Os bancos de dados relacionais representam os dados de uma organização em tabelas que usam colunas com diferentes tipos de dados, permitindo armazenar valores válidos. Desenvolvedores e DBAs precisam conhecer e entender o tipo de dados apropriado para cada coluna para obter um melhor desempenho de consulta.
Este artigo tratará dos tipos de dados populares VARCHAR() e NVARCHAR(), sua comparação e revisões de desempenho no SQL Server.
VARCHAR [ ( n | máximo ) ] em SQL
O VARCHAR tipo de dados representa o não-Unicode tipo de dados string de comprimento variável. Você pode armazenar letras, números e caracteres especiais nele.
- N representa o tamanho da string em bytes.
- A coluna de tipo de dados VARCHAR armazena no máximo 8.000 caracteres não Unicode.
- O tipo de dados VARCHAR leva 1 byte por caractere. Se você não especificar explicitamente o valor de N, será necessário um armazenamento de 1 byte.
Observação:não confunda N com um valor que representa o número de caracteres em uma string.
A consulta a seguir define o tipo de dados VARCHAR com 100 bytes de dados.
DECLARE @text AS VARCHAR(100) ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Ele retorna o comprimento como 17 por causa de 1 byte por caractere, incluindo um caractere de espaço.
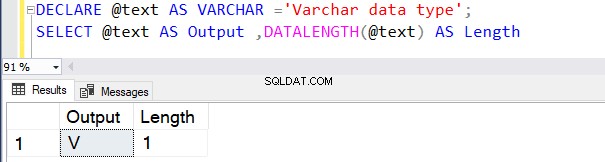
A consulta a seguir define o tipo de dados VARCHAR sem nenhum valor de N . Portanto, o SQL Server considera o valor padrão como 1 byte, conforme mostrado abaixo.
DECLARE @text AS VARCHAR ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Também podemos usar VARCHAR usando a função CAST ou CONVERT. Por exemplo, nos dois exemplos abaixo, declaramos uma variável com 100 bytes de comprimento e depois usamos o operador CAST.
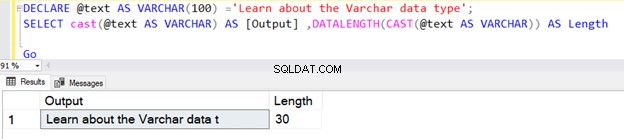
A primeira consulta retorna o comprimento como 30 porque não especificamos N no tipo de dados VARCHAR do operador CAST. O comprimento padrão é 30.
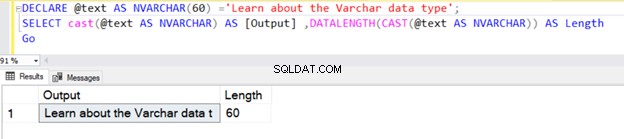
DECLARE @text AS VARCHAR(100) ='Learn about the VARCHAR data type';
SELECT cast(@text AS VARCHAR) AS [Output] ,DATALENGTH(CAST(@text AS VARCHAR)) AS Length
Go
No entanto, se o comprimento da string for menor que 30, ele assumirá o tamanho real da string.

NVARCHAR [ ( n | máximo ) ] em SQL
O NVARCHAR tipo de dados é para o Unicode tipo de dados de caractere de comprimento variável. Aqui, N refere-se ao Conjunto de Caracteres do Idioma Nacional e é usado para definir a string Unicode. Você pode armazenar caracteres não Unicode e Unicode (Kanji japonês, Hangul coreano, etc.).
- N representa o tamanho da string em bytes.
- Ele pode armazenar no máximo 4.000 caracteres Unicode e não Unicode.
- O tipo de dados VARCHAR leva 2 bytes por caractere. São necessários 2 bytes de armazenamento se você não especificar nenhum valor para N.
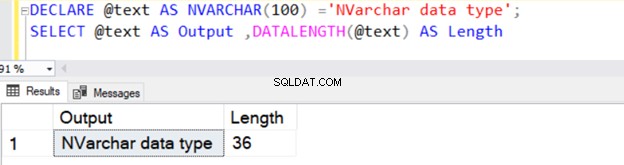
A consulta a seguir define o tipo de dados VARCHAR com 100 bytes de dados.
