O SQL Server nos oferece diferentes soluções para replicar ou arquivar uma tabela ou tabelas de banco de dados em outro banco de dados, ou o mesmo banco de dados com nomes diferentes. Como SQL Server Developer ou Administrador de Banco de Dados, você pode enfrentar situações em que precisa verificar se os dados dessas duas tabelas são idênticos e, se, por engano, os dados não forem replicados entre essas duas tabelas, será necessário sincronizar os dados entre as mesas. Além disso, se você receber uma mensagem de erro, que interrompe o processo de sincronização ou replicação de dados, devido a diferenças de esquema entre as tabelas de origem e destino, você precisa encontrar uma maneira fácil e rápida de identificar as diferenças de esquema, ALTER as tabelas para fazer o esquema idêntico em ambos os lados e retomar o processo de sincronização de dados.
Em outras situações, você precisa de uma maneira fácil de obter a resposta SIM ou NÃO, se os dados e o esquema de duas tabelas forem idênticos ou não. Neste artigo, veremos as diferentes maneiras de comparar os dados e o esquema entre duas tabelas. Os métodos fornecidos neste artigo compararão tabelas hospedadas em bancos de dados diferentes, que é o cenário mais complicado, e também podem ser facilmente usados para comparar as tabelas localizadas no mesmo banco de dados com nomes diferentes.
Antes de descrever os diferentes métodos e ferramentas que podem ser usados para comparar os dados e esquemas das tabelas, vamos preparar nosso ambiente de demonstração criando dois novos bancos de dados e criando uma tabela em cada banco de dados, com uma pequena diferença de tipo de dados entre essas duas tabelas, pois mostrado nas instruções CREATE DATABASE e CREATE TABLE T-SQL abaixo:
CREATE DATABASE TESTDB CREATE DATABASE TESTDB2 CREATE TABLE TESTDB.dbo.FirstComTable ( ID INT IDENTITY (1,1) PRIMARY KEY, FirstName VARCHAR (50), LastName VARCHAR (50), Address VARCHAR (500) ) GO CREATE TABLE TESTDB2.dbo.FirstComTable ( ID INT IDENTITY (1,1) PRIMARY KEY, FirstName VARCHAR (50), LastName VARCHAR (50), Address NVARCHAR (400) ) GO
Após criar os bancos de dados e tabelas, preencheremos as duas tabelas com cinco linhas idênticas, em seguida, inseriremos outro novo registro apenas na primeira tabela, conforme mostrado nas instruções INSERT INTO T-SQL abaixo:
INSERT INTO TESTDB.dbo.FirstComTable VALUES ('AAA','BBB','CCC')
GO 5
INSERT INTO TESTDB2.dbo.FirstComTable VALUES ('AAA','BBB','CCC')
GO 5
INSERT INTO TESTDB.dbo.FirstComTable VALUES ('DDD','EEE','FFF')
GO Agora o ambiente de teste está pronto para começar a descrever os métodos de comparação de dados e esquema.
Compare dados de tabelas usando um LEFT JOIN
A palavra-chave LEFT JOIN T-SQL é usada para recuperar dados de duas tabelas, retornando todos os registros da tabela da esquerda e apenas os registros correspondentes da tabela da direita e valores NULL da tabela da direita quando não houver correspondência entre as duas tabelas.
Para fins de comparação de dados, a palavra-chave LEFT JOIN pode ser usada para comparar duas tabelas, com base na coluna única comum, como a coluna ID em nosso caso, como na instrução SELECT abaixo:
SELECT * FROM TESTDB.dbo.FirstComTable F LEFT JOIN TESTDB2.dbo.FirstComTable S ON F.ID =S.ID
A consulta anterior retornará as cinco linhas comuns existentes nas duas tabelas, além da linha existente na primeira tabela e ausente na segunda, mostrando valores NULL no lado direito do resultado, conforme mostrado abaixo:
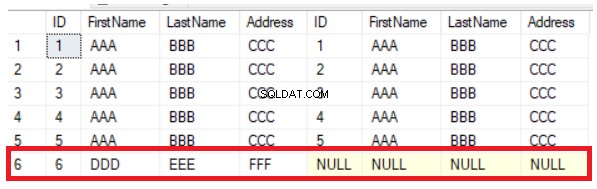
Você pode facilmente derivar do resultado anterior que a sexta coluna que existe na primeira tabela é perdida na segunda tabela. Para sincronizar as linhas entre as tabelas, você precisa inserir o novo registro na segunda tabela manualmente. O método LEFT JOIN é útil para verificar as novas linhas, mas não ajudará no caso de atualização dos valores das colunas. Se você alterar o valor da coluna Endereço da 5ª linha, o método LEFT JOIN não detectará essa alteração conforme mostrado claramente abaixo:
Comparar dados de tabelas usando a cláusula EXCEPT
A instrução EXCEPT retorna as linhas da primeira consulta (consulta esquerda) que não são retornadas da segunda consulta (consulta direita). Em outras palavras, a instrução EXCEPT retornará a diferença entre duas instruções ou tabelas SELECT, o que nos ajuda a comparar facilmente os dados nessas tabelas.
