Nesta postagem, discutiremos o mecanismo de bloqueio do SQL Server e como monitorar o bloqueio do SQL Server com exibições de gerenciamento dinâmico padrão do SQL Server. Antes de começarmos a explicar a arquitetura de bloqueio do SQL Server, vamos dedicar um momento para descrever o que é o banco de dados ACID (Atomicity, Consistency, Isolation and Durability). O banco de dados ACID pode ser explicado como teoria do banco de dados. Se um banco de dados é chamado de banco de dados relacional, ele deve atender aos requisitos de Atomicidade, Consistência, Isolamento e Durabilidade. Agora, vamos explicar esses requisitos brevemente.
Atomicidade :Reflete o princípio da indivisibilidade que descrevemos como a principal característica do processo de transação. Um bloco de transação não pode ser deixado sem supervisão. Metade do bloco de transação restante causa inconsistência de dados. Ou toda a transação é executada ou a transação retorna ao início. Ou seja, todas as alterações feitas pela transação são desfeitas e retornam ao seu estado anterior.
Consistência :Existe uma regra que define a subestrutura da regra de não divisibilidade. Os dados de transação devem fornecer consistência. Ou seja, se a operação de atualização for realizada em uma transação, todas as transações restantes devem ser executadas ou a operação de atualização deve ser cancelada. Esses dados são muito importantes em termos de consistência.
Isolamento :Este é um pacote de solicitação para cada banco de dados de transações. As alterações feitas por um pacote de solicitação devem ser visíveis para outra transação antes de serem concluídas. Cada transação deve ser processada separadamente. Todas as transações devem ser visíveis para outra transação após ocorrerem.
Durabilidade: As transações podem realizar operações complexas com dados. Para proteger todas essas transações, elas devem ser resistentes a um erro de transação. Os problemas de sistema que podem ocorrer no SQL Server devem ser preparados e resilientes contra falhas de energia, sistema operacional ou outros erros induzidos por software.
Transação: A transação é a menor pilha do processo que não pode ser dividida em partes menores. Além disso, alguns grupos de processos de transação podem ser executados sequencialmente, mas, como explicamos no princípio da Atomicidade, se mesmo uma das transações falhar, todos os blocos de transação falharão.
Bloquear: O bloqueio é um mecanismo para garantir a consistência dos dados. O SQL Server bloqueia objetos quando a transação é iniciada. Quando a transação é concluída, o SQL Server libera o objeto bloqueado. Esse modo de bloqueio pode ser alterado de acordo com o tipo de processo do SQL Server e o nível de isolamento. Esses modos de bloqueio são:
Hierarquia de bloqueio: O SQL Server tem uma hierarquia de bloqueio que adquire objetos de bloqueio nessa hierarquia. Um banco de dados está localizado na parte superior da hierarquia e a linha está localizada na parte inferior. A imagem abaixo ilustra a hierarquia de bloqueio do SQL Server.

Bloqueios compartilhados (S): Este tipo de bloqueio ocorre quando o objeto precisa ser lido. Este tipo de bloqueio não causa muito problema.
Bloqueios Exclusivos (X): Quando esse tipo de bloqueio ocorre, ocorre para evitar que outras transações modifiquem ou acessem um objeto bloqueado.
Atualizar (U) bloqueios: Este tipo de bloqueio é semelhante ao bloqueio exclusivo, mas apresenta algumas diferenças. Podemos dividir a operação de atualização em diferentes fases:fase de leitura e fase de gravação. Durante a fase de leitura, o SQL Server não deseja que outras transações tenham acesso a esse objeto para serem alteradas. Por esse motivo, o SQL Server usa o bloqueio de atualização.
Bloqueios de intenção: O bloqueio de intenção ocorre quando o SQL Server deseja adquirir o bloqueio compartilhado (S) ou o bloqueio exclusivo (X) em alguns dos recursos inferiores na hierarquia de bloqueio. Na prática, quando o SQL Server adquire um bloqueio em uma página ou linha, o bloqueio de intenção é necessário na tabela.
Depois de todas essas breves explicações, tentaremos encontrar uma resposta de como identificar bloqueios. O SQL Server oferece muitas exibições de gerenciamento dinâmico para acessar as métricas. Para identificar bloqueios do SQL Server, podemos usar o sys.dm_tran_locks visualizar. Nesta visualização, podemos encontrar muitas informações sobre os recursos do gerenciador de bloqueios ativos no momento.
No primeiro exemplo, criaremos uma tabela de demonstração que não inclui nenhum índice e tentaremos atualizar essa tabela de demonstração.
