A resposta será, claro, "depende", mas com base em testes desse lado ...
Assumindo
- 1 milhão de produtos
producttem um índice clusterizado emproduct_id- A maioria dos produtos (se não todos) tem informações correspondentes no
product_codetabela - Índices ideais presentes em
product_codepara ambas as consultas.
O
PIVOT a versão idealmente precisa de um índice product_code(product_id, type) INCLUDE (code) enquanto o JOIN a versão idealmente precisa de um índice product_code(type,product_id) INCLUDE (code) Se estes estiverem em vigor, dando os planos abaixo
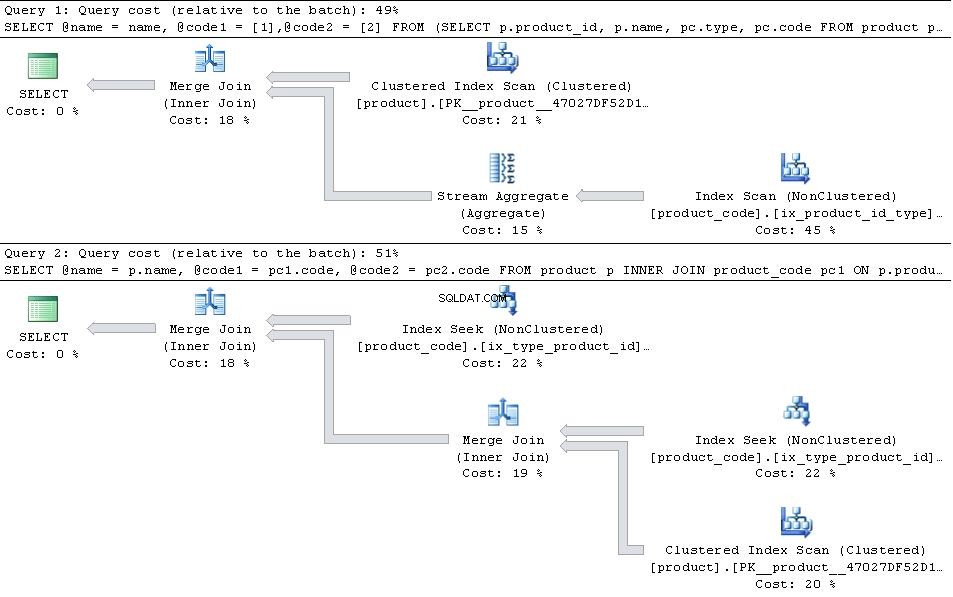
então o
JOIN versão é mais eficiente. Caso
type 1 e type 2 são os únicos types na tabela, então o PIVOT a versão tem um pouco de vantagem em termos de número de leituras, pois não precisa buscar em product_code duas vezes, mas isso é mais do que compensado pela sobrecarga adicional do operador agregado de fluxo PIVOT
Table 'product_code'. Scan count 1, logical reads 10467
Table 'product'. Scan count 1, logical reads 4750
CPU time = 3297 ms, elapsed time = 3260 ms.
PARTICIPE
Table 'product_code'. Scan count 2, logical reads 10471
Table 'product'. Scan count 1, logical reads 4750
CPU time = 1906 ms, elapsed time = 1866 ms.
Se houver
type adicionais registros diferentes de 1 e 2 o JOIN versão aumentará sua vantagem, pois apenas mescla junções nas seções relevantes do type,product_id index enquanto o PIVOT plano usa product_id, type e então teria que escanear o type adicional linhas que estão misturadas com o 1 e 2 linhas.