O que faz com que a consulta de aplicação cruzada tenha um desempenho tão ruim nesse documento XML simples e um desempenho exponencialmente mais lento à medida que o conjunto de dados cresce?
É o uso do eixo pai para obter o ID do atributo do nó do item.
É essa parte do plano de consulta que é problemática.

Observe as 423 linhas que saem da função com valor de tabela inferior.
Adicionar apenas mais um nó de item com três nós de campo fornece isso.
732 linhas retornadas.
E se dobrarmos os nós da primeira consulta para um total de 6 nós de itens?
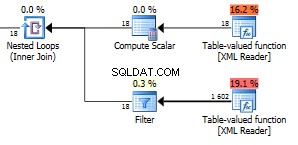
Estamos até uma enorme linha 1602 retornada.
A figura 18 na função superior são todos os nós de campo em seu XML. Temos aqui 6 itens com três campos em cada item. Esses 18 nós são usados em uma junção de loops aninhados com a outra função, de modo que 18 execuções retornando 1602 linhas fornecem 89 linhas por iteração. Esse é o número exato de nós em todo o XML. Bem, na verdade é um a mais do que todos os nós visíveis. Eu não sei por quê. Você pode usar essa consulta para verificar o número total de nós em seu XML.
select count(*)
from @XML.nodes('//*, //@*, //*/text()') as T(X)
Portanto, o algoritmo usado pelo SQL Server para obter o valor quando você usa o eixo pai
.. em uma função de valores é que ela primeiro encontra todos os nós nos quais você está destruindo, 18 no último caso. Para cada um desses nós, ele fragmenta e retorna todo o documento XML e verifica no operador de filtro o nó que você realmente deseja. Aí você tem o seu crescimento exponencial. Em vez de usar o eixo pai, você deve usar uma aplicação cruzada extra. Primeiro triturar no item e depois no campo. select I.X.value('@name', 'varchar(5)') as item_name,
F.X.value('@id', 'uniqueidentifier') as field_id,
F.X.value('@type', 'int') as field_type,
F.X.value('text()[1]', 'nvarchar(15)') as field_value
from #temp as T
cross apply T.x.nodes('/data/item') as I(X)
cross apply I.X.nodes('field') as F(X)
Também alterei como você acessa o valor de texto do campo. Usando
. fará com que o SQL Server procure por nós filhos no field e concatenar esses valores no resultado. Você não tem valores filho, então o resultado é o mesmo, mas é bom evitar ter essa parte no plano de consulta (o operador UDX). O plano de consulta não tem o problema com o eixo pai se você estiver usando um índice XML, mas ainda se beneficiará alterando a forma como busca o valor do campo.



