Quando você precisa trabalhar com um banco de dados com o qual não está 100% familiarizado, pode ficar sobrecarregado com as centenas de métricas disponíveis. Quais são os mais importantes? O que devo monitorar e por quê? Quais padrões nas métricas devem soar alguns alarmes? Nesta postagem do blog, tentaremos apresentar algumas das métricas mais importantes para ficar de olho durante a execução do MySQL ou MariaDB em produção.
Com_* Contadores de status
Começaremos com os contadores Com_* - eles definem o número e os tipos de consultas que o MySQL executa. Estamos falando aqui de tipos de consulta como SELECT, INSERT, UPDATE e muito mais. É muito importante ficar de olho neles, pois picos repentinos ou quedas inesperadas podem sugerir que algo deu errado no sistema.
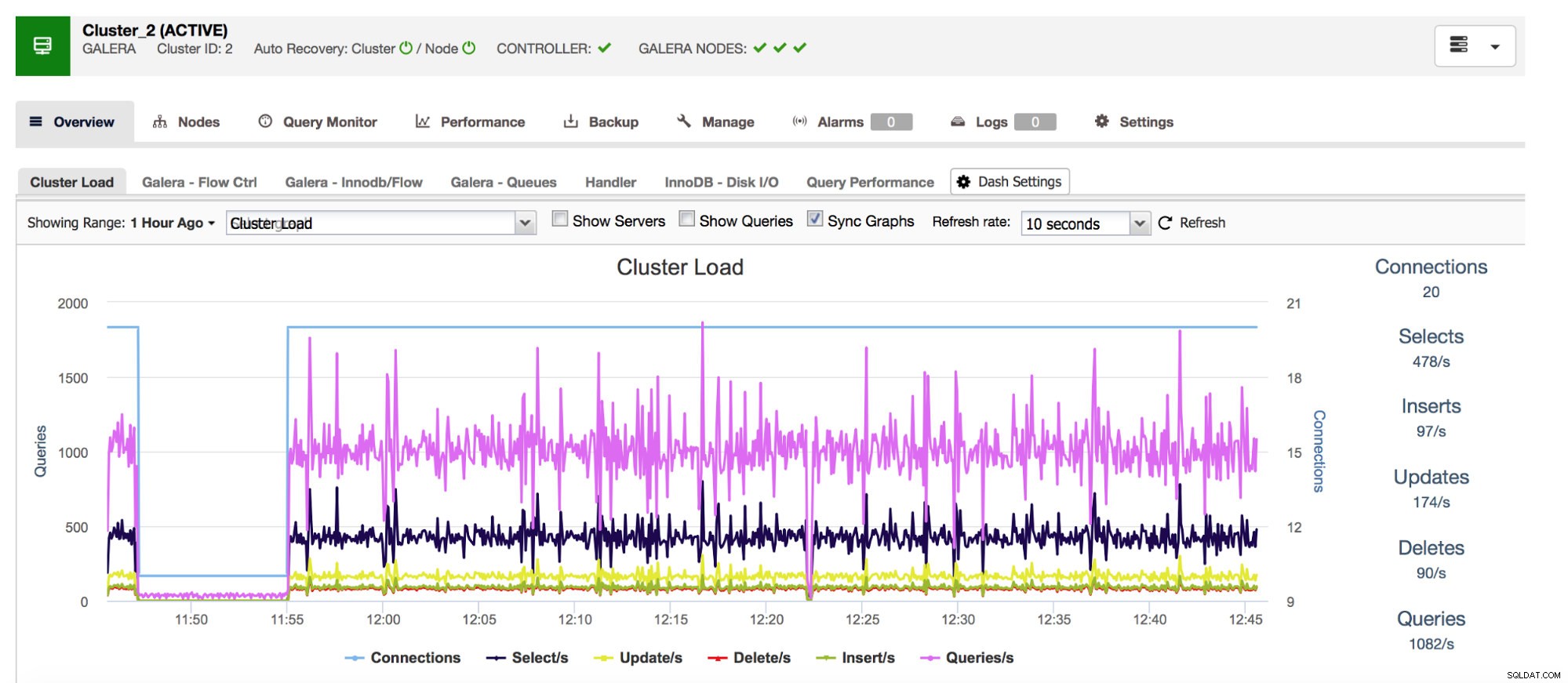
Nosso sistema de gerenciamento de banco de dados com tudo incluído ClusterControl mostra esses dados relacionados aos tipos de consulta mais comuns na seção "Visão geral".
