A replicação de banco de dados é a tecnologia para distribuir dados do servidor primário para os servidores secundários. A replicação funciona no conceito mestre-escravo, onde o banco de dados mestre distribui dados para um ou vários servidores escravos. A replicação pode ser configurada entre várias instâncias do SQL Server no mesmo servidor, OU pode ser configurada entre vários servidores de banco de dados dentro dos mesmos data centers ou separados geograficamente.
Há dois benefícios principais de usar a replicação do SQL Server:
- Usando a replicação, podemos obter dados quase em tempo real que podem ser usados para fins de relatório. Por exemplo, quando você deseja separar a carga de OLTP com uso intenso de gravação em um servidor e a carga com uso intenso de leitura em outro servidor, você pode configurar a replicação para manter os dados sincronizados em ambos os servidores.
- O segundo benefício é que você pode agendar a replicação para ser executada em um horário específico. Por exemplo, se você quiser que o servidor de relatório contenha dados do dia concluído, poderá agendar o instantâneo de replicação adequadamente. Não precisamos escrever lógica adicional para lidar com os dados atuais.
A replicação oferece muita flexibilidade. Usando a replicação, podemos filtrar as linhas e também podemos replicar o subconjunto de dados de qualquer tabela. Podemos alterar os dados replicados ou replicar apenas atualizar e inserir e ignorar as exclusões. Também podemos replicar os dados de outro sistema de banco de dados como o Oracle.
Componentes de replicação
Há sete componentes principais da Replicação do SQL Server. Segue a lista:
- Editora.
- Distribuidor.
- Assinante.
- Artigos.
- Publicação.
- Enviar assinatura.
- Puxar assinatura.
Seguem os detalhes:
Artigos
Um artigo é um objeto de banco de dados, como uma tabela SQL ou um procedimento armazenado. Como mencionei acima, usando a Replicação, podemos filtrar os dados ou replicar a coluna da tabela selecionada, portanto, as colunas ou linhas da tabela são consideradas artigos.
Publicação
Os artigos não podem ser replicados até que se tornem parte da publicação. Publicação é o grupo dos objetos Artigos/Banco de Dados. Ele também representa o conjunto de dados que será replicado pelo SQL Server.
Editora
O Publisher contém um banco de dados mestre que contém os dados que precisam ser publicados. Ele determina quais dados devem ser distribuídos por todos os assinantes.
Distribuidor
O distribuidor é a ponte entre o editor e o assinante. O Distribuidor reúne todos os dados publicados e os mantém até enviar para todos os assinantes. É uma ponte entre o editor e o assinante. Ele suporta vários editores e conceito de assinante. Não é obrigatório configurar o distribuidor em uma instância SQL separada ou em um servidor separado. Se não o configurarmos, o editor poderá atuar como distribuidor. As organizações que têm replicação em grande escala podem configurar o distribuidor em um sistema separado.
Assinantes
O assinante é o fim da fonte ou o destino para o qual os dados ou a publicação replicada serão transmitidos. Na replicação, existe um editor, podendo ter vários assinantes.
Enviar assinatura
Em uma assinatura push, o editor atualiza os dados para o assinante. Em uma assinatura Push, o assinante é passivo. A editora envia artigos ou publicações a todos os seus assinantes. Com base no requisito da organização, no assistente de criação de replicação, na tela, você pode selecionar a assinatura a ser usada. A replicação de transações e a replicação ponto a ponto usam a assinatura Push para manter a disponibilidade dos dados em tempo real.
Puxar assinatura
Em uma assinatura Pull, todos os assinantes solicitam os novos dados ou dados atualizados de seu editor. Em uma assinatura pull, podemos controlar quais dados ou alterações de dados são necessários para os assinantes. É útil quando não precisamos dos dados alterados imediatamente.
Tipos de replicação
O SQL Server oferece suporte a três tipos de replicação:
- Replicação transacional.
- Replicação de instantâneos.
- Mesclar replicação.
Replicação Transacional
Replicação transacional, quaisquer alterações de esquema, alterações de dados que ocorram no banco de dados do editor serão replicadas no banco de dados do assinante. Sempre que qualquer operação de atualização, exclusão ou inserção ocorre no banco de dados do editor, as alterações são rastreadas e essas alterações são enviadas para os bancos de dados do assinante. A replicação transacional envia apenas uma quantidade limitada de dados por uma rede. Além disso, as alterações são quase em tempo real, portanto, podem ser usadas para configurar o site de DR ou para dimensionar as operações de relatório. A replicação transacional é ideal para as seguintes situações:
- Quando você deseja configurar um sistema em que as alterações feitas no editor devem ser aplicadas aos assinantes imediatamente.
- O editor tem INSERT, UPDATES e DELETES alto e baixo.
