Neste artigo, discutiremos os erros típicos que os desenvolvedores iniciantes podem enfrentar ao projetar o código T-SQL. Além disso, veremos as práticas recomendadas e algumas dicas úteis que podem ajudá-lo ao trabalhar com o SQL Server, bem como soluções alternativas para melhorar o desempenho.
Conteúdo:
1. Tipos de dados
2. *
3. Alias
4. Ordem das colunas
5. NOT IN vs NULL
6. Formato de data
7. Filtro de data
8. Cálculo
9. Converter implícito
10. LIKE &índice suprimido
11. Unicode vs ANSI
12. COLAR
13. COLEÇÃO BINÁRIA
14. Estilo de código
15. [var]car
16. Comprimento dos dados
17. ISNULL vs COALESCE
18. Matemática
19. UNIÃO vs UNIÃO TODOS
20. Releia
21. Subconsulta
22. CASO QUANDO
23. Função escalar
24. VISUALIZAÇÕES
25. CURSORES
26. STRING_CONCAT
27. Injeção SQL
Tipos de dados
O principal problema que enfrentamos ao trabalhar com o SQL Server é uma escolha incorreta de tipos de dados.
Suponha que temos duas tabelas idênticas:
DECLARE @Employees1 TABLE ( EmployeeID BIGINT PRIMARY KEY , IsMale VARCHAR(3) , BirthDate VARCHAR(20))INSERT INTO @Employees1VALUES (123, 'YES', '2012-09-01')DECLARE @Employees2 TABLE ( EmployeeID INT PRIMARY KEY , IsMale BIT , BirthDate DATE)INSERT INTO @Employees2VALUES (123, 1, '2012-09-01')
Vamos executar uma consulta para verificar qual é a diferença:
DECLARE @BirthDate DATE ='2012-09-01'SELECT * FROM @Employees1 WHERE BirthDate =@BirthDateSELECT * FROM @Employees2 WHERE BirthDate =@BirthDate
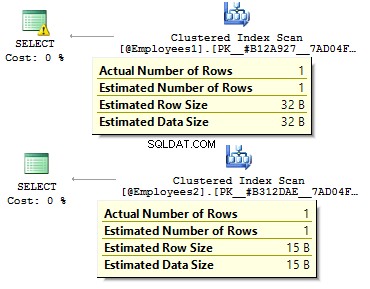
No primeiro caso, os tipos de dados são mais redundantes do que poderiam ser. Por que devemos armazenar um valor de bit como YES/NO fileira? Por que devemos armazenar uma data como uma linha? Por que devemos usar BIGINT para funcionários na tabela, em vez de INT ?
Isso leva às seguintes desvantagens:
- As tabelas podem ocupar muito espaço no disco;
- Precisamos ler mais páginas e colocar mais dados no BufferPool para lidar com dados.
- Desempenho ruim.
*
Eu enfrentei a situação quando os desenvolvedores recuperam todos os dados de uma tabela e, no lado do cliente, usam DataReader para selecionar apenas os campos obrigatórios. Eu não recomendo usar esta abordagem:
USE AdventureWorks2014GOSET STATISTICS TIME, IO ONSELECT *FROM Person.PersonSELECT BusinessEntityID , FirstName , MiddleName , LastNameFROM Person.PersonSET STATISTICS TIME, IO OFF
Haverá uma diferença significativa no tempo de execução da consulta. Além disso, o índice de cobertura pode reduzir um número de leituras lógicas.
Tabela 'Pessoa'. Contagem de varredura 1, leituras lógicas 3819, leituras físicas 3, ... Tempos de execução do SQL Server:Tempo de CPU =31 ms, tempo decorrido =1235 ms.Tabela 'Pessoa'. Contagem de varredura 1, leituras lógicas 109, leituras físicas 1, ... Tempos de execução do SQL Server:tempo de CPU =0 ms, tempo decorrido =227 ms.
Alias
Vamos criar uma tabela:
USE AdventureWorks2014GOIF OBJECT_ID('Sales.UserCurrency') NÃO É NULO DROP TABLE Sales.UserCurrencyGOCREATE TABLE Sales.UserCurrency ( CurrencyCode NCHAR(3) PRIMARY KEY)INSERT INTO Sales.UserCurrencyVALUES ('USD') Suponha que temos uma consulta que retorna a quantidade de linhas idênticas em ambas as tabelas:
SELECT COUNT_BIG(*)FROM Sales.CurrencyWHERE CurrencyCode IN ( SELECT CurrencyCode FROM Sales.UserCurrency )
Tudo estará funcionando conforme o esperado, até que alguém renomeie uma coluna no Sales.UserCurrency tabela:
EXEC sys.sp_rename 'Sales.UserCurrency.CurrencyCode', 'Code', 'COLUMN'
Em seguida, executaremos uma consulta e veremos que obtemos todas as linhas no Sales.Currency tabela, em vez de 1 linha. Ao construir um plano de execução, no estágio de vinculação, o SQL Server verificaria as colunas de Sales.UserCurrency, ele não encontrará CurrencyCode lá e decide que esta coluna pertence ao Sales.Currency tabela. Depois disso, um otimizador descartará o CurrencyCode =CurrencyCode doença.
Assim, recomendo usar aliases:
SELECT COUNT_BIG(*)FROM Sales.Currency cWHERE c.CurrencyCode IN ( SELECT u.CurrencyCode FROM Sales.UserCurrency u)
Ordem das colunas
Suponha que temos uma tabela:
IF OBJECT_ID('dbo.DatePeriod') NÃO É NULO DROP TABLE dbo.DatePeriodGOCREATE TABLE dbo.DatePeriod ( StartDate DATE , EndDate DATE) Sempre inserimos dados lá com base nas informações sobre a ordem das colunas.
INSERT INTO dbo.DatePeriodSELECT '2015-01-01', '2015-01-31'
Suponha que alguém altere a ordem das colunas:
CREATE TABLE dbo.DatePeriod ( EndDate DATE , StartDate DATE)
Os dados serão inseridos em uma ordem diferente. Nesse caso, é uma boa ideia especificar colunas explicitamente na instrução INSERT:
INSERT INTO dbo.DatePeriod (StartDate, EndDate)SELECT '2015-01-01', '2015-01-31'
Aqui está outro exemplo:
SELECT TOP(1) *FROM dbo.DatePeriodORDER BY 2 DESC
Em que coluna vamos ordenar os dados? Dependerá da ordem das colunas em uma tabela. Caso alguém mude a ordem, obtemos resultados errados.
NOT IN vs NULL
Vamos falar sobre o NOT IN demonstração.
Por exemplo, você precisa escrever algumas consultas:retornar os registros da primeira tabela, que não existem na segunda tabela e vice-versa. Normalmente, desenvolvedores juniores usam IN e NÃO DENTRO :
DECLARE @t1 TABLE (t1 INT, UNIQUE CLUSTERED(t1))INSERT INTO @t1 VALUES (1), (2)DECLARE @t2 TABLE (t2 INT, UNIQUE CLUSTERED(t2))INSERT INTO @t2 VALUES (1) )SELECT *FROM @t1WHERE t1 NOT IN (SELECT t2 FROM @t2)SELECT *FROM @t1WHERE t1 IN (SELECT t2 FROM @t2)
A primeira consulta retornou 2, a segunda – 1. Além disso, adicionaremos outro valor na segunda tabela – NULL :
INSERIR VALORES @t2 (1), (NULL)
Ao executar a consulta com NOT IN , não obteremos nenhum resultado. Por que IN funciona e NOT In não? A razão é que o SQL Server usa TRUE , FALSO , e DESCONHECIDO lógica ao comparar dados.
