O banco de dados é uma parte crítica e vital de qualquer negócio ou organização. As tendências crescentes prevêem que 82% das empresas esperam que o número de bancos de dados aumente nos próximos 12 meses. Um grande desafio de todo DBA é descobrir como lidar com o crescimento maciço de dados, e esse será o objetivo mais importante. Como você pode aumentar o desempenho do banco de dados, reduzir custos e eliminar o tempo de inatividade para oferecer aos usuários a melhor experiência possível? A compressão de dados é uma opção? Vamos começar e ver como alguns dos recursos existentes podem ser úteis para lidar com essas situações.
Neste artigo, vamos aprender como a solução de compactação de dados pode nos ajudar a otimizar a solução de gerenciamento de dados. Neste guia, abordaremos os seguintes tópicos:
- Uma visão geral da compactação
- Benefícios da compactação
- Um resumo sobre dados e técnicas de compactação
- Discussão de vários tipos de compactação de dados
- Fatos sobre compactação de dados
- Considerações de implementação
- e mais…
Compressão
A compactação é uma técnica e, portanto, uma operação sensível a recursos, mas com compensações de hardware. Deve-se pensar em implantar a compactação de dados para os seguintes benefícios:
- Gerenciamento de espaço eficaz
- Técnica eficiente de redução de custos
- Facilidade de gerenciamento de backup de banco de dados
- Utilização efetiva da largura de banda N/W
- Recuperação ou restauração segura e mais rápida
- Melhor desempenho – reduz o consumo de memória do sistema
Observação: Se o SQL Server tiver restrição de CPU ou memória, a compactação poderá não ser adequada ao seu ambiente.
A compactação de dados se aplica a:
- Montes
- Índices agrupados
- Índices não agrupados
- Partições
- Visualizações indexadas
Observação: Objetos grandes não são compactados (por exemplo, LOB e BLOB)
Mais adequado para as seguintes aplicações:
- Tabelas de registro
- Tabelas de auditoria
- Tabelas de fatos
- Relatórios
Introdução
A compactação de dados é uma tecnologia que existe desde o SQL Server 2008. A ideia da compactação de dados é que você pode escolher seletivamente tabelas, índices ou partições em um banco de dados. A E/S continua sendo um gargalo na movimentação de informações entre a entrada e a saída do banco de dados. A compactação de dados aproveita esse tipo e ajuda a aumentar a eficiência de um banco de dados. Como sabemos que as velocidades de rede são muito mais lentas que a velocidade de processamento, é possível obter ganhos de eficiência usando o poder de processamento para compactar dados em um banco de dados, para que ele trafegue mais rápido. E, em seguida, use o poder de processamento novamente, para descompactar os dados na outra extremidade. Em geral, a compactação de dados reduz o espaço ocupado pelos dados. A técnica de compactação de dados está disponível para todos os bancos de dados e é suportada por todas as edições do SQL Server 2016 SP1. Antes disso, ele estava disponível apenas nas edições SQL Server Enterprise ou Developer, não no Standard ou Express.
Suporte a recursos

Tipos de compactação de dados
Há dois tipos de compactação de dados disponíveis no SQL Server, nível de linha e nível de página.
A compactação em nível de linha funciona nos bastidores e converte quaisquer tipos de dados de comprimento fixo em tipos de comprimento variável. A suposição aqui é que muitas vezes os dados são armazenados em um tipo de comprimento fixo, como char 100, e eles não preenchem os 100 caracteres inteiros para cada registro. Pequenos ganhos podem ser alcançados removendo esse espaço extra da mesa. Claro, se suas tabelas de dados não usarem texto de comprimento fixo e campos numéricos, ou se o fizerem e você realmente armazenar o número totalmente permitido de caracteres e dígitos, os ganhos de compactação no esquema em nível de linha serão mínimos no melhor.
O conceito de compactação é estendido a todos os tipos de dados de comprimento fixo, incluindo char, int e float. O SQL Server permite economizar espaço armazenando os dados como se fosse um tipo de tamanho variável; os dados aparecerão e se comportarão como um comprimento fixo.
Por exemplo, se você armazenou o valor de 100 em um int coluna, o SQL Server não precisa usar todos os 32 bits, em vez disso, ele simplesmente usa 8 bits (1 byte).
A compactação no nível da página leva as coisas para outro nível. Primeiro, ele aplica automaticamente a compactação em nível de linha em campos de dados de comprimento fixo, para que você obtenha automaticamente esses ganhos por padrão. Então, em cima disso, ele aplica algo chamado compressão de prefixo e outra técnica chamada compressão de dicionário.
