A instalação do SQL Server por padrão cria vários bancos de dados do sistema por instância para manter e administrar essa instância. Neste artigo, examinaremos esses bancos de dados do sistema e entenderemos suas responsabilidades.
Bancos de dados do sistema SQL Server
No SQL Server, os bancos de dados do sistema são criados durante o processo de instalação para armazenar os detalhes de configuração específicos da instância do SQL Server para funcionar normalmente. Cada instalação do SQL Server cria um mínimo de 5 bancos de dados do sistema e 1 banco de dados do sistema relacionado à replicação chamado banco de dados de distribuição que será criado pelos usuários se a Replicação estiver configurada nessa instância. Cada banco de dados do sistema tem sua finalidade e investigaremos isso em detalhes mais adiante neste artigo.
Os bancos de dados do sistema são:
- Mestre – Instalado por padrão
- Msdb – Instalado por padrão
- Modelo – Instalado por padrão
- Tempdb – Instalado por padrão
- Recurso – Instalado por padrão . Introduzido no SQL Server 2005 e disponível em versões posteriores do SQL Server e, portanto, não disponível no SQL Server 2000 e versões anteriores.
- Distribuição – Criado por ação do usuário . Os usuários podem criar o banco de dados de distribuição para configurar a Replicação.
Para visualizar o banco de dados do sistema instalado no SQL Server, podemos usar o SSMS.
Conecte-se à sua instância do SQL Server, expanda Bancos de dados > Bancos de dados do sistema :
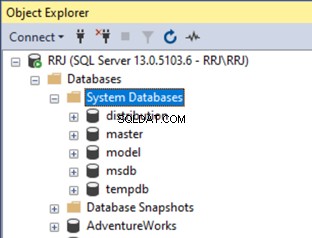
Você notou que o Recurso banco de dados está faltando na lista acima? O problema é que o banco de dados de recursos é um banco de dados de sistema especial que não está listado no SSMS Object Explorer. No entanto, podemos consultar os detalhes do banco de dados de recursos de um DMV do sistema chamado sys.sysaltfiles e execute a consulta:
SELECT dbid, db_name(dbid) database_name, fileid, name, filename
FROM sys.sysaltfiles
WHERE dbid NOT BETWEEN 5 AND 11
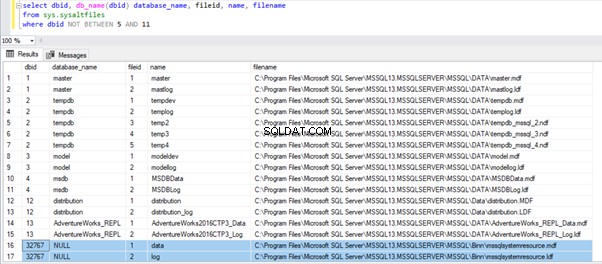
Nos resultados, podemos ver os bancos de dados do sistema na ordem:master, tempdb, model, msdb, distribution , e, finalmente, o dbid 32767 que é um banco de dados de recursos. No entanto, esse banco de dados de recursos não exibe nenhum nome de banco de dados, pois não possui uma entrada em sys.databases . Excluí alguns bancos de dados de usuários entre dbid 5 e 11 e incluí AdventureWorks_REPL como exemplo para mostrar que o DMV também pode exibir bancos de dados de usuários. Entraremos em mais detalhes sobre o banco de dados de recursos e outros bancos de dados do sistema posteriormente.
