Embora o SQL Server no Linux tenha roubado quase todas as manchetes sobre o v.Next, há alguns outros avanços interessantes chegando na próxima versão de nossa plataforma de banco de dados favorita. Na frente do T-SQL, finalmente temos uma maneira integrada de realizar a concatenação de strings agrupadas:
STRING_AGG() . Digamos que temos a seguinte estrutura de tabela simples:
CREATE TABLE dbo.Objects( [object_id] int, [object_name] nvarchar(261), CONSTRAINT PK_Objects PRIMARY KEY([object_id])); CREATE TABLE dbo.Columns( [object_id] int NOT NULL FOREIGN KEY REFERENCES dbo.Objects([object_id]), column_name sysname, CONSTRAINT PK_Columns PRIMARY KEY ([object_id],column_name));
Para testes de desempenho, vamos preencher isso usando
sys.all_objects e sys.all_columns . Mas para uma demonstração simples primeiro, vamos adicionar as seguintes linhas:INSERIR dbo.Objects([object_id],[object_name]) VALUES(1,N'Funcionários'),(2,N'Pedidos'); INSERT dbo.Columns([object_id],column_name) VALUES(1,N'EmployeeID'),(1,N'CurrentStatus'), (2,N'OrderID'),(2,N'OrderDate'),(2 ,N'CódigoDoCliente');
Se os fóruns forem uma indicação, é um requisito muito comum retornar uma linha para cada objeto, juntamente com uma lista de nomes de coluna separados por vírgulas. (Extrapole isso para qualquer tipo de entidade que você modele dessa maneira – nomes de produtos associados a um pedido, nomes de peças envolvidas na montagem de um produto, subordinados subordinados a um gerente etc.) Assim, por exemplo, com os dados acima, teríamos quer saída assim:
colunas de objeto--------- ----------------------------Funcionários EmployeeID,CurrentStatusOrders OrderID,OrderDate, CustomerID
A maneira como faríamos isso nas versões atuais do SQL Server provavelmente seria usar
FOR XML PATH , como demonstrei ser o mais eficiente fora do CLR neste post anterior. Neste exemplo, ficaria assim:SELECT [object] =o.[object_name], [columns] =STUFF( (SELECT N',' + c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] FOR XML PATH, TYPE ).value(N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS o;
Previsivelmente, obtemos a mesma saída demonstrada acima. No SQL Server v.Next, poderemos expressar isso de forma mais simples:
SELECT [object] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',')FROM dbo.Objects AS oINNER JOIN dbo.Columns AS cON o.[object_id] =c.[ object_id]GROUP BY o.[object_name];
Novamente, isso produz exatamente a mesma saída. E conseguimos fazer isso com uma função nativa, evitando tanto o caro
FOR XML PATH andaime e o STUFF() função usada para remover a primeira vírgula (isso acontece automaticamente). E quanto ao pedido?
Um dos problemas com muitas das soluções kludge para concatenação agrupada é que a ordenação da lista separada por vírgulas deve ser considerada arbitrária e não determinística.
Para o
XML PATH solução, demonstrei em outro post anterior que adicionar um ORDER BY é trivial e garantido. Portanto, neste exemplo, poderíamos ordenar a lista de colunas por nome de coluna em ordem alfabética em vez de deixar para o SQL Server classificar (ou não):SELECT [object] =[object_name], [columns] =STUFF( (SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] ORDER BY c. nome_da_coluna -- altera apenas FOR XML PATH, TYPE ).value(N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS o;
Saída:
colunas de objeto--------- ----------------------------Funcionários CurrentStatus,EmployeeIDOrder CustomerID,OrderDate, Código do pedido
CTP 1.1 adiciona
WITHIN GROUP para STRING_AGG() , então, usando a nova abordagem, podemos dizer:SELECT [object] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',') WITHIN GROUP (ORDER BY c.column_name) -- apenas changeFROM dbo.Objects AS oINNER JOIN dbo. Colunas AS cON o.[object_id] =c.[object_id]GROUP BY o.[object_name];
Agora temos os mesmos resultados. Observe que, assim como um
ORDER BY normal cláusula, você pode adicionar várias colunas de ordenação ou expressões dentro de WITHIN GROUP () . Tudo bem, desempenho já!