Compressão de linha
A compactação de linha é um nível interno de compactação que armazena as cadeias de caracteres fixas usando o formato de comprimento variável, não armazenando os caracteres em branco. As etapas a seguir são executadas na compactação em nível de linha.
- Todos os tipos de dados numéricos, como int , flutuar , decimal, e dinheiro são convertidos em tipos de dados de comprimento variável. Por exemplo, 125 armazenados na coluna e o tipo de dados da coluna é um número inteiro. Então sabemos que 4 bytes são usados para armazenar o valor inteiro. Mas 125 pode ser armazenado em 1 byte porque 1 byte pode armazenar valores de 0 a 255. Portanto, 125 pode ser armazenado como um pequeno int , de modo que 3 bytes possam ser salvos.
- Caracter e Nchar tipos de dados são armazenados como tipos de dados de comprimento variável. Por exemplo, “SQL” é armazenado em um char (20) coluna tipo. Mas após a compactação, apenas 3 bytes serão usados. Após a compactação de dados, nenhum caractere em branco é armazenado com esse tipo de dados.
- Os metadados do registro são reduzidos.
- Os valores NULL e 0 são otimizados e nenhum espaço é consumido.
Compressão de página
A compactação de página é um nível avançado de compactação de dados. Por padrão, uma compactação de página também implementa a compactação em nível de linha. A compactação de página é categorizada em dois tipos
- Compressão de prefixo e
- Compressão de dicionário.
Compressão de prefixo
Na compactação de prefixo para cada página, para cada coluna da página, um valor comum é recuperado de todas as linhas e armazenado abaixo do cabeçalho em cada coluna. Agora, em cada linha, uma referência a esse valor é armazenada em vez do valor comum.
Compressão de dicionário
A compactação de dicionário é semelhante à compactação de prefixo, mas os valores comuns são recuperados de todas as colunas e armazenados na segunda linha após o cabeçalho. A compactação de dicionário procura correspondências de valor exatas em todas as colunas e linhas de cada página.
Podemos executar compactação em nível de linha e página para os seguintes objetos de banco de dados.
- Uma tabela armazenada em um heap.
- Uma tabela inteira armazenada como um índice clusterizado.
- Visualização indexada.
- Índice não agrupado.
- Índices e tabelas particionados.
Observação: Podemos realizar a compactação de dados no momento da criação como CREATE TABLE, CREATE INDEX ou após a criação usando o comando ALTER com a opção REBUILD como ALTER TABLE …. RECONSTRUIR COM.
Demonstração
Os WideWorldImporters banco de dados é usado durante toda a demonstração. Além disso, um DW em tempo real banco de dados é considerado para a operação de compactação.
Vamos detalhar as etapas:
1. Para visualizar as configurações de compactação de objetos no banco de dados, execute o seguinte T-SQL:
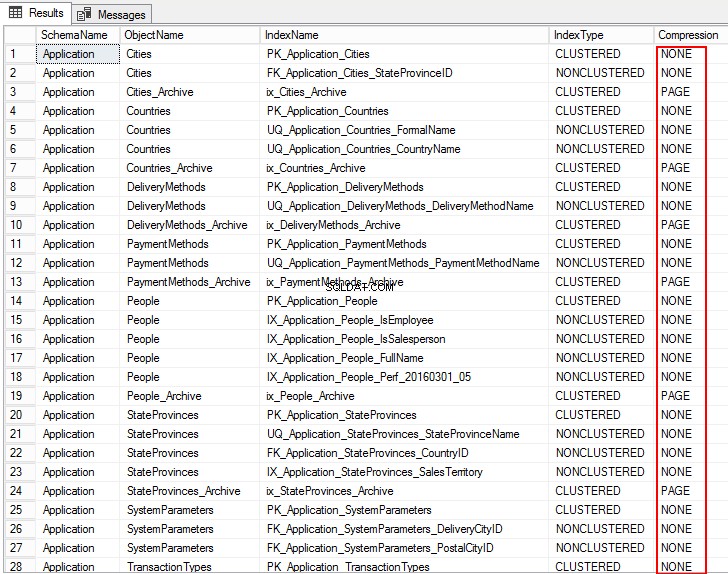
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' ORDER BY S.name, O.name, I.index_id; GO
A saída a seguir mostra o tipo de compactação como PAGE, ROW e, para várias tabelas, é NONE. Isso significa que ele não está configurado para compactação.
