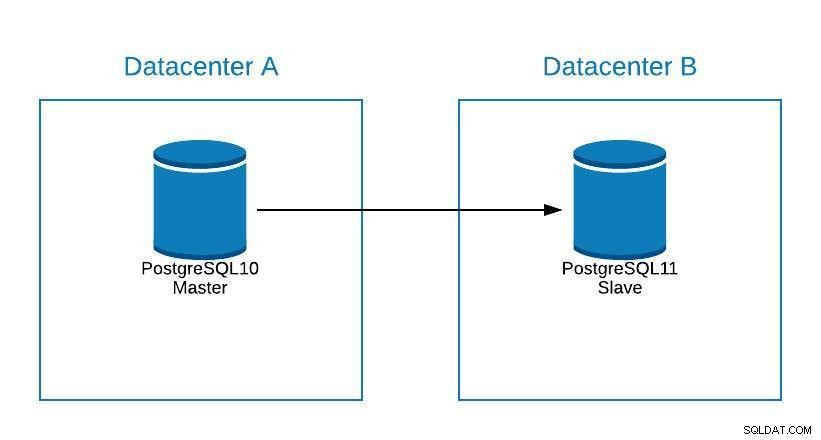 Atualizar Diagrama 1
Atualizar Diagrama 1 Problemas
A função mais importante do failover é minimizar nosso tempo de inatividade ou evitar a perda de informações, ao ter um problema com nosso banco de dados principal.
Se por algum motivo perdermos nosso banco de dados mestre, podemos realizar um failover promovendo nosso escravo a mestre e manter nossos sistemas funcionando.
Para isso, o PostgreSQL não nos fornece nenhuma solução automatizada. Podemos fazê-lo manualmente ou automatizá-lo por meio de um script ou de uma ferramenta externa.
Para promover nosso escravo a mestre:
-
Execute pg_ctl promover
bash-4.2$ pg_ctl promote -D /var/lib/pgsql/10/data/ waiting for server to promote.... done server promoted - Crie um arquivo trigger_file que devemos ter adicionado no recovery.conf do nosso diretório de dados.
bash-4.2$ cat /var/lib/pgsql/10/data/recovery.conf standby_mode = 'on' primary_conninfo = 'application_name=pgsql_node_0 host=postgres1 port=5432 user=replication password=****' recovery_target_timeline = 'latest' trigger_file = '/tmp/failover.trigger' bash-4.2$ touch /tmp/failover.trigger
Para implementar uma estratégia de failover, precisamos planejá-la e testá-la minuciosamente em diferentes cenários de falha. Como as falhas podem acontecer de diferentes maneiras, a solução deve funcionar idealmente para a maioria dos cenários comuns. Se estamos procurando uma maneira de automatizar isso, podemos dar uma olhada no que o ClusterControl tem a oferecer.
ClusterControl para Failover do PostgreSQL
O ClusterControl possui vários recursos relacionados à replicação do PostgreSQL e failover automatizado.
Adicionar escravo
Se quisermos adicionar um escravo em outro datacenter, seja como contingência ou para migrar seus sistemas, podemos ir em Cluster Actions e selecionar Add Replication Slave.
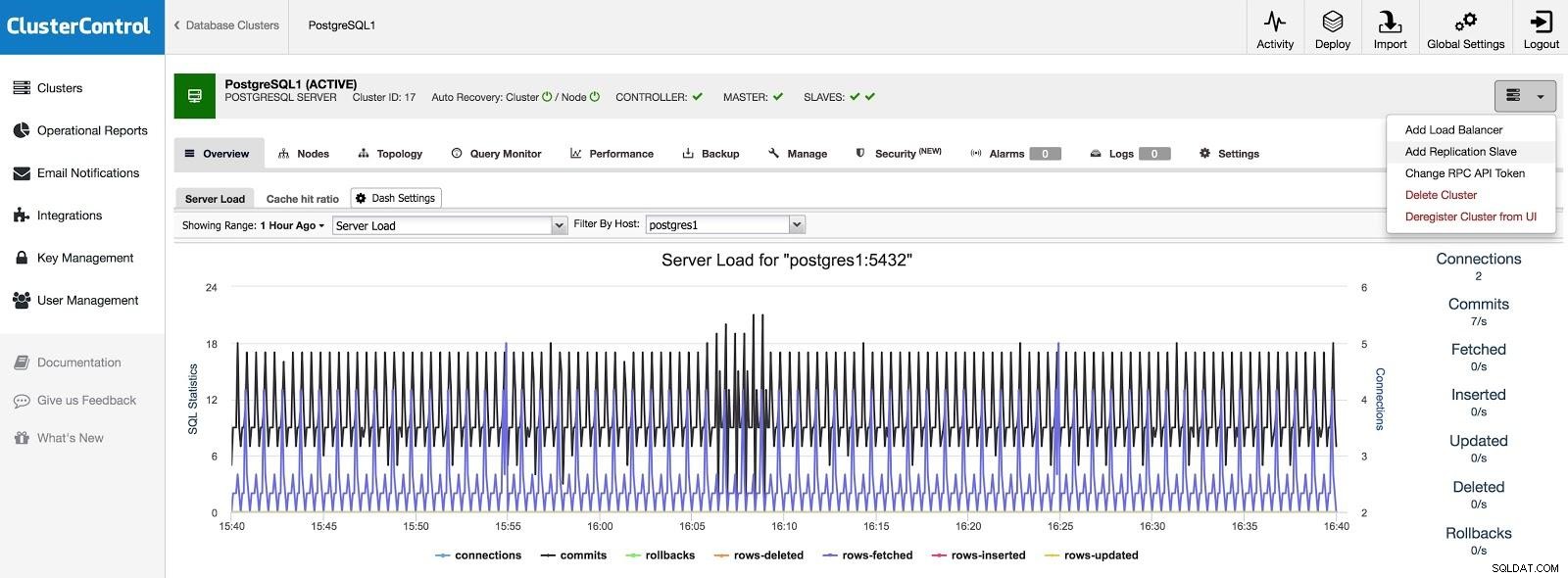 ClusterControl Adicionar escravo 1
ClusterControl Adicionar escravo 1 Precisaremos inserir alguns dados básicos, como IP ou nome do host, diretório de dados (opcional), escravo síncrono ou assíncrono. Devemos ter nosso escravo funcionando depois de alguns segundos.
