Introdução
Você já deve ter ouvido o termo “Collation” no SQL Server. Collation é uma configuração que determina como a classificação de dados de caracteres é feita. Essa é uma configuração importante que tem um grande impacto em como o mecanismo de banco de dados do SQL Server se comporta ao lidar com dados de caracteres. Neste artigo, pretendemos discutir ordenações em geral e mostrar alguns exemplos de como lidar com ordenações.
Onde encontro agrupamentos?
Você pode encontrar o agrupamento SQL no servidor, banco de dados e nível de coluna. Outra coisa importante a saber é que a configuração de agrupamento não precisa ser a mesma no servidor, banco de dados e nível de coluna. Além disso, você pode atualizar suas consultas para usar agrupamentos específicos. É neste momento que você perceberá a importância de configurar a ordenação correta em seu ambiente, pois há uma grande possibilidade de problemas inesperados se a ordenação não for consistente.
Quais são os diferentes tipos de agrupamentos disponíveis?
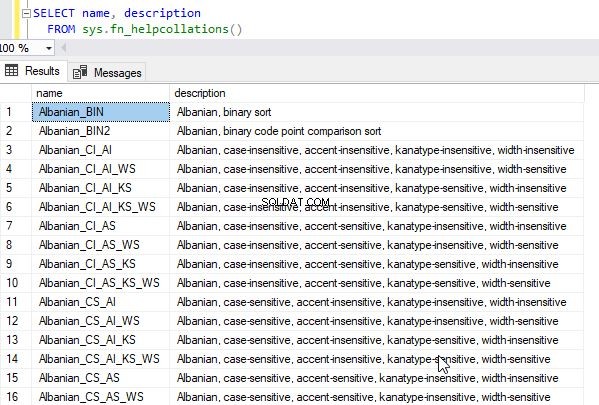
Você pode obter a lista completa de agrupamentos disponíveis consultando a função do sistema sys.fn_helpcollations()
select * from sys.fn_helpcollations()
Isso retornará a seguinte saída.
Se você estiver procurando por agrupamentos específicos por idioma, poderá filtrar ainda mais o nome. Por exemplo, se você estiver procurando pelo agrupamento compatível com o idioma maori, poderá usar a consulta a seguir.
select * from sys.fn_helpcollations()
where name like '%Maori%' Isso retornará a seguinte saída.
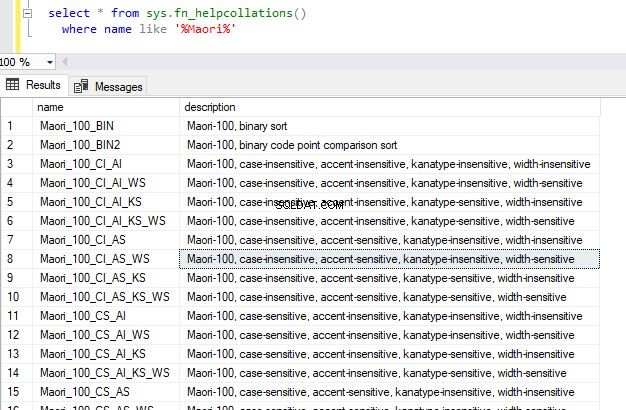
Dessa forma, você pode verificar os agrupamentos suportados para o agrupamento de sua escolha. Ao consultar apenas a função do sistema fn_helpcollations(), 5508 linhas no total foram retornadas, o que significa que há muitos agrupamentos suportados. Observe que isso abrange a maioria dos idiomas ao redor do mundo.
Quais são as diferentes opções que você vê no nome do agrupamento?
Por exemplo, neste agrupamento:Maori_100_CS_AI_KS_WS_SC_UTF8, você pode ver as várias opções no nome do agrupamento.