Restrições de bancos de dados do sistema SQL
Como os bancos de dados do sistema contêm detalhes críticos de configuração do sistema, deve haver medidas de segurança adequadas para evitar a exclusão acidental de dados. Portanto, os bancos de dados do sistema têm as restrições abaixo em comparação com os bancos de dados do usuário:
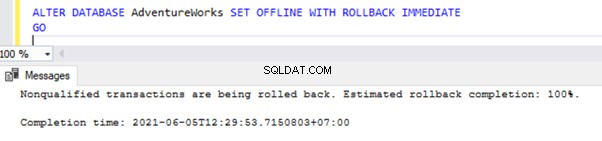
Bancos de dados do sistema não podem ser colocados off-line
Podemos colocar um banco de dados de usuário offline usando o comando ALTER DATABASE conforme mostrado abaixo:
ALTER DATABASE AdventureWorks SET OFFLINE WITH ROLLBACK IMMEDIATE
GO
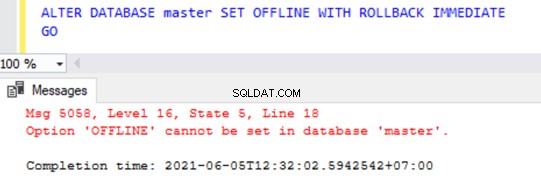
No entanto, se tentarmos colocar qualquer um dos bancos de dados do sistema OFFLINE usando o comando acima, receberemos um erro conforme mostrado abaixo:
Bancos de dados do sistema não podem ser descartados
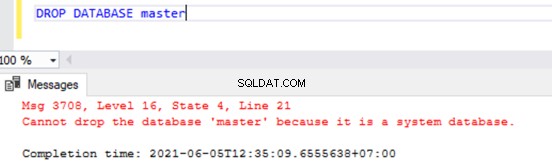
Embora possamos eliminar os bancos de dados do usuário executando o comando DROP DATABASE
DROP DATABASE AdventureWorksSe tentarmos DROP qualquer um dos bancos de dados do sistema, receberemos o erro conforme mostrado abaixo:
O proprietário dos bancos de dados do sistema não pode ser alterado
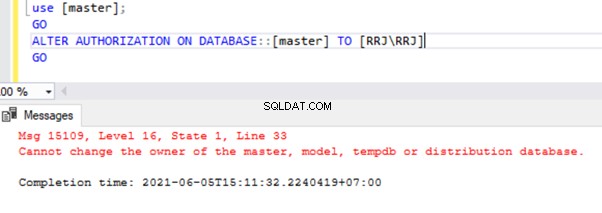
O proprietário do banco de dados do sistema é sa por padrão. Não pode ser alterado. As tentativas de renomear o proprietário do banco de dados do sistema provocarão erros.
Contudo, há uma exceção. É possível modificar o proprietário do msdb base de dados.
use [master];
GO
ALTER AUTHORIZATION ON DATABASE::[master] TO [RRJ\RRJ]
GO
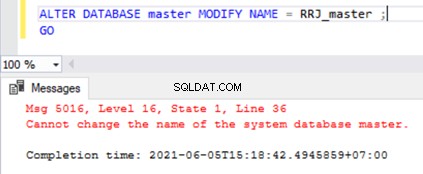
O nome do banco de dados dos bancos de dados do sistema não pode ser alterado
Se tentarmos renomear os bancos de dados do sistema, receberemos uma mensagem de erro conforme mostrado abaixo:
ALTER DATABASE master MODIFY NAME = RRJ_master;
GO
O agrupamento de bancos de dados do sistema não pode ser alterado
Os bancos de dados do sistema são criados com o nome do Collation escolhido durante a instalação do SQL Server. Uma vez instalado, o Collation de bancos de dados do sistema não pode ser alterado. A única maneira de alterar o agrupamento de bancos de dados do sistema é reinstalar a instância do SQL Server com o agrupamento correto.
O grupo de arquivos primário de bancos de dados do sistema não pode ser definido para o modo READ_ONLY
Como o banco de dados do sistema captura informações críticas relacionadas às instâncias do SQL Server, o SQL Server não permite que os arquivos de dados primários que residem no grupo de arquivos primário sejam definidos como somente leitura .
O recurso Change Data Capture não pode ser ativado em bancos de dados do sistema
Esse recurso é usado para rastrear todas as alterações de DML que ocorrem em um banco de dados nas tabelas rastreadas. Se tentarmos habilitar o recurso Change Data Capture em qualquer banco de dados do sistema, ocorrerá o erro:
use master
GO
exec sys.sp_cdc_enable_db

Agora que entendemos a diferença entre bancos de dados do sistema e bancos de dados do usuário, podemos examinar os propósitos de cada banco de dados do sistema com mais detalhes.
Banco de dados mestre no SQL Server
O banco de dados do sistema mestre contém os principais detalhes de configuração relacionados à instância do SQL Server . O SQL Server depende deles quando inicia uma instância específica. Se for impossível iniciar o banco de dados mestre por algum motivo, a instância do SQL Server também não poderá ser iniciada.
Esses detalhes principais armazenados no banco de dados mestre incluem contas de login, detalhes do servidor vinculado, terminais, definições de configuração do sistema e detalhes sobre todos os bancos de dados de usuários.
Agora vem a pergunta. Como o serviço SQL Server sabe onde os dados e arquivos de log do banco de dados mestre estão disponíveis? A resposta está nos parâmetros de configuração de inicialização do serviço SQL Server.