- Quando você deseja configurar o significado de replicação heterogênea, editor ou assinante para bancos de dados não SQL Server, como Oracle.
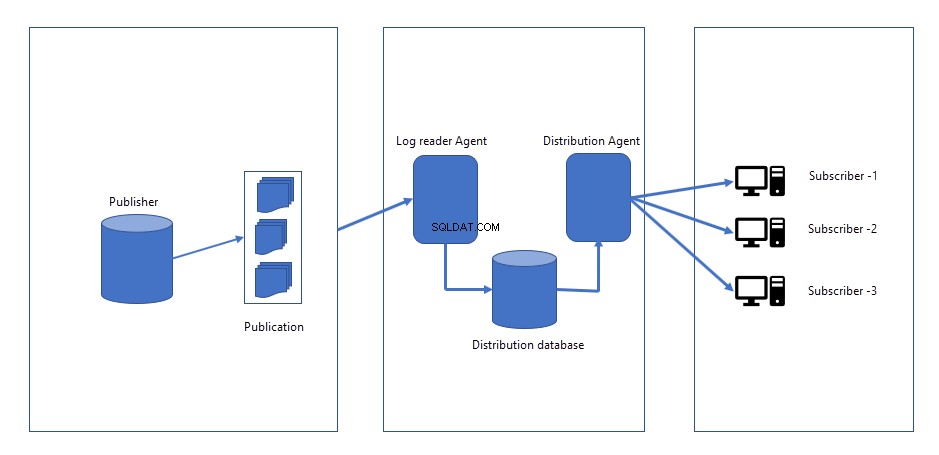
Quando quaisquer alterações são feitas no banco de dados do editor, as alterações são registradas em um arquivo de log no banco de dados do editor. Site do Distribuidor/Editor, dois trabalhos serão criados.
- Agente de instantâneo :O trabalho do agente de instantâneo gera o instantâneo do esquema, dados dos objetos que queremos replicar ou publicar. Os arquivos do instantâneo podem ser salvos no servidor Publicador ou no local da rede. Quando iniciamos a replicação pela primeira vez, ela cria um instantâneo e o aplica a todos os assinantes. O agente de instantâneo permanece ocioso até que seja acionado manualmente ou programado para ser executado em um horário específico.
- Agente do leitor de registros :O trabalho do agente do leitor de log é executado continuamente. Ele lê as alterações (INSERT, UPDATES e DELETES) ocorridas no log de transações do banco de dados do editor e as envia para um agente de distribuição.
- Agente de distribuição :depois que as alterações são recuperadas do agente do leitor de log, o agente de distribuição envia todas as alterações para os assinantes.
Quando configuramos a replicação transacional, ela realiza as seguintes atividades
- Ele inicia tirando o primeiro instantâneo de dados de publicação e objetos de banco de dados e o instantâneo aplicado aos assinantes.
- O agente leitor de logs monitora continuamente o T-Log do editor e, caso ocorra alguma alteração, ele os envia ao distribuidor ou diretamente aos assinantes.
A imagem a seguir representa como funciona a replicação transacional:
Vantagens:
- A replicação de transações pode ser usada como um servidor SQL em espera ou pode ser usada para balanceamento de carga ou separação do sistema de relatórios e do sistema OLTP.
- O servidor do editor replica dados para o servidor do assinante com baixa latência.
- Usando a replicação transacional, a replicação em nível de objeto pode ser implementada.
- A replicação transacional pode ser aplicada quando você tem menos dados para proteger e deve ter um plano de recuperação de dados rápido.
Desvantagens:
- Depois que a replicação é estabelecida, as alterações de esquema no editor não se aplicam ao servidor do assinante. Devemos fazer essas alterações manualmente gerando um novo instantâneo e aplicando-o aos assinantes.
- Se alterarmos os servidores, devemos reconfigurar a replicação.
- Se a replicação transacional for usada como configuração de DR, teremos que fazer o failover manualmente.
Replicação de instantâneo
A replicação de instantâneos gera uma imagem/instantâneo completo da publicação em uma programação definida e envia os arquivos de instantâneos aos assinantes. Quando ocorrer a replicação de instantâneo, os dados de destino serão substituídos por um novo instantâneo. A replicação de instantâneo é a melhor opção quando os dados são menos voláteis. Por exemplo, tabelas mestras como City, Zipcode, Pincode são as melhores candidatas para replicação de snapshots.