DECLARE @text AS NVARCHAR(100) ='NVARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Ele retorna o comprimento da cadeia de 36 porque NVARCHAR leva 2 bytes por armazenamento de caractere.
Semelhante ao tipo de dados VARCHAR, NVARCHAR também possui um valor padrão de 1 caractere (2 bytes) sem especificar um valor explícito para N.
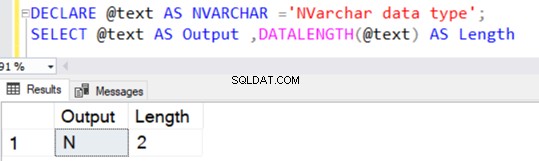
Se aplicarmos a conversão NVARCHAR usando a função CAST ou CONVERT sem nenhum valor explícito de N, o valor padrão é de 30 caracteres, ou seja, 60 bytes.
Armazenando os valores Unicode e não Unicode no tipo de dados VARCHAR
Suponha que tenhamos uma tabela que registre o feedback do cliente de um portal de compras eletrônicas. Para isso, temos uma tabela SQL com a seguinte consulta.
CREATE TABLE UserComments
(
ID int IDENTITY (1,1),
[Language] VARCHAR(50),
[comment] VARCHAR(200),
[NewComment] NVARCHAR(200)
)
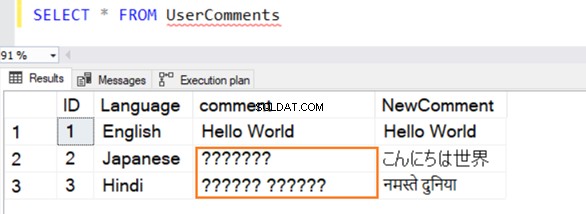
Inserimos vários registros de amostra nesta tabela em inglês, japonês e hindi. O tipo de dados para [Comentário] é VARCHAR e [NewComment] é NVARCHAR() .
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('English','Hello World', N'Hello World')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Japanese','こんにちは世界', N'こんにちは世界')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Hindi','नमस्ते दुनिया', N'नमस्ते दुनिया')
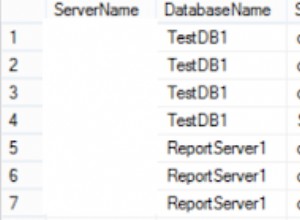
A consulta é executada com sucesso e fornece as seguintes linhas ao selecionar um valor dela. Para as linhas 2 e 3, ele não reconhece dados se não estiverem em inglês.
Tipos de dados VARCHAR e NVARCHAR:comparação de desempenho
Não devemos misturar o uso dos tipos de dados VARCHAR e NVARCHAR nos predicados JOIN ou WHERE. Ele invalida os índices existentes porque o SQL Server requer os mesmos tipos de dados em ambos os lados de JOIN. SQL Server tenta fazer a conversão implícita usando a função CONVERT_IMPLICIT() em caso de incompatibilidade.
O SQL Server usa a precedência do tipo de dados para determinar qual é o tipo de dados de destino. NVARCHAR tem precedência mais alta que o tipo de dados VARCHAR. Portanto, durante a conversão do tipo de dados, o SQL Server converte os valores VARCHAR existentes em NVARCHAR.
CREATE TABLE #PerformanceTest
(
[ID] INT NOT NULL IDENTITY(1, 1) PRIMARY KEY,
[Col1] VARCHAR(50) NOT NULL,
[Col2] NVARCHAR(50) NOT NULL
)
CREATE INDEX [ix_performancetest_col] ON #PerformanceTest (col1)
CREATE INDEX [ix_performancetest_col2] ON #PerformanceTest (col2)
INSERT INTO #PerformanceTest VALUES ('A',N'C')
Agora, vamos executar duas instruções SELECT que recuperam registros de acordo com seus tipos de dados.