Ao executar uma consulta, o SQL Server interpreta a condição IN da seguinte maneira:
a IN (1, NULL) ==a=1 OR a=NULL
NÃO ESTÁ :
a NOT IN (1, NULL) ==a<>1 AND a<>NULL
Ao comparar qualquer valor com NULL, SQL Server retorna DESCONHECIDO. Ou 1=NULL ou NULL=NULL – ambos resultam em DESCONHECIDO. Na medida em que temos AND na expressão, ambos os lados retornam UNKNOWN.
Gostaria de salientar que este caso não é raro. Por exemplo, você marca uma coluna como NOT NULL. Depois de um tempo, outro desenvolvedor decide permitir NULLs para aquela coluna. Isso pode levar à situação, quando um relatório do cliente para de funcionar assim que qualquer valor NULL é inserido na tabela.
Nesse caso, eu recomendaria excluir valores NULL:
SELECT *FROM @t1WHERE t1 NOT IN (SELECT t2 FROM @t2 WHERE t2 IS NOT NULL)
Além disso, é possível usar EXCEPT :
SELECT * FROM @t1EXCEPTSELECT * FROM @t2
Alternativamente, você pode usar NÃO EXISTE :
SELECT *FROM @t1WHERE NOT EXISTS(SELECT 1 FROM @t2 WHERE t1 =t2)
Qual opção é mais preferível? A última opção com NÃO EXISTE parece ser o mais produtivo, pois gera o melhor predicado pushdown operador para acessar os dados da segunda tabela.
Na verdade, os valores NULL podem retornar um resultado inesperado.
Considere isso neste exemplo em particular:
USE AdventureWorks2014GOSELECT COUNT_BIG(*)FROM Production.ProductSELECT COUNT_BIG(*)FROM Production.ProductWHERE Cor ='Cinza'SELECT COUNT_BIG(*)FROM Production.ProductWHERE Cor <> 'Cinza'
Como você pode ver, você não obteve o resultado esperado porque os valores NULL possuem operadores de comparação separados:
SELECT COUNT_BIG(*)FROM Production.ProductWHERE Color IS NULLSELECT COUNT_BIG(*)FROM Production.ProductWHERE Color IS NOT NULL
Aqui está outro exemplo com CHECK restrições:
IF OBJECT_ID('tempdb.dbo.#temp') NÃO É NULL DROP TABLE #tempGOCREATE TABLE #temp ( Color VARCHAR(15) --NULL , CONSTRAINT CK CHECK (Color IN ('Black', 'White') )) Criamos uma tabela com permissão para inserir apenas as cores branca e preta:
INSERT INTO #temp VALUES ('Black')(1 linha(s) afetadas) Tudo funciona como esperado.
INSERT INTO #temp VALUES ('Red')A instrução INSERT entrou em conflito com a restrição CHECK...A instrução foi encerrada. Agora, vamos adicionar NULL:
INSERT INTO #temp VALUES (NULL)(1 linha(s) afetadas)
Por que a restrição CHECK passou o valor NULL? Bem, a razão é que há o suficiente NÃO FALSO condição para fazer um registro. A solução é definir explicitamente uma coluna como NOT NULL ou use NULL na restrição.
Formato de data
Muitas vezes, você pode ter dificuldades com tipos de dados.
Por exemplo, você precisa obter a data atual. Para fazer isso, você pode usar a função GETDATE:
SELECT GETDATE()
Em seguida, basta copiar o resultado retornado em uma consulta obrigatória e excluir a hora:
SELECT *FROM sys.objectsWHERE create_date <'2016-11-14'
Isso é correto?
A data é especificada por uma constante de string:
SET LANGUAGE PortugueseSET DATEFORMAT DMYDECLARE @d1 DATETIME ='05/12/2016' , @d2 DATETIME ='2016/12/05' , @d3 DATETIME ='2016-12-05' , @d4 DATETIME ='05 -dec-2016'SELECT @d1, @d2, @d3, @d4
Todos os valores têm uma interpretação de valor único:
----------- ----------- ----------- -----------2016-12 -05 2016-05-12 2016-05-12 2016-12-05
Não causará nenhum problema até que a consulta com essa lógica de negócios seja executada em outro servidor em que as configurações possam ser diferentes:
SET DATEFORMAT MDYDECLARE @d1 DATETIME ='05/12/2016' , @d2 DATETIME ='2016/12/05' , @d3 DATETIME ='2016-12-05' , @d4 DATETIME ='05-dez -2016'SELECT @d1, @d2, @d3, @d4
No entanto, essas opções podem levar a uma interpretação incorreta da data:
----------- ----------- ----------- -----------2016-05 -12 2016-12-05 2016-12-05 2016-12-05
Além disso, esse código pode levar a um bug visível e latente.
Considere o exemplo a seguir. Precisamos inserir dados em uma tabela de teste. Em um servidor de teste tudo funciona perfeitamente:
DECLARE @t TABLE (a DATETIME)INSERT INTO @t VALUES ('05/13/2016') Ainda assim, no lado do cliente, essa consulta terá problemas, pois as configurações do nosso servidor são diferentes:
DECLARE @t TABLE (a DATETIME)SET DATEFORMAT DMYINSERT INTO @t VALUES ('05/13/2016') Msg 242, Level 16, State 3, Line 28A conversão de um tipo de dados varchar em um tipo de dados datetime resultou em um valor fora do intervalo.
Assim, que formato devemos usar para declarar constantes de data? Para responder a esta pergunta, execute esta consulta:
SET DATEFORMAT YMDSET LANGUAGE PortugueseDECLARE @d1 DATETIME ='2016/01/12' , @d2 DATETIME ='2016-01-12' , @d3 DATETIME ='12-jan-2016' , @d4 DATETIME ='20160112 'SELECT @d1, @d2, @d3, @d4GOSET LANGUAGE DeutschDECLARE @d1 DATETIME ='2016/01/12' , @d2 DATETIME ='2016-01-12' , @d3 DATETIME ='12-jan-2016' , @d4 DATETIME ='20160112'SELECT @d1, @d2, @d3, @d4
A interpretação das constantes pode diferir dependendo do idioma instalado:
----------- ----------- ----------- -----------2016-01 -12 2016-01-12 2016-01-12 2016-01-12 ----------- ----------- ----------- -----------2016-12-01 2016-12-01 2016-01-12 2016-01-12
Assim, é melhor usar as duas últimas opções. Além disso, gostaria de acrescentar que especificar explicitamente a data não é uma boa ideia:
SET LANGUAGE FrenchDECLARE @d DATETIME ='12-jan-2016'Msg 241, Level 16, State 1, Line 29Échec de la conversion de la date et/ou de l'heure a partir de uma cadeia de caracteres.
Portanto, se você deseja que as constantes com as datas sejam interpretadas corretamente, você precisa especificá-las no seguinte formato AAAAMMDD.