Handler_* Contadores de status
Uma categoria de métricas que você deve ficar de olho são os contadores Handler_* no MySQL. Os contadores Com_* informam que tipo de consultas sua instância MySQL está executando, mas um SELECT pode ser totalmente diferente de outro - SELECT pode ser uma pesquisa de chave primária, também pode ser uma varredura de tabela se um índice não puder ser usado. Os manipuladores informam como o MySQL acessa os dados armazenados - isso é muito útil para investigar os problemas de desempenho e avaliar se há um possível ganho na revisão de consultas e indexação adicional.
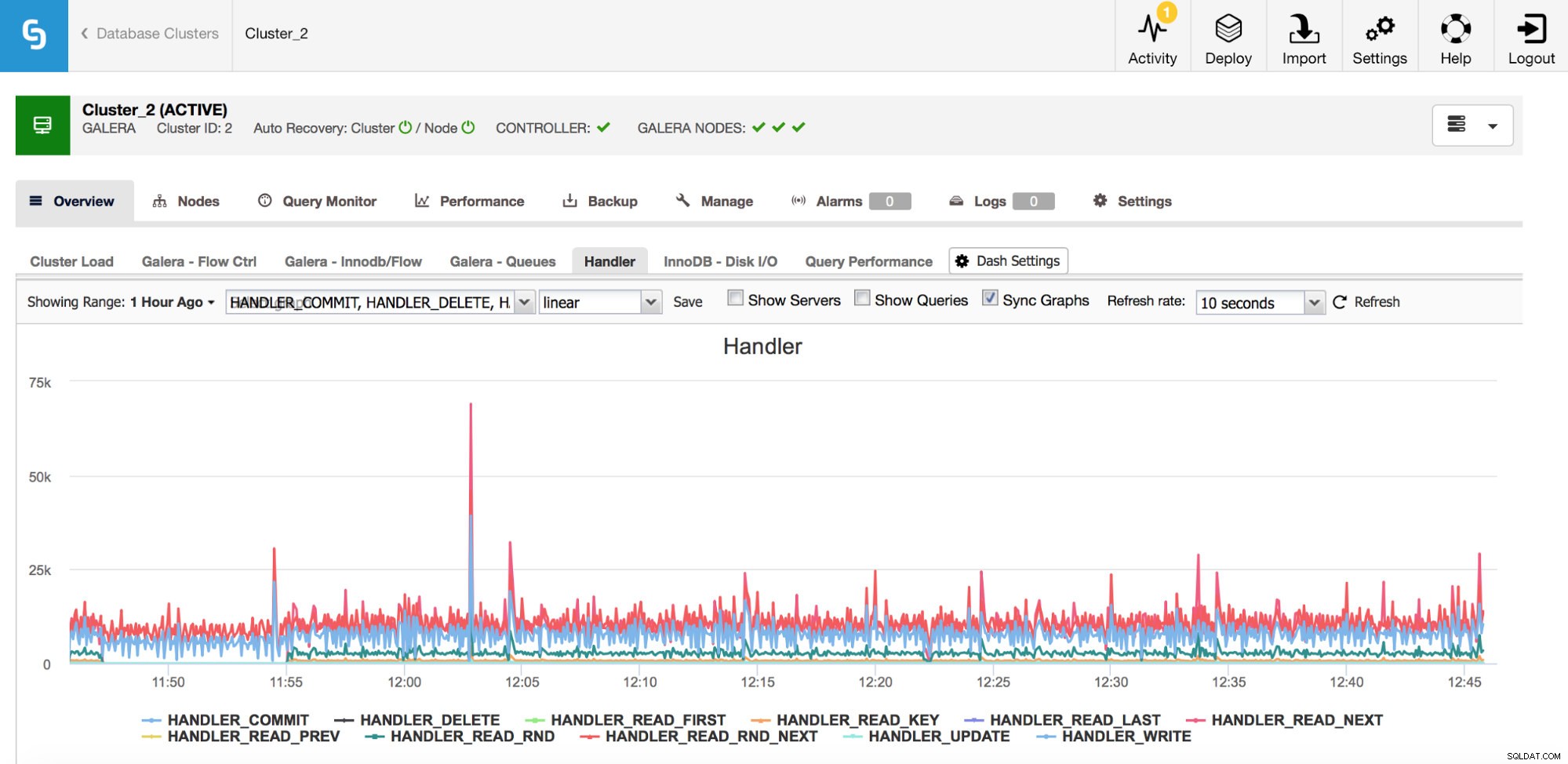
Como você pode ver no gráfico acima, existem muitas métricas para rastrear (e os gráficos do ClusterControl são os mais importantes) - não abordaremos todas elas aqui (você pode encontrar descrições na documentação do MySQL), mas gostaríamos de destacar as os mais importantes.
