Este é o primeiro artigo de uma série de artigos sobre OLTP na memória. Ele ajuda você a entender como o novo mecanismo Hekaton funciona internamente. Vamos nos concentrar em detalhes de tabelas e índices otimizados na memória. Este é o artigo de nível básico, o que significa que você não precisa ser um especialista em SQL Server, no entanto, você precisa ter algum conhecimento básico sobre o mecanismo tradicional do SQL Server.
Introdução
O mecanismo OLTP In-Memory do SQL Server 2014 (projeto Hekaton) foi criado desde o início para utilizar terabytes de memória disponível e um grande número de núcleos de processamento. O OLTP na memória permite que os usuários trabalhem com tabelas e índices com otimização de memória e procedimentos armazenados compilados nativamente. Você pode usá-lo junto com as tabelas e índices baseados em disco e os procedimentos armazenados T-SQL, que o SQL Server sempre forneceu.
Os recursos internos e os recursos do mecanismo OLTP na memória diferem significativamente do mecanismo relacional padrão. Você precisa revisar quase tudo o que sabia sobre como vários processos simultâneos são tratados.
O mecanismo do SQL Server é otimizado para armazenamento baseado em disco. Ele lê páginas de dados de 8 KB na memória para processamento e grava páginas de dados de 8 KB de volta no disco após modificações. Obviamente, o SQL Server corrige principalmente as alterações no disco no log de transações. Ler páginas de dados de 8 KB do disco e gravá-las de volta pode gerar muita E/S e levar a um custo de latência mais alto. Mesmo quando os dados no cache de buffer, o SQL Server é projetado para assumir que não é, o que leva ao uso ineficiente da CPU.
Considerando as limitações das estruturas tradicionais de armazenamento baseadas em disco, a equipe do SQL Server começou a construir um mecanismo de banco de dados otimizado para memória principal grande e CPUs de vários núcleos. A equipe estabeleceu os seguintes objetivos:
- Otimizado para dados que foram armazenados completamente na memória, mas também foram duráveis nas reinicializações do SQL Server
- Totalmente integrado ao mecanismo existente do SQL Server
- Alto desempenho para operações OLTP
- Projetado para CPUs modernas
O OLTP In-Memory do SQL Server atende a todos esses objetivos.
Sobre o OLTP na memória
O OLTP In-Memory do SQL Server 2014 fornece várias tecnologias para trabalhar com tabelas com otimização de memória, juntamente com as tabelas baseadas em disco. Por exemplo, ele permite acessar dados na memória utilizando interfaces padrão, como T-SQL e SSMS. A ilustração a seguir demonstra tabelas e índices otimizados para memória, como parte do OLTP In-Memory (à esquerda) e das tabelas baseadas em disco (à esquerda) que exigem a leitura e gravação de páginas de dados de 8 KB. O OLTP na memória também oferece suporte a procedimentos armazenados compilados nativamente e fornece um novo compilador OLTP na memória.
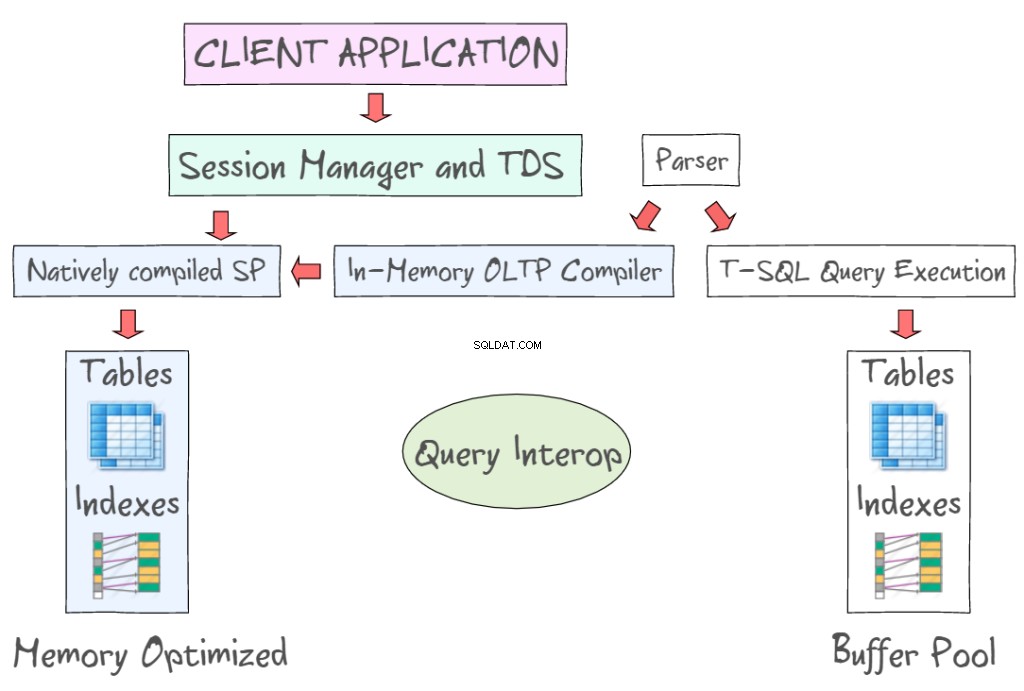
Query Interop permite interpretar T-SQL para fazer referência a tabelas com otimização de memória. Se uma transação fizer referência a tabelas com otimização de memória e baseadas em disco, ela poderá ser chamada de transação entre contêineres. O aplicativo cliente utiliza o Tabular Data Stream – um protocolo de camada de aplicativo usado para transferir dados entre um servidor de banco de dados e um cliente. Ele foi inicialmente projetado e desenvolvido pela Sybase Inc. para seu mecanismo de banco de dados relacional Sybase SQL Server em 1984, e mais tarde pela Microsoft no Microsoft SQL Server.