Além disso, gostaria de chamar sua atenção para o comportamento de alguns tipos de dados:
SET LANGUAGE PortugueseSET DATEFORMAT YMDDECLARE @d1 DATE ='2016-01-12' , @d2 DATETIME ='2016-01-12'SELECT @d1, @d2GOSET LANGUAGE DeutschSET DATEFORMAT DMYDECLARE @d1 DATE ='2016-01- 12' , @d2 DATETIME ='2016-01-12'SELECT @d1, @d2
Ao contrário de DATETIME, o DATE type é interpretado corretamente com várias configurações em um servidor:
---------- ----------2016-01-12 2016-01-12---------- ------- ---2016-01-12 2016-12-01
Filtro de data
Para seguir em frente, consideraremos como filtrar dados de forma eficaz. Vamos começar com eles DATETIME/DATE:
USE AdventureWorks2014GOUPDATE TOP(1) dbo.DatabaseLogSET PostTime ='20140716 12:12:12'
Agora, vamos tentar descobrir quantas linhas a consulta retorna para um dia especificado:
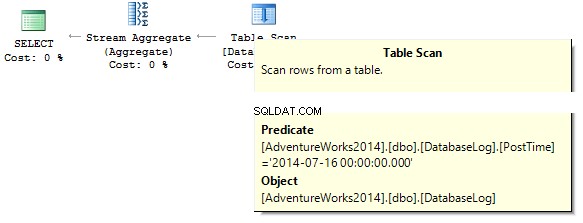
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime ='20140716'
A consulta retornará 0. Ao construir um plano de execução, o SQL Server está tentando converter uma constante de string para o tipo de dados da coluna que precisamos filtrar:
Crie um índice:
CRIAR ÍNDICE NÃO CLUSTERADO IX_PostTime ON dbo.DatabaseLog (PostTime)
Existem opções corretas e incorretas para saída de dados. Por exemplo, você precisa excluir a coluna de tempo:
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CONVERT(CHAR(8), PostTime, 112) ='20140716'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CAST(PostTime AS DATE) ='20140716'
Ou precisamos especificar um intervalo:
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime BETWEEN '20140716' AND '20140716 23:59:59.997'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime>='20140716' AND PostTime <'20140717'
Levando em conta a otimização, posso dizer que essas duas consultas são as mais corretas. O ponto é que todas as conversões e cálculos de colunas de índice que estão sendo filtradas podem diminuir drasticamente o desempenho e aumentar o tempo de leituras lógicas:
Tabela 'DatabaseLog'. Contagem de varredura 1, leituras lógicas 7, ...Tabela 'DatabaseLog'. Contagem de varredura 1, leituras lógicas 2, ...
O PostTime campo não havia sido incluído no índice antes, e não pudemos ver nenhuma eficiência no uso dessa abordagem correta na filtragem. Outra coisa é quando precisamos gerar dados para um mês:
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CONVERT(CHAR(8), PostTime, 112) LIKE '201407%'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE DATEPART(YEAR, PostTime) =2014 AND DATEPART(MONTH, PostTime) =7SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE YEAR(PostTime) =2014 AND MONTH(PostTime) =7SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE EOMONTH(PostTime) ='20140731'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime>='20140701' AND PostTime <'20140801'
Novamente, a última opção é mais preferível:
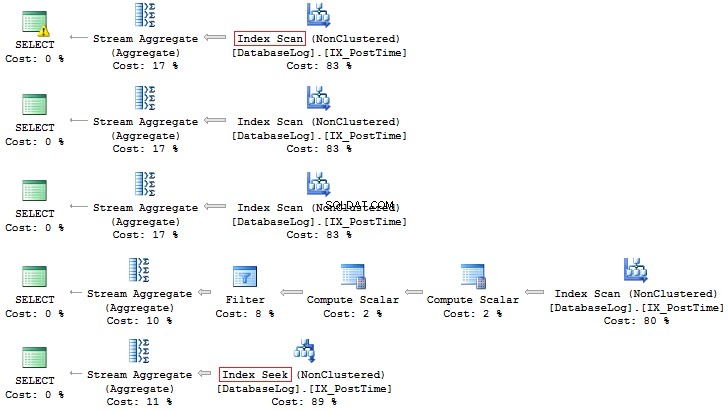
Além disso, você sempre pode criar um índice com base em um campo calculado:
IF COL_LENGTH('dbo.DatabaseLog', 'MonthLastDay') NÃO É NULL ALTER TABLE dbo.DatabaseLog DROP COLUMN MonthLastDayGOALTER TABLE dbo.DatabaseLog ADD MonthLastDay AS EOMONTH(PostTime) --PERSISTEDGOCREATE INDEX IX_MonthLastDay ON dbo.DatabaseLog (MonthLastDay) Em comparação com a consulta anterior, a diferença nas leituras lógicas pode ser significativa (se estiverem em questão tabelas grandes):
SET STATISTICS IO ONSELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime>='20140701' AND PostTime <'20140801'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE MonthLastDay ='20140731'SET STATISTICS IO OFFTable 'DatabaseLog'. Contagem de varredura 1, leituras lógicas 7, ...Tabela 'DatabaseLog'. Contagem de varredura 1, leituras lógicas 3, ...
Cálculo
Como já foi discutido, quaisquer cálculos nas colunas de índice diminuem o desempenho e aumentam o tempo de leituras lógicas:
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID * 2 =10000SELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID =2500 * 2SELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID =5000Table 'Person'. Contagem de varredura 1, leituras lógicas 67, ...Tabela 'Pessoa'. Contagem de varredura 0, leituras lógicas 3, ...
Se observarmos os planos de execução, no primeiro, o SQL Server executa o IndexScan :
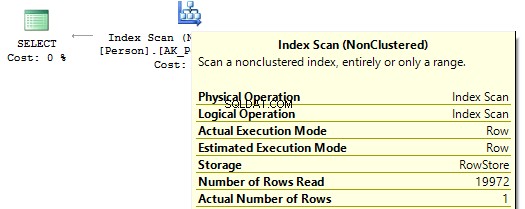
Então, quando não houver cálculos nas colunas de índice, veremos IndexSeek :

Converter implícito
Vamos dar uma olhada nessas duas consultas que filtram pelo mesmo valor:
USE AdventureWorks2014GOSELECT BusinessEntityID, NationalIDNumberFROM HumanResources.EmployeeWHERE NationalIDNumber =30845SELECT BusinessEntityID, NationalIDNumberFROM HumanResources.EmployeeWHERE NationalIDNumber ='30845'
Os planos de execução fornecem as seguintes informações:
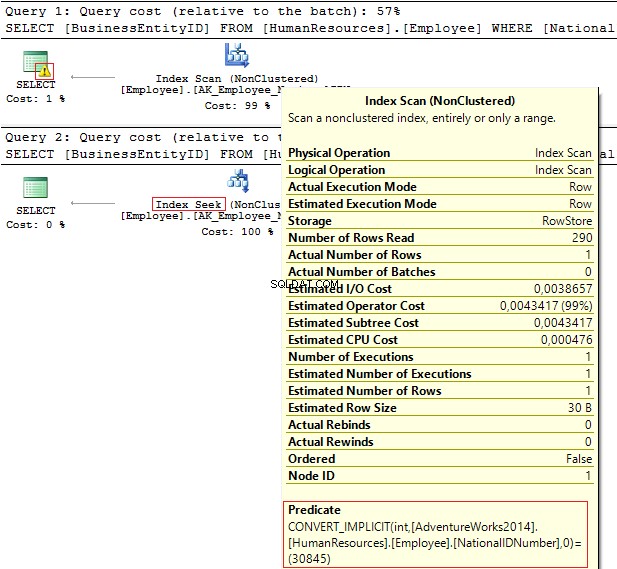
- Aviso e IndexScan no primeiro plano
- IndexSeek – no segundo.
Tabela 'Funcionário'. Contagem de varredura 1, leituras lógicas 4, ...Tabela 'Employee'. Contagem de varredura 0, leituras lógicas 2, ...
O NationalIDNumber coluna tem o NVARCHAR(15) tipo de dados. A constante que usamos para filtrar os dados é definida como INT o que nos leva a uma conversão implícita de tipo de dados. Por sua vez, pode diminuir o desempenho. Você pode monitorá-lo quando alguém modifica o tipo de dados na coluna, no entanto, as consultas não são alteradas.
É importante entender que uma conversão de tipo de dados implícita pode levar a erros em tempo de execução. Por exemplo, antes que o campo PostalCode fosse numérico, um código postal podia conter letras. Assim, o tipo de dados foi atualizado. Ainda assim, se inserirmos um código postal alfabético, a consulta antiga não funcionará mais:
SELECT AddressIDFROM Person.[Address]WHERE PostalCode =92700SELECT AddressIDFROM Person.[Address]WHERE PostalCode ='92700'Msg 245, Level 16, State 1, Line 16Falha na conversão ao converter o valor nvarchar 'K4B 1S2' para tipo de dados int.