Para visualizar os parâmetros de configuração de inicialização de uma instância do SQL Server, primeiro devemos conhecer a ferramenta interna chamada SQL Server Configuration Manager . Ele ajuda a gerenciar todos os serviços relacionados ao SQL Server de todas as instâncias disponíveis no servidor específico. Para visualizar esses dados, abra o SQL Server Configuration Manager e ele exibirá a lista conforme mostrado abaixo:
Clique em Serviços do SQL Server para visualizar a lista de Serviços disponíveis neste Servidor ou PC:
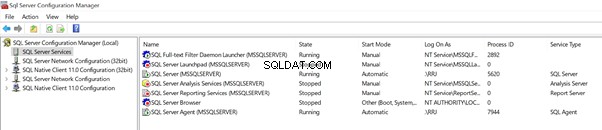
Espere um segundo! Parece familiar para o services.msc listando todos os serviços disponíveis no servidor, mas exibindo apenas os serviços relacionados ao SQL Server.
Vamos abrir services.msc para ver como fica e verificar as diferenças entre o SQL Server Configuration Manager e services.msc para comparar qual é melhor.
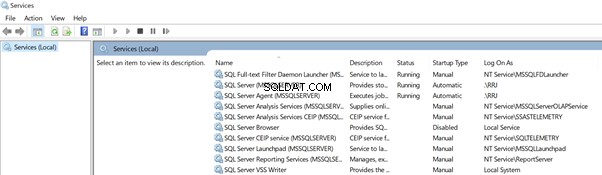
O SQL Server Configuration Manager exibe a ID do processo dos serviços que estão em execução no momento. Não encontramos isso em services.msc . Claro, podemos obter essas informações do Gerenciador de Tarefas do Windows, mas o SQL Server Configuration Manager nos ajudou a visualizar isso em um único local.
Agora, vamos ter uma visão detalhada. Clique com o botão direito do mouse no serviço SQL Server em services.msc . Você verá os menus abaixo:Geral , Logon , Recuperação e Dependências .
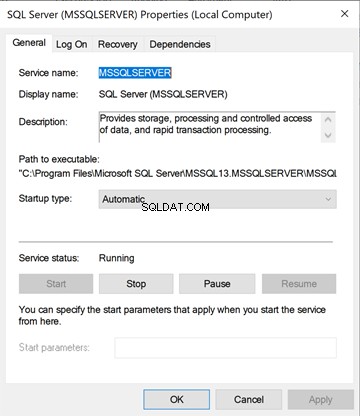
No SQL Server Configuration Manager, clique com o botão direito do mouse no SQL Server(MSSQLSERVER) serviço> Propriedades . Ele lista os menus abaixo – Log On, Service. FileStream, Advanced, Alwayson OnHigh Availability e Parâmetros de inicialização .
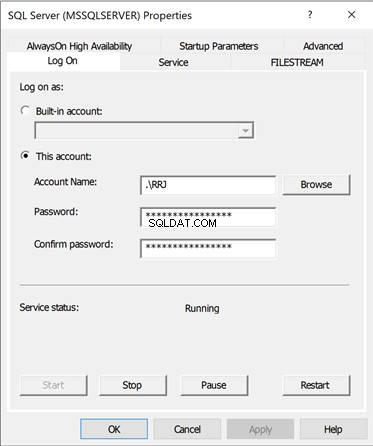
Os Parâmetros de inicialização do Serviço que armazena a localização dos dados do banco de dados mestre e arquivos de log estava disponível apenas no SQL Server Configuration Manager .
Clique em Parâmetros de inicialização para ver os detalhes – para Existente Parâmetros . Você verá as seguintes informações:
- A localização física do banco de dados mestre Arquivo de dados
- A localização física do banco de dados mestre Arquivo de log de transações
- A localização física da Pasta ErrorLog onde estão localizados os erros relacionados ao SQL Server Service.
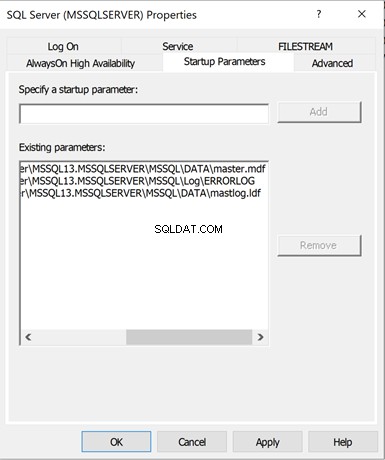
Podemos adicionar mais parâmetros de inicialização como Modo de usuário único (-m) , etc. Para isso, precisamos especificar os valores necessários em Especificar um parâmetro de inicialização e clique em Adicionar .
