Na semana passada, fiz algumas comparações rápidas de desempenho, colocando o novo
STRING_AGG() função contra o tradicional FOR XML PATH abordagem que usei por muito tempo. Testei tanto a ordem indefinida/arbitrária quanto a ordem explícita e STRING_AGG() saiu por cima em ambos os casos:- SQL Server v.Next :Desempenho STRING_AGG(), Parte 1
Para esses testes, deixei de fora várias coisas (nem todas intencionalmente):
- Mikael Eriksson e Grzegorz Łyp apontaram que eu não estava usando o
FOR XML PATHabsolutamente mais eficiente construir (e para ser claro, eu nunca fiz). - Não fiz nenhum teste no Linux; apenas no Windows. Não espero que sejam muito diferentes, mas como Grzegorz viu durações muito diferentes, vale a pena investigar mais.
- Também testei apenas quando a saída seria uma string finita e não-LOB - que acredito ser o caso de uso mais comum (não acho que as pessoas normalmente concatenarão cada linha em uma tabela em uma única linha separada por vírgula string, mas é por isso que perguntei no meu post anterior seu(s) caso(s) de uso).
- Para os testes de ordenação, não criei um índice que pudesse ser útil (ou tentei qualquer coisa em que todos os dados fossem provenientes de uma única tabela).
Neste post, vou lidar com alguns desses itens, mas não todos eles.
PARA O CAMINHO XML
Eu estava usando o seguinte:
... FOR XML PATH, TYPE).value(N'.[1]', ...
Após este comentário de Mikael, atualizei meu código para usar essa construção ligeiramente diferente:
... FOR XML PATH(''), TYPE).value(N'text()[1]', ... Linux x Windows
Inicialmente, me preocupei apenas em executar testes no Windows:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. Developer Edition (64-bit) on Windows Server 2016 Datacenter 6.3(Build 14393: ) (Hypervisor)
Mas Grzegorz fez questão de que ele (e presumivelmente muitos outros) só tinha acesso ao sabor Linux do CTP 1.1. Então eu adicionei o Linux à minha matriz de teste:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. on Linux (Ubuntu 16.04.1 LTS)
Algumas observações interessantes, mas completamente tangenciais:
@@VERSIONnão mostra a edição nesta compilação, masSERVERPROPERTY('Edition')retorna aDeveloper Edition (64-bit)esperada .- Com base nos tempos de compilação codificados nos binários, as versões Windows e Linux parecem agora ser compiladas ao mesmo tempo e da mesma fonte. Ou isso foi uma coincidência maluca.
Testes não ordenados
Comecei testando a saída ordenada arbitrariamente (onde não há ordenação explicitamente definida para os valores concatenados). Seguindo Grzegorz, usei WideWorldImporters (Padrão), mas realizei uma junção entre
Sales.Orders e Sales.OrderLines . O requisito fictício aqui é gerar uma lista de todos os pedidos e, junto com cada pedido, uma lista separada por vírgulas de cada StockItemID . Desde
StockItemID for um inteiro, podemos usar um varchar definido , o que significa que a string pode ter 8.000 caracteres antes que tenhamos que nos preocupar com a necessidade de MAX. Como um int pode ter um comprimento máximo de 11 (realmente 10, se não assinado), mais uma vírgula, isso significa que um pedido teria que suportar cerca de 8.000/12 (666) itens de estoque no pior cenário (por exemplo, todos os valores de StockItemID têm 11 dígitos). No nosso caso, o ID mais longo é de 3 dígitos, portanto, até que os dados sejam adicionados, precisaríamos de 8.000/4 (2.000) itens de estoque exclusivos em qualquer pedido único para justificar MAX. No nosso caso, há apenas 227 itens em estoque no total, então o MAX não é necessário, mas você deve ficar de olho nisso. Se uma string tão grande for possível em seu cenário, você precisará usar varchar(max) em vez do padrão (STRING_AGG() retorna nvarchar(max) , mas trunca para 8.000 bytes, a menos que a entrada é um tipo MAX). As consultas iniciais (para mostrar a saída de amostra e observar as durações para execuções únicas):
SET STATISTICS TIME ON;
GO
SELECT o.OrderID, StockItemIDs = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT o.OrderID,
StockItemIDs = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Sample output:
OrderID StockItemIDs
======= ============
1 67
2 50,10
3 114
4 206,130,50
5 128,121,155
Important SET STATISTICS TIME metrics (SQL Server Execution Times):
Windows:
STRING_AGG: CPU time = 217 ms, elapsed time = 405 ms.