No caso de usar outro datacenter, recomendamos a criação de um escravo assíncrono, caso contrário a latência pode afetar consideravelmente o desempenho.
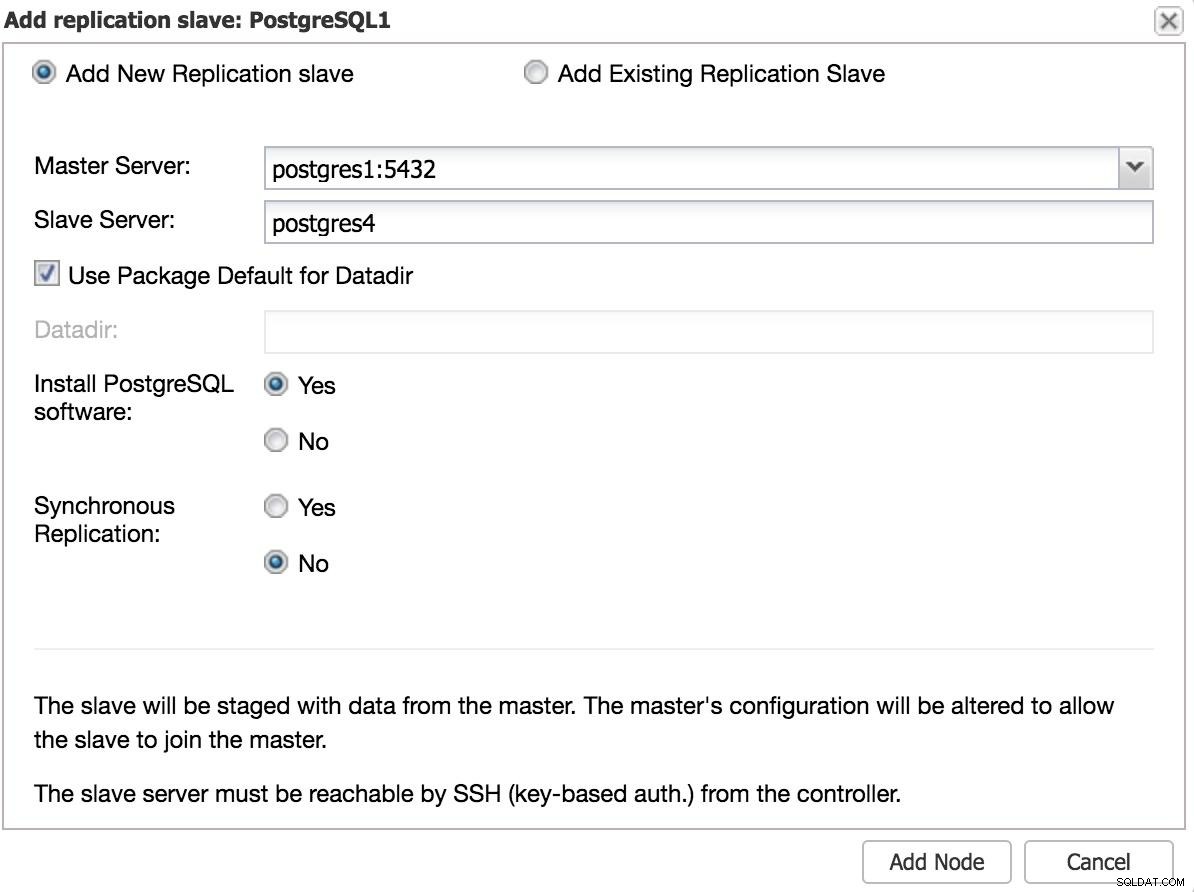 ClusterControl Adicionar Slave 2
ClusterControl Adicionar Slave 2 Failover manual
Com o ClusterControl, o failover pode ser feito manualmente ou automaticamente.