Usando processadores quad-core de 2,6 GHz, 8 GB de memória e SQL Server CTP1.1 (14.0.100.187), criei um novo banco de dados, recriei essas tabelas e adicionei linhas de
sys.all_objects e sys.all_columns . Certifiquei-me de incluir apenas objetos que tivessem pelo menos uma coluna:INSERT dbo.Objects([object_id], [object_name]) -- 656 linhas SELECT [object_id], QUOTENAME(s.name) + N'.' + QUOTENAME(o.name) FROM sys.all_objects AS o INNER JOIN sys.schemas AS s ON o.[schema_id] =s.[schema_id] WHERE EXISTS ( SELECT 1 FROM sys.all_columns WHERE [object_id] =o.[object_id] ]); INSERT dbo.Columns([object_id], column_name) -- 8.085 linhas SELECT [object_id], name FROM sys.all_columns AS c WHERE EXISTS ( SELECT 1 FROM dbo.Objects WHERE [object_id] =c.[object_id] );
No meu sistema, isso gerou 656 objetos e 8.085 colunas (seu sistema pode produzir números ligeiramente diferentes).
Os Planos
Primeiro, vamos comparar os planos e as guias Table I/O para nossas duas consultas não ordenadas, usando o Plan Explorer. Aqui estão as métricas gerais de tempo de execução:
Métricas de tempo de execução para XML PATH (superior) e STRING_AGG() (inferior)
O plano gráfico e E/S de tabela doFOR XML PATHinquerir:
Plano e E/S de tabela para XML PATH, sem pedido
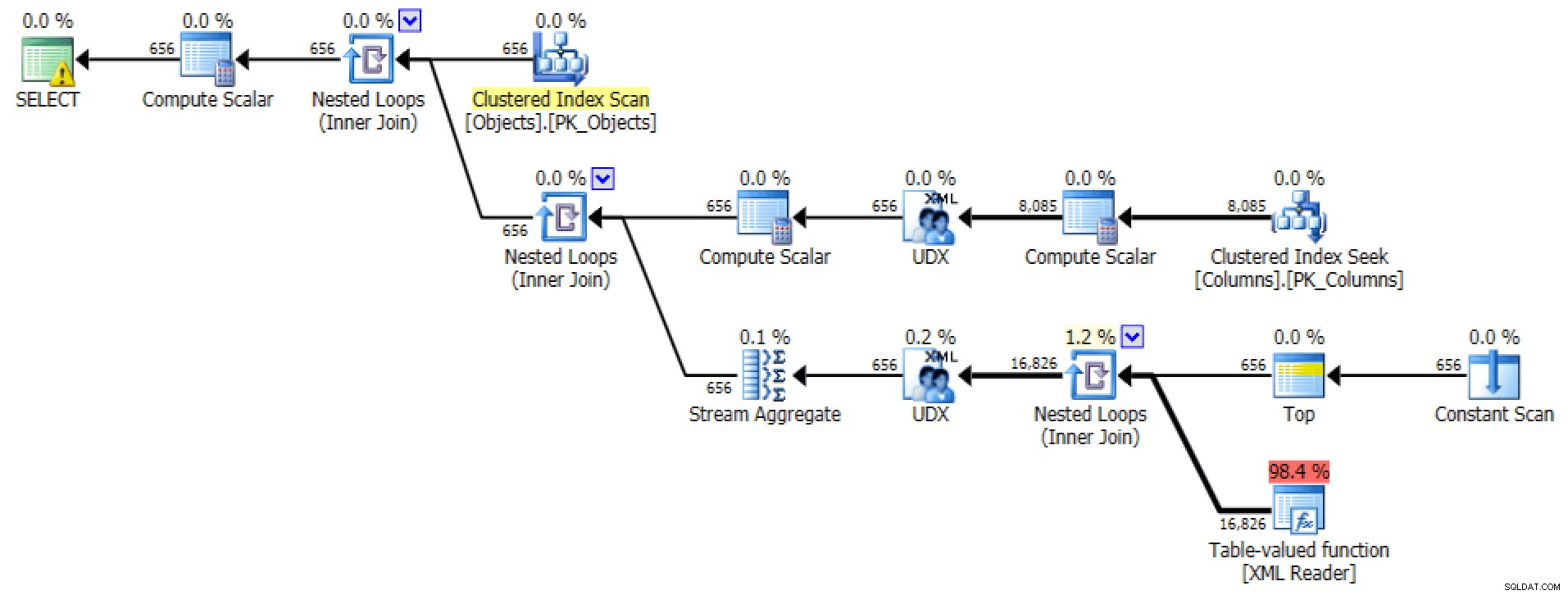
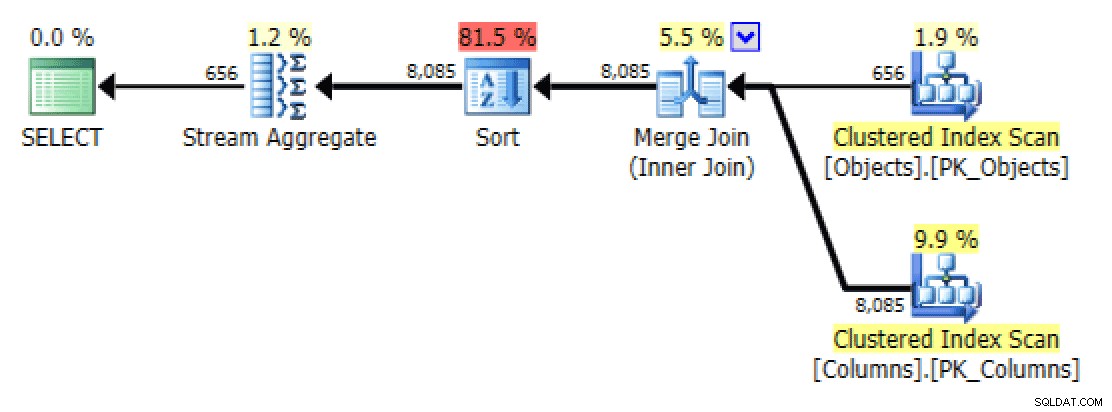
E doSTRING_AGGversão:
Plano e E/S de tabela para STRING_AGG, sem pedidos
Para este último, a busca de índice clusterizado parece um pouco preocupante para mim. Este parecia um bom caso para testar o raramente usadoFORCESCANdica (e não, isso certamente não ajudaria oFOR XML PATHinquerir):
