Há muito tempo, respondi a uma pergunta sobre NULL no Stack Exchange intitulada “Por que não devemos permitir NULLs?” Eu tenho minha cota de irritações e paixões, e o medo de NULLs está bem no topo da minha lista. Um colega me disse recentemente, depois de expressar uma preferência para forçar uma string vazia em vez de permitir NULL:
"Não gosto de lidar com valores nulos no código."
Sinto muito, mas isso não é um bom motivo. Como a camada de apresentação lida com strings vazias ou NULLs não deve ser o driver para o design da sua tabela e modelo de dados. E se você está permitindo uma “falta de valor” em alguma coluna, importa para você do ponto de vista lógico se a “falta de valor” é representada por uma string de comprimento zero ou um NULL? Ou pior, um valor de token como 0 ou -1 para números inteiros ou 1900-01-01 para datas?
Itzik Ben-Gan escreveu recentemente uma série inteira sobre NULLs, e eu recomendo ler tudo:
- Complexidades NULL - Parte 1
- Complexidades NULL - Parte 2
- Complexidades NULL – Parte 3, Recursos padrão ausentes e alternativas T-SQL
- Complexidades NULL – Parte 4, Restrição exclusiva padrão ausente
Mas meu objetivo aqui é um pouco menos complicado do que isso, depois que o tópico surgiu em uma pergunta diferente do Stack Exchange:“Adicione um campo auto now a uma tabela existente”. Lá, o usuário estava adicionando uma nova coluna a uma tabela existente, com a intenção de preenchê-la automaticamente com a data/hora atual. Eles se perguntaram se deveriam deixar NULLs nessa coluna para todas as linhas existentes ou definir um valor padrão (como 1900-01-01, presumivelmente, embora não fossem explícitos).
Pode ser fácil para alguém que saiba filtrar linhas antigas com base em um valor simbólico - afinal, como alguém poderia acreditar que algum tipo de bugiganga Bluetooth foi fabricado ou comprado em 1900-01-01? Bem, eu já vi isso em sistemas atuais onde eles usam alguma data de aparência arbitrária nas visualizações para atuar como um filtro mágico, apresentando apenas linhas onde o valor pode ser confiável. Na verdade, em todos os casos que vi até agora, a data na cláusula WHERE é a data/hora em que a coluna (ou sua restrição padrão) foi adicionada. O que está tudo bem; talvez não seja a melhor maneira de resolver o problema, mas é um maneira.
No entanto, se você não estiver acessando a tabela pela visualização, essa implicação de um conhecido valor ainda pode causar problemas lógicos e relacionados a resultados. O problema lógico é simplesmente que alguém que interage com a mesa precisa saber que 1900-01-01 é um valor de token falso que representa “desconhecido” ou “não relevante”. Para um exemplo do mundo real, qual era a velocidade média de lançamento, em segundos, para um quarterback que jogou na década de 1970, antes de medirmos ou rastrearmos tal coisa? 0 é um bom valor de token para “desconhecido”? Que tal -1? Ou 100? Voltando às datas, se um paciente sem identificação for internado no hospital e estiver inconsciente, o que ele deve inserir como data de nascimento? Não acho que 1900-01-01 seja uma boa ideia, e certamente não era uma boa ideia quando era mais provável que fosse uma data de nascimento real.
Implicações de desempenho de valores de token
Do ponto de vista do desempenho, valores falsos ou “token” como 1900-01-01 ou 9999-21-31 podem apresentar problemas. Vejamos alguns deles com um exemplo baseado vagamente na pergunta recente mencionada acima. Temos uma tabela Widgets e, após alguns retornos de garantia, decidimos adicionar uma coluna EnteredService onde inseriremos a data/hora atual para novas linhas. Em um caso, deixaremos todas as linhas existentes como NULL e, no outro, atualizaremos o valor para nossa data mágica 1900-01-01. (Vamos deixar qualquer tipo de compressão fora da conversa por enquanto.)