A instrução EXCEPT pode ser usada para comparar os dados nas tabelas criadas anteriormente, tomando a diferença entre a consulta SELECT * da primeira tabela e a consulta SELECT * da segunda tabela, usando as instruções T-SQL abaixo:
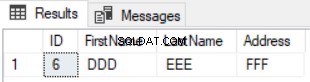
SELECT * FROM TESTDB.dbo.FirstComTable F EXCEPT SELECT * FROM TESTDB2.dbo. FirstComTable S
O resultado da consulta anterior será a linha que está disponível na primeira tabela e não disponível na segunda, conforme mostrado abaixo:
Usar a instrução EXCEPT para comparar duas tabelas é melhor do que a instrução LEFT JOIN, pois os registros atualizados serão capturados no resultado das diferenças de dados. Suponha que atualizamos o endereço da linha número 5 na segunda tabela e verificamos a diferença usando a instrução EXCEPT novamente, você verá que a linha número 5 será retornada com o resultado das diferenças conforme mostrado abaixo:
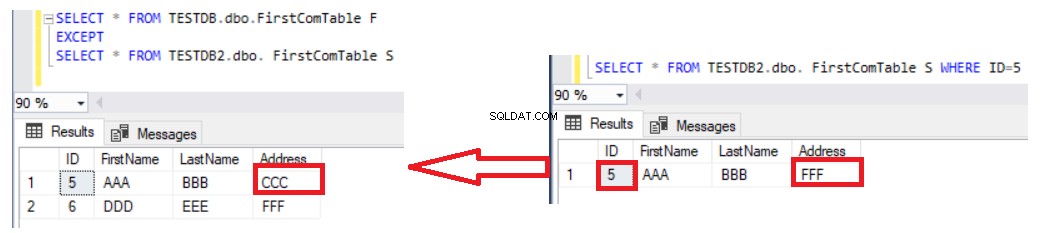
A única desvantagem de usar a instrução EXCEPT para comparar os dados em duas tabelas é que você precisa sincronizar os dados manualmente escrevendo uma instrução INSERT para os registros ausentes na segunda tabela. Leve em consideração que as duas tabelas que são comparadas são tabelas chaveadas para ter o resultado correto, com uma chave única usada para comparação. Se removermos a coluna ID exclusiva da instrução SELECT em ambos os lados da instrução EXCEPT e listarmos o restante das colunas não-chave, como na instrução abaixo:
SELECT FirstName, LastName, Address FROM TESTDB.dbo. FirstComTable F EXCEPT SELECT FirstName, LastName, Address FROM TESTDB2.dbo. FirstComTable S
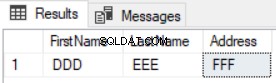
O resultado mostrará que apenas os novos registros são retornados, e os atualizados não serão listados, conforme mostrado no resultado abaixo:
Comparar dados de tabelas usando UNION ALL … GROUP BY
A instrução UNION ALL também pode ser usada para comparar os dados em duas tabelas, com base em uma coluna de chave exclusiva. Para usar a instrução UNION ALL para retornar a diferença entre duas tabelas, você precisa listar as colunas a serem comparadas na instrução SELECT e usar essas colunas na cláusula GROUP BY, conforme mostrado na consulta T-SQL abaixo:
SELECT DISTINCT *
FROM
(
SELECT * FROM
( SELECT * FROM TESTDB.dbo. FirstComTable
UNION ALL
SELECT * FROM TESTDB2.dbo. FirstComTable) Tbls
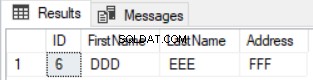
GROUP BY ID,FirstName, LastName, Address
HAVING COUNT(*)<2) Diff E somente a linha que existe na primeira tabela e perdida na segunda tabela será retornada conforme mostrado abaixo:
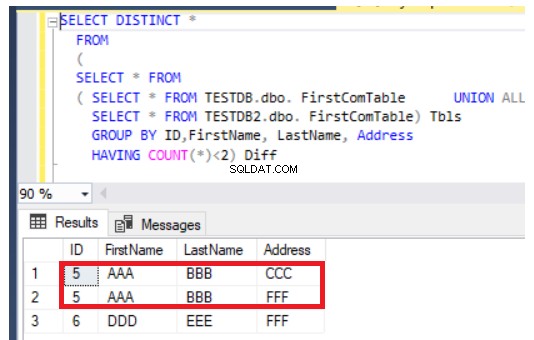
A consulta anterior também funcionará bem no caso de atualização de registros, mas de forma diferente. Ele retornará os registros recém inseridos além das colunas atualizadas de ambas as tabelas, como no caso da linha número 5, mostrada abaixo:
Compare dados de tabelas usando as ferramentas de dados do SQL Server