Percebemos que o SQL Server Configuration Manager não apenas exibe detalhes avançados, mas também nos permite fazer muitas configurações avançadas relacionadas ao serviço SQL Server. Portanto, eu recomendaria pessoalmente usar o SQL Server Configuration Manager para parar/iniciar serviços relacionados ao SQL Server em comparação com a opção padrão Services.msc.
Práticas recomendadas para o banco de dados mestre
Como o banco de dados mestre armazena detalhes críticos sobre a instância do SQL Server, é recomendável seguir as práticas recomendadas ao manipular esse banco de dados.
- Todas as alterações de configuração em uma instância do SQL Server serão armazenadas no banco de dados mestre. Assim, você sempre precisa fazer um backup completo do banco de dados mestre para restaurar para o status mais recente, caso estejamos restaurando o banco de dados mestre a partir do backup completo, conforme necessário.
- Mesmo que o SQL Server permita que os usuários criem tabelas de usuários ou outros objetos no banco de dados mestre, isso não é recomendado. O banco de dados mestre deve permanecer simples e limpo. Se você precisar criar objetos de usuário no banco de dados mestre, faça backups completos do banco de dados mestre com mais frequência.
- O SQL Server é compatível com a opção de procedimento de inicialização para executar determinados procedimentos armazenados ao iniciar uma instância do SQL Server. Ele usa o sp_procoption procedimento. Tenha cuidado ao usar essa opção, pois ter um código não ideal ou uma lógica recursiva pode afetar o tempo de inicialização da instância do SQL Server.
Se o SQL Server não pôde ser iniciado devido a problemas com o banco de dados mestre, precisamos restaurar o banco de dados mestre do último backup válido conhecido.
Modelo de banco de dados no SQL Server
Como o nome indica, o Banco de dados do sistema modelo atua como um modelo ou modelo para qualquer criação de banco de dados do usuário em termos de caminho de arquivo, tamanho inicial, configurações de crescimento automático e o modelo de recuperação e outras opções de configuração .
Quaisquer objetos de usuário, como tabelas, procedimentos, etc., criados nos bancos de dados modelo também serão criados automaticamente nos novos bancos de dados de usuário nessa instância do SQL Server.
Vamos verificar isso criando uma nova tabela no banco de dados do modelo:
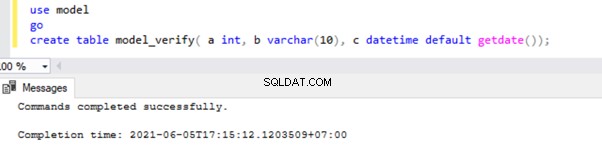
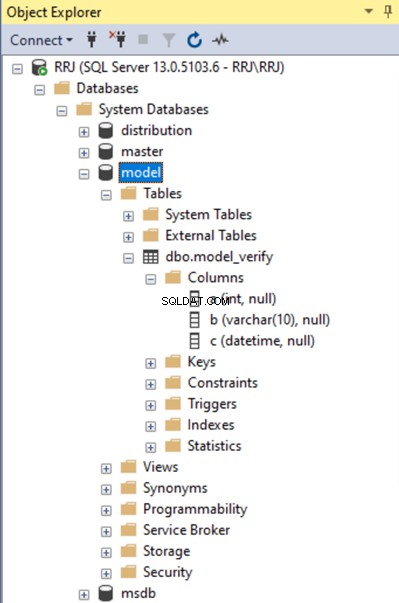
Vamos verificar se esta tabela está presente no banco de dados do modelo:
O banco de dados Modelo também armazena o caminho de arquivo padrão dos bancos de dados do usuário, conforme mostrado abaixo nas Propriedades do banco de dados do msdb base de dados.
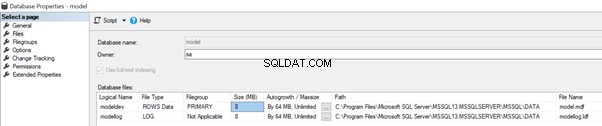
De acordo com a configuração atual, o Tamanho do arquivo inicial de ambos os Dados e Arquivos de registro está definido para 8 MB com crescimento automático para ambos definido para 64 MB.
Se você precisar criar um banco de dados de usuário em um caminho de arquivo diferente em vez do local do arquivo de banco de dados do modelo, podemos modificá-lo nas Propriedades do servidor dessa instância do SQL Server.