CS – diferencia maiúsculas de minúsculas
IA – sem acento
KS – kana sensível ao tipo
WS – sensível à largura
SC – caracteres suplementares
UTF8 – Padrão de codificação
Com base no tipo de opção de agrupamento selecionada, o mecanismo de banco de dados do SQL Server terá um desempenho diferente ao lidar com dados de caracteres para operações de classificação e pesquisa. Por exemplo, se você usar a opção com distinção entre maiúsculas e minúsculas no agrupamento SQL, o mecanismo de banco de dados se comportará de maneira diferente para uma operação de consulta procurando por “Adam” ou “adam”. Supondo que você tenha uma tabela chamada “sample” e haja uma coluna de primeiro nome com um usuário “adam”. A consulta abaixo não retornará resultados se não houver linha com o primeiro nome “Adam”. Isso ocorre devido à opção “CS-Case sensitive” no agrupamento.
select * from sample
where firstname like '%Adam%' Com este exemplo simples, você pode entender o significado de escolher a opção de agrupamento SQL correta. Certifique-se de entender os requisitos do aplicativo antes de selecionar o agrupamento em primeiro lugar.
Encontrando agrupamento na instância do SQL Server
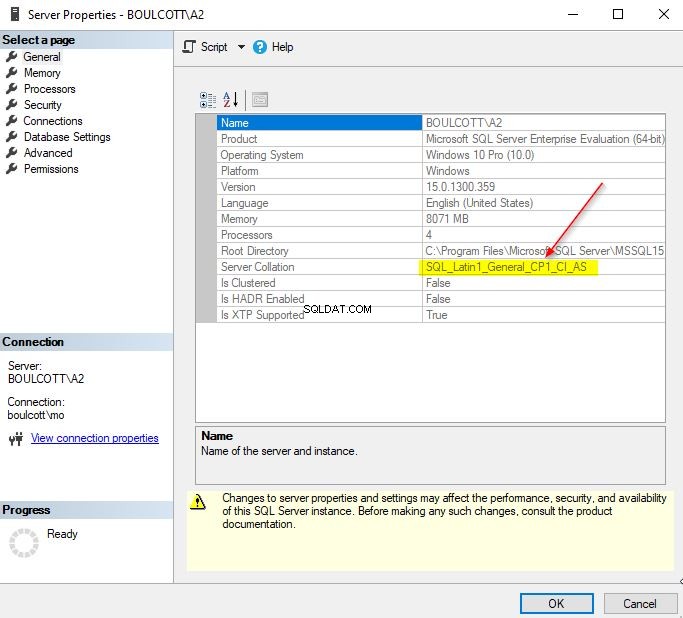
Você pode obter o agrupamento do servidor no SQL Server Management Studio (SSMS) clicando com o botão direito do mouse na instância do SQL, clicando na opção “Propriedades” e marcando a guia “Geral”. Esse agrupamento é selecionado por padrão na instalação do SQL Server.
Como alternativa, você pode usar a opção serverproperty para localizar o valor de agrupamento.
select SERVERPROPERTY('collation'), 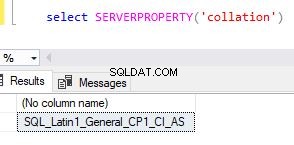
Encontrando agrupamento de um banco de dados SQL
No SSMS, clique com o botão direito do mouse no banco de dados SQL e vá para “Propriedades”. Você pode verificar os detalhes do agrupamento na guia "Geral", conforme mostrado abaixo.
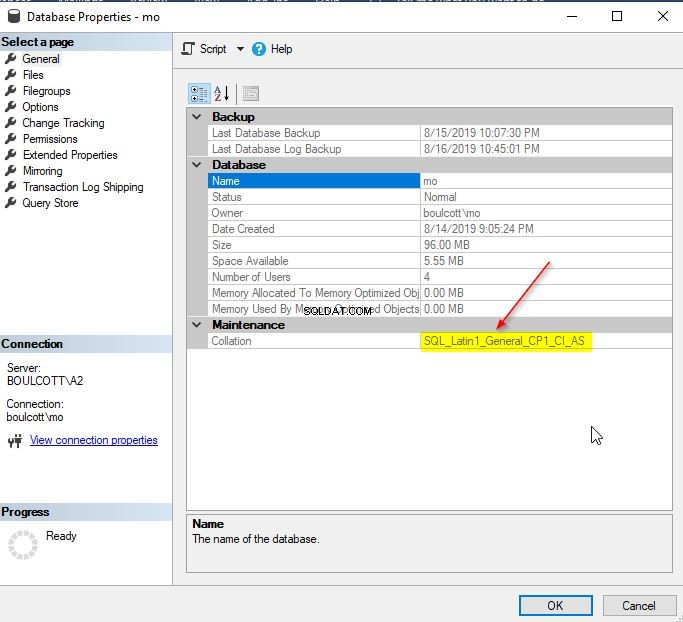
Como alternativa, você pode usar a função databasepropertyex para obter os detalhes de um agrupamento de banco de dados.