Outro exemplo é quando você precisa usar EntityFramework no projeto, que por padrão interpreta todos os campos de linha como Unicode:
SELECT CustomerID, AccountNumberFROM Sales.CustomerWHERE AccountNumber =N'AW00000009'SELECT CustomerID, AccountNumberFROM Sales.CustomerWHERE AccountNumber ='AW00000009'
Portanto, são geradas consultas incorretas:

Para resolver esse problema, verifique se os tipos de dados correspondem.
Curtir e índice suprimido
Na verdade, ter um índice de cobertura não significa que você o usará de forma eficaz.
Vamos verificar neste exemplo em particular. Suponha que precisamos gerar todas as linhas que começam com…
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT AddressLine1FROM Person.[Address]WHERE SUBSTRING(AddressLine1, 1, 3) ='100'SELECT AddressLine1FROM Person.[Address]WHERE LEFT(AddressLine1, 3) ='100'SELECT AddressLine1FROM Person.[ Endereço]WHERE CAST(AddressLine1 AS CHAR(3)) ='100'SELECT AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '100%'
Obteremos as seguintes leituras lógicas e planos de execução:
Tabela 'Endereço'. Contagem de varredura 1, leituras lógicas 216, ...Tabela 'Endereço'. Contagem de varredura 1, leituras lógicas 216, ...Tabela 'Endereço'. Contagem de varredura 1, leituras lógicas 216, ...Tabela 'Endereço'. Contagem de varredura 1, leituras lógicas 4, ...
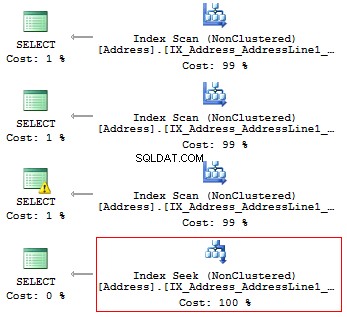
Assim, se houver um índice, ele não deve conter nenhum cálculo ou conversão de tipos, funções, etc.
Mas o que você faz se precisar encontrar a ocorrência de uma substring em uma string?
SELECT AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '%100%'v
Voltaremos a esta questão mais adiante.
Unicode x ANSI
É importante lembrar que existem os UNICODE e ANSI cordas. O tipo UNICODE inclui NVARCHAR/NCHAR (2 bytes para um símbolo). Para armazenar ANSI strings, é possível usar VARCHAR/CHAR (1 byte para 1 símbolo). Há também TEXT/NTEXT , mas não recomendo usá-los, pois podem diminuir o desempenho.
Se você especificar uma constante Unicode em uma consulta, será necessário precedê-la com o símbolo N. Para verificar, execute a seguinte consulta:
SELECT '文本 ANSI' , N'文本 UNICODE'------- ------------?? ANSI 文本 UNICODE
Se N não preceder a constante, o SQL Server tentará encontrar um símbolo adequado na codificação ANSI. Se não encontrar, ele mostrará um ponto de interrogação.
RECOLHER
Muitas vezes, ao ser entrevistado para o cargo Desenvolvedor de BD Médio/Sênior, um entrevistador geralmente faz a seguinte pergunta:Essa consulta retornará os dados?
DECLARE @a NCHAR(1) ='Ё' , @b NCHAR(1) ='Ф'SELECT @a, @bWHERE @a =@b
Depende. Em primeiro lugar, o símbolo N não precede uma constante de string, portanto, será interpretado como ANSI. Em segundo lugar, depende muito do valor COLLATE atual, que é um conjunto de regras, ao selecionar e comparar dados de string.
USE [master]GOIF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_100_CI_ASGOUSE testGODECLARE @a NCHAR(1) ='Ё' , @b NCHAR(1 ) ='Ф'SELECT @a, @bWHERE @a =@b Esta instrução COLLATE retornará pontos de interrogação, pois seus símbolos são iguais:
---- ----? ?
Se alterarmos a instrução COLLATE por outra instrução:
Teste ALTER DATABASE COLLATE Cyrillic_General_100_CI_AS
Nesse caso, a consulta não retornará nada, pois os caracteres cirílicos serão interpretados corretamente.
Portanto, se uma constante de string ocupa UNICODE, é necessário definir N antes de uma constante de string. Ainda assim, eu não recomendaria configurá-lo em todos os lugares pelos motivos que discutimos acima.
Outra pergunta a ser feita na entrevista refere-se à comparação de linhas.
Considere o seguinte exemplo:
DECLARE @a VARCHAR(10) ='TEXT' , @b VARCHAR(10) ='text'SELECT IIF(@a =@b, 'TRUE', 'FALSE')
Essas linhas são iguais? Para verificar isso, precisamos especificar explicitamente COLLATE:
DECLARE @a VARCHAR(10) ='TEXT' , @b VARCHAR(10) ='text'SELECT IIF(@a COLLATE Latin1_General_CS_AS =@b COLLATE Latin1_General_CS_AS, 'TRUE', 'FALSE')
Como existem COLLATEs que diferenciam maiúsculas de minúsculas (CS) e não diferenciam maiúsculas de minúsculas (CI) ao comparar e selecionar linhas, não podemos dizer com certeza se elas são iguais. Além disso, existem vários COLLATEs em um servidor de teste e no lado do cliente.
Há um caso em que COLLATEs de uma base de destino e tempdb não combina.
Crie um banco de dados com COLLATE:
USE [master]GOIF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Albanian_100_CS_ASGOUSE testGOCREATE TABLE t (c CHAR(1))INSERT INTO t VALUES ('a ')GOIF OBJECT_ID('tempdb.dbo.#t1') NÃO É NULL DROP TABLE #t1IF OBJECT_ID('tempdb.dbo.#t2') NÃO É NULL DROP TABLE #t2IF OBJECT_ID('tempdb.dbo.#t3') IS NOT NULL DROP TABLE #t3GOCREATE TABLE #t1 (c CHAR(1))INSERT INTO #t1 VALUES ('a')CREATE TABLE #t2 (c CHAR(1) COLLATE database_default)INSERT INTO #t2 VALUES ('a') SELECT c =CAST('a' AS CHAR(1))INTO #t3DECLARE @t TABLE (c VARCHAR(100))INSERT INTO @t VALUES ('a')SELECT 'tempdb', DATABASEPROPERTYEX('tempdb', 'collation ')UNION ALLSELECT 'test', DATABASEPROPERTYEX(DB_NAME(), 'collation')UNION ALLSELECT 't', SQL_VARIANT_PROPERTY(c, 'collation') FROM tUNION ALLSELECT '#t1', SQL_VARIANT_PROPERTY(c, 'collation') FROM # t1UNION ALLSELECT '#t2', SQL_VARIANT_PROPERTY(c, 'agrupamento') FROM # t2UNION ALLSELECT '#t3', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t3UNION ALLSELECT '@t', SQL_VARIANT_PROPERTY(c, 'collation') FROM @t Ao criar uma tabela, ela herda COLLATE de um banco de dados. A única diferença para a primeira tabela temporária, para a qual determinamos uma estrutura explicitamente sem COLLATE, é que ela herda COLLATE do tempdb base de dados.
------ --------------------------tempdb Cirílico_General_CI_AStest Albanês_100_CS_ASt Albanês_100_CS_AS#t1 Cirílico_General_CI_AS#t2 Albanês_100_CS_AS#t3 Albanês_100_CS_AS@t Albanês_100_CS_AS
Descreverei o caso em que os COLLATEs não correspondem no exemplo específico com #t1.
