Neste artigo, falaremos sobre os pontos de verificação do SQL Server.
Para melhorar o desempenho, o SQL Server aplica modificações nas páginas do banco de dados na memória. Muitas vezes, essa memória é chamada de cache de buffer ou pool de buffer. O SQL Server não libera essas páginas no disco após cada alteração. Em vez disso, o mecanismo de banco de dados executa uma operação de ponto de verificação em cada banco de dados de tempos em tempos. O PONTO DE VERIFICAÇÃO A operação grava as páginas sujas (páginas modificadas na memória atuais) e também grava detalhes sobre o log de transações.
O SQL Server oferece suporte a quatro tipos de pontos de verificação:
1. Automático — Esse tipo de ponto de verificação ocorre em segundo plano e depende das configurações do servidor de intervalo de recuperação. O valor é medido em minutos, e o valor padrão é 1 minuto (não pode ser definido abaixo). O ponto de verificação será concluído no tempo que minimizar o impacto no desempenho.
EXEC sp_configure 'recovery interval', 'seconds'
No modelo de recuperação SIMPLE, um ponto de verificação automático também é acionado quando o log de transações está 70% cheio.
2. Indireto — Esse tipo de ponto de verificação também ocorre nos bastidores de acordo com as configurações de tempo de recuperação do banco de dados especificadas pelo usuário. A partir do SQL Server 2016 CTP2, o valor padrão para esse tipo de ponto de verificação é 1 minuto. Isso significa que um banco de dados usará pontos de verificação indiretos. Para versões mais antigas do SQL Server, o padrão é 0. Isso significa que um banco de dados usará pontos de verificação automáticos, cuja frequência depende da configuração do intervalo de recuperação da instância do SQL Server. A Microsoft recomenda 1 minuto para a maioria dos sistemas.
ALTER DATABASE … SET TARGET_RECOVERY_TIME =
target_recovery_time { SECONDS | MINUTES }
Ao definir isso, considere os recursos do subsistema de E/S subjacente. Pode fazer sentido definir para definir isso mais baixo para subsistemas de E/S mais rápidos (por exemplo, SSDs). Tenha cuidado, essa configuração persiste por meio de backup e restauração, portanto, a restauração para um hardware mais lento pode causar problemas de desempenho ao gerar muita carga de E/S.
3. Manual — Ocorre durante a execução do comando T-SQL CHECKPOINT.
CHECKPOINT [ checkpoint_duration ]
checkpoint_duration é um número inteiro usado para definir a quantidade de tempo em que um ponto de verificação deve ser concluído. Esse parâmetro também controla quantos recursos são atribuídos à operação de ponto de verificação. Se o parâmetro não for especificado, o ponto de verificação será concluído no tempo que minimizar o impacto no desempenho.
4. Interno — Algumas operações do SQL Server emitem esse tipo de ponto de verificação para garantir que as imagens de disco correspondam ao estado atual do log de transações. Estes são pontos de verificação que são executados quando uma determinada operação ocorre:
- Um arquivo de dados é adicionado ou removido
- Ocorre um desligamento do banco de dados (por qualquer motivo)
- Um backup ou instantâneo do banco de dados é criado
- É executado um comando DBCC que cria um instantâneo de banco de dados oculto (ou, por exemplo, DBCC_CHECKDB, DBCC_CHECKTABLE).
Por que os checkpoints são úteis?
Os pontos de verificação reduzem o tempo de recuperação de falhas. Isso acontece porque as páginas do arquivo de dados não são gravadas no disco ao mesmo tempo que os registros de log. Existem páginas de arquivos de dados na memória que são mais atualizadas do que as páginas de arquivos de dados em disco.
Os pontos de verificação reduzem a E/S no disco e melhoram o desempenho. O motivo pelo qual as páginas do arquivo de dados não são gravadas no disco no momento da confirmação da transação é para reduzir o número de operações de E/S. Imagine os vários milhares de transações UPDATE para uma única página de dados. É mais eficiente gravar uma página de dados no disco apenas uma vez, durante um ponto de verificação, do que após cada alteração.