select DATABASEPROPERTYEX('Your DB Name','collation') 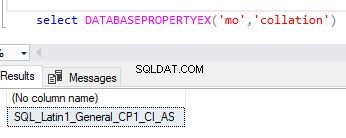
Encontrando agrupamento de uma coluna em uma tabela
No SSMS, vá para a tabela, depois para as colunas e, finalmente, clique com o botão direito do mouse nas colunas individuais para visualizar as “Propriedades”. Se a coluna for do tipo de dados de caractere, você verá os detalhes do agrupamento.
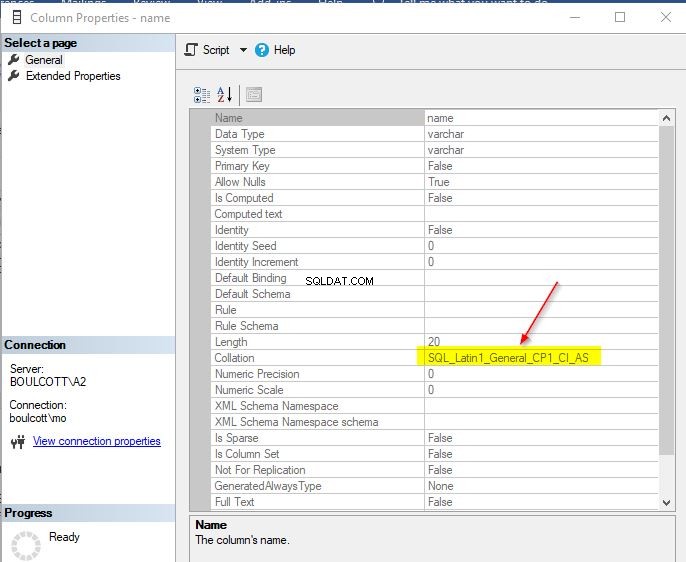
No entanto, ao mesmo tempo, se você verificar o valor de um tipo de dados que não seja de caractere, o valor de agrupamento será nulo. Abaixo está uma captura de tela de uma coluna que possui o tipo de dados int.
Como alternativa, você pode usar uma consulta de amostra abaixo para visualizar os valores de agrupamento das colunas.
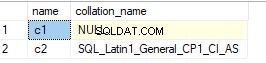
select sc.name, sc.collation_name from sys.columns sc inner join sys.tables t on sc.object_id=t.object_id where t.name='t1' – enter your table name
Abaixo está a saída para a consulta.
Experimentando diferentes agrupamentos em consultas SQL
Nesta seção, veremos como a ordem de classificação é afetada quando diferentes agrupamentos são usados em consultas. Uma tabela de amostra é criada com 2 colunas, conforme mostrado abaixo.
A coluna fname tem o agrupamento padrão do banco de dados ao qual pertence. Neste caso, o agrupamento é SQL_Latin1_General_CP1_CI_AS.
Para inserir alguns registros na tabela, utilize uma consulta abaixo. Atribua seus próprios valores aos parâmetros.
insert into emp values (1,'mohammed') insert into emp values (2,'moinudheen') insert into emp values (3,'Mohammed') insert into emp values (4,'Moinudheen') insert into emp values (5,'MOHAMMED') insert into emp values (6,'MOINUDHEEN')
Agora, consulte a tabela emp e classifique-a pela coluna fname usando diferentes agrupamentos. Usaremos o agrupamento padrão da coluna para classificação, bem como outro agrupamento sensível a maiúsculas e minúsculas – SQL_Latin1_General_CP1_CS_AS.