No SSMS, clique com o botão direito do mouse em Servidor > Propriedades > Configurações do banco de dados . Veja os locais padrão do banco de dados:
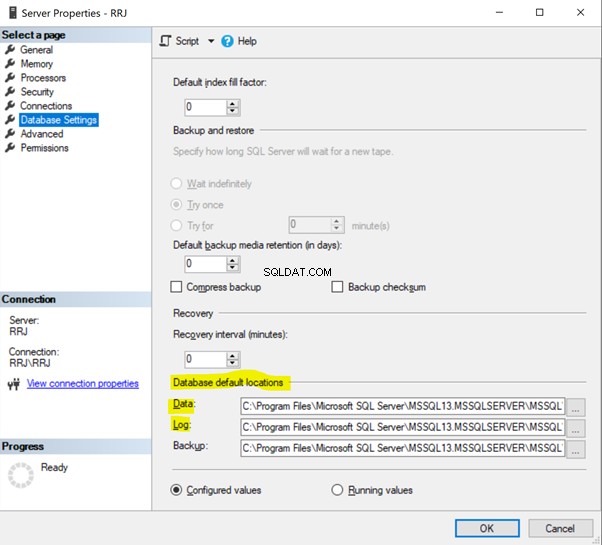
Altere o caminho do arquivo para o caminho desejado e clique em OK . O banco de dados do usuário Dados e Registrar os arquivos serão criados no novo caminho que você forneceu.
Vamos criar um novo banco de dados chamado model_test e verifique os novos caminhos do arquivo de dados e log do banco de dados junto com as propriedades do arquivo Initial e Autogrowth e o model_verify tabela no novo banco de dados.
Vamos verificar o model_test Caminhos de arquivo de dados e log. Clique com o botão direito do mouse no model_test banco de dados> Propriedades > Arquivos :
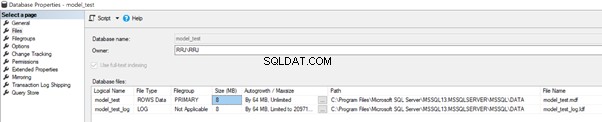
Como podemos ver, os Dados e Registrar arquivos do model_test banco de dados são criados de acordo com o caminho disponível no banco de dados modelo. O valor do tamanho do arquivo inicial dos arquivos de dados e log é 8 MB. O valor Autogrowth é 64 MB. Esses valores correspondem à configuração do banco de dados modelo.
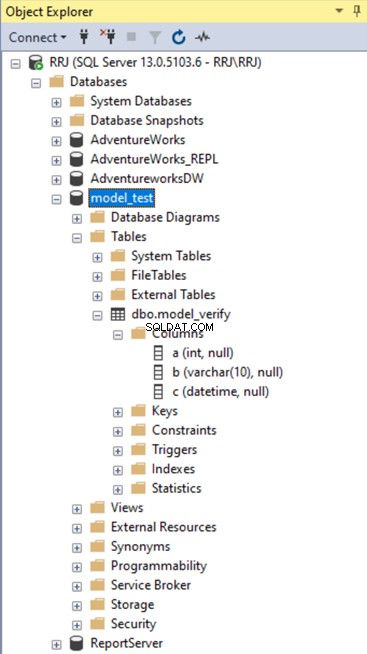
Agora, verificaremos se o model_verify a tabela é criada no model_test base de dados. Podemos ver este novo banco de dados.
Além de tabelas, isso se aplica a Views, Stored Procedures, Functions e quaisquer objetos criados nos bancos de dados do modelo.
Práticas recomendadas para banco de dados modelo
Como o banco de dados modelo atua como um modelo para qualquer criação de banco de dados de novo usuário, devemos implementar as práticas abaixo ao lidar com ele:
- Sempre que você quiser implementar qualquer alteração na configuração do banco de dados do modelo (por exemplo, tamanho inicial do arquivo, tamanho do crescimento automático, criação, modificação ou exclusão de objetos do usuário), faça um backup completo do banco de dados do modelo imediatamente.
- Como todos os objetos de usuário criados nos bancos de dados de modelo são criados em qualquer banco de dados de usuário, tome cuidado para adicionar apenas os objetos necessários. Caso contrário, muitos objetos desnecessários serão criados em todos os bancos de dados de usuários e você gastará muito tempo classificando-os e limpando seus bancos de dados.
- Configure os parâmetros Initial File Size e Autogrowth para os arquivos de dados e log. Ele ajuda a gerenciar melhor os tamanhos dos arquivos de dados e log nos bancos de dados do usuário e melhora o desempenho.
Banco de dados MSDB
O banco de dados do sistema msdb armazena as informações críticas abaixo nas tabelas do sistema:
- Itens relacionados ao SQL Server Agent, como trabalhos, históricos de trabalho, alertas, operadores, proxies etc.