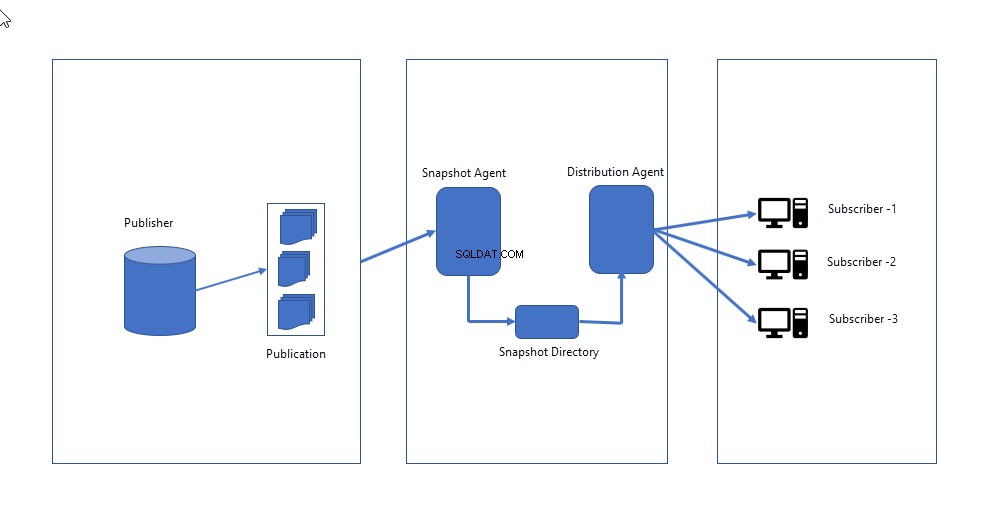
Ao configurar a replicação de instantâneos, os seguintes componentes importantes são definidos:
- Agente de instantâneo :Cria uma imagem completa do esquema e dos dados definidos na publicação e envia para o distribuidor. O agente de instantâneo permanece ocioso até que seja acionado manualmente OU programado para ser executado em um horário específico.
- Agente distribuidor :ele envia os arquivos de instantâneo aos assinantes e aplica o esquema e os dados substituindo o existente.
A replicação de instantâneo executa as seguintes atividades:
- Na programação definida, o agente de instantâneo coloca um bloqueio compartilhado no esquema e nos dados a serem publicados.
- Snapshot inteiro dos dados publicados copiados para o distribuidor. O agente de instantâneo cria três arquivos
- Arquivo para o esquema de banco de dados criado de dados publicados.
- Arquivo BCP para exportar dados em tabelas SQL
- Arquivos de índice para exportar dados de índice.
- Depois que os arquivos são criados, o agente de instantâneo libera bloqueios compartilhados em dados e dados publicados.
- Os agentes distribuidores iniciam e substituem o esquema e os dados do assinante usando arquivos criados pelo agente de instantâneo.
A imagem a seguir ilustra como funciona a replicação de instantâneo.
Vantagens
- A replicação de instantâneos é muito simples de configurar. Se os dados não forem alterados com frequência, a replicação de snapshots é uma opção muito adequada.
- Você pode controlar quando enviar dados. Por exemplo, uma tabela mestra que tem um grande volume de dados, mas muda com menos frequência do que você pode replicar os dados quando o tráfego é baixo.
Desvantagens
- O instantâneo gerado pelo agente de instantâneo contém dados publicados alterados e inalterados, portanto, o instantâneo transmitido pela rede pode produzir latência e afetar outras operações.
- À medida que os dados aumentam, o tamanho do instantâneo aumenta e leva mais tempo para criar e distribuir o instantâneo aos assinantes.
Mesclar replicação
A replicação de mesclagem pode ser usada quando precisamos gerenciar alterações em vários servidores e essas alterações precisam ser consolidadas.
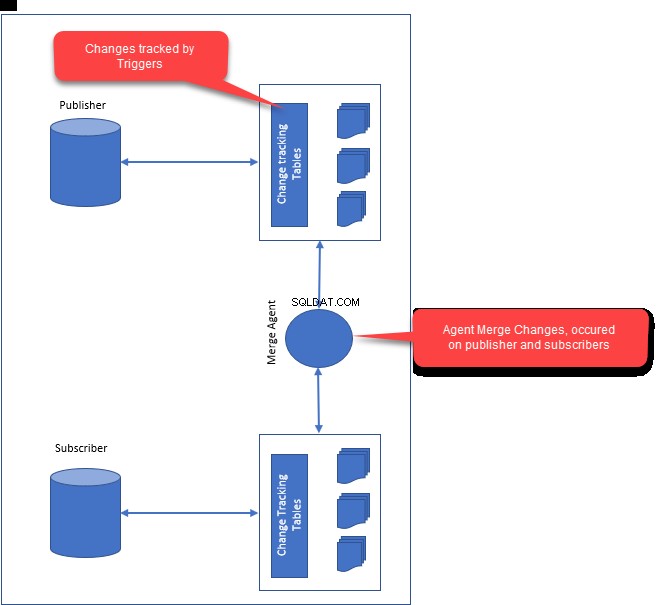
Ao configurar a replicação de mesclagem, os seguintes componentes serão criados:
- Agente de instantâneo :o agente de instantâneo gera o primeiro instantâneo de dados de publicação e objetos de banco de dados. Depois que o instantâneo for criado, ele será distribuído a todos os assinantes.