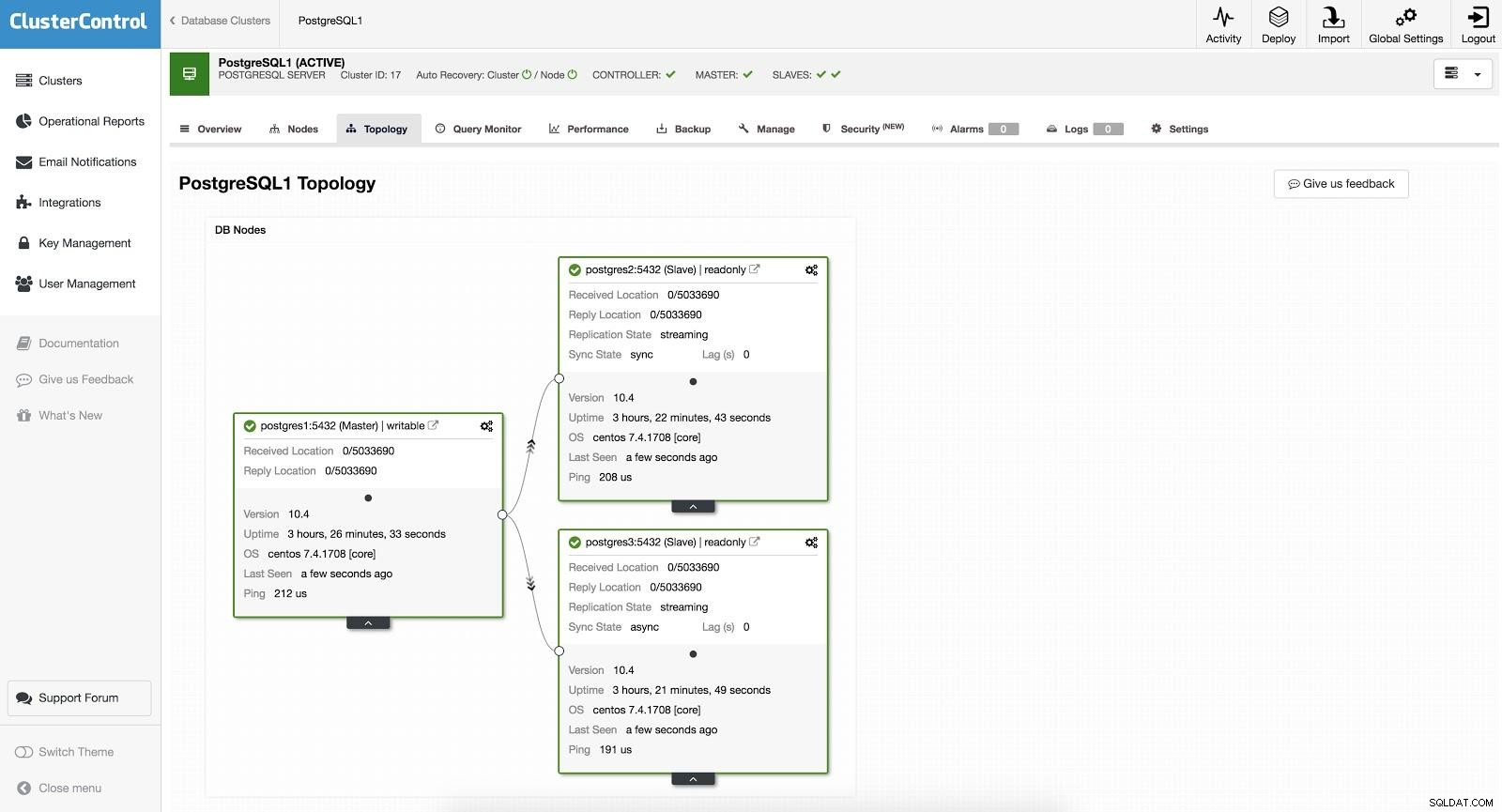 ClusterControl Failover 1
ClusterControl Failover 1 Para realizar um failover manual, vá para ClusterControl -> Select Cluster -> Nodes, e no Action Node de um de nossos slaves, selecione "Promote Slave". Desta forma, após alguns segundos, nosso escravo torna-se mestre, e o que era nosso mestre anteriormente, torna-se escravo.
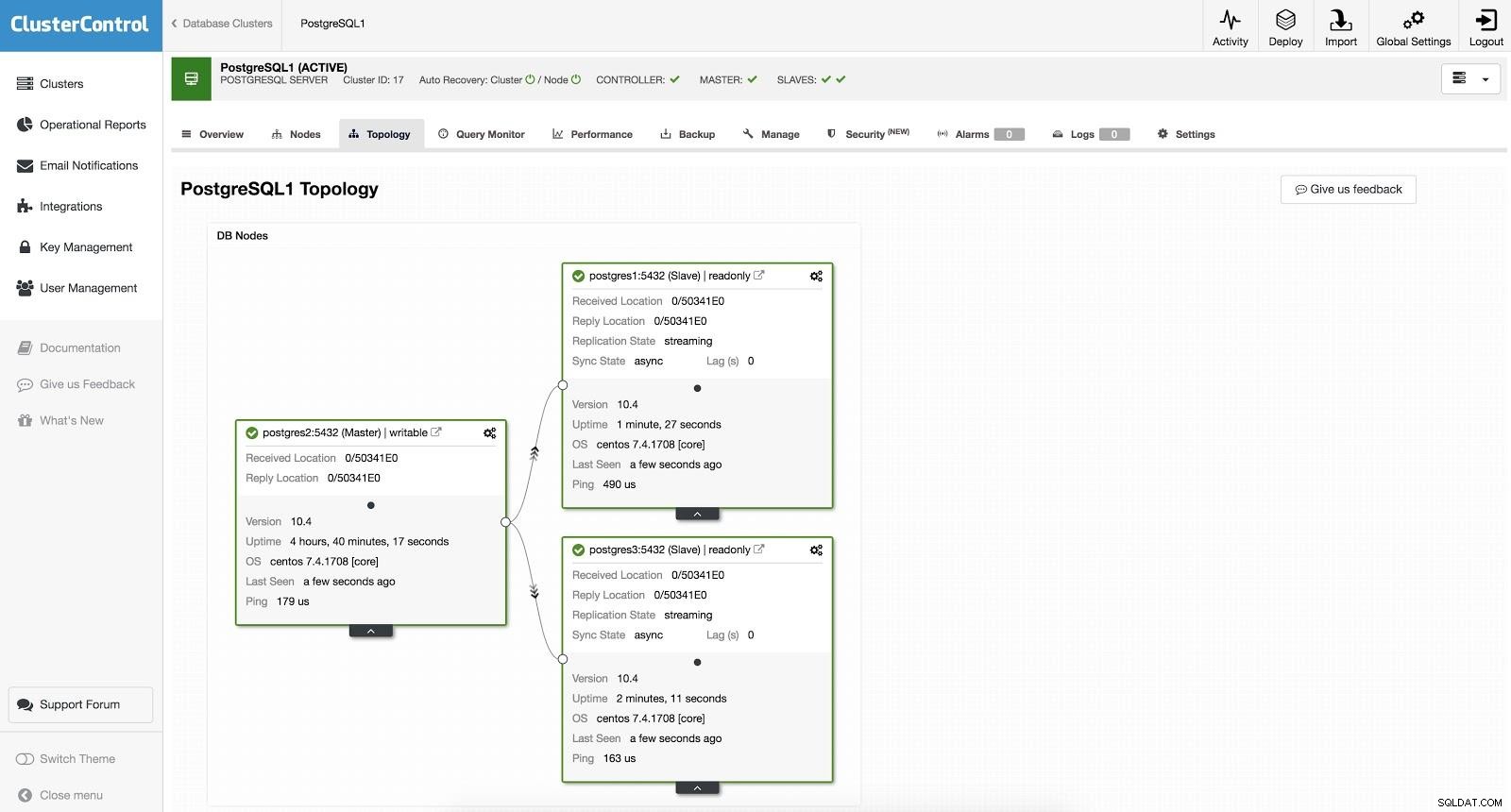 ClusterControl Failover 2
ClusterControl Failover 2 O acima é útil para as tarefas de migração, manutenção e atualizações que vimos anteriormente.