Por exemplo, os dados não são filtrados corretamente, pois COLLATE pode não levar em consideração um caso:
SELECT *FROM #t1WHERE c ='A'
Alternativamente, podemos ter um conflito para conectar tabelas com COLLATEs diferentes:
SELECT *FROM #t1JOIN t ON [#t1].c =t.c
Tudo parece estar funcionando perfeitamente em um servidor de teste, enquanto em um servidor cliente recebemos um erro:
Msg 468, Level 16, State 9, Line 93Não é possível resolver o conflito de agrupamento entre "Albanian_100_CS_AS" e "Cyrillic_General_CI_AS" na operação igual a.
Para contornar isso, temos que definir hacks em todos os lugares:
SELECT *FROM #t1JOIN t ON [#t1].c =t.c COLLATE database_default
COLLATE BINÁRIO
Agora, vamos descobrir como usar o COLLATE para seu benefício.
Considere o exemplo com a ocorrência de uma substring em uma string:
SELECT AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '%100%'
É possível otimizar esta consulta e reduzir seu tempo de execução.
Primeiramente, precisamos gerar uma tabela grande:
USE [master]GOIF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_100_CS_ASGOALTER DATABASE test MODIFY FILE (NAME =N'test', SIZE =64MB)GOALTER DATABASE test MODIFY FILE (NAME =N'test_log', SIZE =64MB)GOUSE testGOCREATE TABLE t ( ansi VARCHAR(100) NOT NULL , unicode NVARCHAR(100) NOT NULL)GO;WITH E1(N) AS ( SELECT * FROM ( VALORES (1),(1),(1),(1),(1), (1),(1),(1),(1),(1) ) t(N) ), E2(N ) AS (SELECT 1 FROM E1 a, E1 b), E4(N) AS (SELECT 1 FROM E2 a, E2 b), E8(N) AS (SELECT 1 FROM E4 a, E4 b)INSERT INTO tSELECT v, vFROM (SELECT TOP(50000) v =REPLACE(CAST(NEWID() AS VARCHAR(36)) + CAST(NEWID() AS VARCHAR(36)), '-', '') FROM E8) t Crie colunas calculadas com COLLATEs e índices binários:
ALTER TABLE t ADICIONAR ansi_bin AS UPPER(ansi) COLLATE Latin1_General_100_Bin2ALTER TABLE t ADICIONAR unicod_bin AS UPPER(unicod) COLLATE Latin1_General_100_BIN2CREATE NONCLUSTERED INDEX ansi ON t (ansi)CREATE NONCLUSTERED INDEX unicod ON t (unicod ()CREATE NONCLUSTERED INDEX ansi_bin ON t ansi_bin)CRIAR ÍNDICE NÃO CLUSTERADO unicod_bin ON t (unicod_bin)
Execute o processo de filtragem:
SET STATISTICS TIME, IO ONSELECT COUNT_BIG(*)FROM tWHERE ansi LIKE '%AB%'SELECT COUNT_BIG(*)FROM tWHERE unicode LIKE '%AB%'SELECT COUNT_BIG(*)FROM tWHERE ansi_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2SELECT COUNT_BIG(*)FROM tWHERE unicod_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2SET STATISTICS TIME, IO OFF
Como você pode ver, esta consulta retorna o seguinte resultado:
Tempos de execução do SQL Server:tempo de CPU =350 ms, tempo decorrido =354 ms. Tempos de execução do SQL Server:tempo de CPU =335 ms, tempo decorrido =355 ms. Tempos de execução do SQL Server:tempo de CPU =16 ms, tempo decorrido =18 ms.Tempos de execução do SQL Server:tempo de CPU =17 ms, tempo decorrido =18 ms.
A questão é que o filtro baseado na comparação binária leva menos tempo. Assim, se você precisar filtrar a ocorrência de strings com frequência e rapidez, é possível armazenar dados com COLLATE terminando com BIN. No entanto, deve-se notar que todos os COLLATEs binários diferenciam maiúsculas de minúsculas.
Estilo de código
Um estilo de codificação é estritamente individual. Ainda assim, esse código deve ser simplesmente mantido por outros desenvolvedores e corresponder a certas regras.
Crie um banco de dados separado e uma tabela dentro:
USE [master]GOIF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_CI_ASGOUSE testGOCREATE TABLE dbo.Employee (EmployeeID INT PRIMARY KEY) Em seguida, escreva a consulta:
selecione funcionárioid de funcionário
Agora, altere COLLATE para qualquer um que faça distinção entre maiúsculas e minúsculas:
Teste ALTER DATABASE COLLATE Latin1_General_CS_AI
Em seguida, tente executar a consulta novamente:
Msg 208, Level 16, State 1, Line 19Nome de objeto inválido 'employee'.
Um otimizador usa regras para o COLLATE atual na etapa de vinculação quando verifica tabelas, colunas e outros objetos, bem como compara cada objeto da árvore sintática com um objeto real de um catálogo do sistema.
Se você quiser gerar consultas manualmente, precisará sempre usar as maiúsculas e minúsculas corretas nos nomes dos objetos.
Quanto às variáveis, os COLLATEs são herdados do banco de dados mestre. Assim, você precisa usar o caso correto para trabalhar com eles também:
SELECT DATABASEPROPERTYEX('master', 'collation')DECLARE @EmpID INT =1SELECT @empid Nesse caso, você não receberá um erro:
-----------------------Cirílico_General_CI_AS-----------1
Ainda assim, um erro de caso pode aparecer em outro servidor:
--------------------------Latin1_General_CS_ASMsg 137, Level 15, State 2, Line 4Deve declarar a variável escalar "@empid".[var]char
Como você sabe, existem (CHAR , NCHAR ) e variável (VARCHAR , NVARCHAR ) tipos de dados:
DECLARE @a CHAR(20) ='text' , @b VARCHAR(20) ='text'SELECT LEN(@a) , LEN(@b) , DATALENGTH(@a) , DATALENGTH(@b) , '"' + @a + '"' , '"' + @b + '"'SELECT [a =b] =IIF(@a =@b, 'TRUE', 'FALSE'), [b =a] =IIF(@b =@a, 'TRUE', 'FALSE') , [a LIKE b] =IIF(@a LIKE @b, 'TRUE', 'FALSE') , [b LIKE a] =IIF(@ b LIKE @a, 'VERDADEIRO', 'FALSO')
Se uma linha tiver um comprimento fixo, digamos 20 símbolos, mas você tiver escrito apenas 4 símbolos, o SQL Server adicionará 16 espaços em branco à direita por padrão:
--- --- ---- ---- ----------- ----------- -----------4 4 20 4 "texto" "texto"
Além disso, é importante entender que, ao comparar linhas com =, os espaços em branco à direita não são levados em consideração:
a =b b =a a LIKE b b LIKE a----- ----- -------- --------VERDADEIRO VERDADEIRO VERDADEIRO FALSO
Quanto ao operador LIKE, sempre serão inseridos espaços em branco.
SELECT 1WHERE 'a' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a ' -- !!!SELECT 1WHERE 'a' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a%'Tamanho dos dados
É sempre necessário especificar o comprimento do tipo.
Considere o seguinte exemplo:
DECLARE @a DECIMAL , @b VARCHAR(10) ='0.1' , @c SQL_VARIANTSELECT @a =@b , @c =@aSELECT @a , @c , SQL_VARIANT_PROPERTY(@c,'BaseType') , SQL_VARIANT_PROPERTY(@c,'Precision') , SQL_VARIANT_PROPERTY(@c,'Scale')
As you can see, the type length was not specified explicitly. Thus, the query returned an integer instead of a decimal value:
---- ---- ---------- ----- -----0 0 decimal 18 0
As for rows, if you do not specify a row length explicitly, then its length will contain only 1 symbol:
----- ------------------------------------------ ---- ---- ---- ----40 123456789_123456789_123456789_123456789_ 1 1 30 30
In addition, if you do not need to specify a length for CAST/CONVERT, then only 30 symbols will be used.