CREATE TABLE TestBlock (Id INT , Nm VARCHAR(100)) INSERT INTO TestBlock values(1,'CodingSight') In this step, we will create an open transaction and analyze the locked resources. BEGIN TRAN UPDATE TestBlock SET Nm='NewValue_CodingSight' where Id=1 select @@SPID
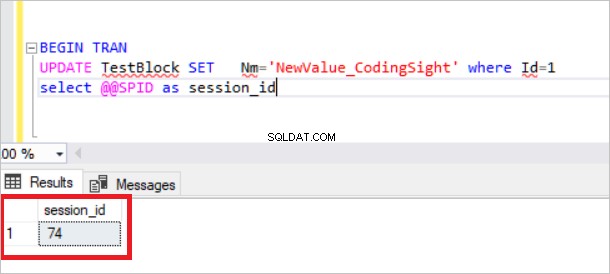
Agora, vamos verificar a visualização sys.dm_tran_lock.
select * from sys.dm_tran_locks WHERE request_session_id=74
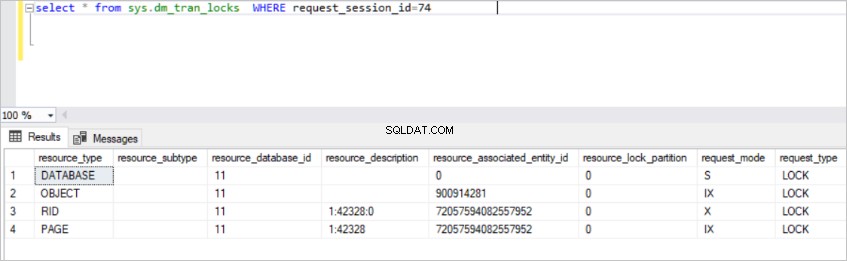
Essa exibição retorna muitas informações sobre recursos de bloqueio ativo. Mas não é possível entender alguns dos dados nesta visão. Por esse motivo, temos que aderir ao sys.dm_tran_locks vista para outras vistas.
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()
and request_session_id=74
ORDER BY request_session_id, resource_associated_entity_id
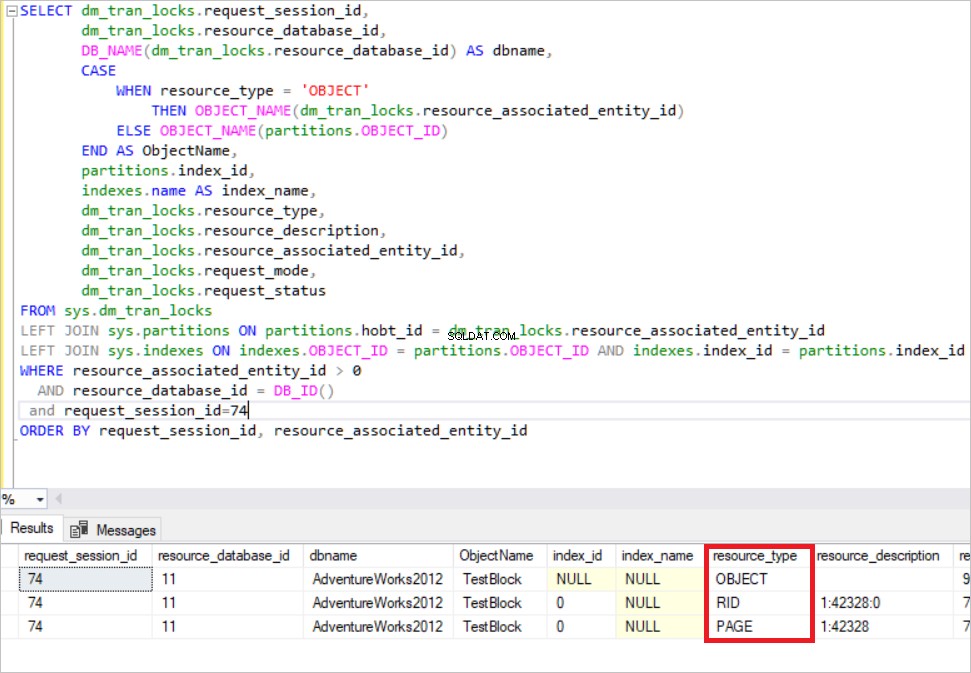
Na imagem acima, você pode ver os recursos bloqueados. O SQL Server adquire o bloqueio exclusivo nessa linha. (RI :um identificador de linha usado para bloquear uma única linha em um heap) Ao mesmo tempo, o SQL Server adquire o bloqueio exclusivo de intenção na página e o TestBlock tabela. Isso significa que qualquer outro processo não pode ler esse recurso até que o SQL Server libere os bloqueios. Este é o mecanismo de bloqueio básico no SQL Server.
Agora, preencheremos alguns dados sintéticos em nossa tabela de teste.