Tabelas com otimização de memória
Ao acessar tabelas baseadas em disco, os dados necessários podem já estar na memória, embora não estejam. Se os dados não estiverem na memória, o SQL Server precisará lê-los do disco. A diferença mais fundamental ao usar tabelas com otimização de memória é que a tabela inteira e seus índices são armazenados na memória o tempo todo . As operações de dados simultâneas não requerem bloqueio ou travamento.
Enquanto um usuário modifica os dados na memória, o SQL Server executa alguma E/S de disco para qualquer tabela que precise ser durável, de outra forma, onde precisamos de uma tabela para reter os dados na memória no momento de uma falha ou reinicialização do servidor.
Estrutura de armazenamento baseada em linha
Outra diferença significativa é a estrutura de armazenamento subjacente. As tabelas baseadas em disco são otimizadas para endereçáveis em bloco armazenamento em disco, enquanto as tabelas otimizadas na memória são otimizadas para endereçáveis por byte armazenamento de memória.
O SQL Server mantém as linhas de dados em páginas de dados de 8K, com alocação de espaço de extensões para tabelas baseadas em disco. A página de dados é a unidade fundamental de armazenamento em disco e memória. Ao ler e gravar dados do disco, o SQL Server lê e grava apenas as páginas de dados relevantes. Uma página de dados conterá apenas dados de uma tabela ou índice. Os processos do aplicativo modificam as linhas em diferentes páginas de dados conforme necessário. Posteriormente, durante a operação CHECKPOINT, o SQL Server primeiro corrige os registros de log no disco e, em seguida, grava todas as páginas sujas no disco. Essa operação geralmente causa muitas E/S físicas aleatórias.
Para tabelas com otimização de memória, não há páginas de dados, nem extensões. Existem apenas linhas de dados gravadas na memória sequencialmente, na ordem em que as transações ocorreram. Cada linha contém um ponteiro de índice para a próxima linha. Todas as E/S são varreduras na memória dessas estruturas. Não há noção de linhas de dados sendo gravadas em um local específico que pertence a um objeto especificado. No entanto, você não precisa pensar que as tabelas com otimização de memória são armazenadas como o conjunto desorganizado de linhas de dados (semelhante a heaps baseados em disco). Cada instrução CREATE TABLE para uma tabela com otimização de memória cria pelo menos um índice que o SQL Server usa para vincular todas as linhas de dados dessa tabela.
Cada linha de dados consiste no cabeçalho da linha e na carga útil que são os dados reais da coluna. O cabeçalho armazena informações sobre a instrução que criou a linha, ponteiros para cada índice na tabela de destino e valores de carimbo de data/hora. Timestamp indica a hora em que uma transação inseriu e excluiu uma linha. Registros do SQL Server atualizados inserindo uma nova versão de linha e marcando a versão antiga como excluída. Várias versões da mesma linha podem existir a qualquer momento. Isso permite o acesso simultâneo à mesma linha durante a modificação dos dados. O SQL Server exibe a versão da linha relevante para cada transação de acordo com a hora em que a transação foi iniciada em relação aos carimbos de data/hora da versão da linha. Este é o núcleo do novo controle de simultaneidade de várias versões mecanismo para tabelas na memória.
A propósito, a Oracle possui um excelente sistema de controle de várias versões. Basicamente, funciona da seguinte forma:
- O usuário A inicia uma transação e atualiza 1.000 linhas com algum valor no momento T1.
- O usuário B lê as mesmas 1.000 linhas no momento T2.
- O usuário A atualiza a linha 565 com o valor Y (o valor original era X).
- O usuário B chega à linha 565 e descobre que uma transação está em operação desde a hora T1.
- O banco de dados retorna o registro não modificado dos logs. O valor retornado é o valor que foi confirmado no momento menor ou igual a T2.
- Se o registro não puder ser recuperado dos logs de redo, isso significa que o banco de dados não está configurado adequadamente. Mais espaço precisa ser alocado para os logs.
