O que é otimização de consulta no SQL Server? É um grande tema. Cada técnica ou problema precisa de um artigo separado para cobrir as bases. Mas quando você está apenas começando a melhorar seu jogo com consultas, você precisa de algo mais simples para confiar. Este é o objetivo deste artigo.
Você pode dizer que suas consultas são ótimas, tudo funciona bem e os usuários estão satisfeitos. Claro que o desempenho não é tudo. Os resultados também devem estar corretos. Seja uma junção, uma subconsulta, um sinônimo, uma CTE, uma visualização ou qualquer outra coisa, ela deve ter um desempenho aceitável.
E no final do dia, você pode ir para casa com seus usuários. Você não quer ficar no escritório corrigindo as consultas lentas durante a noite.
Antes de começar, deixe-me assegurar-lhe que a jornada não será difícil. Este será apenas um primer. Teremos exemplos que não serão muito estranhos para você também. Por fim, quando você estiver pronto para um estudo mais aprofundado, apresentaremos alguns links que você pode conferir.
Vamos começar.
1. A otimização de consulta SQL começa no design e na arquitetura
Surpreso? A otimização de consulta SQL não é uma reflexão tardia ou um band-aid quando algo quebra. Sua consulta é executada tão rapidamente quanto seu design permite. Estamos falando de tabelas normalizadas, tipos de dados corretos, uso de índices, arquivamento de dados antigos e qualquer uma das melhores práticas que você possa imaginar.
Um bom design de banco de dados funciona em sinergia com as configurações corretas de hardware e SQL Server. Você o projetou para funcionar sem problemas por vários anos e ainda se sentir novo? Esse é um grande sonho, mas temos apenas um certo (geralmente – curto) tempo para pensar sobre isso.
Não será perfeito no primeiro dia de produção, mas deveríamos ter coberto as bases. Vamos minimizar a dívida técnica. Se você está trabalhando com uma equipe, isso é ótimo comparado a um show de um homem só. Você pode cobrir grande parte dos sinos e assobios.
Ainda assim, e se o banco de dados estiver funcionando ao vivo e você atingir a parede de desempenho? Aqui estão algumas dicas e truques de otimização de consulta SQL.
2. Identifique consultas problemáticas com o relatório padrão do SQL Server
Quando você está codificando, é fácil identificar uma longa série de código ou um procedimento armazenado. Você pode depurá-lo linha por linha. A linha que está atrasada é a única a ser corrigida.
Mas e se o seu helpdesk lançar uma dúzia de tíquetes porque é lento? Os usuários não podem identificar a localização exata no código, nem o helpdesk. O tempo é seu pior inimigo.
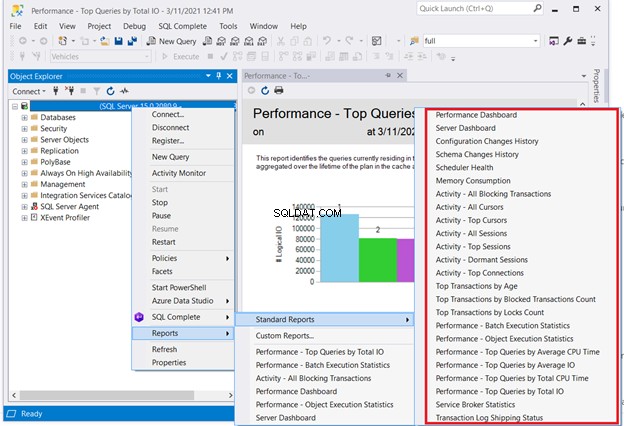
Uma solução que não exigirá codificação é verificar os relatórios padrão do SQL Server. Clique com o botão direito do mouse no servidor necessário no SQL Server Management Studio> Relatórios> Relatórios padrão . Nosso ponto de interesse pode ser o Painel de Desempenho ou Desempenho – Principais consultas por E/S total . Escolha a primeira consulta com desempenho ruim. Em seguida, inicie a otimização de consulta SQL ou o ajuste de desempenho SQL a partir daí.
3. Ajuste de consulta SQL com STATISTICS IO
Depois de identificar a consulta em questão, você pode começar a verificar as leituras lógicas em STATISTICS IO. Esta é uma das ferramentas de otimização de consulta SQL.
Existem alguns pontos de E/S, mas você deve se concentrar em leituras lógicas. Quanto mais altas forem as leituras lógicas, mais problemático será o desempenho da consulta.
Ao reduzir os três fatores a seguir, você pode acelerar as consultas de ajuste de desempenho no SQL:
- leituras lógicas altas,
- leituras lógicas de alto LOB,
- ou leituras lógicas de WorkTable/WorkFile altas.
Para obter as informações sobre leituras lógicas, ative STATISTICS IO na janela de consulta do SQL Server Management Studio.