Failover automático
No caso de failover automático, o ClusterControl detecta falhas no mestre e promove um escravo com os dados mais atuais como o novo mestre. Ele também funciona no restante dos escravos para que eles sejam replicados do novo mestre.
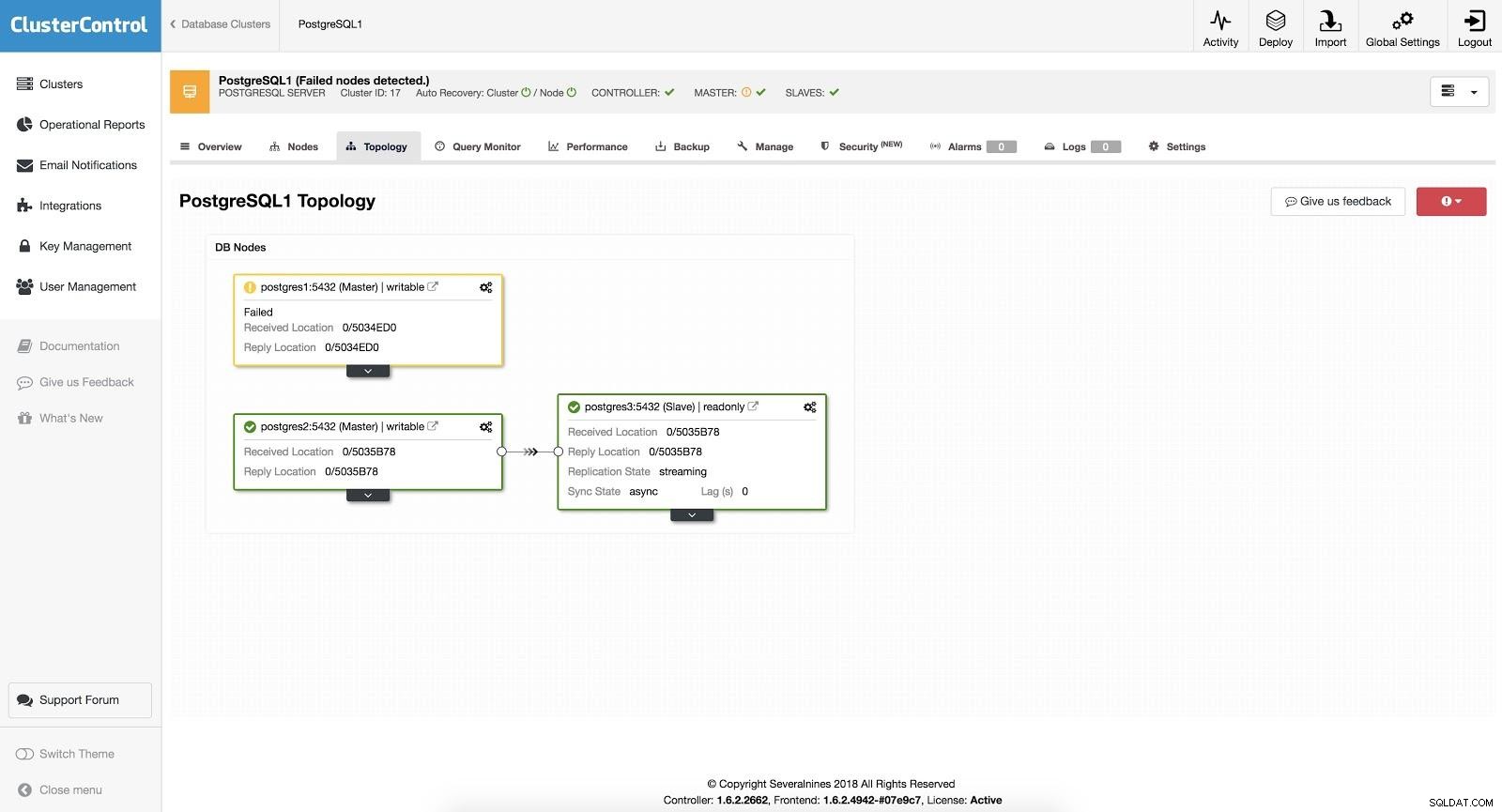 ClusterControl Failover 3
ClusterControl Failover 3 Com a opção “Autorecovery” ativada, nosso ClusterControl realizará um failover automático e nos notificará sobre o problema. Desta forma, nossos sistemas podem se recuperar em segundos e sem nossa intervenção.