FOR XML PATH: CPU time = 1954 ms, elapsed time = 2097 ms.
Linux:
STRING_AGG: CPU time = 627 ms, elapsed time = 472 ms.
FOR XML PATH: CPU time = 2188 ms, elapsed time = 2223 ms.
*/ Ignorei completamente os dados de tempo de análise e compilação, pois eles sempre eram exatamente zero ou próximos o suficiente para serem irrelevantes. Houve pequenas variações nos tempos de execução para cada execução, mas não muito – os comentários acima refletem o delta típico em tempo de execução (
STRING_AGG parecia tirar uma pequena vantagem do paralelismo lá, mas apenas no Linux, enquanto FOR XML PATH não em nenhuma das plataformas). Ambas as máquinas tinham um único soquete, CPU quad-core alocada, 8 GB de memória, configuração pronta para uso e nenhuma outra atividade. Então eu queria testar em escala (simplesmente uma única sessão executando a mesma consulta 500 vezes). Eu não queria retornar toda a saída, como na consulta acima, 500 vezes, pois isso sobrecarregaria o SSMS – e espero que não represente cenários de consulta do mundo real de qualquer maneira. Então, atribuí a saída às variáveis e apenas medi o tempo geral de cada lote:
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID, @x = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID,
@x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Fiz esses testes três vezes e a diferença foi profunda – quase uma ordem de magnitude. Aqui está a duração média nos três testes:
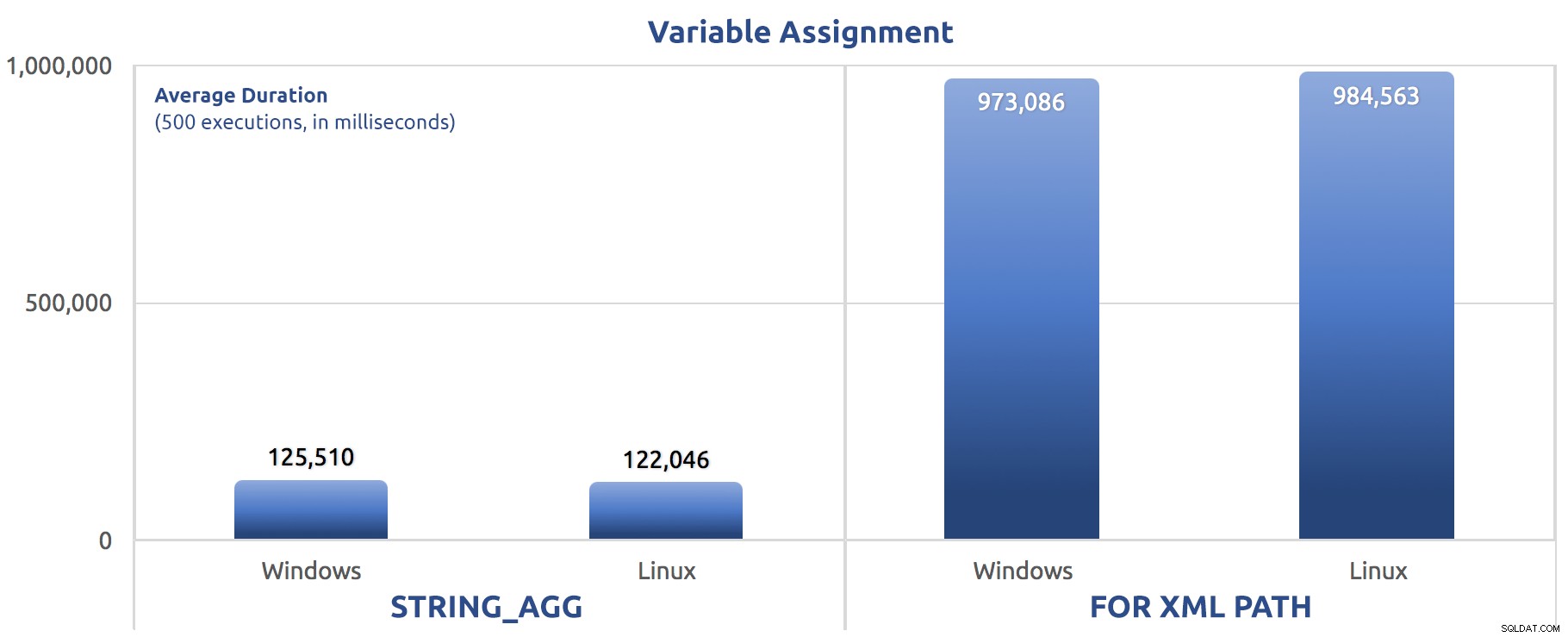 Duração média, em milissegundos, para 500 execuções de atribuição de variável
Duração média, em milissegundos, para 500 execuções de atribuição de variável Eu testei uma variedade de outras coisas dessa maneira também, principalmente para ter certeza de que estava cobrindo os tipos de testes que Grzegorz estava executando (sem a parte LOB).
- Selecionando apenas o comprimento da saída
- Obtendo o comprimento máximo da saída (de uma linha arbitrária)
- Selecionando toda a saída em uma nova tabela
Selecionando apenas o comprimento da saída
Esse código apenas percorre cada pedido, concatena todos os valores de StockItemID e retorna apenas o comprimento.
SET STATISTICS TIME ON;
GO
SELECT LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 142 ms, elapsed time = 351 ms.
FOR XML PATH: CPU time = 1984 ms, elapsed time = 2120 ms.
Linux:
STRING_AGG: CPU time = 310 ms, elapsed time = 191 ms.
FOR XML PATH: CPU time = 2149 ms, elapsed time = 2167 ms.