O SQL Server Data Tools, também conhecido como SSDT, construído sobre o Microsoft Visual Studio pode ser facilmente usado para comparar os dados em duas tabelas com o mesmo nome, com base em uma coluna de chave exclusiva, hospedada em dois bancos de dados diferentes e sincronizar os dados nessas tabelas , ou gere um script de sincronização para ser usado posteriormente.
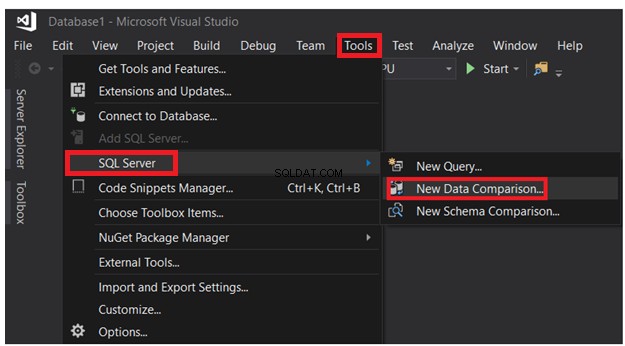
Na janela SSDT aberta, clique no menu Ferramentas -> lista SQL Server e escolha a Nova comparação de dados opção, como mostrado abaixo:
Na janela de conexão exibida, você pode escolher entre as sessões conectadas anteriormente ou preencher a janela Propriedades da Conexão com o nome do SQL Server, as credenciais e o nome do banco de dados e clicar em Conectar , como mostrado abaixo:

No assistente de Nova Comparação de Dados exibido, especifique os nomes dos bancos de dados de origem e destino e as opções de comparação usadas no processo de comparação de tabelas e clique em Avançar , como mostrado abaixo:
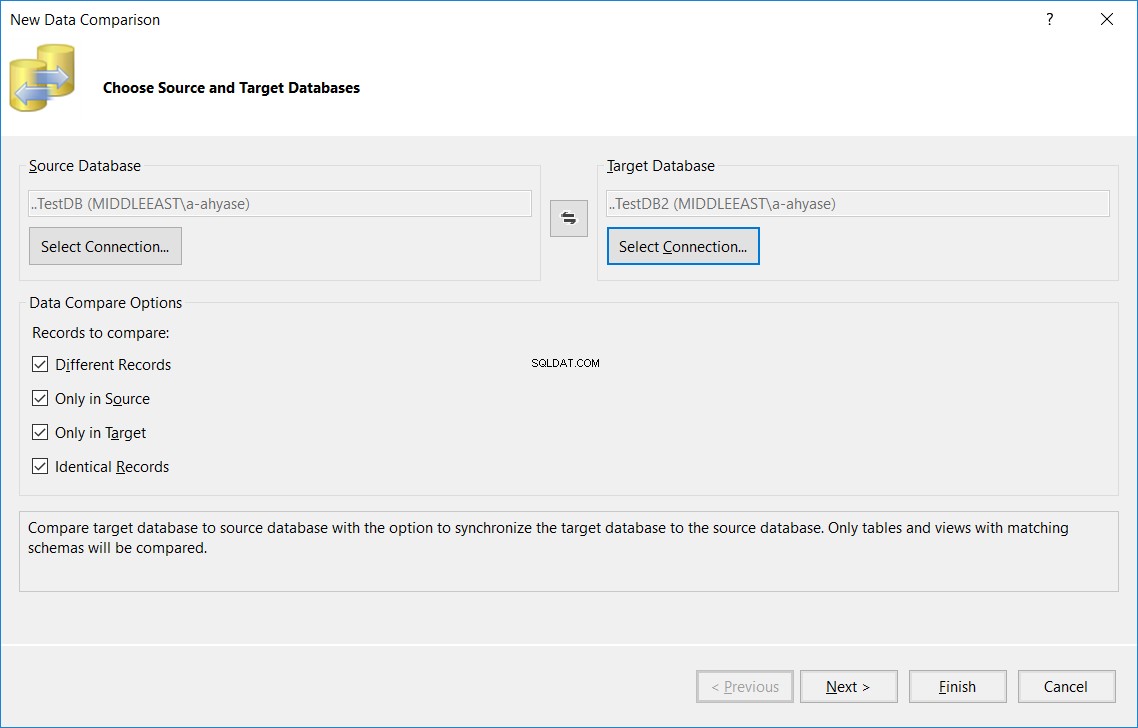
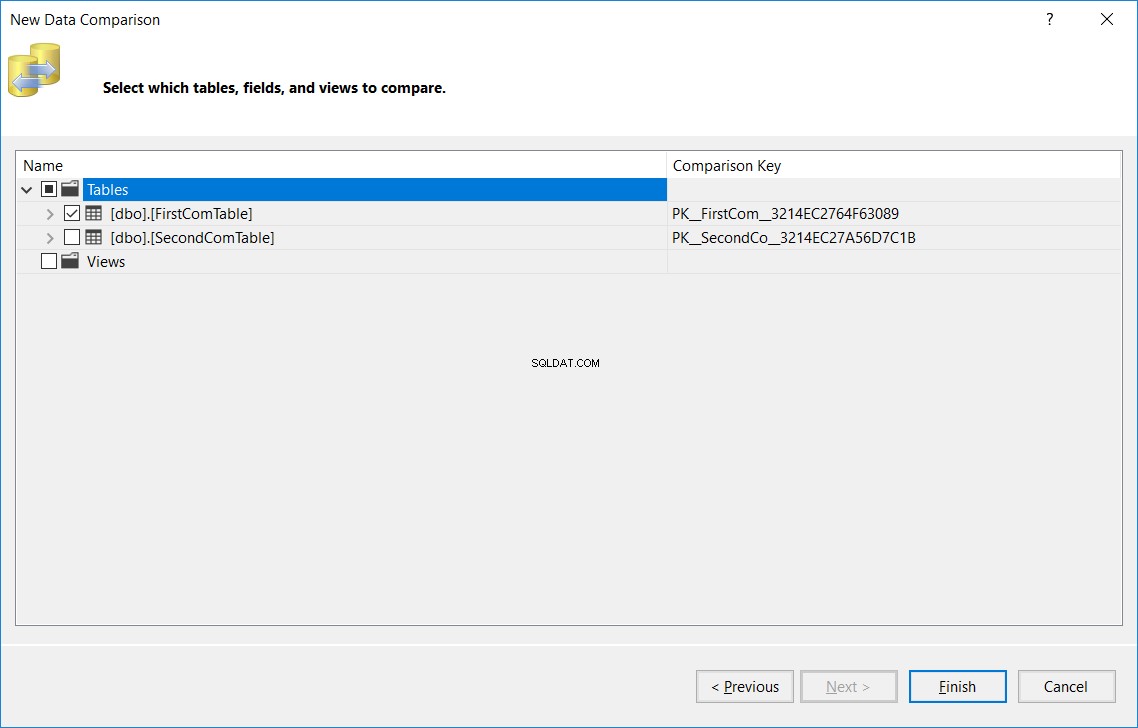
Na próxima janela, especifique o nome da tabela, que deve ser o mesmo nome nos bancos de dados de origem e destino, que serão comparados nos dois bancos de dados e clique em Concluir , como abaixo:
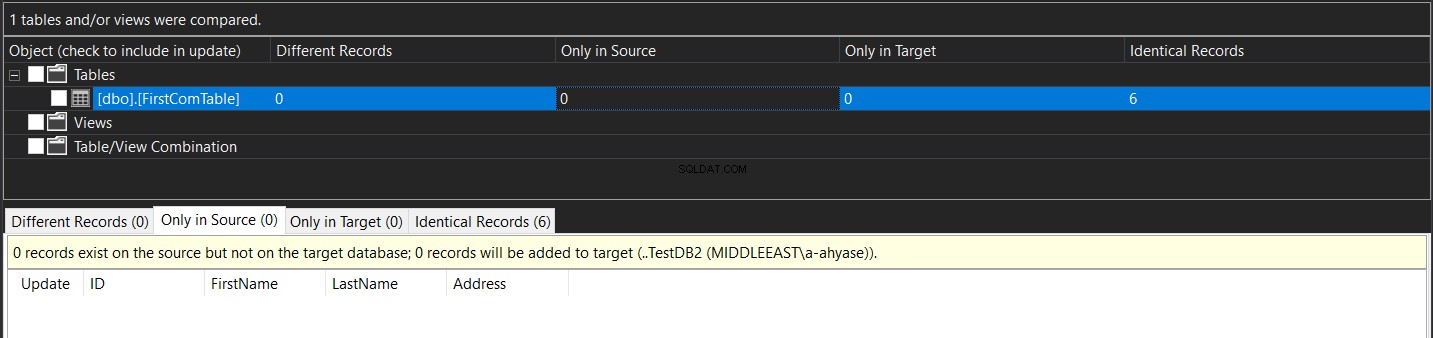
O resultado exibido mostrará o número de registros encontrados na origem e perdidos no destino, encontrados no destino e perdidos na origem, o número de registros atualizados com a mesma chave e valores de colunas diferentes (Registros Diferentes) e por fim o número de registros idênticos encontrados em ambas as tabelas, conforme demonstrado abaixo:
Clique no nome da tabela no resultado anterior, você encontrará uma visão detalhada desses achados, conforme mostrado abaixo:

Você pode usar a mesma ferramenta para gerar um script para sincronizar as tabelas de origem e destino ou atualizar a tabela de destino diretamente com as alterações ausentes ou diferentes, conforme abaixo:
Se você clicar na opção Gerar Script, uma instrução INSERT com a coluna ausente na tabela de destino será exibida, conforme mostrado abaixo:
BEGIN TRANSACTION
BEGIN TRANSACTION SET IDENTITY_INSERT [dbo].[FirstComTable] ON INSERT INTO [dbo].[FirstComTable] ([ID], [FirstName], [LastName], [Address]) VALUES (6, N'DDD', N'EEE', N'FFF') SET IDENTITY_INSERT [dbo].[FirstComTable] OFF COMMIT TRANSACTION
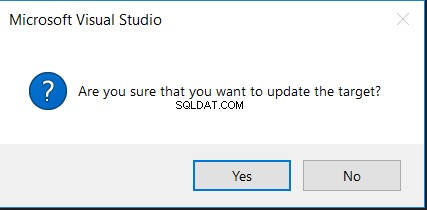
Escolher a opção Atualizar Alvo solicitará primeiro sua confirmação para realizar a alteração, conforme a mensagem abaixo:
Após a sincronização, você verá que os dados nas duas tabelas serão idênticos, conforme mostrado abaixo:
Compare dados de tabelas usando a ferramenta de terceiros “dbForge Studio for SQL Server”
No mundo do SQL Server, você pode encontrar um grande número de ferramentas de terceiros que facilitam a vida dos administradores e desenvolvedores de banco de dados. Uma dessas ferramentas, que torna as tarefas de administração de banco de dados muito fáceis, é o dbForge Studio para SQL Server, que nos fornece maneiras fáceis de executar as tarefas de administração e desenvolvimento de banco de dados. Essa ferramenta também pode nos ajudar a comparar os dados nas tabelas do banco de dados e sincronizar essas tabelas.