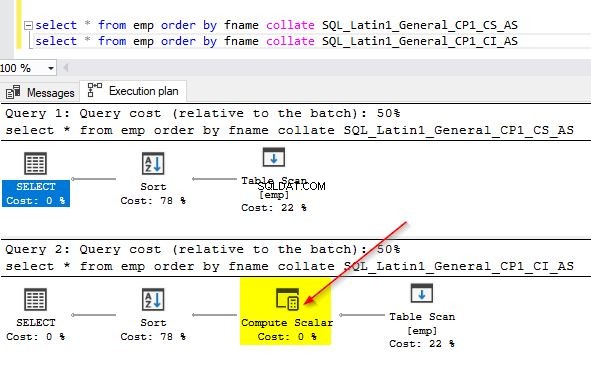
select * from emp order by fname collate SQL_Latin1_General_CP1_CS_AS select * from emp order by fname collate SQL_Latin1_General_CP1_CI_AS – this is default
A saída para essas consultas é fornecida abaixo. Observe a diferença no agrupamento usado. Estamos usando case sensitive em vez de case insensitive.
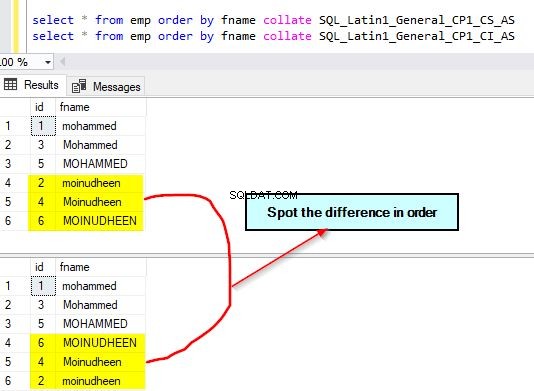
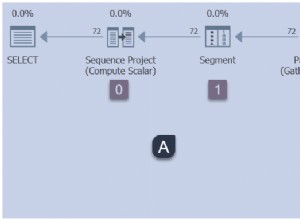
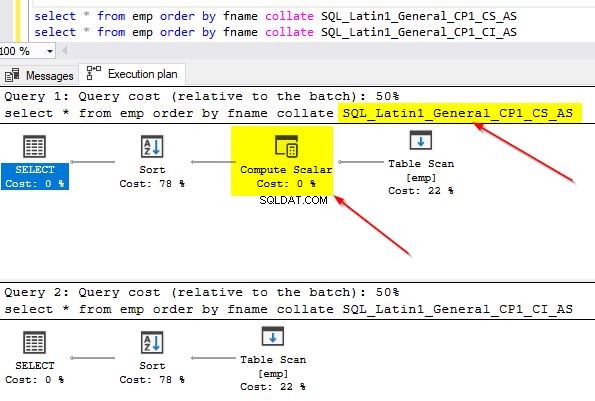
Você também pode verificar os planos de consulta para ambas as consultas para identificar a diferença. No primeiro plano de consulta em que usamos um agrupamento diferente do da coluna, você pode notar o operador adicional “Compute Scalar”.
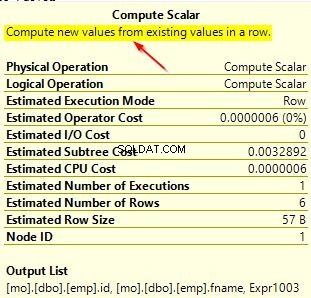
Ao passar o mouse sobre o operador “Compute Scalar”, você verá os detalhes adicionais conforme mostrado abaixo. Isso se deve à conversão implícita que está ocorrendo, pois estamos usando um agrupamento diferente do padrão usado na coluna.
Com este pequeno exemplo, você pode ver o tipo de impacto no desempenho da consulta ao usar agrupamentos explicitamente nas consultas. Em nosso banco de dados de demonstração, usamos uma tabela simples, mas imagine um cenário em tempo real em que pequenas alterações no desempenho da consulta podem causar resultados inesperados.