Handler_read_rnd_next - sempre que o MySQL acessar uma linha sem uma pesquisa de índice, em ordem seqüencial, este contador será aumentado. Se em sua carga de trabalho handler_read_rnd_next for responsável por uma alta porcentagem de todo o tráfego, isso significa que suas tabelas, provavelmente, poderiam usar alguns índices adicionais porque o MySQL faz muitas varreduras de tabela.
Handler_read_next e handler_read_prev - esses dois contadores são atualizados sempre que o MySQL faz uma varredura de índice - para frente ou para trás. Handler_read_first e handler_read_last podem esclarecer um pouco mais sobre que tipo de varredura de índice são essas - se estivermos falando de varredura de índice completa (para frente ou para trás), esses dois contadores serão atualizados.
Handler_read_key - este contador, por outro lado, se seu valor for alto, informa que suas tabelas estão bem indexadas, pois muitas das linhas foram acessadas por meio de uma pesquisa de índice.
Atraso de replicação
Se você estiver trabalhando com a replicação do MySQL, o atraso da replicação é uma métrica que você definitivamente deseja monitorar. O atraso de replicação é inevitável e você terá que lidar com isso, mas para lidar com isso você precisa entender por que isso acontece. Para isso o primeiro passo será saber _quando_ ele apareceu.