No menu Comparação, escolha Nova comparação de dados opção, como mostrado abaixo:
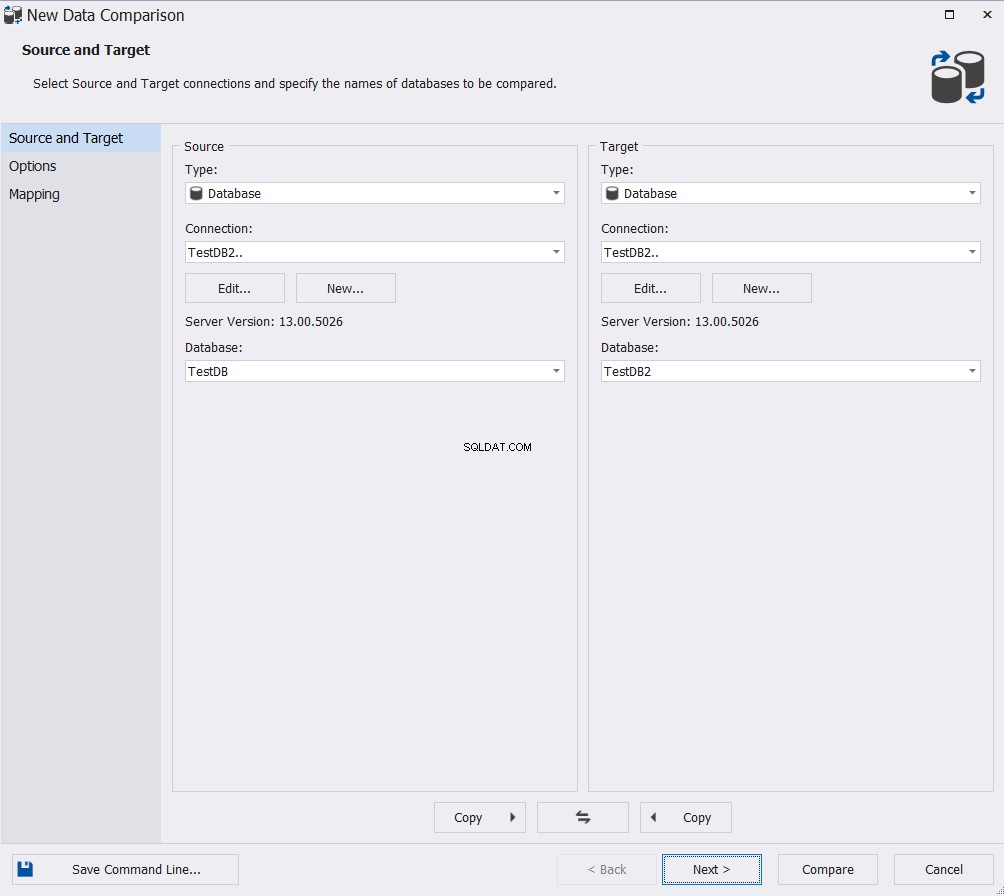
No assistente de Nova Comparação de Dados, especifique o banco de dados de origem e de destino e clique em Avançar :
Escolha as opções adequadas na ampla variedade de opções de mapeamento e comparação disponíveis e clique em Avançar :
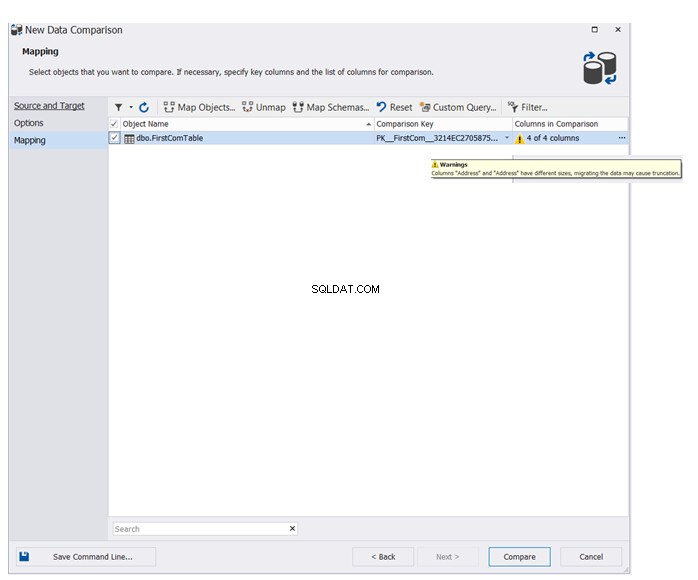
Especifique o nome da tabela ou tabelas que participarão do processo de comparação de dados. O assistente exibirá uma mensagem de aviso caso haja diferenças de esquema entre as tabelas de bancos de dados de origem e destino. Clique em Comparar para prosseguir:
O resultado final mostrará detalhadamente as diferenças de dados entre as tabelas de origem e destino, com a possibilidade de clicar
 para sincronizar as tabelas de origem e destino, conforme mostrado abaixo:
para sincronizar as tabelas de origem e destino, conforme mostrado abaixo: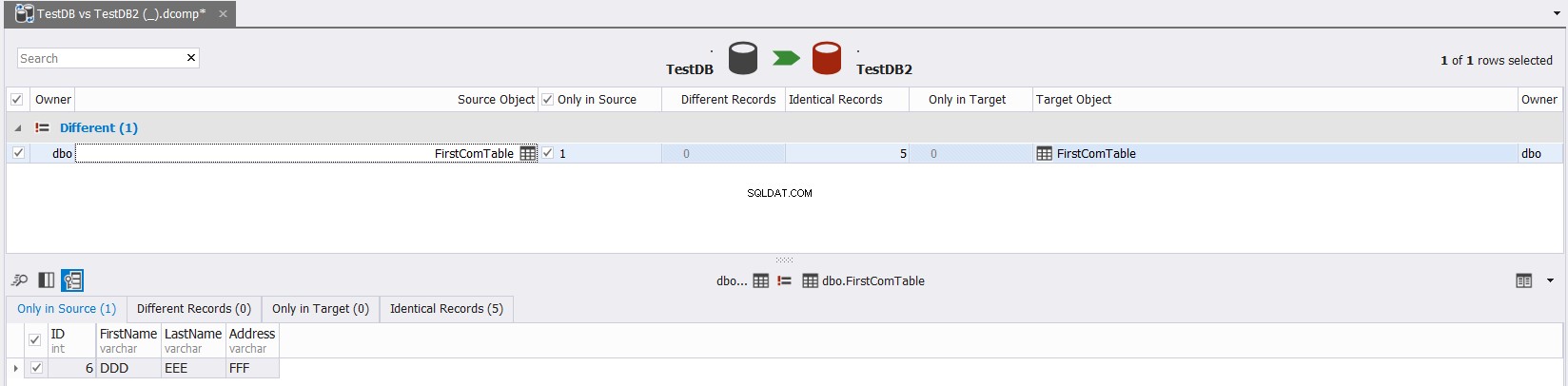
Comparar esquema de tabelas usando sys.columns
Conforme mencionado no início deste artigo, para replicar ou arquivar uma tabela, você precisa verificar se o esquema das tabelas de origem e destino é idêntico. O SQL Server nos fornece diferentes maneiras de comparar o esquema das tabelas no mesmo banco de dados ou em bancos de dados diferentes. O primeiro método é consultar a exibição do catálogo do sistema sys.columns, que retorna uma linha para cada coluna de um objeto que possui uma coluna, com as propriedades de cada coluna.
Para comparar o esquema de tabelas localizadas em diferentes bancos de dados, você precisa fornecer a sys.columns o nome da tabela no banco de dados atual, sem poder fornecer uma tabela hospedada em outro banco de dados. Para isso, vamos consultar o sys.columns duas vezes, salvar o resultado de cada consulta em uma tabela temporária e, finalmente, comparar o resultado dessas duas consultas usando o comando EXCEPT T-SQL, conforme mostrado claramente abaixo:
USE TESTDB SELECT name, system_type_id, user_type_id,max_length, precision,scale, is_nullable, is_identity INTO #DBSchema FROM sys.columns WHERE object_id = OBJECT_ID(N'dbo.FirstComTable') GO USE TestDB2 GO SELECT name, system_type_id, user_type_id,max_length, precision,scale, is_nullable, is_identity INTO #DB2Schema FROM sys.columns WHERE object_id = OBJECT_ID(N'dbo.FirstComTable '); GO SELECT * FROM #DBSchema EXCEPT SELECT * FROM #DB2Schema
O resultado nos mostrará que a definição da coluna Address é diferente nessas duas tabelas, sem informações específicas sobre a diferença exata, conforme mostrado abaixo:

Comparar o esquema de tabelas usando INFORMATION_SCHEMA.COLUMNS
A visualização do sistema INFORMATION_SCHEMA.COLUMNS também pode ser usada para comparar o esquema de diferentes tabelas, fornecendo o nome da tabela. Novamente, para comparar duas tabelas hospedadas em bancos de dados diferentes, vamos consultar o INFORMATION_SCHEMA.COLUMNS duas vezes, manter o resultado de cada consulta em uma tabela temporária e por fim comparar o resultado dessas duas consultas usando o comando EXCEPT T-SQL, conforme mostrado claramente abaixo:
USE TestDB SELECT COLUMN_NAME, IS_NULLABLE,DATA_TYPE,CHARACTER_MAXIMUM_LENGTH, NUMERIC_PRECISION,NUMERIC_SCALE INTO #DBSchema FROM [INFORMATION_SCHEMA].[COLUMNS] SC1 WHERE SC1.TABLE_NAME='FirstComTable' GO USE TestDB2 SELECT COLUMN_NAME, IS_NULLABLE,DATA_TYPE,CHARACTER_MAXIMUM_LENGTH, NUMERIC_PRECISION,NUMERIC_SCALE INTO #DB2Schema FROM [INFORMATION_SCHEMA].[COLUMNS] SC2 WHERE SC2.TABLE_NAME='FirstComTable' GO SELECT * FROM #DBSchema EXCEPT SELECT * FROM #DB2Schema
E o resultado será de alguma forma semelhante ao anterior, mostrando que a definição da coluna Address é diferente nessas duas tabelas, sem informações específicas sobre a diferença exata, conforme mostrado abaixo:

Compare o esquema de tabelas usando dm_exec_describe_first_result_set
Os esquemas de tabelas também podem ser comparados consultando a função de gerenciamento dinâmico dm_exec_describe_first_result_set, que usa uma instrução Transact-SQL como parâmetro e descreve os metadados do primeiro conjunto de resultados para a instrução.