Verificando se é possível alterar o agrupamento no nível da instância
Nesta seção, analisaremos diferentes cenários em que talvez seja necessário alterar os agrupamentos padrão. Você pode encontrar situações em que servidores ou bancos de dados são entregues a você e podem não estar atendendo às suas políticas padrão, portanto, talvez seja necessário alterar o agrupamento. O agrupamento padrão do SQL Server é SQL_Latin1_General_CP1_CI_AS. Alterar o agrupamento no nível da instância SQL não é simples. Ele requer o script de todos os objetos nos bancos de dados do usuário, a exportação dos dados, a eliminação dos bancos de dados do usuário, a reconstrução do banco de dados mestre com o novo agrupamento, a criação dos bancos de dados do usuário e a importação de todos os dados. Portanto, se você estiver instalando novas instâncias do SQL, certifique-se de obter o agrupamento certo na primeira vez, caso contrário, poderá ter que fazer muito trabalho indesejado posteriormente. Explicar em detalhes os estágios para alterar o agrupamento no nível da instância está além do escopo deste artigo devido às etapas detalhadas necessárias para cada um dos estágios.
Alterando o agrupamento no nível do banco de dados
Felizmente, alterar o agrupamento de nível de banco de dados não é tão difícil quanto alterar o agrupamento de instâncias. Podemos atualizar o agrupamento usando SSMS e T-SQL. No SSMS, basta clicar com o botão direito do mouse no banco de dados, ir em “Propriedades” e clicar na guia “Opções” no lado esquerdo. Lá, você pode ver a opção de alterar o agrupamento no menu suspenso.
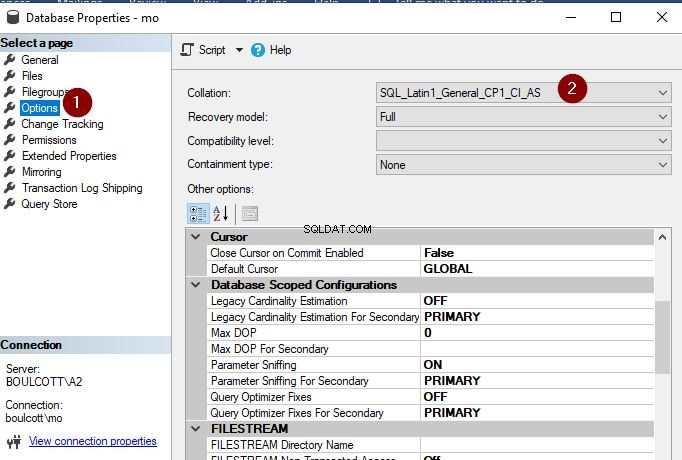
Clique em “OK” uma vez feito. Acabei de alterar o agrupamento do banco de dados para SQL_Latin1_General_CP1_CI_AS. Apenas certifique-se de executar esta operação quando o banco de dados não estiver em uso, pois a operação falhará, conforme mostrado abaixo.
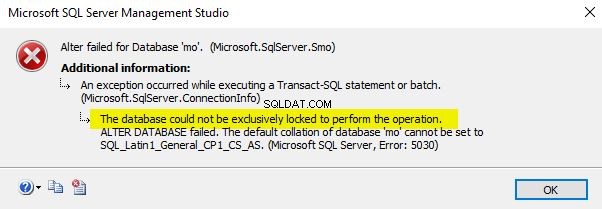
Use a consulta de procedimento para alterar o agrupamento do banco de dados usando T-SQL.
USE master; GO ALTER DATABASE mo COLLATE SQL_Latin1_General_CP1_CS_AS; GO
Você notaria que alterar o agrupamento do nível do banco de dados não afetará o agrupamento das colunas existentes nas tabelas. Você pode usar os exemplos anteriores para verificar o impacto do agrupamento na ordem de classificação das consultas abaixo.
select * from emp order by fname collate SQL_Latin1_General_CP1_CS_AS select * from emp order by fname collate SQL_Latin1_General_CP1_CI_AS – - this is default
O agrupamento de colunas fname permanecerá o original e permanecerá inalterado mesmo após alterar o agrupamento de nível de banco de dados.