- Agente de mesclagem :O agente de mesclagem é responsável por resolver os conflitos entre o editor e os assinantes. Quaisquer conflitos são resolvidos por meio do agente de mesclagem que usa a resolução de conflitos. Dependendo de como você configurou a resolução de conflitos, os conflitos são resolvidos pelo agente de mesclagem.
Quando configuramos a replicação de mesclagem, ela realiza as seguintes atividades:
- Ele inicia tirando um instantâneo de dados de publicação e objetos de banco de dados e um instantâneo aplicado aos assinantes.
- Ao configurar a replicação de mesclagem, ele cria acionadores no editor e no assinante. Os acionadores são responsáveis por acompanhar as alterações subsequentes e as modificações de tabela no editor e nos assinantes.
- Quando o editor e os assinantes se conectam à rede, as alterações das linhas de dados e a modificação do esquema serão sincronizadas entre si. Ao mesclar as alterações do editor e dos assinantes, o agente de mesclagem resolve os conflitos com base nas condições definidas no agente de mesclagem.
A replicação de mesclagem é usada em ambientes de servidor para cliente e é ideal para as situações em que os assinantes precisam recuperar dados do publicador, fazer alterações off-line e sincronizar as alterações com o publicador e outros assinantes.
Pode haver situações práticas em que a mesma linha seja alterada por diferentes editores e assinantes. Nesse momento, o agente de mesclagem analisará qual resolução de conflito está definida e fará as alterações apropriadas.
O SQL Server identifica exclusivamente uma coluna usando um identificador globalmente exclusivo para cada linha em uma tabela publicada. Se a tabela já tiver uma coluna de identificador exclusivo, o SQL Server usará automaticamente essa coluna. Caso contrário, ele adicionará uma coluna rowguid na tabela e criará um índice com base na coluna.
Os gatilhos serão criados nas tabelas publicadas em editores e assinantes. Eles são usados para rastrear as alterações com base nas alterações de linha ou coluna.
A imagem a seguir ilustra como funciona a replicação de mesclagem:
Vantagens:
- Esta é a única maneira de consolidar as alterações nos dados de vários servidores.
Desvantagens:
- Demora muito tempo para replicar e sincronizar ambas as extremidades.
- Há baixa consistência, pois muitas partes devem ser sincronizadas.
- Pode haver conflitos ao mesclar a replicação se as mesmas linhas forem afetadas em mais de um assinante e editor. Ele pode ser corrigido usando a resolução de conflitos, mas torna a configuração da replicação mais complicada.
Código T-SQL para revisar a configuração de replicação
Configurei a replicação de instantâneo e a replicação transacional em duas instâncias da minha máquina. Usando o gerenciamento dinâmico de SQL (DMVs), podemos verificar a configuração da replicação. Para revisar a configuração da replicação, podemos usar o código T-SQL. O código de script preenche o seguinte:
- Nome do banco de dados do assinante.
- Nome do editor.
- Tipo de assinatura.
- Banco de dados do editor.
- Nome do agente de replicação.
Abaixo segue o roteiro:
SELECT DistributionAgent.subscriber_db [Subscriber DB], DistributionAgent.publication [PUB Name], RIGHT(LEFT(DistributionAgent.NAME, Len(DistributionAgent.NAME) - ( Len( DistributionAgent.id) + 1 )), Len(LEFT( DistributionAgent.NAME, Len(DistributionAgent.NAME) - ( Len( DistributionAgent.id) + 1 ))) - ( 10 + Len(DistributionAgent.publisher_db) + ( CASE WHEN DistributionAgent.publisher_db = 'ALL' THEN 1 ELSE Len( DistributionAgent.publication) + 2 END ) )) [SUBSCRIBER], ( CASE WHEN DistributionAgent.subscription_type = '0' THEN 'Push' WHEN DistributionAgent.subscription_type = '1' THEN 'Pull' WHEN DistributionAgent.subscription_type = '2' THEN 'Anonymous' ELSE Cast(DistributionAgent.subscription_type AS VARCHAR) END ) [Subscrition Type], DistributionAgent.publisher_db + ' - ' + Cast(DistributionAgent.publisher_database_id AS VARCHAR) [Publisher Database], DistributionAgent.NAME [Pub - DB - Publication - SUB - AgentID] FROM distribution.dbo.msdistribution_agents DistributionAgent WHERE DistributionAgent.subscriber_db <> 'virtual'
Segue a saída:

Resumo
Neste artigo, expliquei:
- O fundamento e os benefícios da Replicação e seus componentes.
- Replicação transacional.
- Replicação de instantâneo.
- Mesclar replicação.