ISNULL vs COALESCE
There are two functions:ISNULL and COALESCE. On the one hand, everything seems to be simple. If the first operator is NULL, then it will return the second or the next operator, if we talk about COALESCE. On the other hand, there is a difference – what will these functions return?
DECLARE @a CHAR(1) =NULLSELECT ISNULL(@a, 'NULL'), COALESCE(@a, 'NULL')DECLARE @i INT =NULLSELECT ISNULL(@i, 7.1), COALESCE(@i, 7.1)
The answer is not obvious, as the ISNULL function converts to the smallest type of two operands, whereas COALESCE converts to the largest type.
---- ----N NULL---- ----7 7.1
As for performance, ISNULL will process a query faster, COALESCE is split into the CASE WHEN operator.
Math
Math seems to be a trivial thing in SQL Server.
SELECT 1 / 3SELECT 1.0 / 3
However, it is not. Everything depends on the fact what data is used in a query. If it is an integer, then it returns the integer result.
-----------0-----------0.333333
Also, let’s consider this particular example:
SELECT COUNT(*) , COUNT(1) , COUNT(val) , COUNT(DISTINCT val) , SUM(val) , SUM(DISTINCT val)FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)SELECT AVG(val) , SUM(val) / COUNT(val) , AVG(val * 1.) , AVG(CAST(val AS FLOAT))FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)
This query COUNT(*)/COUNT(1) will return the total amount of rows. COUNT on the column will return the amount of non-NULL rows. If we add DISTINCT, then it will return the amount of non-NULL unique values.
The AVG operation is divided into SUM and COUNT. Thus, when calculating an average value, NULL is not applicable.
UNION vs UNION ALL
When the data is not overridden, then it is better to use UNION ALL to improve performance. In order to avoid replication, you may use UNION.
Still, if there is no replication, it is preferable to use UNION ALL:
SELECT [object_id]FROM sys.system_objectsUNIONSELECT [object_id]FROM sys.objectsSELECT [object_id]FROM sys.system_objectsUNION ALLSELECT [object_id]FROM sys.objects
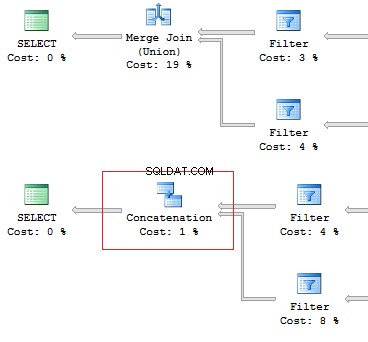
Also, I would like to point out the difference of these operators:the UNION operator is executed in a parallel way, the UNION ALL operator – in a sequential way.
Assume, we need to retrieve 1 row on the following conditions:
DECLARE @AddressLine NVARCHAR(60)SET @AddressLine ='4775 Kentucky Dr.'SELECT TOP(1) AddressIDFROM Person.[Address]WHERE AddressLine1 =@AddressLine OR AddressLine2 =@AddressLine
As we have OR in the statement, we will receive IndexScan:
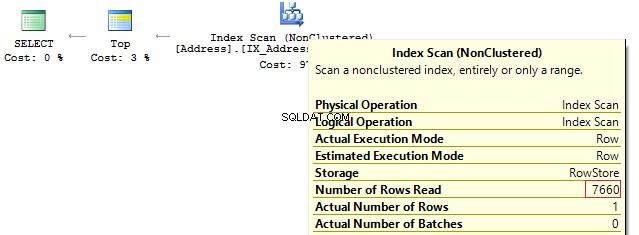
Table 'Address'. Scan count 1, logical reads 90, ...
Now, we will re-write the query using UNION ALL:
SELECT TOP(1) AddressIDFROM ( SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine1 =@AddressLine UNION ALL SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine2 =@AddressLine) t
When the first subquery had been executed, it returned 1 row. Thus, we have received the required result, and SQL Server stopped looking for, using the second subquery:
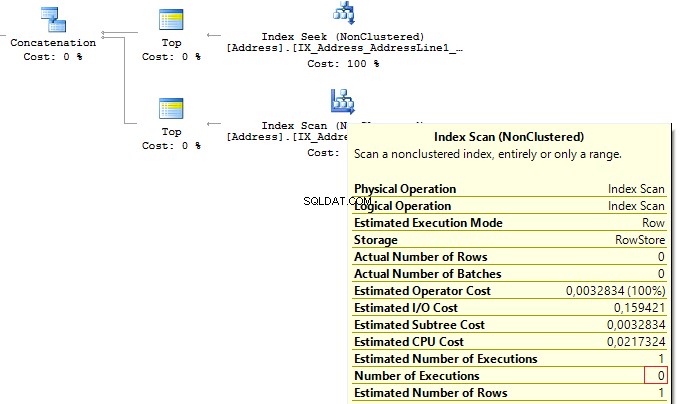
Table 'Worktable'. Scan count 0, logical reads 0, ...Table 'Address'. Scan count 1, logical reads 3, ...Re-read
Very often, I faced the situation when the data can be retrieved with one JOIN. In addition, a lot of subqueries are created in this query:
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT e.BusinessEntityID , ( SELECT p.LastName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID ) , ( SELECT p.FirstName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID )FROM HumanResources.Employee eSELECT e.BusinessEntityID , p.LastName , p.FirstNameFROM HumanResources.Employee eJOIN Person.Person p ON e.BusinessEntityID =p.BusinessEntityID
The fewer there are unnecessary table lookups, the fewer logical readings we have:
Table 'Person'. Scan count 0, logical reads 1776, ...Table 'Employee'. Scan count 1, logical reads 2, ...Table 'Person'. Scan count 0, logical reads 888, ...Table 'Employee'. Scan count 1, logical reads 2, ...SubQuery
The previous example works only if there is a one-to-one connection between tables.
Assume tables Person.Person and Sales.SalesPersonQuotaHistory were directly connected. Thus, one employee had only one record for a share size.
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT p.BusinessEntityID , ( SELECT s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID )FROM Person.Person p
However, as settings on the client server may differ, this query may lead to the following error:
Msg 512, Level 16, State 1, Line 6Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <=,>,>=or when the subquery is used as an expression.
It is possible to solve such issues by adding TOP(1) and ORDER BY. Using the TOP operation makes an optimizer force using IndexSeek. The same refers to using OUTER/CROSS APPLY with TOP:
SELECT p.BusinessEntityID , ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC )FROM Person.Person pSELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pOUTER APPLY ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC) t
When executing these queries, we will get the same issue – multiple IndexSeek operators:
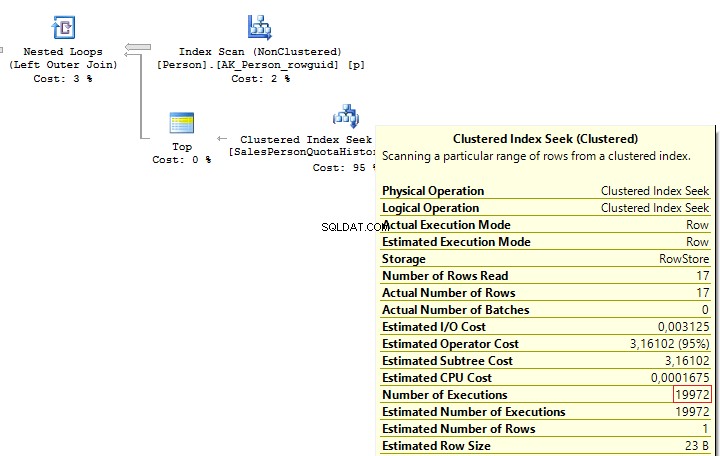
Table 'SalesPersonQuotaHistory'. Scan count 19972, logical reads 39944, ...Table 'Person'. Scan count 1, logical reads 67, ...