CREATE TABLE dbo.Widgets_NULL
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WNULL PRIMARY KEY (WidgetID)
);
CREATE TABLE dbo.Widgets_Token
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WToken PRIMARY KEY (WidgetID)
); Agora vamos inserir as mesmas 100.000 linhas em cada tabela:
INSERT dbo.Widgets_NULL(Description)
OUTPUT inserted.Description INTO dbo.Widgets_Token(Description)
SELECT TOP (100000) LEFT(OBJECT_DEFINITION(o.object_id), 250)
FROM master.sys.all_objects AS o
CROSS JOIN (SELECT TOP (50) * FROM master.sys.all_objects) AS o2
WHERE o.[type] IN (N'P',N'FN',N'V')
AND OBJECT_DEFINITION(o.object_id) IS NOT NULL; Então podemos adicionar a nova coluna e atualizar 10% dos valores existentes com uma distribuição de datas atuais, e os outros 90% para nossa data de token apenas em uma das tabelas:
ALTER TABLE dbo.Widgets_NULL ADD EnteredService datetime;
ALTER TABLE dbo.Widgets_Token ADD EnteredService datetime;
GO
UPDATE dbo.Widgets_NULL
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = '19000101'
WHERE WidgetID <= 90000; Finalmente, podemos adicionar índices:
CREATE INDEX IX_EnteredService ON dbo.Widgets_NULL (EnteredService); CREATE INDEX IX_EnteredService ON dbo.Widgets_Token(EnteredService);
Espaço usado
Sempre ouço “espaço em disco é barato” quando falamos sobre escolhas de tipo de dados, fragmentação e valores de token versus NULL. Minha preocupação não é tanto com o espaço em disco que esses valores extras sem sentido ocupam. É mais que, quando a tabela é consultada, está desperdiçando memória. Aqui podemos ter uma ideia rápida de quanto espaço nossos valores de token consomem antes e depois que a coluna e o índice são adicionados:
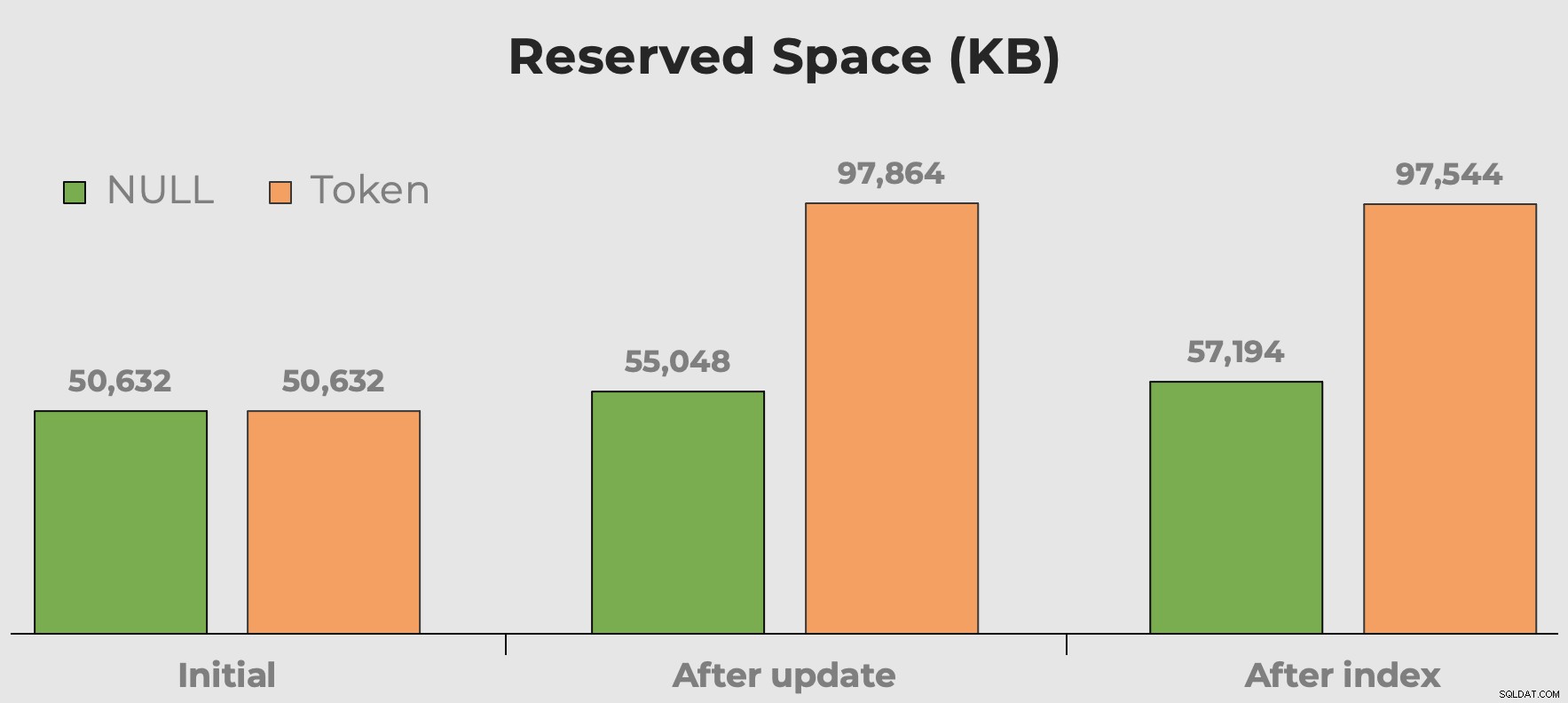 Espaço reservado da tabela após adicionar uma coluna e adicionar um índice. O espaço quase dobra com valores de token.