2. Para estimar a compactação, execute o seguinte procedimento armazenado do sistema sp_estimate_data_compression_savings . Nesse caso, o procedimento armazenado é executado nas tabelas PurchaseOrderLines.
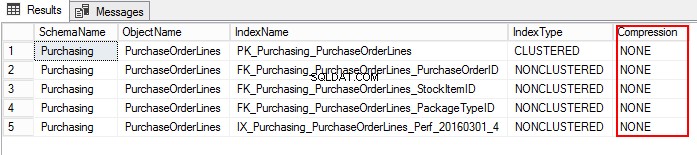
3. Vamos descobrir a configuração de compactação PurchaseOrderLines executando o seguinte T-SQL:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' and o.name ='PurchaseOrderLines' ORDER BY S.name, O.name, I.index_id;
EXEC sp_estimate_data_compression_savings @schema_name = 'Purchasing', @object_name = 'PurchaseOrderLines', @index_id = NULL, @partition_number = NULL, @data_compression = 'Page'; GO

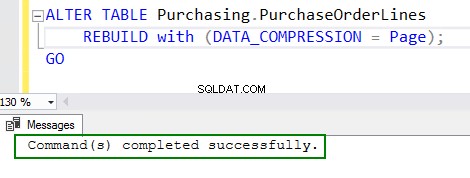
4. Habilite a compactação executando o comando ALTER table:
ALTER TABLE Purchasing.PurchaseOrderLines REBUILD with (DATA_COMPRESSION = Page); GO
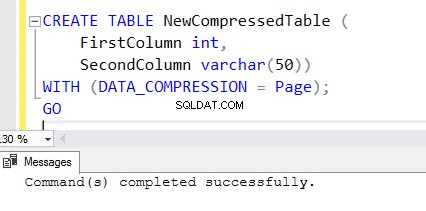
5. Para criar uma nova tabela com o recurso habilitado para compactação, inclua a cláusula WITH no final da instrução CREATE TABLE. Você pode ver a instrução CREATE TABLE abaixo usada para criar NewCompressedTable .
CREATE TABLE NewCompressedTable (
FirstColumn int,
SecondColumn varchar(50))
WITH (DATA_COMPRESSION = Page);
GO
Fatos sobre compactação de dados
Vamos percorrer algumas das informações reais sobre compressão
- A compactação não pode ser aplicada a tabelas do sistema
- Uma tabela não pode ser habilitada para compactação quando o tamanho da linha excede 8.060 bytes.
- Os dados compactados são armazenados em cache no buffer pool; significa tempos de resposta mais rápidos
- Ativar a compactação pode fazer com que os planos de consulta sejam alterados porque os dados são armazenados usando um número diferente de páginas e número de linhas por página.
- Índices não agrupados não herdam a propriedade de compactação
- Quando um índice clusterizado é criado em um heap, o índice clusterizado herda o estado de compactação do heap, a menos que um estado de compactação alternativo seja especificado.
- As compactações de nível ROW e PAGE podem ser ativadas e desativadas, offline ou online.
- Se a configuração de heap for alterada, todos os índices não clusterizados deverão ser reconstruídos.
- Os requisitos de espaço em disco para ativar ou desativar a compactação de linha ou página são os mesmos para criar ou reconstruir um índice.
- Quando as partições são divididas usando a instrução ALTER PARTITION, ambas as partições herdam o atributo de compactação de dados da partição original.
- Quando duas partições são mescladas, a partição resultante herda o atributo de compactação de dados da partição de destino.
- Para alternar uma partição, a propriedade de compactação de dados da partição deve corresponder à propriedade de compactação da tabela.
- Tabelas e índices columnstore são sempre armazenados com a compactação Columnstore.
- A compactação de dados é incompatível com colunas esparsas, portanto, a tabela não pode ser compactada.
Cenário em tempo real
Vamos percorrer a técnica de compactação de dados e entender os principais parâmetros de compactação de dados.
Para verificar o espaço usado por cada tabela, execute o seguinte T-SQL. A saída da consulta nos fornece informações detalhadas sobre o uso de cada tabela. Este seria o fator decisivo para a implementação da compressão de dados.