TRUNCATE TABLE TestBlock DECLARE @K AS INT=0 WHILE @K <8000 BEGIN INSERT TestBlock VALUES(@K, CAST(@K AS varchar(10)) + ' Value' ) SET @example@sqldat.com+1 END After completing this step, we will run two queries and check the sys.dm_tran_locks view. BEGIN TRAN UPDATE TestBlock set Nm ='New_Value' where Id<5000
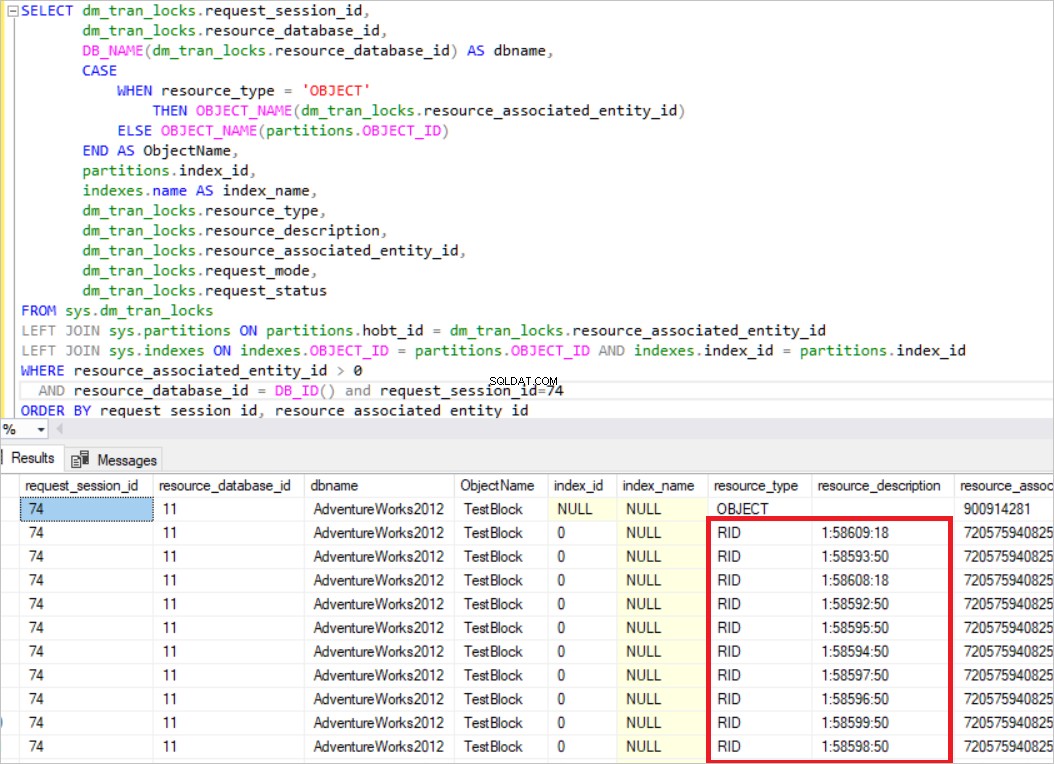
Na consulta acima, o SQL Server adquire o bloqueio exclusivo em cada linha. Agora, vamos executar outra consulta.
BEGIN TRAN UPDATE TestBlock set Nm ='New_Value' where Id<7000
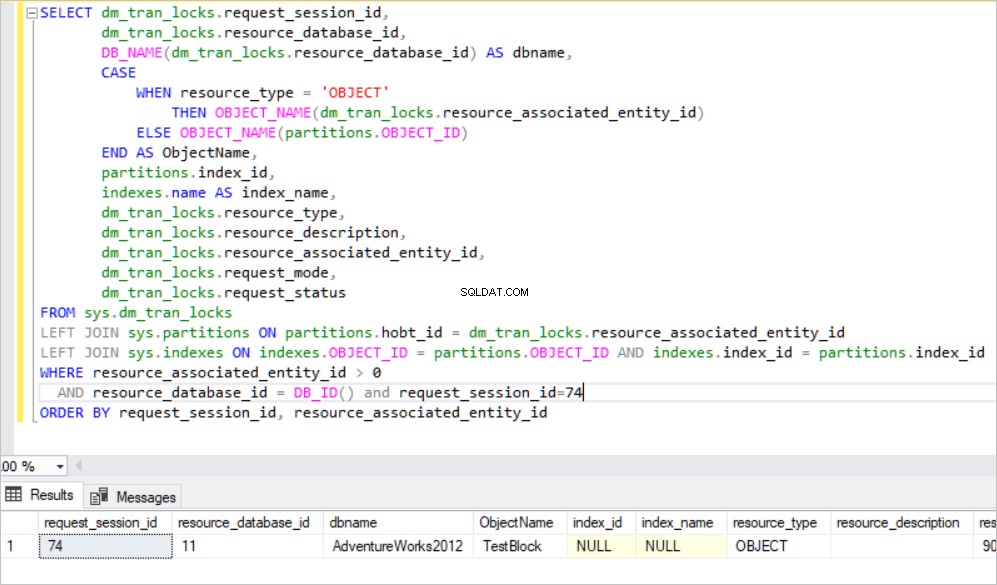
Na consulta acima, o SQL Server cria o bloqueio exclusivo na tabela, pois o SQL Server tenta adquirir muitos bloqueios RID para essas linhas que serão atualizadas. Esse caso causa muito consumo de recursos no mecanismo de banco de dados. Portanto, o SQL Server move automaticamente esse bloqueio exclusivo para um objeto de nível superior que está na hierarquia de bloqueio. Definimos esse mecanismo como Lock Escalation. O escalonamento de bloqueio pode ser alterado no nível da tabela.