*/ Para a versão em lote, novamente, usei atribuição de variável, em vez de tentar retornar muitos conjuntos de resultados ao SSMS. A atribuição de variável terminaria em uma linha arbitrária, mas isso ainda requer verificações completas, porque a linha arbitrária não é selecionada primeiro.
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Métricas de desempenho de 500 execuções:
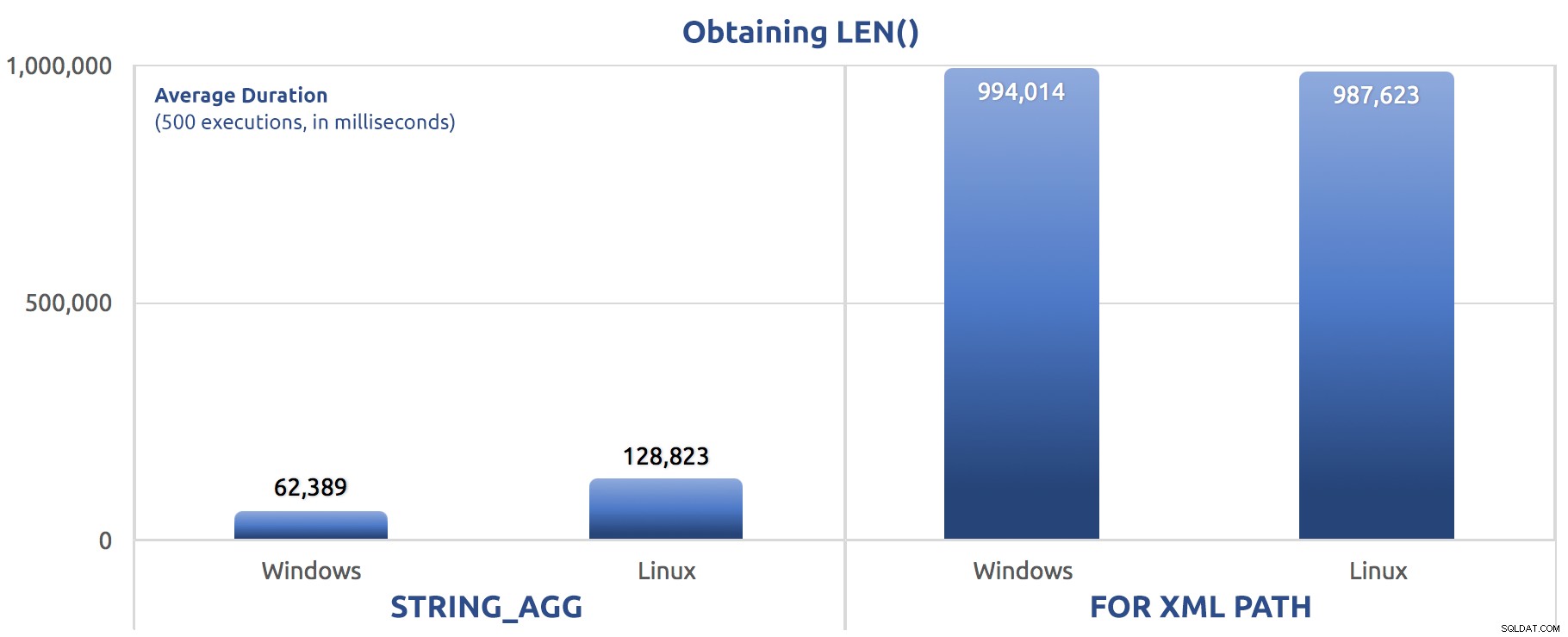 500 execuções de atribuição de LEN() a uma variável
500 execuções de atribuição de LEN() a uma variável Novamente, vemos
FOR XML PATH é muito mais lento, tanto no Windows quanto no Linux. Selecionando o comprimento máximo da saída
Uma pequena variação do teste anterior, este apenas recupera o máximo comprimento da saída concatenada:
SET STATISTICS TIME ON;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STUFF(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 188 ms, elapsed time = 48 ms.
FOR XML PATH: CPU time = 1891 ms, elapsed time = 907 ms.
Linux:
STRING_AGG: CPU time = 270 ms, elapsed time = 83 ms.
FOR XML PATH: CPU time = 2725 ms, elapsed time = 1205 ms.
*/ E em escala, apenas atribuímos essa saída a uma variável novamente:
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STUFF