Re-write this query with a window function:
SELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pLEFT JOIN ( SELECT s.BusinessEntityID , s.SalesQuota , RowNum =ROW_NUMBER() OVER (PARTITION BY s.BusinessEntityID ORDER BY s.QuotaDate DESC) FROM Sales.SalesPersonQuotaHistory s) t ON p.BusinessEntityID =t.BusinessEntityID AND t.RowNum =1
Obtemos o seguinte resultado:
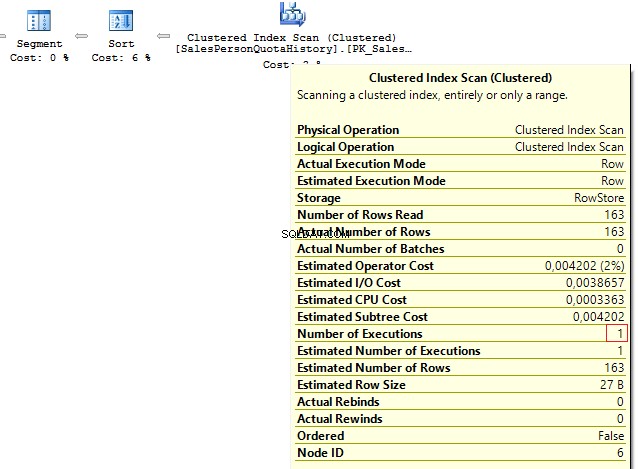
Table 'Person'. Scan count 1, logical reads 67, ...Table 'SalesPersonQuotaHistory'. Scan count 1, logical reads 4, ...CASE WHEN
Since this operator is used very often, I would like to specify its features. Regardless, how we wrote the CASE WHEN operator:
USE AdventureWorks2014GOSELECT BusinessEntityID , Gender , Gender =CASE Gender WHEN 'M' THEN 'Male' WHEN 'F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.Employee
SQL Server will decompose the statement to the following:
SELECT BusinessEntityID , Gender , Gender =CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.Employee
Thus, this will lead to the main issue:each condition will be executed in a sequential order until one of them returns TRUE or ELSE.
Consider this issue on a particular example. To do this, we will create a scalar-valued function which will return the right part of a postal code:
IF OBJECT_ID('dbo.GetMailUrl') IS NOT NULL DROP FUNCTION dbo.GetMailUrlGOCREATE FUNCTION dbo.GetMailUrl( @Email NVARCHAR(50))RETURNS NVARCHAR(50)AS BEGIN RETURN SUBSTRING(@Email, CHARINDEX('@', @Email) + 1, LEN(@Email))END
Then, configure SQL Profiler to build SQL events:StmtStarting / SP:StmtCompleted (if you want to do this with XEvents :sp_statement_starting / sp_statement_completed ).
Execute the query:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) --WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddress
The function will be executed for 10 times. Now, delete a comment from the condition:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddress
In this case, the function will be executed for 20 times. The thing is that it is not necessary for a statement to be a must function in CASE. It may be a complicated calculation. As it is possible to decompose CASE, it may lead to multiple calculations of the same operators.
You may avoid it by using subqueries:
SELECT EmailAddressID , EmailAddress , CASE MailUrl WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM ( SELECT TOP(10) EmailAddressID , EmailAddress , MailUrl =dbo.GetMailUrl(EmailAddress) FROM Person.EmailAddress) t
In this case, the function will be executed 10 times.
In addition, we need to avoid replication in the CASE operator:
SELECT DISTINCT CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='M' THEN '...' WHEN Gender ='M' THEN '......' WHEN Gender ='F' THEN 'Female' WHEN Gender ='F' THEN '...' ELSE 'Unknown' ENDFROM HumanResources.Employee
Though statements in CASE are executed in a sequential order, in some cases, SQL Server may execute this operator with aggregate functions:
DECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE 1/0 ENDGODECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE MIN(1/0) ENDScalar func
It is not recommended to use scalar functions in T-SQL queries.
Consider the following example:
USE AdventureWorks2014GOUPDATE TOP(1) Person.[Address]SET AddressLine2 =AddressLine1GOIF OBJECT_ID('dbo.isEqual') IS NOT NULL DROP FUNCTION dbo.isEqualGOCREATE FUNCTION dbo.isEqual( @val1 NVARCHAR(100), @val2 NVARCHAR(100))RETURNS BITAS BEGIN RETURN CASE WHEN (@val1 IS NULL AND @val2 IS NULL) OR @val1 =@val2 THEN 1 ELSE 0 ENDEND
The queries return the identical data:
SET STATISTICS TIME ONSELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE dbo.IsEqual(AddressLine1, AddressLine2) =1SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE (AddressLine1 IS NULL AND AddressLine2 IS NULL) OR AddressLine1 =AddressLine2SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE AddressLine1 =ISNULL(AddressLine2, '')SET STATISTICS TIME OFF
However, as each call of the scalar function is a resource-intensive process, we can monitor this difference:
SQL Server Execution Times:CPU time =63 ms, elapsed time =57 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.
In addition, when using a scalar function, it is not possible for SQL Server to build parallel execution plans, which may lead to poor performance in a huge volume of data.
Sometimes scalar functions may have a positive effect. For example, when we have SCHEMABINDING in the statement:
IF OBJECT_ID('dbo.GetPI') IS NOT NULL DROP FUNCTION dbo.GetPIGOCREATE FUNCTION dbo.GetPI ()RETURNS FLOATWITH SCHEMABINDINGAS BEGIN RETURN PI()ENDGOSELECT dbo.GetPI()FROM Sales.Currency
In this case, the function will be considered as deterministic and executed 1 time.
VIEWs
Here I would like to talk about features of views.
Create a test table and view on its base:
IF OBJECT_ID('dbo.tbl', 'U') IS NOT NULL DROP TABLE dbo.tblGOCREATE TABLE dbo.tbl (a INT, b INT)GOINSERT INTO dbo.tbl VALUES (0, 1)GOIF OBJECT_ID('dbo.vw_tbl', 'V') IS NOT NULL DROP VIEW dbo.vw_tblGOCREATE VIEW dbo.vw_tblAS SELECT * FROM dbo.tblGOSELECT * FROM dbo.vw_tbl
As you can see, we get the correct result:
a b----------- -----------0 1
Now, add a new column in the table and retrieve data from the view:
ALTER TABLE dbo.tbl ADD c INT NOT NULL DEFAULT 2GOSELECT * FROM dbo.vw_tbl
We receive the same result:
a b----------- -----------0 1
Thus, we need either to explicitly set columns or recompile a script object to get the correct result:
EXEC sys.sp_refreshview @viewname =N'dbo.vw_tbl'GOSELECT * FROM dbo.vw_tbl
Result:
a b c----------- ----------- -----------0 1 2
When you directly refer to the table, this issue will not take place.