Sempre que você vê um pico de atraso de replicação, você deseja verificar outros gráficos para obter mais pistas - por que isso aconteceu? O que pode ter causado isso? Os motivos podem ser diferentes - DMLs longos e pesados, aumento significativo no número de DMLs executados em um curto período de tempo, limitações de CPU ou E/S.
E/S do InnoDB
Há uma série de métricas importantes para monitorar relacionadas à E/S.
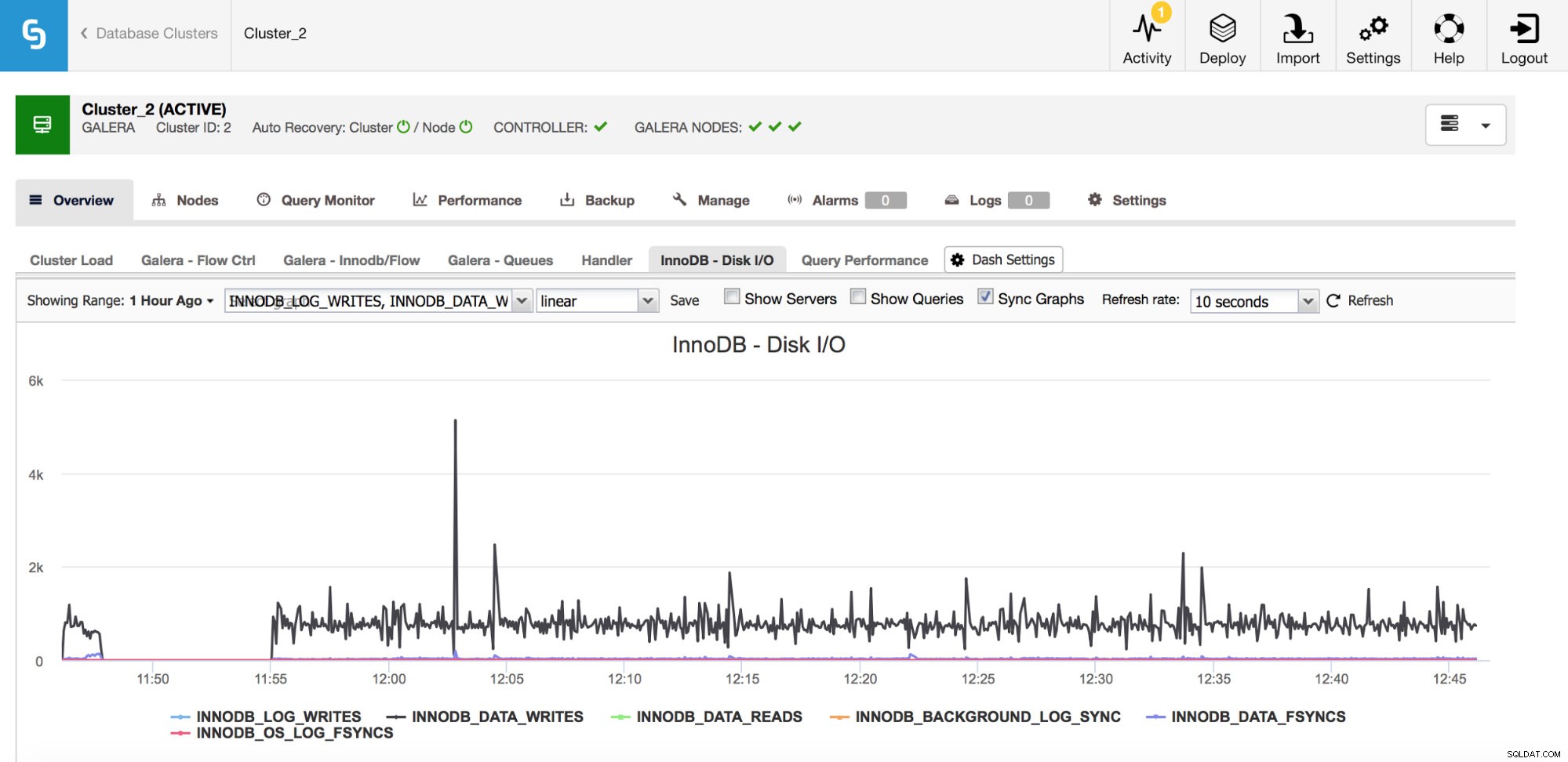
No gráfico acima, você pode ver algumas métricas que informam que tipo de E/S o InnoDB faz - gravações e leituras de dados, gravações de redo log, fsyncs. Essas métricas ajudarão você a decidir, por exemplo, se o atraso de replicação foi causado por um pico de E/S ou talvez por algum outro motivo. Também é importante acompanhar essas métricas e compará-las com suas limitações de hardware - se você estiver chegando perto dos limites de hardware de seus discos, talvez seja hora de analisar isso antes que tenha efeitos mais sérios no desempenho do banco de dados.
Guia de DevOps para gerenciamento de banco de dados de vários novesSaiba mais sobre o que você precisa saber para automatizar e gerenciar seus bancos de dados de código abertoBaixe gratuitamente
Métricas do Galera - Controle de fluxo e filas
Se você usar o Galera Cluster (não importa qual sabor você use), há mais algumas métricas que você deseja monitorar de perto, elas estão um pouco ligadas. A primeira delas são as métricas relacionadas ao controle de fluxo.