O Cluster Control nos oferece a possibilidade de configurar uma lista branca/lista negra para definir como queremos que nossos servidores sejam levados (ou não) em consideração ao decidir sobre um candidato mestre.
Dentre os disponíveis de acordo com a configuração acima, o ClusterControl escolherá o slave mais avançado, utilizando para isso o pg_current_xlog_location (PostgreSQL 9+) ou pg_current_wal_lsn (PostgreSQL 10+) dependendo da versão do nosso banco de dados.
O ClusterControl também realiza várias verificações sobre o processo de failover, a fim de evitar alguns erros comuns. Um exemplo é que se conseguirmos recuperar nosso antigo mestre com falha, ele NÃO será reintroduzido automaticamente no cluster, nem como mestre nem como escravo. Precisamos fazer isso manualmente. Isso evitará a possibilidade de perda ou inconsistência de dados no caso de nosso escravo (que promovemos) estar atrasado no momento da falha. Também podemos querer analisar o problema em detalhes, mas ao adicioná-lo ao nosso cluster, possivelmente perderíamos as informações de diagnóstico.
Além disso, se o failover falhar, nenhuma tentativa adicional for feita, será necessária a intervenção manual para analisar o problema e executar as ações correspondentes. Isso é para evitar a situação em que o ClusterControl, como gerenciador de alta disponibilidade, tenta promover o próximo escravo e o próximo. Pode haver um problema e não queremos piorar as coisas tentando vários failovers.
Balanceadores de carga
Como mencionamos anteriormente, o balanceador de carga é uma ferramenta importante a ser considerada para nosso failover, especialmente se quisermos usar o failover automático em nossa topologia de banco de dados.
Para que o failover seja transparente tanto para o usuário quanto para a aplicação, precisamos de um componente intermediário, pois não basta promover um mestre a escravo. Para isso, podemos usar HAProxy + Keepalived.
O que é HAProxy?
O HAProxy é um balanceador de carga que distribui o tráfego de uma origem para um ou mais destinos e pode definir regras e/ou protocolos específicos para esta tarefa. Se algum dos destinos parar de responder, ele será marcado como off-line e o tráfego será enviado para o restante dos destinos disponíveis. Isso evita que o tráfego seja enviado para um destino inacessível e evita a perda desse tráfego direcionando-o para um destino válido.
O que é Keepalived?
Keepalived permite configurar um IP virtual dentro de um grupo ativo/passivo de servidores. Este IP virtual é atribuído a um servidor “Primário” ativo. Caso este servidor falhe, o IP é automaticamente migrado para o servidor “Secundário” que foi considerado passivo, permitindo que ele continue trabalhando com o mesmo IP de forma transparente para nossos sistemas.
Para implementar esta solução com ClusterControl, começamos como se fosse adicionar um escravo. Vá para Cluster Actions e selecione Add Load Balancer (consulte ClusterControl Add Slave 1 image).