SELECT [object] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',')FROM dbo.Objects AS oINNER JOIN dbo.Columns AS c WITH (FORCESCAN) -- adicionado hintON o .[object_id] =c.[object_id]GROUP BY o.[object_name];
Agora, o plano e a guia Table I/O parecem muito muito melhor, pelo menos à primeira vista:
Plano e E/S de tabela para STRING_AGG(), sem ordenação, com FORCESCAN
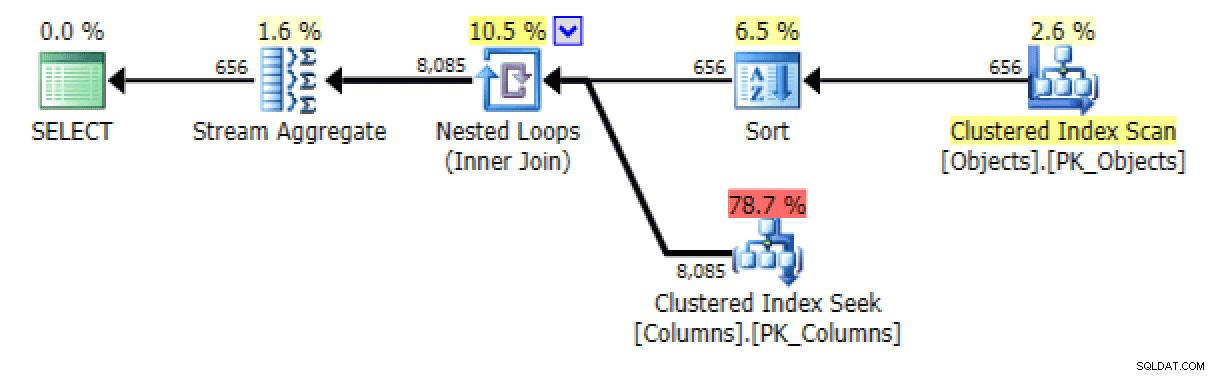
As versões ordenadas das consultas geram aproximadamente os mesmos planos. Para oFOR XML PATHversão, uma classificação é adicionada:
Classificação adicionada na versão FOR XML PATH
ParaSTRING_AGG(), uma varredura é escolhida neste caso, mesmo sem oFORCESCANdica e nenhuma operação de classificação adicional é necessária - portanto, o plano parece idêntico aoFORCESCANversão.
Em escala
Analisar um plano e métricas de tempo de execução únicas pode nos dar uma ideia sobre seSTRING_AGG()tem um desempenho melhor do que oFOR XML PATHexistente solução, mas um teste maior pode fazer mais sentido. O que acontece quando realizamos a concatenação agrupada 5.000 vezes?
SELECT SYSDATETIME();GO DECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id ] =c.[object_id] GROUP BY o.[object_name];GO 5000SELECT [string_agg, unordered] =SYSDATETIME();GO DECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',' ) FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c WITH (FORCESCAN) ON o.[object_id] =c.[object_id] GROUP BY o.[object_name];GO 5000SELECT [string_agg, unordered, forcescan] =SYSDATETIME( ); GODECLARE @x nvarchar(max);SELECT @x =STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] FOR XML PATH, TYPE).value (N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS o;GO 5000SELECT [para caminho xml, não ordenado] =SYSDATETIME(); GODECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',') WITHIN GROUP (ORDER BY c.column_name) FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id ] =c.