- Recursos do SQL Server, como Service Broker e Database Mail, com detalhes de configuração e histórico.
- Os detalhes de backup e restauração do SQL Server são armazenados nas tabelas do banco de dados msdb.
- Configurações de envio de logs, perfis do agente de replicação e configurações do coletor de dados.
- Planos de manutenção, pacotes SSIS e alguns outros detalhes.
Em outras palavras, o banco de dados do sistema msdb armazena todas as informações críticas relacionadas aos SQL Server Agent Services e alguns outros serviços relacionados.
Práticas recomendadas para banco de dados msdb
O banco de dados msdb armazena muitas informações de configuração críticas relacionadas a SQL Server Agents, Jobs e Database Mail. Ele também armazena detalhes históricos. Portanto, devemos implementar as práticas abaixo ao lidar com o banco de dados msdb:
- Em uma instância do SQL Server com muitos bancos de dados ou trabalhos configurados, o tamanho do banco de dados msdb aumentará continuamente ao longo do tempo. Portanto, backups completos devem ser implementados para os bancos de dados msdb diariamente junto com outros bancos de dados de usuários. Se o msdb receber muitas informações críticas, podemos alterar o modelo de recuperação do banco de dados msdb para completo e implementar o backup do log de transações também.
- Embora o SQL Server permita que os usuários criem objetos de usuário no banco de dados msdb, é recomendável não criar nenhuma tabela ou objeto de usuário no banco de dados msdb e aumentar ainda mais o tamanho do banco de dados msdb.
- Realize a limpeza regular das tabelas do sistema msdb para manter o tamanho do banco de dados msdb sob controle e evitar os impactos no desempenho de ter dados enormes em várias tabelas.
Banco de dados temporário
O banco de dados do sistema tempdb pode ser considerado como uma área de trabalho global disponível para todos os usuários conectados à instância do SQL Server para realizar seu SELECT ou outras operações .
O banco de dados Tempdb manterá os tipos de objeto abaixo enquanto os usuários realizam suas operações:
- Os objetos temporários criados explicitamente pelos usuários podem ser tabelas e índices temporários locais ou globais, variáveis de tabela, tabelas usadas em funções com valor de tabela e cursores.
- Objetos internos criados pelo mecanismo de banco de dados, como:
- Tabelas de trabalho usadas para resultados intermediários para spools, cursores, classificações e objetos grandes temporários (LOB)
- Arquivos de trabalho para operações de junção de hash ou agregação de hash
- Resultados de classificação intermediários ao lidar com a criação ou reconstrução de índices se SORT_IN_TEMPDB estiver definido como ON e outras operações como consultas GROUP BY, ORDER BY ou UNION
- Armazenamentos de versão que oferecem suporte ao recurso de controle de versão de linha, seja armazenamento de versão comum ou armazenamento de versão de compilação de índice online.
Sempre que o serviço SQL Server for iniciado ou reiniciado, o banco de dados tempdb será criado novamente com a ajuda do banco de dados modelo. Assim, tempdb é o único banco de dados do sistema que não pode ter backup .
Se tentarmos fazer backup, receberemos erros:
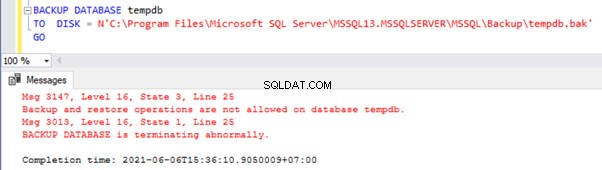
Como usamos tempdb em quase todas as operações do usuário, esse banco de dados representa um gargalo de desempenho significativo em várias versões do SQL Server. A partir do SQL Server 2016, várias técnicas de otimização foram implementadas pela Microsoft – vamos discuti-las mais tarde.
Antes de entrar nas práticas recomendadas para o banco de dados tempdb, vamos dar uma olhada rápida em seus arquivos de dados na configuração padrão, conforme mostrado abaixo:
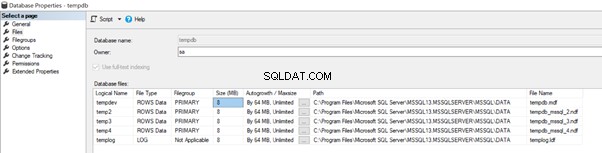
Para minha instância atual do SQL Server, temos 4 arquivos de dados e um arquivo de log para o banco de dados tempdb.