Páginas limpas e sujas
O conjunto de buffers mantém várias páginas de dados na memória. Existem dois tipos de páginas de dados:limpas e sujo . Uma página limpa é aquela que não foi alterada desde que foi a última leitura do disco ou gravada no disco. Uma página suja é uma página que foi alterada e as alterações não foram gravadas no disco. Os pontos de verificação referem-se a “páginas sujas”.
As informações sobre a página podem ser vistas usando sys.dm_os_buffer_descriptors . Vamos ver o que esta função retorna:
SELECT * FROM sys.dm_os_buffer_descriptors dobd; GO
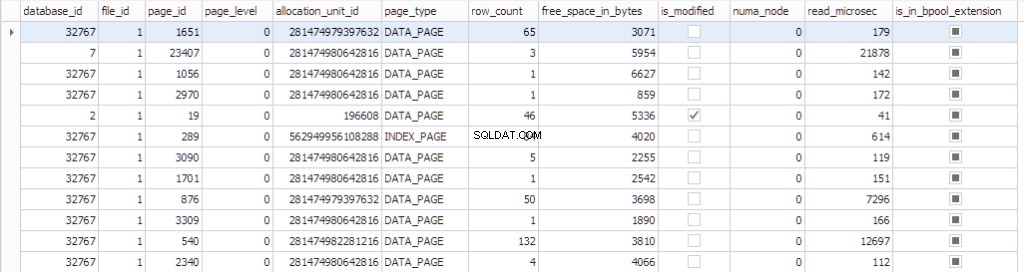
Cada página tem uma estrutura de controle associada a ela que rastreia o estado da página:
- Um banco de dados com o datdabase_id 32767 é um banco de dados de recursos somente leitura que contém todos os objetos do sistema.
- file_id , page_id , allocation_unit_id essa página pertence.
- Que tipo de página é:página de dados ou página de índice.
- O número de linhas na página.
- O espaço livre na página
- Se a página está suja ou não
- O numa_node ao qual a página específica pertence
- Algumas informações sobre o algoritmo usado recentemente
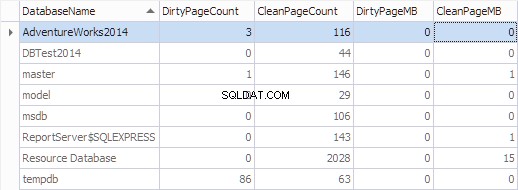
Vamos agregar essas informações por banco de dados usando o seguinte código:
SELECT
*,
[DirtyPageCount] * 8 / 1024 AS [DirtyPageMB],
[CleanPageCount] * 8 / 1024 AS [CleanPageMB]
FROM (SELECT
(CASE
WHEN ([database_id] = 32767) THEN N'Resource Database'
ELSE DB_NAME([database_id])
END) AS [DatabaseName],
SUM(CASE
WHEN ([is_modified] = 1) THEN 1
ELSE 0
END) AS [DirtyPageCount],
SUM(CASE
WHEN ([is_modified] = 1) THEN 0
ELSE 1
END) AS [CleanPageCount]
FROM sys.dm_os_buffer_descriptors
GROUP BY [database_id]) AS [buffers]
ORDER BY [DatabaseName]
GO
Mecanismo de ponto de verificação
Quando o ponto de verificação ocorre, ele grava todas as páginas sujas no disco. Páginas marcadas como sujas assim que tiverem algumas alterações. Não importa se a transação que fez a alteração foi confirmada ou não confirmada no momento do ponto de verificação. Após as páginas terem sido gravadas no disco, o bit “sujo” é apagado. Quando o ponto de verificação ocorre, as seguintes ações ocorrem:
- Um novo registro de log indica o início de um ponto de verificação
- Registros de log adicionais aparecem com informações de ponto de verificação (como o estado do log de transações no momento em que o ponto de verificação é iniciado)
- Todas as páginas sujas são gravadas no disco
- Marque o LSN do ponto de verificação na página de inicialização do banco de dados (no dbi_checkptLSN), isso é fundamental para a recuperação de falhas
- Se o modelo de recuperação SIMPLE for usado, tente limpar o log
- Um registro de log final indica que o ponto de verificação foi concluído
É possível que os pontos de verificação de vários bancos de dados ocorram em paralelo. O SQL Server 2000 estava limitado a um ponto de verificação por vez. Quando o gerenciador de buffer grava uma página, ele procura páginas sujas adjacentes que podem ser incluídas em uma única operação de coleta e gravação. Além disso, o pool de buffers tentará garantir que não sobrecarregue o subsistema de E/S. Ele mantém o controle de quanto tempo leva para a E/S ser concluída. Se a latência de gravação exceder 20 ms durante o ponto de verificação, ela se estrangulará. Durante o desligamento, o limite de estrangulamento aumenta para 100 ms. Você pode encontrar uma explicação mais detalhada aqui. Você pode usar a opção de inicialização “-kXX” não documentada para definir a taxa de E/S do ponto de verificação em XX MB/s.