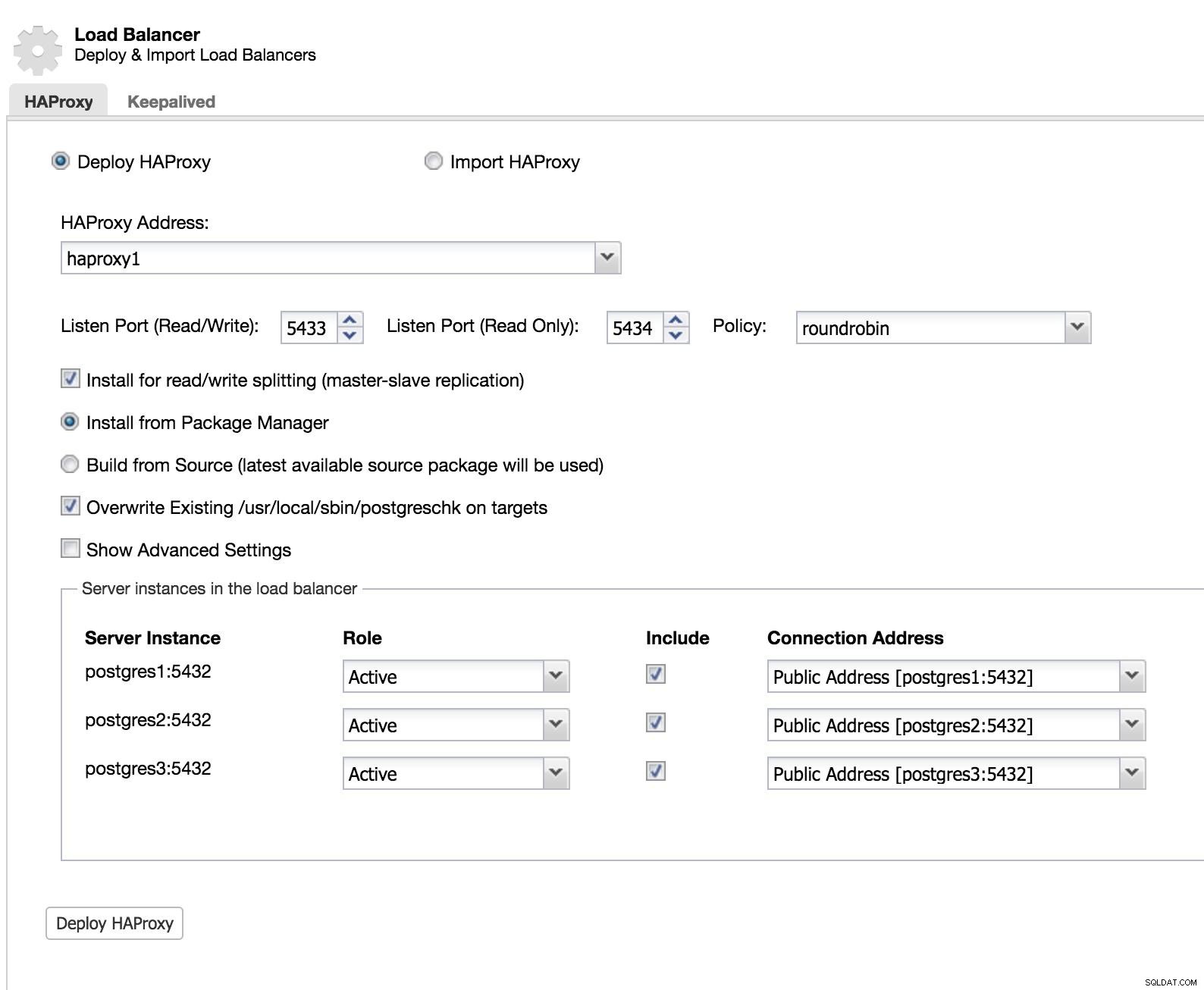 ClusterControl Load Balancer 1
ClusterControl Load Balancer 1 Adicionamos as informações do nosso novo load balancer e como queremos que ele se comporte (Policy).
No caso de querer implementar o failover para nosso load balancer, devemos configurar pelo menos duas instâncias.
Em seguida, podemos configurar o Keepalived (Selecione Cluster -> Gerenciar -> Load Balancer -> Keepalived).