ALTER TABLE XX_TableName SET ( LOCK_ESCALATION = AUTO -- or TABLE or DISABLE ) GO
Gostaria de adicionar algumas notas sobre o escalonamento de bloqueio. Se você tiver uma tabela particionada, podemos definir a escalação para o nível de partição.
Nesta etapa, executaremos uma consulta que cria um bloqueio na tabela AdventureWorks HumanResources. Esta tabela tem índices clusterizados e não clusterizados.
BEGIN TRAN UPDATE [HumanResources].[Department] SET Name='NewName' where DepartmentID=1
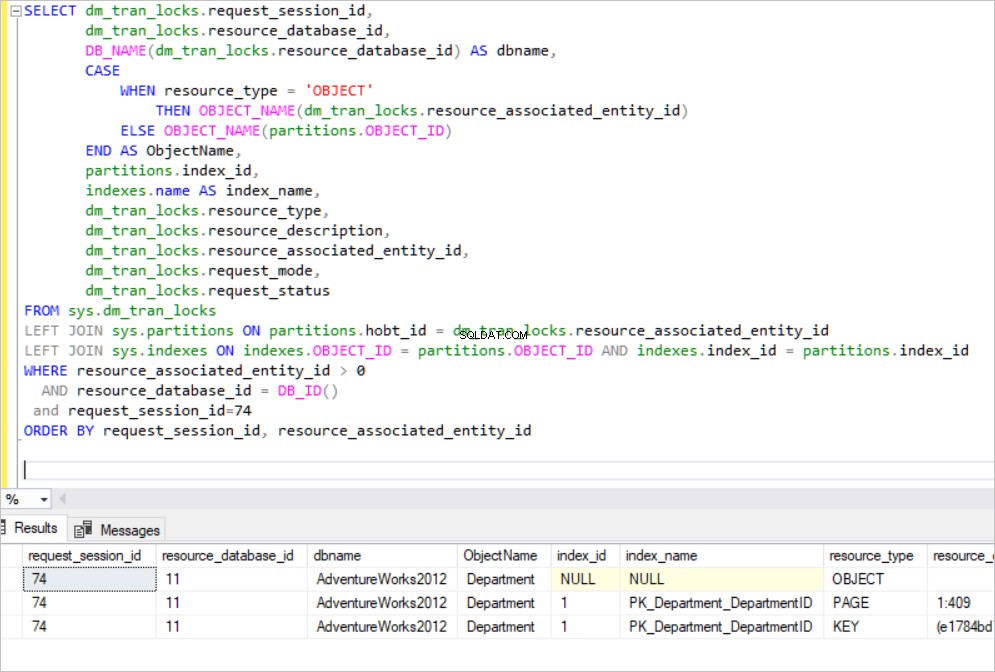
Como você pode ver no painel de resultados abaixo, nossa transação adquire bloqueios exclusivos na chave de índice de cluster PK_Department_DepartmentID e também adquire bloqueios exclusivos na chave de índice não clusterizado AK_Department_Name. Agora, podemos fazer esta pergunta “Por que o SQL Server bloqueia um índice não clusterizado?”
O Nome coluna está indexada no índice não clusterizado AK_Department_Name e tentamos alterar o Nome coluna. Nesse caso, o SQL Server precisa alterar quaisquer índices não clusterizados nessa coluna. O nível folha de índice não clusterizado inclui cada valor KEY classificado.
Conclusões
Neste artigo, mencionamos as principais linhas do mecanismo de bloqueio do SQL Server e consideramos o uso de sys.dm_tran_locks. A exibição sys.dm_tran_locks retorna muitas informações sobre os recursos de bloqueio atualmente ativos. Se você pesquisar no Google, poderá encontrar muitos exemplos de consultas sobre essa visualização.
Referências
Guia de controle de versão de linha e bloqueio de transações do SQL Server
SQL Server, objeto de bloqueios