- Os resultados retornados são sempre os mesmos em relação à hora de início da transação. Assim, dentro da transação, a consistência de leitura é alcançada.
Tabelas compiladas nativamente
A grande diferença final é que as tabelas otimizadas na memória são compiladas nativamente . Quando um usuário cria uma tabela ou índice com otimização de memória, o SQL Server armazena a estrutura de cada tabela (junto com todos os índices) nos metadados. Mais tarde, o SQL Server utiliza esses metadados para compilar em DDL um conjunto de rotinas de linguagem nativa para acessar a tabela. Esses DDL estão associados ao banco de dados, mas não fazem parte dele.
Em outras palavras, o SQL Server mantém na memória não apenas tabelas e índices, mas também DDL para acessar e modificar essas estruturas. Depois que uma tabela foi alterada, o SQL Server precisa recriar todos os DDL para operações de tabela. É por isso que você não pode alterar uma tabela depois de criada. Essas operações são invisíveis para os usuários.
Procedimentos armazenados compilados nativamente
O melhor desempenho é obtido ao utilizar procedimentos armazenados compilados nativamente para acessar tabelas compiladas nativamente. Tais procedimentos contêm instruções do processador e podem ser executados diretamente pela CPU sem compilação adicional. No entanto, existem algumas restrições nas construções T-SQL para os procedimentos armazenados compilados nativamente (em comparação com o código interpretado tradicionalmente). Outro ponto significativo é que os procedimentos armazenados compilados nativamente só podem acessar tabelas com otimização de memória.
Sem bloqueios
O OLTP na memória é um sistema sem bloqueio. Isso é possível porque o SQL Server nunca modifica nenhuma linha existente. A operação UPDATE cria a nova versão e marca a versão anterior como excluída. Em seguida, insere uma nova versão de linha com novos dados dentro dela.
Índices
Como você deve ter adivinhado, os índices são muito diferentes dos tradicionais. As tabelas otimizadas na memória não têm páginas. O SQL Server utiliza índices para vincular todas as linhas que pertencem a uma tabela em uma única estrutura. Não podemos usar a instrução CREATE INDEX para criar um índice para a tabela otimizada na memória. Depois de criar a PRIMARY KEY em uma coluna, o SQL Server cria automaticamente um índice exclusivo nessa coluna. Na verdade, é o único índice exclusivo permitido. Você pode criar no máximo oito índices em uma tabela com otimização de memória.
Por analogia com as tabelas, o SQL Server mantém os índices otimizados para memória na memória. No entanto, o SQL Server nunca registra operações em índices. O SQL Server mantém os índices automaticamente durante as modificações da tabela.
As tabelas com otimização de memória suportam dois tipos de índices:índice de hash e índice de intervalo . Ambos são estruturas não agrupadas.
O índice de hash é um novo tipo de índice, projetado especificamente para tabelas com otimização de memória. É extremamente útil para realizar pesquisas em valores específicos. O próprio índice é armazenado como uma tabela de hash. É uma matriz de baldes de hash, onde cada balde é um ponteiro para uma única linha.
O índice de intervalo (não agrupado) é útil para recuperar intervalos de valores.
Recuperação
O mecanismo básico de restauração para um banco de dados com tabelas com otimização de memória é o mesmo que o mecanismo de recuperação de bancos de dados com tabelas baseadas em disco. No entanto, a recuperação de tabelas com otimização de memória inclui a etapa de carregar as tabelas com otimização de memória na memória antes que o banco de dados esteja disponível para acesso do usuário.
Quando o SQL Server é reiniciado, cada banco de dados passa pelas seguintes fases do processo de recuperação:análise , refazer e desfazer .
Na fase de análise, o mecanismo OLTP na memória identifica o inventário do ponto de verificação a ser carregado e pré-carrega suas entradas de log da tabela do sistema. Ele também processará alguns registros de log de alocação de arquivos.
Na fase de refazer, os dados dos pares de arquivos de dados e delta são carregados na memória. Em seguida, os dados são atualizados do log de transações ativo com base no último ponto de verificação durável e as tabelas na memória são preenchidas e os índices reconstruídos. Durante essa fase, a recuperação de tabela com otimização de memória e baseada em disco é executada simultaneamente.
A fase de desfazer não é necessária para tabelas com otimização de memória, pois o OLTP na memória não registra transações não confirmadas para tabelas com otimização de memória.
Quando todas as operações forem concluídas, o banco de dados estará disponível para acesso.
Resumo
Neste artigo, analisamos rapidamente o mecanismo OLTP In-Memory do SQL Server. Aprendemos que estruturas com otimização de memória são armazenadas na memória. Os processos de aplicativos podem encontrar os dados necessários acessando essas estruturas na memória sem a necessidade de E/S de disco. Nos artigos a seguir, veremos como criar e acessar bancos de dados e tabelas OLTP na memória.
Leitura adicional
OLTP na memória:o que há de novo no SQL Server 2016
Usando índices em tabelas com otimização de memória do SQL Server