Espaço reservado da tabela após adicionar uma coluna e adicionar um índice. O espaço quase dobra com valores de token. Execução da consulta
Inevitavelmente, alguém fará suposições sobre os dados na tabela e consultará a coluna EnteredService como se todos os valores fossem legítimos. Por exemplo:
SELECT COUNT(*) FROM dbo.Widgets_Token
WHERE EnteredService <= '20210101';
SELECT COUNT(*) FROM dbo.Widgets_NULL
WHERE EnteredService <= '20210101'; Os valores do token podem atrapalhar as estimativas em alguns casos, mas, mais importante, eles produzirão resultados incorretos (ou pelo menos inesperados). Aqui está o plano de execução para a consulta na tabela com valores de token:
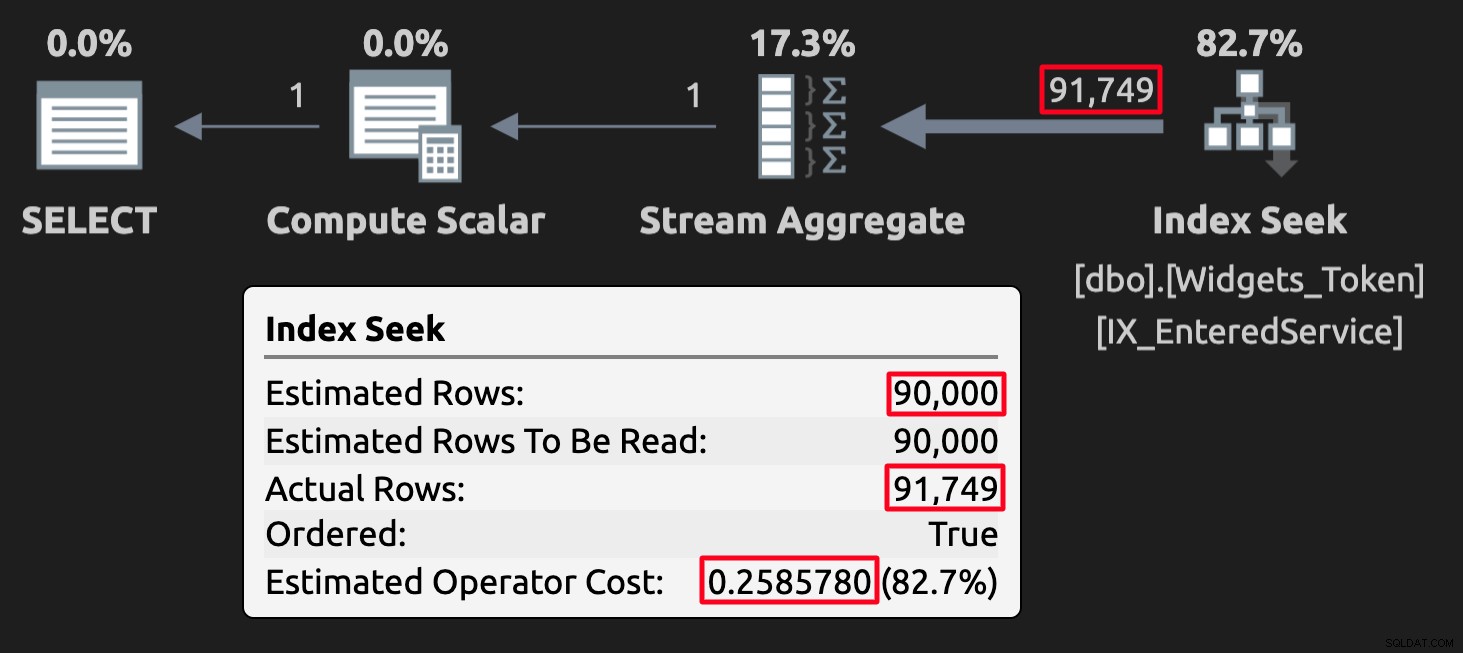 Plano de execução para a tabela de tokens; observe o alto custo.
