As duas respostas mais votadas usam muitas tabelas obsoletas que devem ser evitadas.
Aqui está uma maneira muito mais limpa de fazer isso.
Obtenha todas as tabelas das quais um procedimento armazenado depende:
SELECT DISTINCT p.name AS proc_name, t.name AS table_name
FROM sys.sql_dependencies d
INNER JOIN sys.procedures p ON p.object_id = d.object_id
INNER JOIN sys.tables t ON t.object_id = d.referenced_major_id
ORDER BY proc_name, table_name
Funciona com MS SQL SERVER 2005+
Lista de alterações:
sysdependsdeve ser substituído porsys.sql_dependencies- A nova tabela usa
object_idem vez deid - A nova tabela usa
referenced_major_idem vez dedepid
- A nova tabela usa
- Usando
sysobjectsdeve ser substituído por visualizações de catálogo de sistema mais focadas- Como marc_s apontou, use
sys.tablesesys.procedures - Observação :Isso evita ter que verificar onde
o.xtype = 'p'(etc.)
- Como marc_s apontou, use
-
Além disso, não há necessidade de um CTE que useROW_NUMBER()apenas para garantir que apenas um de cada conjunto de registros seja retornado. É isso queDISTINCTexiste para!
- Na verdade, o SQL é inteligente o suficiente para usar DISTINCT nos bastidores.
-
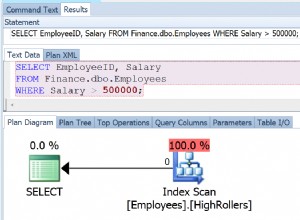
Eu envio como evidência:Anexo A . As consultas a seguir possuem o mesmo Plano de Execução!
-- Complex WITH MyPeople AS ( SELECT id, name, ROW_NUMBER() OVER(PARTITION BY id, name ORDER BY id, name) AS row FROM People) SELECT id, name FROM MyPeople WHERE row = 1 -- Better SELECT DISTINCT id, name FROM People