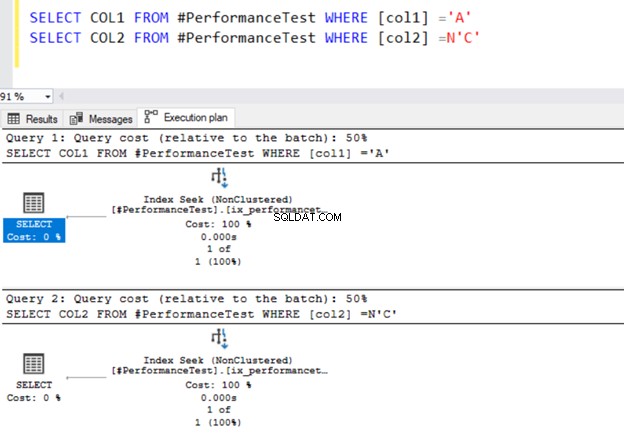
SELECT COL1 FROM #PerformanceTest WHERE [col1] ='A'
SELECT COL2 FROM #PerformanceTest WHERE [col2] =N'C'
Ambas as consultas usam o Operador de busca de índice e os índices que definimos anteriormente.
Agora, alternamos os valores do tipo de dados para comparação com o predicado WHERE. A coluna 1 tem um tipo de dados VARCHAR, mas especificamos N'A' para colocá-lo como tipo de dados NVARCHAR.
Da mesma forma, col2 é o tipo de dados NVARCHAR e especificamos o valor ‘C’ que se refere ao tipo de dados VARCHAR.
SELECT COL2 FROM #PerformanceTest WHERE [col2] ='C'No plano de execução real da consulta, você obtém uma varredura de índice e a instrução SELECT tem um símbolo de aviso.
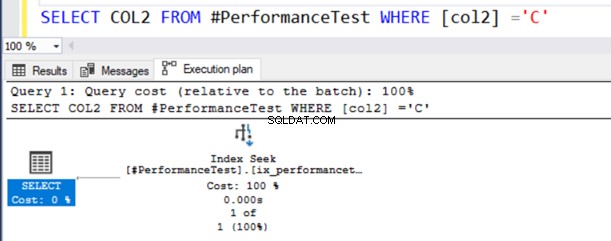
Essa consulta funciona bem porque o tipo de dados NVARCHAR() pode ter valores Unicode e não Unicode.
Agora, a segunda consulta usa uma varredura de índice e emite um símbolo de aviso no operador SELECT.
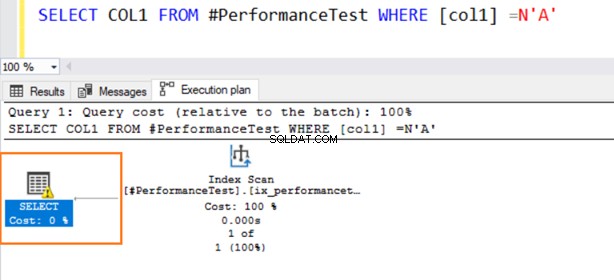
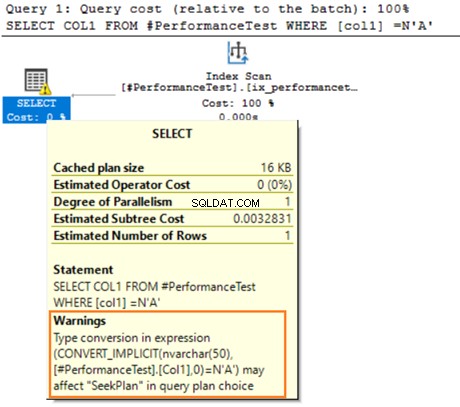
Passe o mouse sobre a instrução SELECT que emite um aviso sobre a conversão implícita. O SQL Server não pôde usar o índice existente corretamente. Isso se deve aos diferentes algoritmos de classificação de dados para os tipos de dados VARCHAR e NVARCHAR.
Se a tabela tiver milhões de linhas, o SQL Server precisará fazer trabalho adicional e converter dados usando a conversão de dados implicitamente. Isso pode afetar negativamente o desempenho da sua consulta. Portanto, você deve evitar misturar e combinar esses tipos de dados na otimização das consultas.
Conclusão
Você deve revisar seus requisitos de dados ao projetar tabelas de banco de dados e seus tipos de dados de colunas adequadamente. Normalmente, o tipo de dados VARCHAR atende a maioria de seus requisitos de dados. No entanto, se você precisar armazenar tipos de dados Unicode e não Unicode em uma coluna, considere usar o NVARCHAR. No entanto, você deve revisar sua implicação de desempenho e tamanho de armazenamento antes de tomar a decisão final.