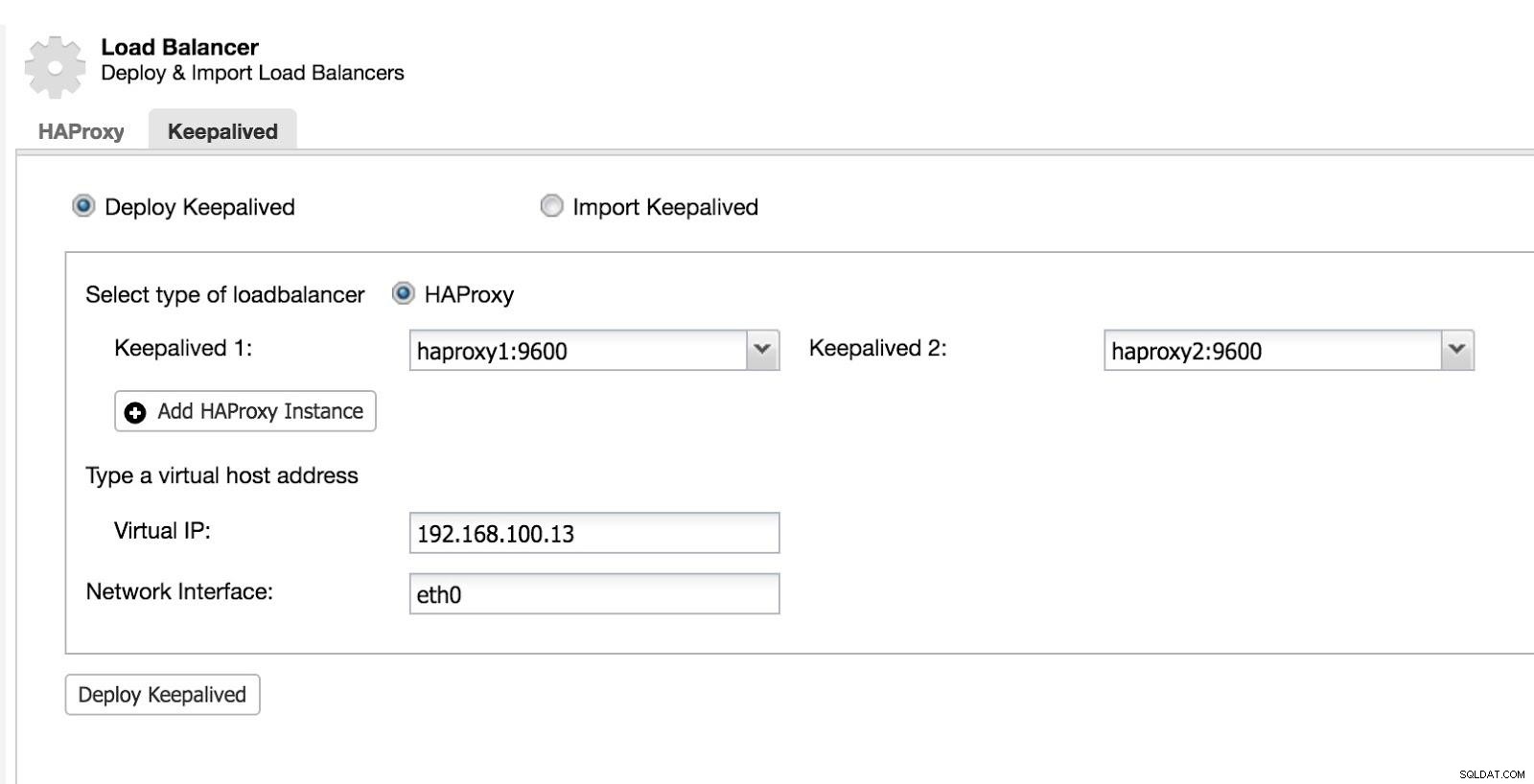 ClusterControl Load Balancer 2
ClusterControl Load Balancer 2 Após isso, temos a seguinte topologia:
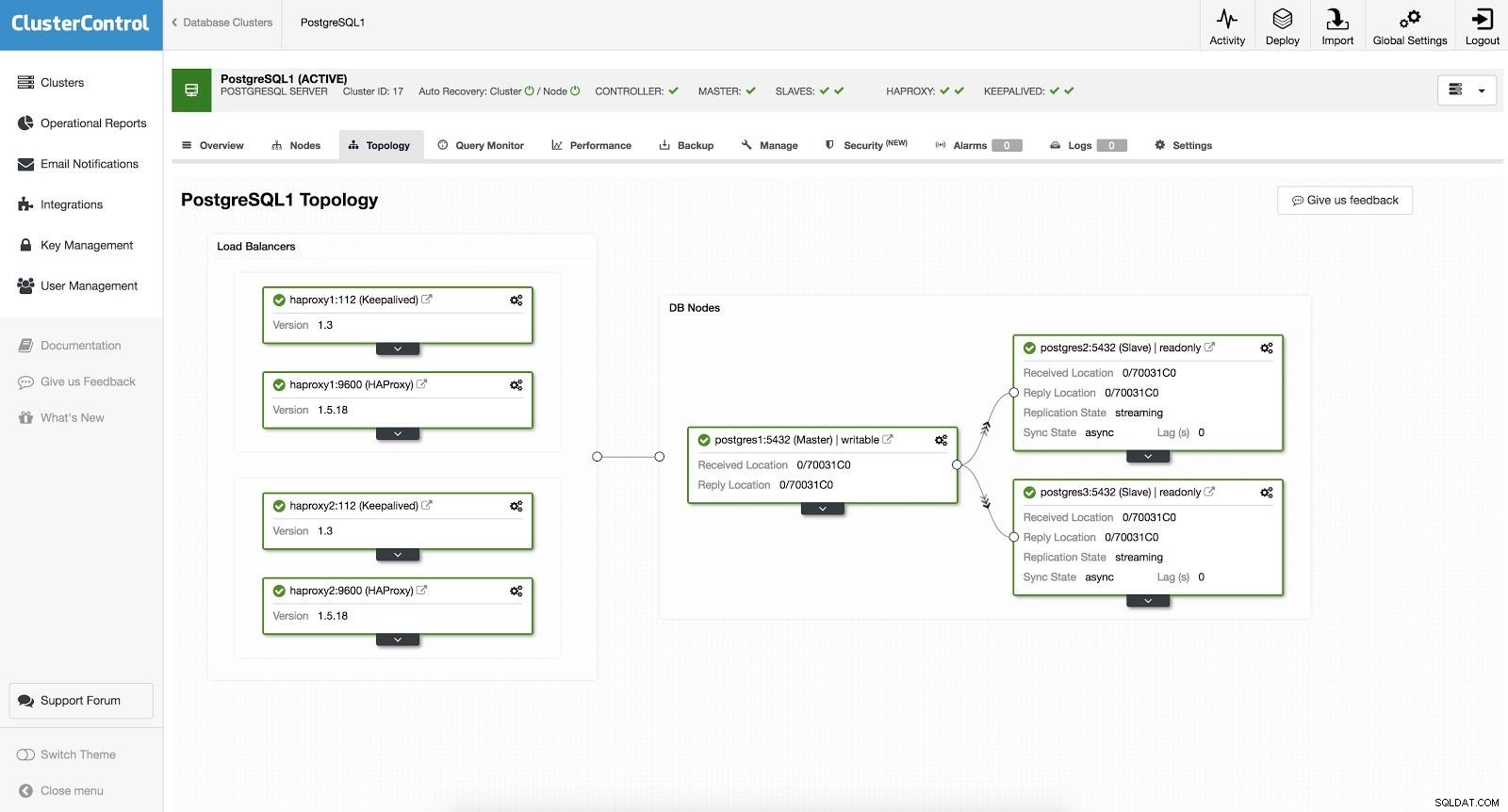 ClusterControl Load Balancer 3
ClusterControl Load Balancer 3 O HAProxy é configurado com duas portas diferentes, uma de leitura/gravação e outra de somente leitura.