[object_id] GROUP BY o.[object_name];GO 5000SELECT [string_agg, ordenado] =SYSDATETIME(); GODECLARE @x nvarchar(max);SELECT @x =STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] ORDER BY c.column_name FOR XML PATH , TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS oORDER BY o.[object_name];GO 5000SELECT [para caminho xml , ordenado] =SYSDATETIME();
Depois de executar este script cinco vezes, calculei a média dos números de duração e aqui estão os resultados:
Duração (milissegundos) para várias abordagens de concatenação agrupada
Podemos ver que nossoFORCESCANA dica realmente piorou as coisas – enquanto mudamos o custo da busca de índice clusterizado, a classificação foi realmente muito pior, embora os custos estimados os considerassem relativamente equivalentes. Mais importante, podemos ver queSTRING_AGG()oferece um benefício de desempenho, quer as strings concatenadas precisem ou não ser ordenadas de uma maneira específica. Como comSTRING_SPLIT(), que examinei em março, estou bastante impressionado com o fato de essa função ser bem dimensionada antes de "v1".
Tenho mais testes planejados, talvez para um post futuro:
- Quando todos os dados vêm de uma única tabela, com e sem um índice que suporta ordenação
- Testes de desempenho semelhantes no Linux
Enquanto isso, se você tiver casos de uso específicos para concatenação agrupada, compartilhe-os abaixo (ou envie um e-mail para abertrand@sentryone.com). Estou sempre aberto a garantir que meus testes sejam o mais real possível.