Now, I would like to discuss a situation when all the data is combined in one query as well as wrapped in one view. I will do it on this particular example:
ALTER VIEW HumanResources.vEmployeeAS SELECT e.BusinessEntityID , p.Title , p.FirstName , p.MiddleName , p.LastName , p.Suffix , e.JobTitle , pp.PhoneNumber , pnt.[Name] AS PhoneNumberType , ea.EmailAddress , p.EmailPromotion , a.AddressLine1 , a.AddressLine2 , a.City , sp.[Name] AS StateProvinceName , a.PostalCode , cr.[Name] AS CountryRegionName , p.AdditionalContactInfo FROM HumanResources.Employee e JOIN Person.Person p ON p.BusinessEntityID =e.BusinessEntityID JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID =e.BusinessEntityID JOIN Person.[Address] a ON a.AddressID =bea.AddressID JOIN Person.StateProvince sp ON sp.StateProvinceID =a.StateProvinceID JOIN Person.CountryRegion cr ON cr.CountryRegionCode =sp.CountryRegionCode LEFT JOIN Person.PersonPhone pp ON pp.BusinessEntityID =p.BusinessEntityID LEFT JOIN Person.PhoneNumberType pnt ON pp.PhoneNumberTypeID =pnt.PhoneNumberTypeID LEFT JOIN Person.EmailAddress ea ON p.BusinessEntityID =ea.BusinessEntityID
What should you do if you need to get only a part of information? For example, you need to get Fist Name and Last Name of employees:
SELECT BusinessEntityID , FirstName , LastNameFROM HumanResources.vEmployeeSELECT p.BusinessEntityID , p.FirstName , p.LastNameFROM Person.Person pWHERE p.BusinessEntityID IN ( SELECT e.BusinessEntityID FROM HumanResources.Employee e )
Look at the execution plan in the case of using a view:
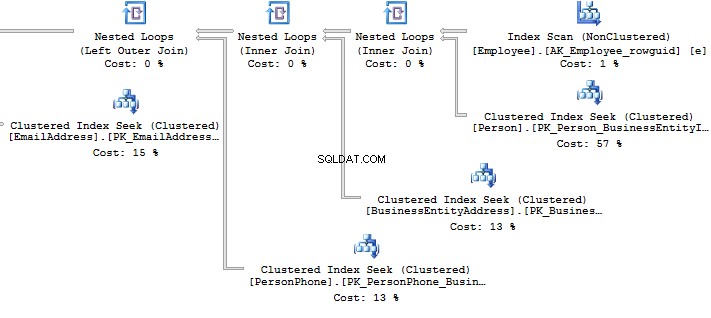
Table 'EmailAddress'. Scan count 290, logical reads 640, ...Table 'PersonPhone'. Scan count 290, logical reads 636, ...Table 'BusinessEntityAddress'. Scan count 290, logical reads 636, ...Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...
Now, we will compare it with the query we have written manually:
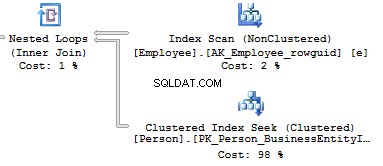
Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...
When creating an execution plan, an optimizer in SQL Server drops unused connections.
However, sometimes when there is no valid foreign key between tables, it is not possible to check whether a connection will impact the sample result. It may also be applied to the situation when tables are connecteCURSORs
I recommend that you do not use cursors for iteration data modification.
You can see the following code with a cursor:
DECLARE @BusinessEntityID INTDECLARE cur CURSOR FOR SELECT BusinessEntityID FROM HumanResources.EmployeeOPEN curFETCH NEXT FROM cur INTO @BusinessEntityIDWHILE @@FETCH_STATUS =0 BEGIN UPDATE HumanResources.Employee SET VacationHours =0 WHERE BusinessEntityID =@BusinessEntityID FETCH NEXT FROM cur INTO @BusinessEntityIDENDCLOSE curDEALLOCATE cur
Though, it is possible to re-write the code by dropping the cursor:
UPDATE HumanResources.EmployeeSET VacationHours =0WHERE VacationHours <> 0
In this case, it will improve performance and decrease the time to execute a query.
STRING_CONCAT
To concatenate rows, the STRING_CONCAT could be used. However, as there is no such a function in the SQL Server, we will do this by assigning a value to the variable.
To do this, create a test table:
IF OBJECT_ID('tempdb.dbo.#t') IS NOT NULL DROP TABLE #tGOCREATE TABLE #t (i CHAR(1))INSERT INTO #tVALUES ('1'), ('2'), ('3')
Then, assign values to the variable:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tSELECT @txt--------123
Everything seems to be working fine. However, MS hints that this way is not documented and you may get this result:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tORDER BY LEN(i)SELECT @txt--------3
Alternatively, it is a good idea to use XML as a workaround:
SELECT [text()] =iFROM #tFOR XML PATH('')--------123
It should be noted that it is necessary to concatenate rows per each data, rather than into a single set of data:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'------------------------ ------------------------------------ScrapReason ScrapReasonID, Name, ModifiedDateShift ShiftID, Name, StartTime, EndTime
In addition, it is recommended that you should avoid using the XML method for parsing as it is a high-runner process:
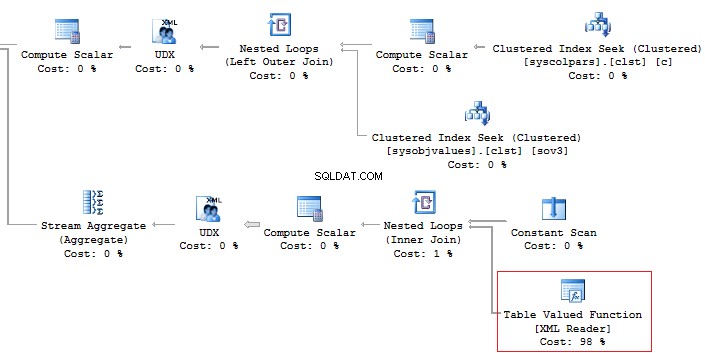
Alternatively, it is possible to do this less time-consuming:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
But, it does not change the main point.
Now, execute the query without using the value method:
SELECT t.name , STUFF(( SELECT ', ' + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
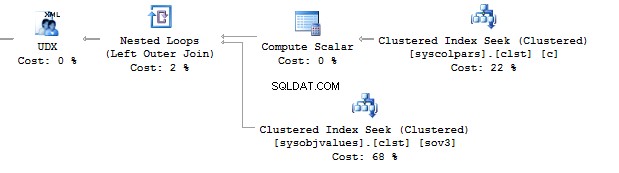
This option would work perfect. However, it may fail. If you want to check it, execute the following query:
SELECT t.name , STUFF(( SELECT ', ' + CHAR(13) + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
If there are special symbols in rows, such as tabulation, line break, etc., then we will get incorrect results.
Thus, if there are no special symbols, you can create a query without the value method, otherwise, use value(‘(./text())[1]’… .
SQL Injection
Assume we have a code:
DECLARE @param VARCHAR(MAX)SET @param =1DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =' + @paramPRINT @SQLEXEC (@SQL)
Create the query:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1
If we add any additional value to the property,
SET @param ='1; select ''hack'''
Then our query will be changed to the following construction:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1; select 'hack'
This is called SQL injection when it is possible to execute a query with any additional information.
If the query is formed with String.Format (or manually) in the code, then you may get SQL injection:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( string.Format("SELECT TOP(5) name FROM sys.objects WHERE schema_id ={0}", value), conn); using (SqlDataReader reader =command.ExecuteReader()) { while (reader.Read()) {} }}
When you use sp_executesql and properties as shown in this code:
DECLARE @param VARCHAR(MAX)SET @param ='1; select ''hack'''DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id'PRINT @SQLEXEC sys.sp_executesql @SQL , N'@schema_id INT' , @schema_id =@param
It is not possible to add some information to the property.
In the code, you may see the following interpretation of the code:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( "SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id", conn); command.Parameters.Add(new SqlParameter("schema_id", value)); ...}Summary
Working with databases is not as simple as it may seem. There are a lot of points you should keep in mind when writing T-SQL queries.
Of course, it is not the whole list of pitfalls when working with SQL Server. Still, I hope that this article will be useful for newbies.