(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime(); Resultados de desempenho, para 500 execuções, em média em três execuções:
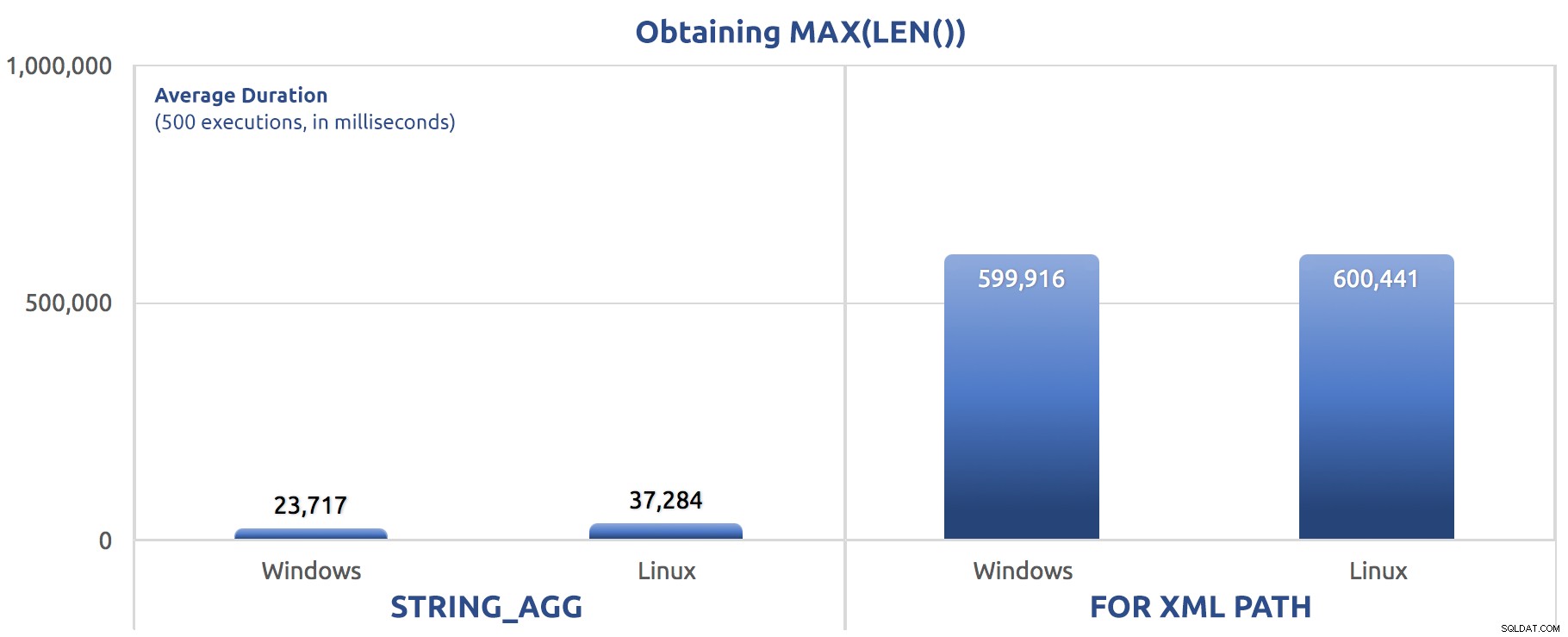 500 execuções de atribuição de MAX(LEN()) a uma variável
500 execuções de atribuição de MAX(LEN()) a uma variável Você pode começar a notar um padrão nesses testes –
FOR XML PATH é sempre um cão, mesmo com as melhorias de desempenho sugeridas no meu post anterior. SELECIONAR EM
Eu queria ver se o método de concatenação tinha algum impacto na escrita os dados de volta ao disco, como é o caso em alguns outros cenários:
SET NOCOUNT ON;
GO
SET STATISTICS TIME ON;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_AGG;
SELECT o.OrderID, x = STRING_AGG(ol.StockItemID, ',')
INTO dbo.HoldingTank_AGG
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_XML;
SELECT o.OrderID, x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
INTO dbo.HoldingTank_XML
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 218 ms, elapsed time = 90 ms.
FOR XML PATH: CPU time = 4202 ms, elapsed time = 1520 ms.
Linux:
STRING_AGG: CPU time = 277 ms, elapsed time = 108 ms.
FOR XML PATH: CPU time = 4308 ms, elapsed time = 1583 ms.