A partir do SQL Server 2016, temos o instalador do SQL Server que permite adicionar vários arquivos ao tempdb. Os 4 arquivos acima com tamanho inicial de 8 MB e tamanho de crescimento automático de 64 MB foram criados usando as opções padrão mostradas abaixo.
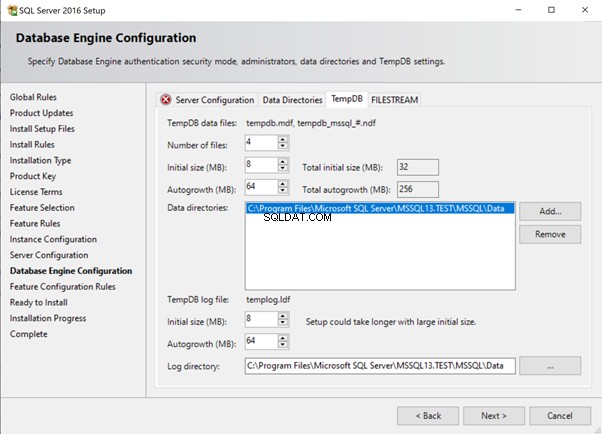
Se tivermos um único arquivo de dados no banco de dados tempdb, todos os núcleos lógicos disponíveis no servidor tentarão acessar o mesmo arquivo de dados do tempdb, resultando em um gargalo de desempenho.
Ter vários arquivos de dados associará logicamente determinados núcleos a um único arquivo. Assim, temos menos contenção em arquivos de dados tempdb. Isso melhorará o impacto no desempenho dos arquivos de dados tempdb.
Práticas recomendadas para banco de dados tempdb
Como o banco de dados tempdb é como uma área de trabalho global para todas as atividades do usuário, o tamanho do tempdb aumenta com base nas atividades do usuário. Pode ser um gargalo de desempenho para toda a instância do SQL Server.
Portanto, devemos implementar as seguintes práticas:
- Coloque os arquivos de dados e log tempdb no armazenamento de alto desempenho para obter IOPS mais altas e obter melhor desempenho.
- Certifique-se de que o banco de dados tempdb seja dividido em vários arquivos de dados para reduzir a contenção e evitar gargalos de desempenho no banco de dados tempdb.
- Se o número de núcleos lógicos for menor que 8, podemos ter um arquivo de dados tempdb por núcleo lógico. Em nossa instância de teste, tínhamos 4 núcleos lógicos. Portanto, 4 arquivos de dados no tempdb devem ser suficientes.
- Se o número de núcleos lógicos for maior que 8, comece com 8 arquivos de dados e aumente em 4 arquivos de dados se problemas de contenção e desempenho forem observados no banco de dados tempdb.
- Se o número de núcleos lógicos em um servidor for 32 ou 64, podemos começar com 8 arquivos de dados. Isso significa que 4 núcleos ou 8 núcleos estão associados logicamente para um único arquivo de dados.
Para mais clareza sobre vários arquivos de dados tempdb, recomendo o excelente artigo de Paul Randal.
- Certifique-se de que os arquivos de dados tempdb estejam configurados com o tamanho de arquivo inicial ideal. Idealmente, isso deve ser alcançado por meio de uma abordagem de tentativa e erro. Tempdb com tamanho de arquivo inicial ideal tende a crescer menos vezes em comparação com tempdb configurado com tamanho de arquivo inicial menor, que tende a crescer várias vezes, levando à fragmentação. Por exemplo, na configuração atual, todos os arquivos são configurados com um tamanho de arquivo inicial de 8 MB, que é muito pequeno para lidar com SQL Workloads. Assim, aplique a abordagem de tentativa e erro e defina o tamanho inicial do arquivo para 512 MB ou 1 GB, ou algum outro valor.
- Certifique-se de que todos os arquivos de dados tempdb tenham o mesmo tamanho de arquivo. As propriedades de crescimento automático devem ser definidas igualmente. Em nosso cenário, todos os arquivos estão configurados para crescimento automático de 64 MB. Definir o tamanho do Autogrowth para 512 MB ou 1 GB, ou qualquer outro valor apropriado, ajuda a reduzir o autogrowth frequente em arquivos de dados tempdb.
- Certifique-se de que o tamanho do arquivo inicial e o crescimento automático para o arquivo de log tempdb estejam configurados para um valor ideal semelhante aos arquivos de dados tempdb. Como o modelo de recuperação do tempdb é definido como Simples por padrão e não pode ser modificado, configurar o tamanho do arquivo inicial e a propriedade de crescimento automático do arquivo de log do tempdb deve ser suficiente.