Plano de execução para a tabela de tokens; observe o alto custo. E aqui está o plano de execução para a consulta na tabela com NULLs:
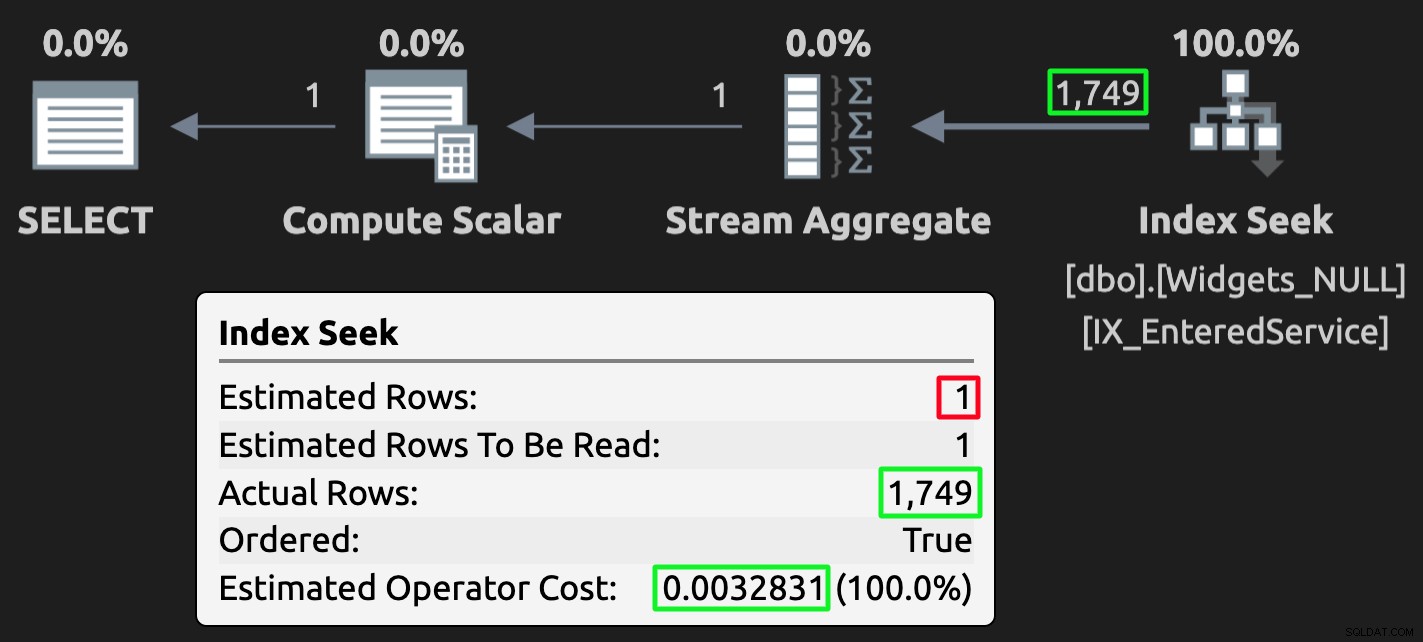 Plano de execução para a tabela NULL; estimativa errada, mas custo muito menor.
Plano de execução para a tabela NULL; estimativa errada, mas custo muito menor. O mesmo aconteceria de outra forma se a consulta pedisse>={alguma data} e 9999-12-31 fosse usado como o valor mágico representando desconhecido.
Novamente, para as pessoas que sabem que os resultados estão errados especificamente porque você usou valores de token, isso não é um problema. Mas todos os outros que não sabem disso – incluindo futuros colegas, outros herdeiros e mantenedores do código e até mesmo você com desafios de memória – provavelmente vão tropeçar.
Conclusão
A escolha de permitir NULLs em uma coluna (ou evitar totalmente NULLs) não deve ser reduzida a uma decisão ideológica ou baseada no medo. Existem desvantagens reais e tangíveis em arquitetar seu modelo de dados para garantir que nenhum valor possa ser NULO ou usar valores sem sentido para representar algo que poderia facilmente não ter sido armazenado. Não estou sugerindo que todas as colunas do seu modelo devam permitir NULLs; apenas que você não se oponha à ideia de NULOS.