Em nossa porta de leitura e gravação, temos nosso servidor mestre como online e o restante de nossos nós como offline. Na porta somente leitura, temos o mestre e os escravos online. Dessa forma, podemos equilibrar o tráfego de leitura entre nossos nós. Ao escrever, será usada a porta de leitura e gravação, que apontará para o mestre.
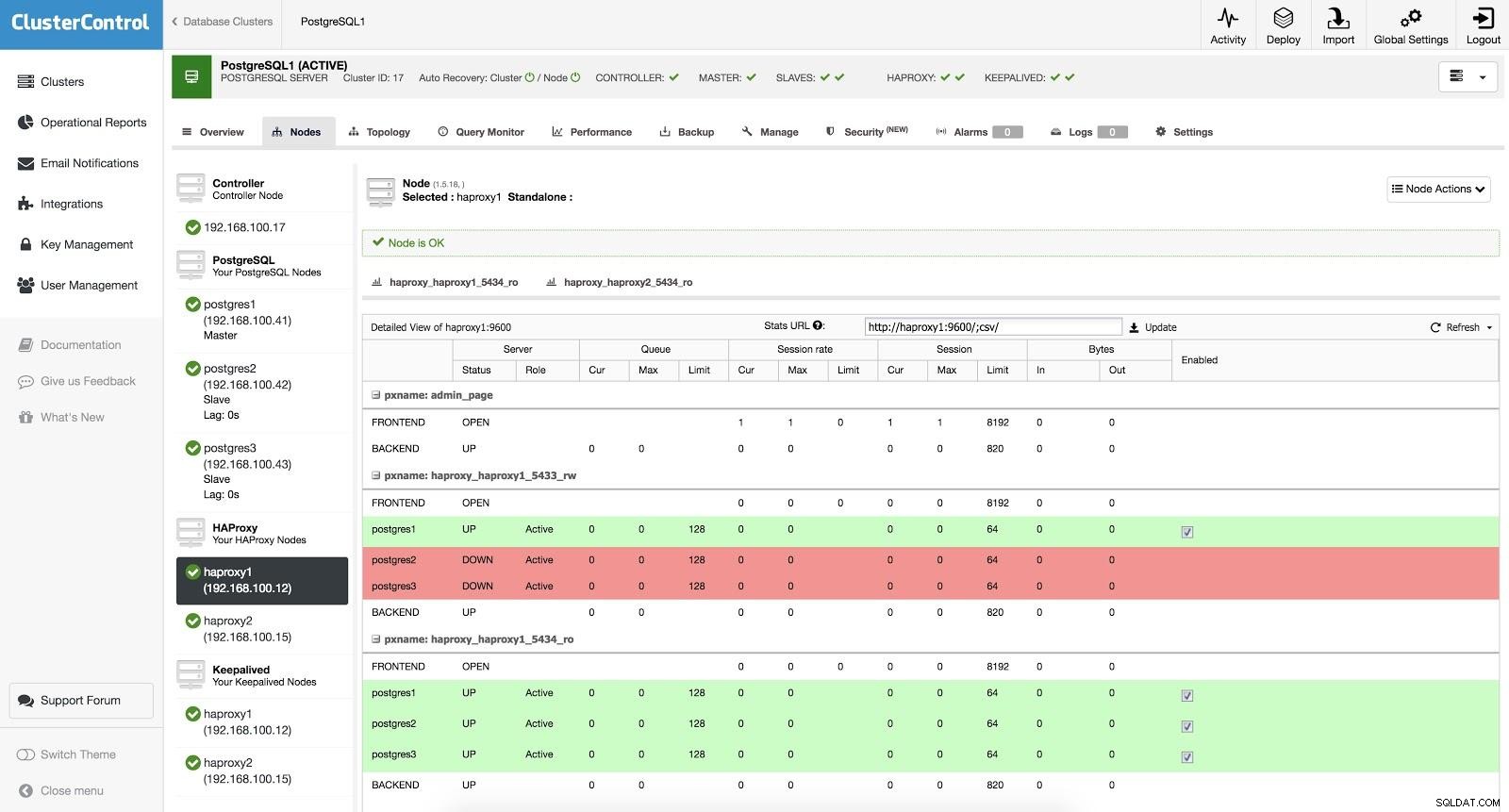 ClusterControl Load Balancer 3
ClusterControl Load Balancer 3 Quando o HAProxy detecta que um de nossos nós, mestre ou escravo, não está acessível, ele automaticamente o marca como offline. O HAProxy não enviará nenhum tráfego para ele. Essa verificação é feita por scripts de verificação de integridade configurados pelo ClusterControl no momento da implantação. Eles verificam se as instâncias estão ativas, se estão em recuperação ou são somente leitura.
Quando o ClusterControl promove um slave para master, nosso HAProxy marca o master antigo como offline (para ambas as portas) e coloca o nó promovido online (na porta de leitura/gravação). Desta forma, nossos sistemas continuam operando normalmente.
Se nosso HAProxy ativo (que recebe um endereço IP virtual ao qual nossos sistemas se conectam) falhar, o Keepalived migra esse IP para nosso HAProxy passivo automaticamente. Isso significa que nossos sistemas podem continuar a funcionar normalmente.
Conclusão
Como pudemos ver, o failover é parte fundamental de qualquer banco de dados de produção. Pode ser útil ao executar tarefas de manutenção comuns ou migrações. Esperamos que este blog tenha sido útil como introdução ao tema, para que você possa continuar pesquisando e criar suas próprias estratégias de failover.