*/ Neste caso, vemos que talvez
SELECT INTO foi capaz de tirar vantagem de um pouco de paralelismo, mas ainda vemos FOR XML PATH luta, com tempos de execução uma ordem de magnitude maior que STRING_AGG . A versão em lote apenas trocou os comandos SET STATISTICS por
SELECT sysdatetime(); e adicionou o mesmo GO 500 após os dois lotes principais como nos testes anteriores. Aqui está como isso aconteceu (mais uma vez, me diga se você já ouviu isso antes):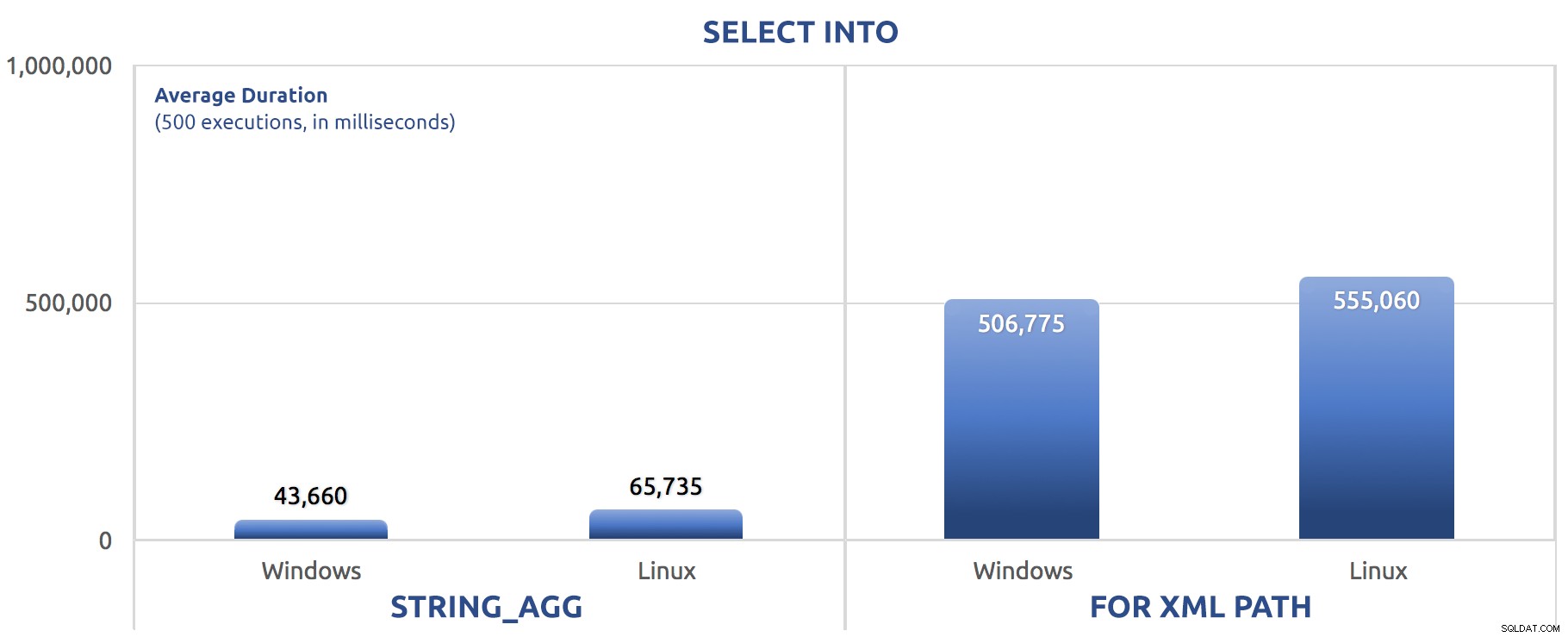 500 execuções de SELECT INTO
500 execuções de SELECT INTO Testes solicitados
Executei os mesmos testes usando a sintaxe ordenada, por exemplo:
... STRING_AGG(ol.StockItemID, ',')
WITHIN GROUP (ORDER BY ol.StockItemID) ...
... WHERE ol.OrderID = o.OrderID
ORDER BY ol.StockItemID
FOR XML PATH('') ... Isso teve muito pouco impacto em qualquer coisa – o mesmo conjunto de quatro equipamentos de teste mostrou métricas e padrões quase idênticos em todos os aspectos.
Estarei curioso para ver se isso é diferente quando a saída concatenada está em não-LOB ou onde a concatenação precisa ordenar strings (com ou sem um índice de suporte).
Conclusão
Para strings não LOB , está claro para mim que
STRING_AGG tem uma vantagem de desempenho definitiva sobre FOR XML PATH , no Windows e no Linux. Observe que, para evitar o requisito de varchar(max) ou nvarchar(max) , não usei nada semelhante aos testes que Grzegorz executou, o que significaria simplesmente concatenar todos os valores de uma coluna, em uma tabela inteira, em uma única string. Na minha próxima postagem, examinarei o caso de uso em que a saída da string concatenada poderia ser maior que 8.000 bytes e, portanto, os tipos e conversões de LOB teriam que ser usados. 