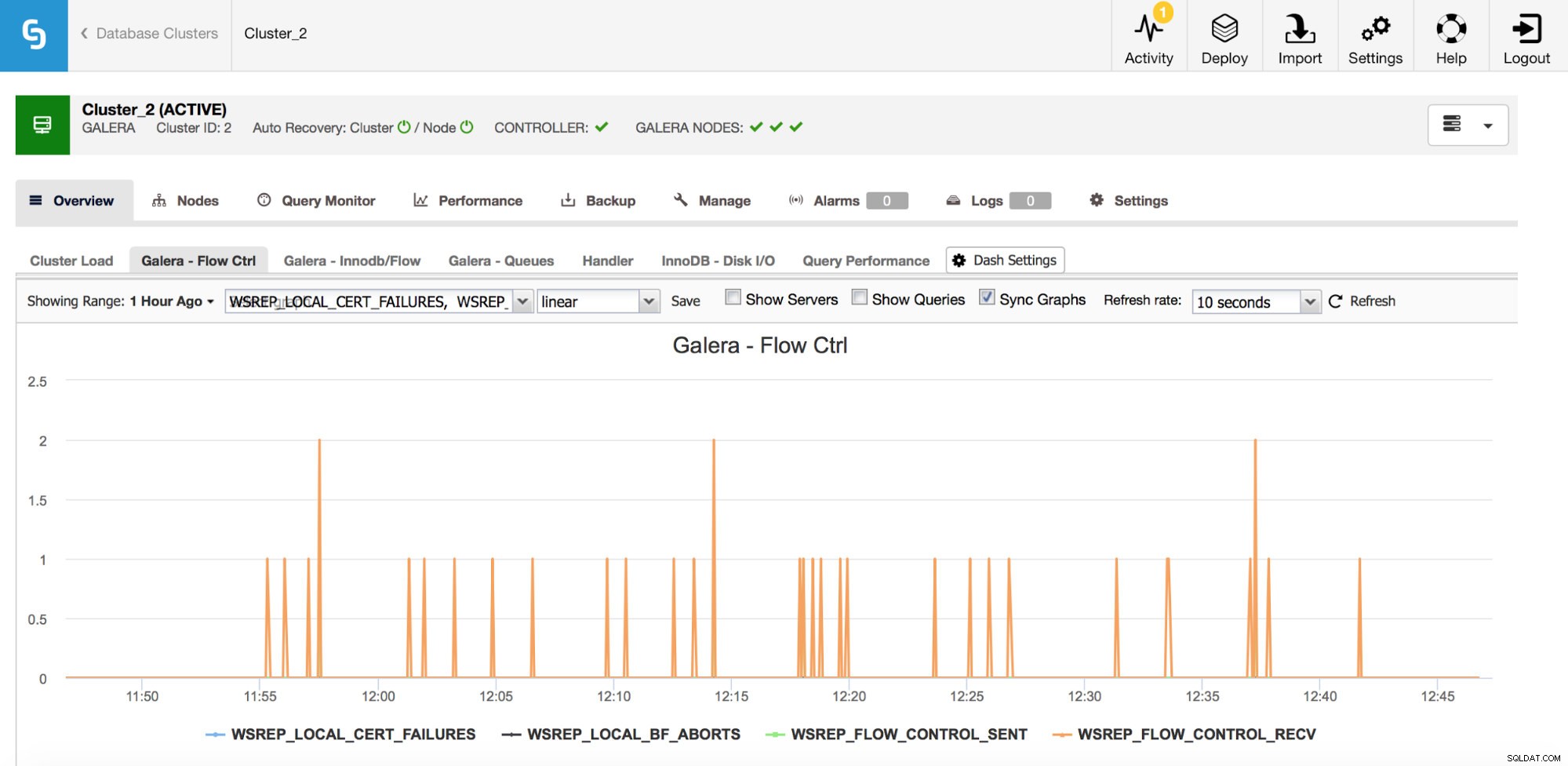
O controle de fluxo, no Galera, é um meio de manter o cluster sincronizado. Sempre que um nó trava e não consegue acompanhar o restante do cluster, ele começa a enviar mensagens de controle de fluxo solicitando que os nós restantes do cluster reduzam a velocidade. Isso permite que ele alcance. Isso reduz o desempenho do cluster, portanto, é importante saber qual nó e quando ele começou a enviar mensagens de controle de fluxo. Isso pode explicar algumas das lentidão experimentadas pelos usuários ou limitar a janela de tempo e o host a serem usados para investigações adicionais.
O segundo conjunto de métricas a serem monitoradas são as relacionadas às filas de envio e recebimento no Galera.