Para comparar o esquema de duas tabelas, você precisa unir o DMF dm_exec_describe_first_result_set consigo mesmo, fornecendo a instrução SELECT de cada tabela como parâmetro, como na consulta T-SQL abaixo:
SELECT FT.name , ST.name , FT.system_type_name , ST.system_type_name , FT.max_length , ST.max_length , FT.precision , ST.precision , FT.scale , ST.scale , FT.is_nullable , ST.is_nullable , FT.is_identity_column , ST.is_identity_column FROM sys.dm_exec_describe_first_result_set (N'SELECT * FROM TestDB.DBO.FirstComTable', NULL, 0) FT LEFT OUTER JOIN sys.dm_exec_describe_first_result_set (N'SELECT * FROM TestDB2.DBO.FirstComTable', NULL, 0) ST ON FT.Name =ST.Name GO
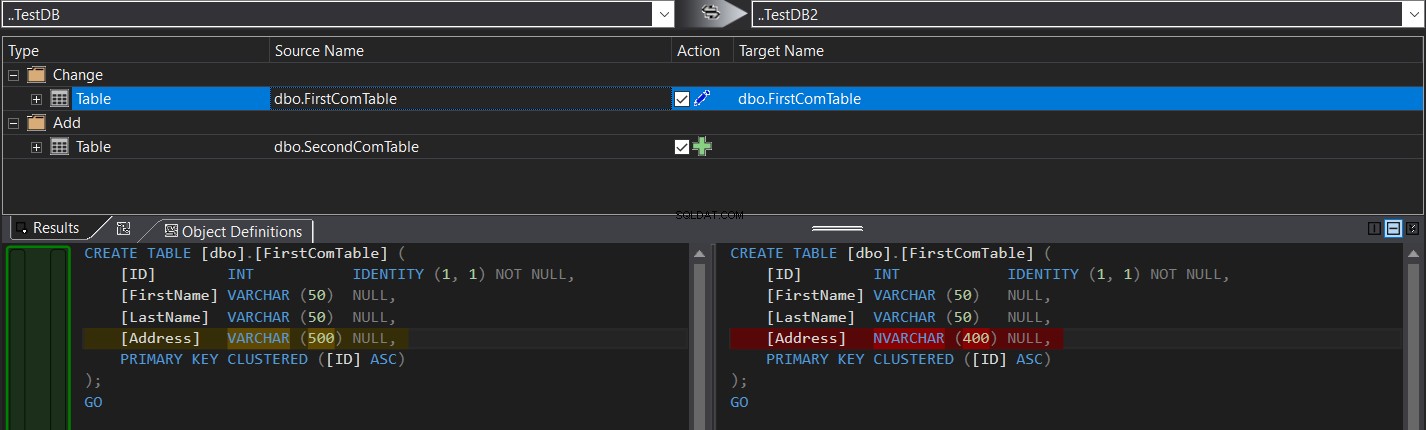
O resultado será mais claro desta vez, pois você pode comparar a olho nu, a diferença entre as duas tabelas, ou seja, o tamanho e o tipo da coluna Endereço, conforme mostrado abaixo:

Compare o esquema de tabelas usando as ferramentas de dados do SQL Server
O SQL Server Data Tools também pode ser usado para comparar o esquema de tabelas localizadas em diferentes bancos de dados. No menu Ferramentas, escolha Nova comparação de esquema opção da lista de opções do SQL Server, conforme mostrado abaixo:
Após fornecer os parâmetros de conexão, clique no botão Comparar:

O resultado da comparação mostrará, especificamente, a diferença de esquema entre as duas tabelas na forma de comandos CREATE TABLE T-SQL, sombreados como no instantâneo abaixo:
Você pode clicar facilmente
 para sincronizar o esquema da tabela ou clique
para sincronizar o esquema da tabela ou clique  para fazer o script da alteração e executá-la posteriormente, conforme mostrado abaixo:
para fazer o script da alteração e executá-la posteriormente, conforme mostrado abaixo: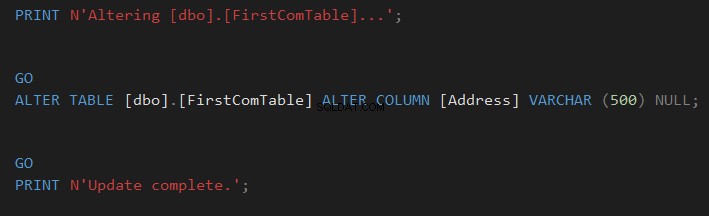
Compare o esquema de tabelas usando o dbForge Studio para a ferramenta de terceiros do SQL Server
A ferramenta dbForge Studio for SQL Server nos fornece a capacidade de comparar o esquema das diferentes tabelas do banco de dados. No menu Comparação, escolha a Nova comparação de esquema opção, conforme abaixo:
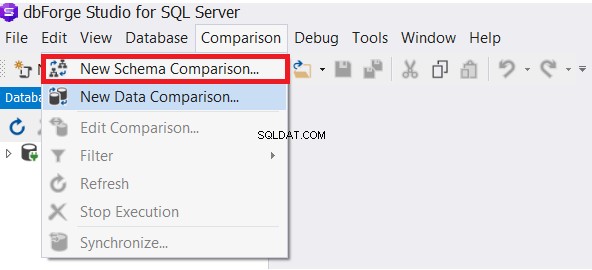
Depois de especificar as propriedades de conexão dos bancos de dados de origem e destino, escolha a opção de mapeamento adequada entre as opções disponíveis e clique em Avançar :
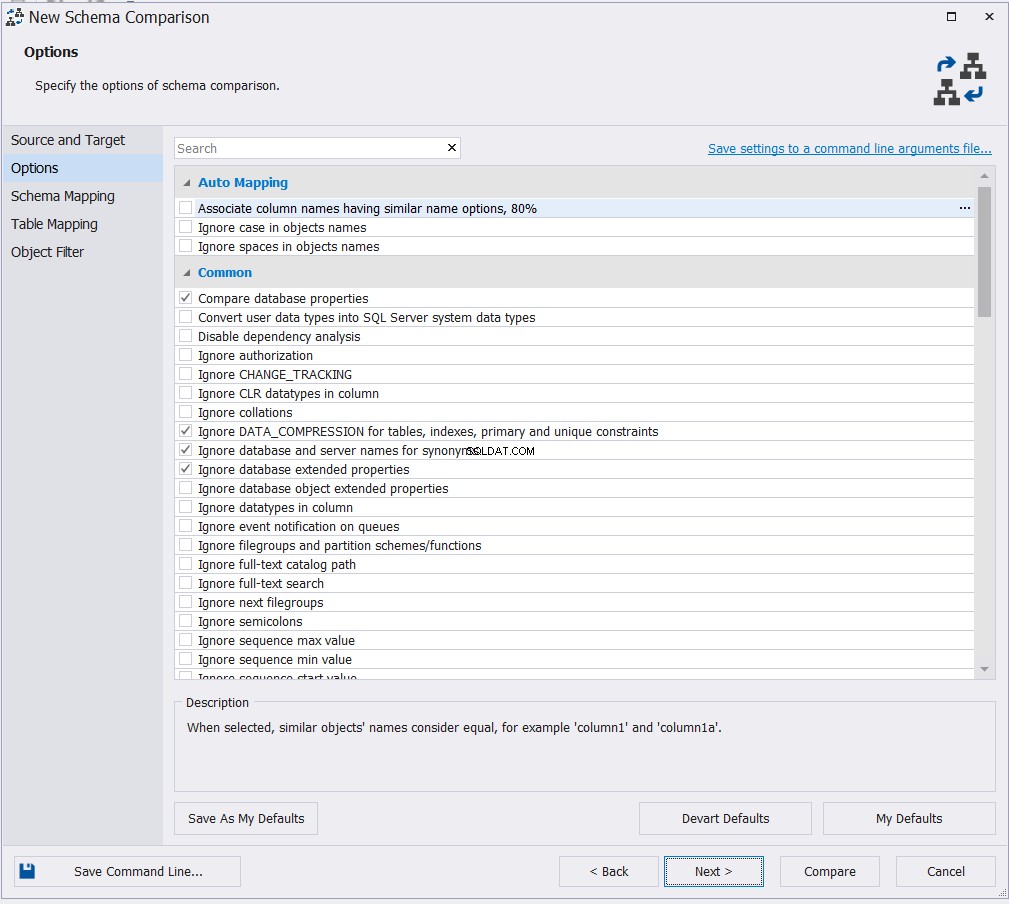
Escolha os esquemas que você irá comparar seu objeto e clique em Próximo :
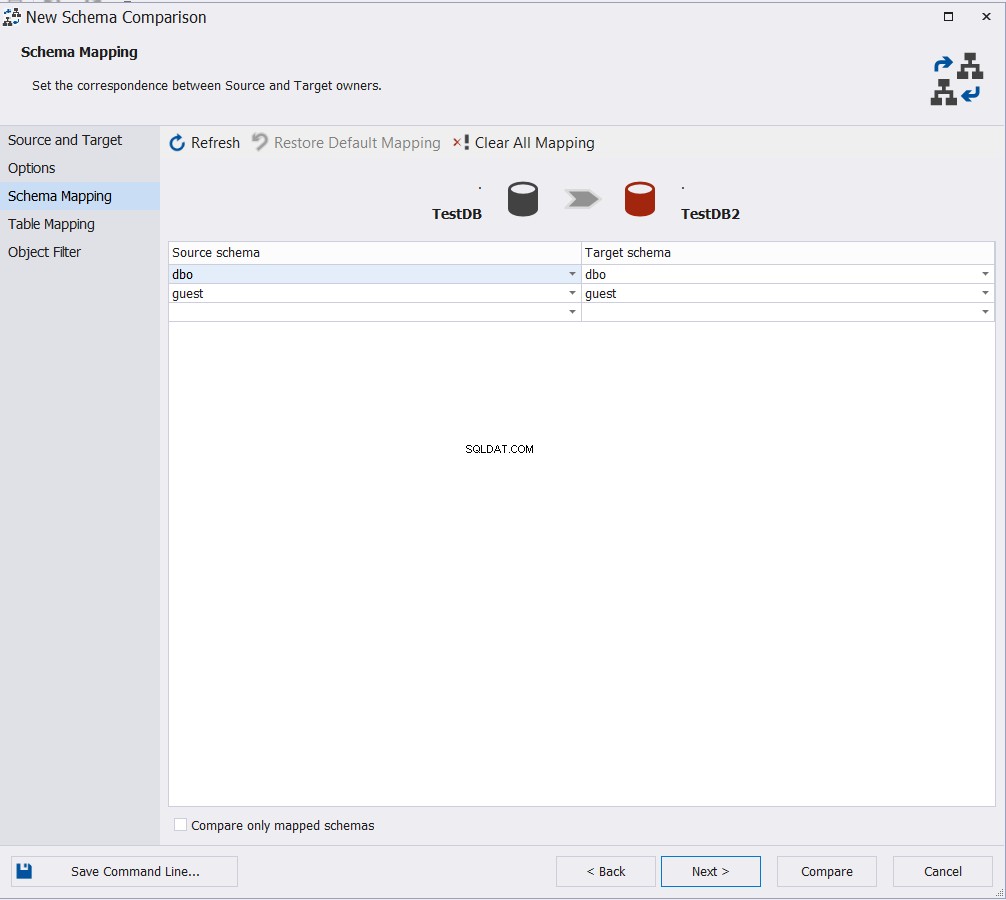
Especifique a tabela ou tabelas que participarão do processo de comparação de esquema e clique em Comparar , se você quiser pular a alteração das configurações padrão na janela Filtro de Objetos, conforme abaixo:
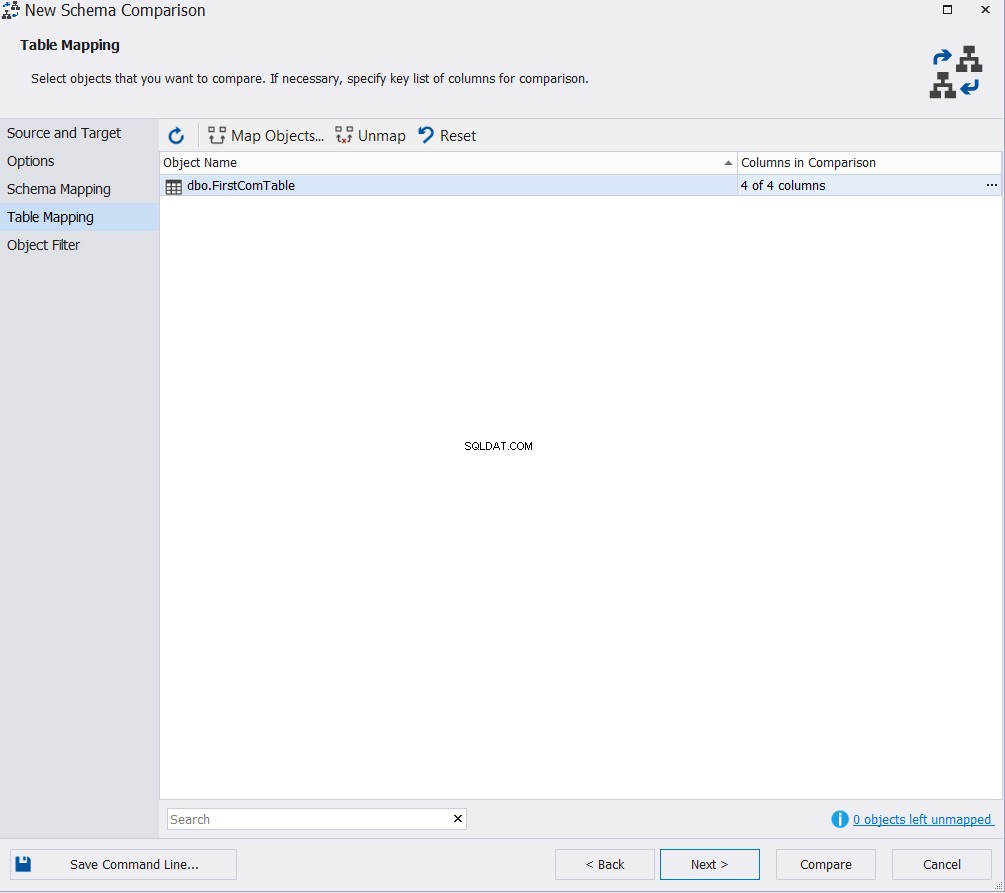
O resultado da comparação exibido mostrará a diferença entre o esquema das duas tabelas, destacando exatamente a parte do tipo de dados que difere entre as duas colunas, com a capacidade de especificar qual ação deve ser feita para sincronizar as duas tabelas, conforme mostrado abaixo :
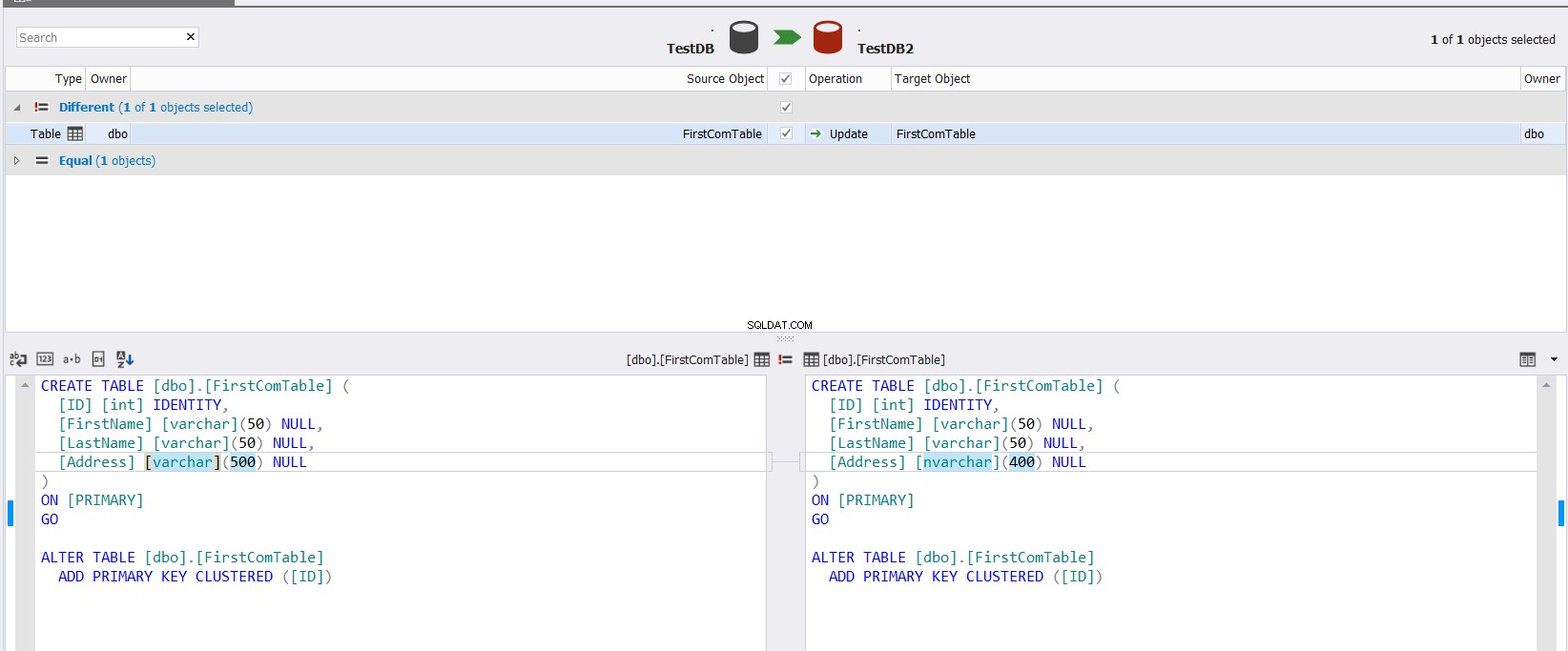
Se você conseguir sincronizar o esquema das duas tabelas, clique no botão e especifique no assistente de Sincronização de Esquemas se consegue executar a alteração diretamente na tabela de destino, ou apenas fazer um script para ser usado no futuro, conforme abaixo:
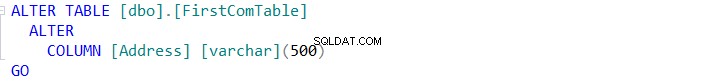
Links úteis:
- Operadores de conjunto – EXCEPT e INTERSECT (Transact-SQL)
- Operadores de conjunto – UNION (Transact-SQL)
- Faça o download do SQL Server Data Tools (SSDT)
- Compare e sincronize dados em uma ou mais tabelas com dados em um banco de dados de referência
- sys.dm_exec_describe_first_result_set (Transact-SQL)
- sys.columns (Transact-SQL)
- Exibições de esquema de informações do sistema (Transact-SQL)
Ferramentas úteis:
dbForge Schema Compare for SQL Server – ferramenta confiável que economiza seu tempo e esforço ao comparar e sincronizar bancos de dados no SQL Server.
dbForge Data Compare for SQL Server – poderosa ferramenta de comparação SQL capaz de trabalhar com big data.