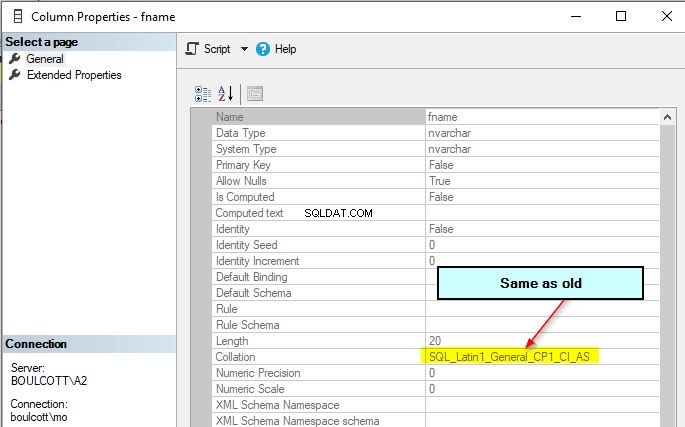
No entanto, o novo agrupamento de nível de banco de dados será aplicado a todas as novas colunas nas novas tabelas que você criar. Portanto, sempre teste a alteração dos agrupamentos de banco de dados completamente, pois isso tem um impacto considerável na saída ou no comportamento das consultas.
Alterando a ordenação no nível da coluna
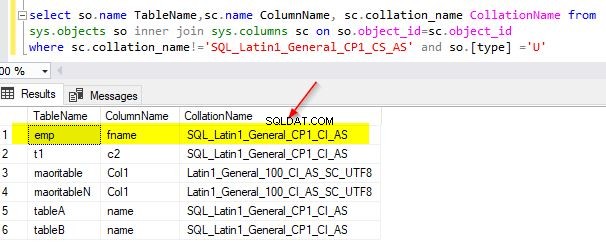
Na seção anterior, você notou que mesmo após alterar o agrupamento do nível do banco de dados, o agrupamento das colunas existentes nas tabelas permanece inalterado. Nesta seção, veremos como podemos alterar o agrupamento das colunas existentes nas tabelas para corresponder ao agrupamento do banco de dados. Na seção anterior, você alterou o agrupamento do banco de dados para SQL_Latin1_General_CP1_CS_AS. Em seguida, você deseja identificar todas as colunas nas tabelas de usuário que não correspondem a esse agrupamento de banco de dados. Você pode usar este script para identificar essas colunas.
select so.name TableName,sc.name ColumnName, sc.collation_name CollationName from sys.objects so inner join sys.columns sc on so.object_id=sc.object_id where sc.collation_name!='SQL_Latin1_General_CP1_CS_AS' and so.[type] ='U'
A saída de amostra do meu banco de dados de demonstração é mostrada abaixo.
Suponha que você queira alterar o agrupamento da coluna fname existente para “SQL_Latin1_General_CP1_CS_AS”, então você pode usar este script de alteração abaixo.
use mo
go
ALTER TABLE dbo.emp ALTER COLUMN fname
nvarchar(20) COLLATE SQL_Latin1_General_CP1_CS_AS NULL;
GO Se você usar os exemplos anteriores em que verificou o desempenho da consulta usando diferentes agrupamentos, notará que o operador “computar escalar” não é usado quando usamos o mesmo agrupamento do banco de dados. Consulte a captura de tela abaixo. No exemplo anterior, você pode ter notado o operador “Compute scalar” sendo usado no primeiro plano de execução. Como alteramos o agrupamento de colunas para corresponder ao agrupamento do banco de dados, não há necessidade de conversão implícita. Você verá o operador “Compute scalar” na segunda consulta, pois ele usa um agrupamento diferente explicitamente.
select * from emp order by fname collate SQL_Latin1_General_CP1_CS_AS – - this is default select * from emp order by fname collate SQL_Latin1_General_CP1_CI_AS
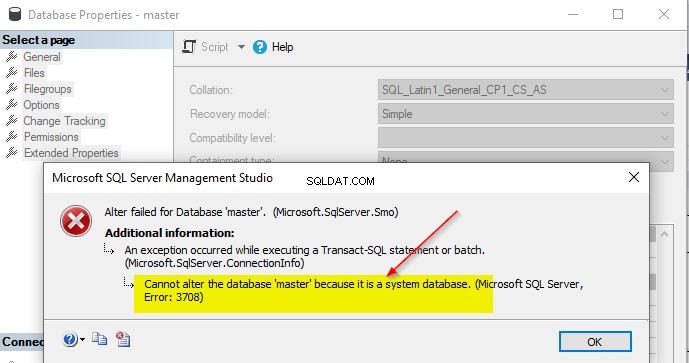
Podemos alterar o agrupamento de bancos de dados do sistema?