SELECT
t.NAME AS TableName,
i.name as indexName,
sum(p.rows) as RowCounts,
sum(a.total_pages) as TotalPages,
sum(a.used_pages) as UsedPages,
sum(a.data_pages) as DataPages,
(sum(a.total_pages) * 8) / 1024 as TotalSpaceMB,
(sum(a.used_pages) * 8) / 1024 as UsedSpaceMB,
(sum(a.data_pages) * 8) / 1024 as DataSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
WHERE
t.NAME NOT LIKE 'dt%' AND
i.OBJECT_ID > 255 AND
i.index_id <= 1
GROUP BY
t.NAME, i.object_id, i.index_id, i.name
ORDER BY
TotalSpaceMB desc
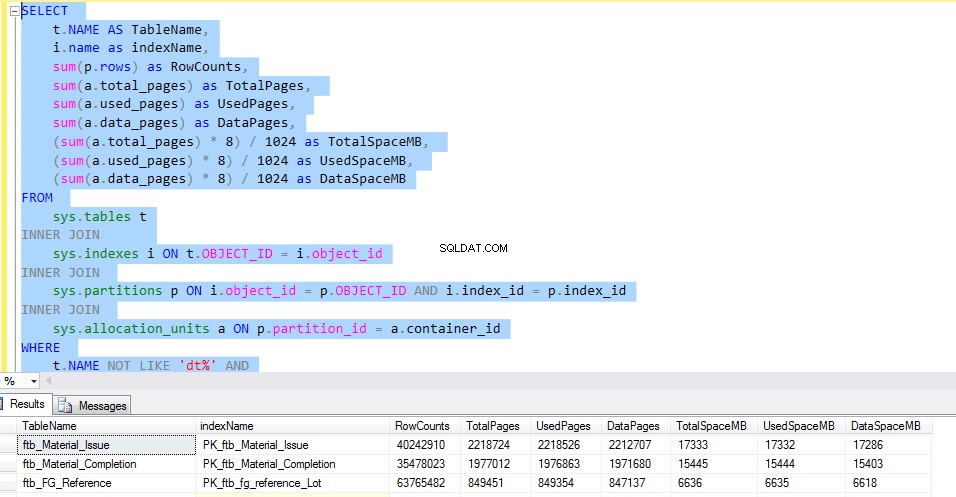
Vamos considerar o ftb_material_Issue tabela de fatos. A tabela de fatos tem tipos de dados numéricos BIGINT.
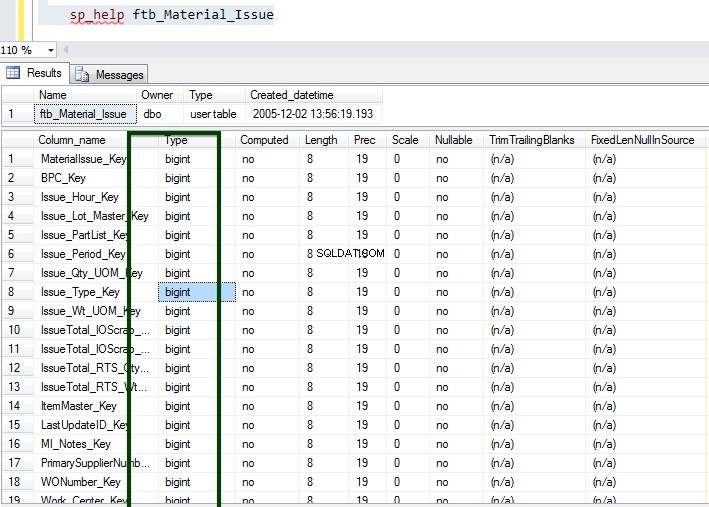
Agora, execute o procedimento armazenado sp_spaceused para entender os detalhes da tabela. Você pode aprender mais sobre o comando sp_spaceused aqui.
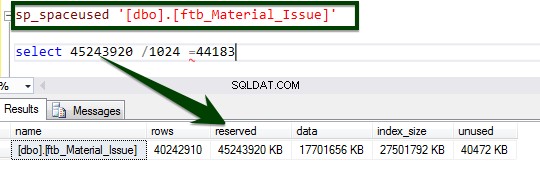
Habilite a compactação em nível de tabela executando o seguinte T-SQL. O seguinte T-SQL foi executado no servidor e levou 34 minutos e 14 segundos para compactar a página no nível da tabela.