Tempdb é vital para o desempenho da instância do SQL Server. Analisaremos detalhadamente os problemas frequentes enfrentados no tempdb e como reduzi-lo de maneira ideal em nossos próximos artigos.
Banco de dados de recursos no SQL Server
O banco de dados do Resource System é o único banco de dados do sistema somente leitura que não está listado nos bancos de dados do sistema no SSMS, conforme visto anteriormente.
O ID do banco de dados (dbid) de bancos de dados de recursos em todas as instâncias será 32767, que também é o número máximo de bancos de dados com suporte em uma instância do SQL Server. Ele pode ser consultado nos sys.sysaltfiles sistema DMV. Executando a consulta SELECT abaixo em sys.sysaltfiles retornará o conjunto de resultados mostrando onde os arquivos de dados e log do banco de dados de recursos estão localizados:
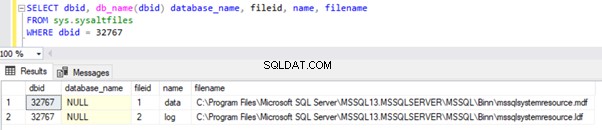
Podemos ver arquivos físicos do banco de dados de recursos disponíveis no caminho mencionado acima. A data de modificação indica a hora da instalação da instância do SQL Server ou a última vez que os Service Packs (SP) ou a atualização cumulativa (CU) foram aplicados nessa instância.

O banco de dados de recursos contém todos os objetos do sistema, como sys.objects , sys.databases , sys.sysaltfiles , etc. fisicamente dentro dele. Este banco de dados lista logicamente todos esses objetos no esquema sys em todos os bancos de dados disponíveis na instância . Como o banco de dados de recursos é somente leitura, nenhum objeto ou dado de usuário pode ser criado nele.
O banco de dados do sistema de recursos foi introduzido a partir do SQL Server 2005 para agilizar a atualização do SQL Server para uma nova versão do SP ou CU. Antes de introduzir essa opção, todas essas atualizações e atualizações significavam que as alterações seriam aplicadas em todos os bancos de dados, tornando o processo de atualização mais complicado e demorado. Agora, qualquer atualização de versão do SQL Server ou atualização de SP ou CU apenas atualiza ou substitui o banco de dados de recursos.
Como o banco de dados de recursos é somente leitura e não é visível para os usuários, ele não requer nenhuma intervenção do usuário. Se você deseja incluir o banco de dados de recursos de backup em seu planejamento de Alta Disponibilidade ou Recuperação de Desastres, basta fazer um backup dos arquivos mssqlsystemresource.mdf e mssqlsystemresource.ldf após interromper o SQL Server Services (o serviço SQL Server não permitirá copiar os arquivos enquanto SQL Server Service está funcionando) e salve-o em um local seguro. Tome cuidado redobrado para não atualizá-lo em nenhuma instância do SQL Server em execução com uma versão diferente dos níveis SP ou CU, pois isso pode causar problemas inesperados.
Banco de dados de distribuição no SQL Server
O banco de dados do sistema de distribuição é o coração da Replicação. Os usuários podem criar ou configurar o banco de dados de distribuição como parte da configuração da Replicação com a ajuda do Assistente para Configurar Distribuição ou do Assistente para Criar Publicação. Descrevemos detalhadamente as etapas de criação do banco de dados de distribuição como parte de meu artigo anterior sobre os internos de replicação transacional do SQL Server.
Práticas recomendadas para banco de dados de distribuição
Como o banco de dados de distribuição é essencial para a funcionalidade de Replicação, devemos implementar as seguintes práticas:
- Mova os arquivos de dados e log do banco de dados de distribuição para a unidade com boa IOPS para evitar problemas de desempenho de distribuição.
- Configure as propriedades Initial File Size e Autogrowth do banco de dados de distribuição para um valor melhor para evitar problemas de fragmentação.
- Inclua o banco de dados de distribuição nas tarefas de manutenção de backup completo do banco de dados.
- Inclua bancos de dados de distribuição nos trabalhos de manutenção de índice para evitar problemas de fragmentação e desempenho.
Em meu artigo sobre os componentes internos da Replicação Transacional do SQL Server, você também encontrará recomendações sobre outras práticas eficientes.
Conclusão
Obrigado por passar por outro artigo cheio de energia!
Espero que tenha ajudado você a esclarecer a essência e os propósitos dos bancos de dados do sistema SQL Server e aprender as práticas recomendadas para evitar problemas de desempenho nesses bancos de dados.