Não é possível alterar o agrupamento de bancos de dados do sistema. Se você tentar alterar o agrupamento dos bancos de dados do sistema – master, model, msdb ou tempdb, você receberá esta mensagem de erro.
Você precisará seguir as etapas descritas anteriormente para alterar o agrupamento no nível de instância do SQL Server para alterar o agrupamento dos bancos de dados do sistema. É importante obter os agrupamentos corretos na primeira vez que você instalar o SQL Server para evitar esses problemas.
O problema conhecido sobre o conflito de ordenação
Outro problema comum que você pode encontrar é o erro relacionado ao conflito de agrupamento, especialmente ao usar objetos temporários. Os objetos temporários são armazenados no tempdb. O tempdb sendo um banco de dados do sistema assumirá o agrupamento da instância SQL. Ao criar bancos de dados de usuário com agrupamento diferente do da instância SQL, você terá problemas ao usar objetos temporários. Você também pode enfrentar problemas ao comparar colunas em tabelas com agrupamentos diferentes. Até agora, você já sabe que uma tabela pode ter colunas com diferentes agrupamentos, pois não podemos alterar o agrupamento no nível da tabela. A mensagem de erro comum que você notará é algo como “Não é possível resolver o conflito de agrupamento entre “Collation1” e “Collation2” na operação igual a”. Collation1 e Collation2 podem ser qualquer agrupamento usado em uma consulta. Usando um exemplo simples, podemos produzir uma demonstração desse conflito de agrupamento. Se você concluiu os exemplos anteriores deste artigo, já terá uma tabela chamada “emp”. Basta criar uma tabela temporária em seu banco de dados de demonstração e inserir registros usando o script de exemplo fornecido.
create table #emptemp (id int, fname nvarchar(20)) insert into #emptemp select * from emp
Basta executar uma junção usando ambas as tabelas e você obterá esse erro de conflito de agrupamento, conforme mostrado abaixo.
select e.id, et.fname from emp e inner join #emptemp et on e.fname=et.fname

Você notará que o agrupamento do banco de dados do usuário usado é “SQL_Latin1_General_CP1_CS_AS” e não corresponde ao agrupamento do servidor. Para corrigir esse tipo de erro, você pode alterar as colunas usadas nos objetos temporários para usar o agrupamento padrão do banco de dados do usuário. Você pode usar a opção “database_default” ou fornecer explicitamente o nome do agrupamento do banco de dados do usuário. Neste exemplo, usamos o agrupamento “SQL_Latin1_General_CP1_CS_AS”. Experimente uma destas opções
Opção 1: Use a opção database_default
alter table #emptemp alter column fname nvarchar(20) collate database_default
Feito isso, execute a instrução select novamente e o erro será corrigido.
Opção 2: Use o agrupamento do banco de dados do usuário explicitamente
alter table #emptemp alter column fname nvarchar(20) collate SQL_Latin1_General_CP1_CS_AS
Uma vez feito, execute a instrução select novamente e o erro será corrigido.
Conclusão
Neste artigo, você descobriu sobre:
• o conceito de agrupamento
• as diferentes opções de agrupamento disponíveis
• encontrar detalhes de agrupamento para qualquer instância, banco de dados e coluna SQL
• A EXEMPLO DE TRABALHO ao experimentar opções de agrupamento em consultas SQL
• alterando agrupamentos no nível de instância, nível de banco de dados e nível de coluna
• COMO alterar agrupamentos de bancos de dados do sistema
• um conflito de agrupamento e como para fixar isso
Agora você sabe sobre a importância da ordenação e a importância de configurar a ordenação correta na instância SQL e também nos objetos do banco de dados. Sempre teste os vários cenários em seu ambiente de teste antes de aplicar qualquer uma das opções acima em seus sistemas de produção.