ALTER TABLE dbo.ftb_material_Issue REBUILD with (DATA_COMPRESSION = Page);
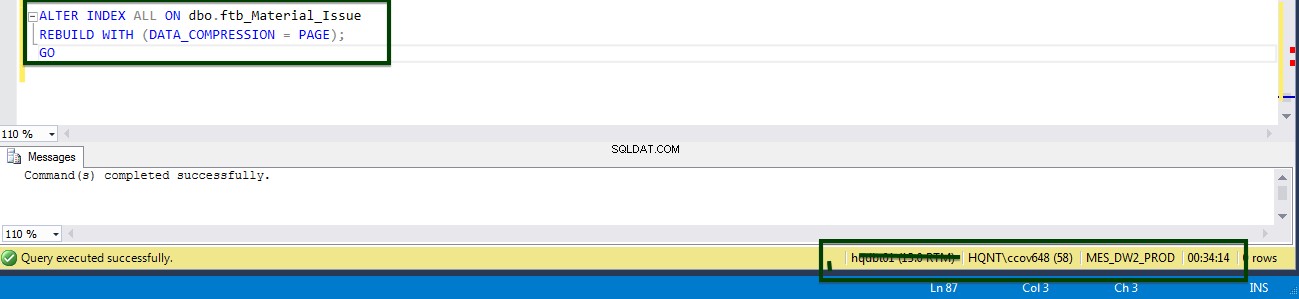
Você pode ver as flutuações de CPU e E/S durante a execução do comando ALTER table.
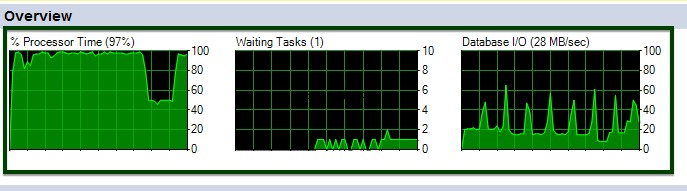
Agora, vamos fazer a comparação de compactação de dados Antes v/s Depois. O tamanho da tabela de aproximadamente 45 GB é reduzido para aproximadamente 15 GB.
O processo é implementado na maioria dos objetos usando um script automatizado e aqui está o resultado final da comparação.
Comparação de dados entre Antes e Depois da operação de compactação de índice.

Resumo
A compactação de dados é uma técnica muito eficaz para reduzir o tamanho dos dados; dados reduzidos requerem menos processos de E/S. Adicionar compactação ao banco de dados aumenta a carga nos requisitos da CPU. Você precisará garantir que tenha a capacidade de processamento disponível para acomodar essas alterações de maneira eficiente. Portanto, é melhor fazer uma pequena pesquisa primeiro e ver os tipos de ganhos que podem ser esperados antes de aplicar as modificações para habilitar a compactação de dados. É muito benéfico na configuração do banco de dados em nuvem, onde o custo está envolvido.
Organize as compressões (não faça todas de uma vez) e comprima durante períodos de baixa atividade. A compactação de dados e a compactação de backup coexistem perfeitamente e podem resultar em economia adicional de espaço de armazenamento, então vá em frente e aproveite.
A compactação não apenas reduz o tamanho dos arquivos físicos, mas também reduz a E/S de disco, o que pode melhorar muito o desempenho de muitos aplicativos de banco de dados, juntamente com backups de banco de dados.
A decisão de implementar a compactação é mais fácil se conhecermos a infraestrutura subjacente e os requisitos de negócios. Definitivamente, podemos usar o procedimento do sistema disponível para entender e estimar a economia de compactação. Este procedimento armazenado não fornece tais detalhes que informam como a compactação afetará positiva ou negativamente seu sistema. É evidente que existem compensações para qualquer tipo de compressão. Se você tiver os mesmos padrões de dados enormes, a compactação é a chave para economizar espaço. Com o aumento da potência da CPU e cada sistema vinculado a estruturas de vários núcleos, a compactação pode ser adequada para muitos sistemas. Eu recomendaria testar seus sistemas. Teste para garantir que o desempenho não seja afetado negativamente. Se um índice tiver muitas atualizações e exclusões, o custo da CPU para compactar e descompactar os dados pode superar as economias de E/S e RAM da compactação de dados. Nem todo banco de dados ou tabela será automaticamente um bom candidato para aplicar compactação, portanto, é melhor fazer uma pequena pesquisa primeiro para ver os tipos de ganhos que podem ser esperados antes de aplicar as modificações para habilitar a compactação de dados em seus bancos de dados. Você precisa testar a compactação para ver se ela funciona bem em seu ambiente, pois pode não funcionar bem em bancos de dados de inserção pesada.
Referências
Edições e recursos com suporte do SQL Server 2016
Compressão de dados
Implementação de compactação de linha
Implementação de compactação de página