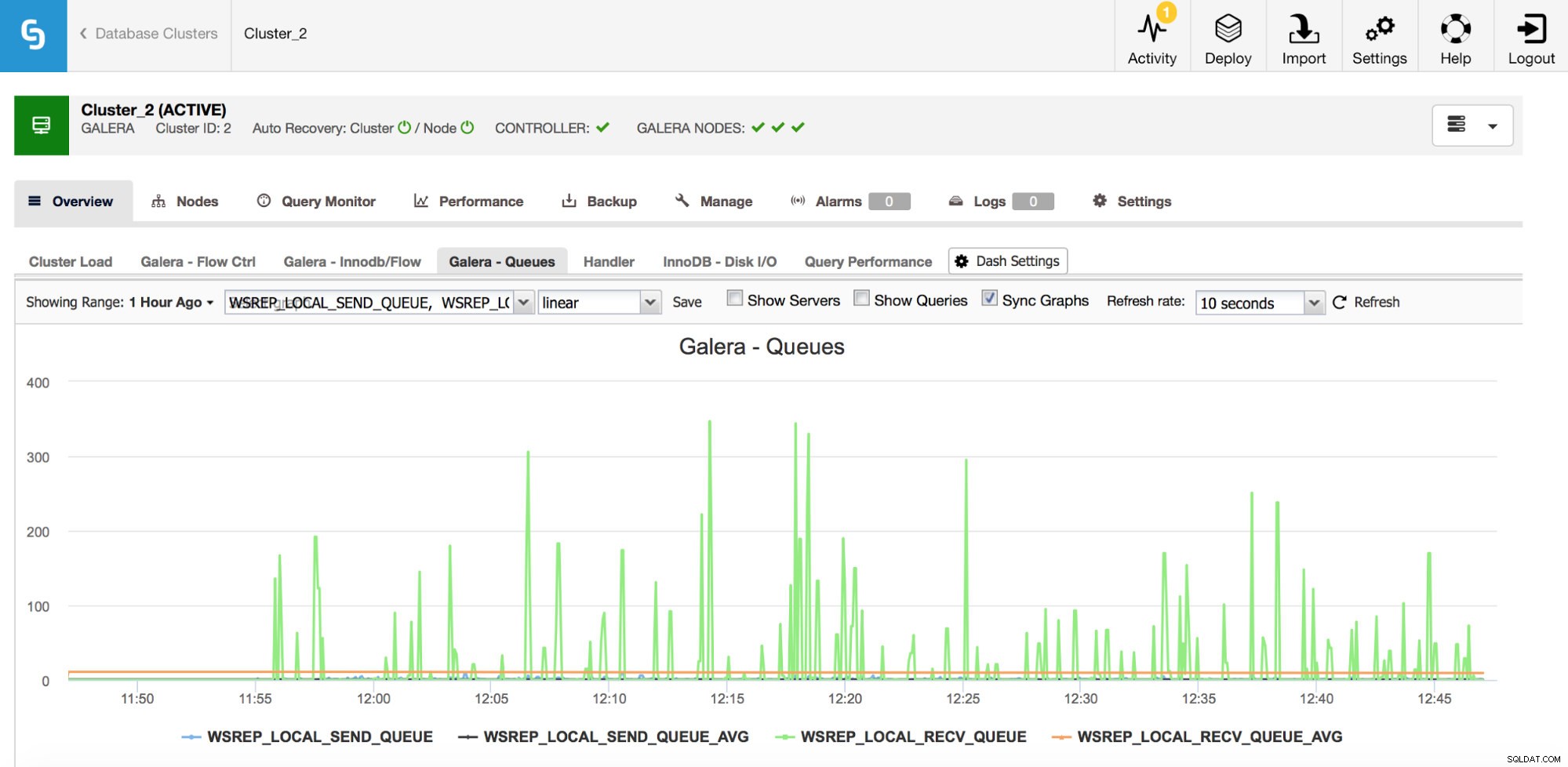
Os nós Galera podem armazenar em cache os conjuntos de gravação (transações) se não puderem aplicar todos eles imediatamente. Se necessário, eles também podem armazenar em cache conjuntos de gravação que estão prestes a ser enviados para outros nós (se um determinado nó receber gravações do aplicativo). Ambos os casos são sintomas de uma lentidão que, muito provavelmente, resultará no envio de mensagens de controle de fluxo e exigirá alguma investigação - por que aconteceu, em qual nó, em que momento?
Isso é, claro, apenas a ponta do iceberg quando consideramos todas as métricas que o MySQL disponibiliza - ainda assim, você não pode errar se começar a assistir aqueles que abordamos aqui, além de métricas regulares de SO/hardware como CPU , memória, utilização do disco e estado dos serviços.