Quando a página do arquivo de dados é gravada no disco por um ponto de verificação, o log de gravação antecipada garante que todos os registros de log que afetam essa página sejam gravados primeiro no log de transações no disco. Todos os registros de log até e incluindo o último que afetou a página são gravados, independentemente de qual transação eles fazem parte. Os registros de log são escritos de três maneiras:
- Quando qualquer transação é confirmada ou abortada
- Quando a página do arquivo de dados é gravada no disco
- Quando um bloco de log atinge o tamanho máximo de 60 KB e é encerrado à força
Registro de registro de ponto de verificação
Os pontos de verificação gravam vários registros de log no log de transações:
- LOP_BEGIN_CKPT — significa que o ponto de verificação foi iniciado
- LOP_XACT_CKPT com contexto NULL (somente se houver transações não confirmadas no momento em que o ponto de verificação foi iniciado) — contém uma contagem do número de transações não confirmadas. Ele também lista os LSNs dos registros de log LOP_BEGIN_XACT das transações não confirmadas.
- LOP_BEGIN_CKPT com um contexto de LOP_BOOT_PAGE_CKPT (somente SQL Server 2012) — significa que a página de inicialização foi atualizada.
- LOP_END_CKPT — significa o fim do checkpoint.
Monitoramento de pontos de verificação
Pode ser útil correlacionar pontos de verificação que ocorrem com picos de E/S para que as alterações possam ser feitas no banco de dados específico (para o subsistema de E/S) para aliviar o pico de E/S se sobrecarregar o subsistema de E/S. Por exemplo, fazer pontos de verificação manuais mais frequentes ou configurar um intervalo de recuperação mais baixo no SQL Server 2012 com pontos de verificação indiretos. Isso produzirá uma carga de E/S mais constante sem picos altos que sobrecarregam o subsistema de E/S. No entanto, a causa raiz pode ser mais E/S sendo executada devido a uma alteração em algum lugar, portanto, não aceite apenas um aumento repentino na atividade do ponto de verificação sem investigar por que ocorreu.
O contador de páginas/s do Gerenciador de buffer/ponto de verificação não é específico do banco de dados, portanto, identificar qual banco de dados está envolvido requer sinalizadores de rastreamento ou eventos estendidos.
Sinalizador de rastreamento 3502 grava mensagens no log de erros sobre qual ponto de verificação do banco de dados está ocorrendo.
Sinalizador de rastreamento 3504 grava informações mais detalhadas sobre quantas páginas foram gravadas e a latência média de gravação.
Esses sinalizadores de rastreamento são seguros para uso na produção por um tempo limitado. Tudo o que eles fazem é imprimir mensagens no log de erros.
Se você quiser usar eventos estendidos, há dois eventos que você pode usar:checkpoint_begin e checkpoint_end.
Resumo
Neste artigo, falamos sobre pontos de verificação no SQL Server — o principal mecanismo para gravar páginas de arquivos de dados em disco depois que eles foram alterados.