DEFINIR ESTATÍSTICAS IO ON
Você pode obter a saída na guia Mensagens após a conclusão da consulta. A Figura 2 exibe a saída de amostra:
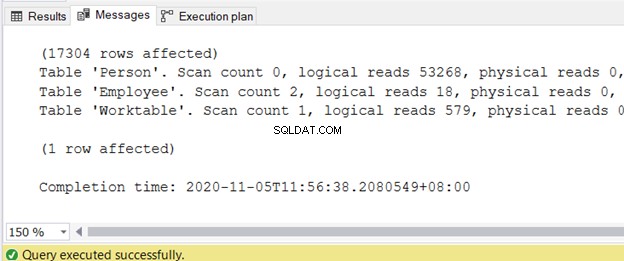
Escrevi um artigo separado sobre a redução de leituras lógicas em 3 estatísticas de E/S desagradáveis que retardam o desempenho da consulta SQL. Consulte-o para obter as etapas exatas e amostras de código com leituras lógicas altas e maneiras de reduzi-las.
4. Ajuste de consulta SQL com planos de execução
As leituras lógicas por si só não fornecerão a imagem completa. A série de etapas escolhidas pelo otimizador de consulta contará a história do seu conjunto de resultados. Como tudo começa depois que você executa a consulta?
A Figura 3 abaixo é um diagrama do que acontece após você acionar a execução até o momento em que obtém o conjunto de resultados.
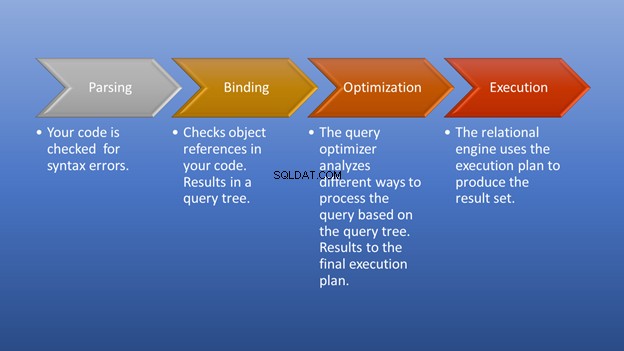
A análise e a vinculação acontecerão em um piscar de olhos. A parte incrível é a fase de otimização, que é o nosso foco. Nesse estágio, o otimizador de consultas desempenha um papel fundamental na seleção do melhor plano de execução possível. Embora essa parte precise de alguns recursos, ela economiza muito tempo ao escolher um plano de execução eficiente. Isso acontece dinamicamente, à medida que o banco de dados muda ao longo do tempo. Dessa forma, o programador pode se concentrar em como formar o resultado final.
Cada plano que o otimizador de consulta considera tem seu custo de consulta. Entre muitas opções, o otimizador escolherá o plano com o custo mais razoável. Observação :O custo razoável não é igual ao menor custo. Ele também precisa considerar qual plano produzirá os resultados mais rápidos. O plano com o menor custo nem sempre é o mais rápido. Por exemplo, o otimizador pode optar por utilizar vários núcleos de processador. Chamamos isso de execução paralela. Isso consumirá mais recursos, mas será executado mais rapidamente em comparação com a execução serial.
Outro ponto a considerar são as estatísticas. O otimizador de consulta depende dele para criar planos de execução. Se as estatísticas estiverem desatualizadas, não espere a melhor decisão do otimizador de consultas.
Quando o plano for decidido e a execução prosseguir, você verá os resultados. E agora?
Inspecione o plano de execução da consulta no SQL Server
Ao formar uma consulta, você deseja ver os resultados primeiro. Os resultados têm que estar corretos. Quando for, você terminou.
É assim mesmo?
Se você estiver com pouco tempo e o trabalho estiver em jogo, você pode concordar com isso. Além disso, você sempre pode voltar. No entanto, se surgirem outros problemas, você pode esquecê-los novamente. E então, o fantasma do passado irá caçar você.
Agora, qual é a melhor coisa a fazer depois de obter os resultados corretos?
Inspecione o Plano de Execução Real ou as Estatísticas de consulta ao vivo !
O último é bom se sua consulta estiver lenta e você quiser ver o que acontece a cada segundo à medida que as linhas são processadas.
Às vezes, a situação o forçará a inspecionar o plano imediatamente. Para começar, pressione Control-M ou clique em Incluir Plano de Execução Real na barra de ferramentas do SQL Server Management Studio. Se você preferir dbForge Studio para SQL Server, vá para Query Profiler - fornece as mesmas informações + alguns sinos e assobios que você não encontra no SSMS.
Vimos o Plano de Execução Real . Vamos prosseguir.
Há um índice ausente ou recomendações de índice?
Um índice ausente é fácil de detectar – você recebe o aviso imediatamente.
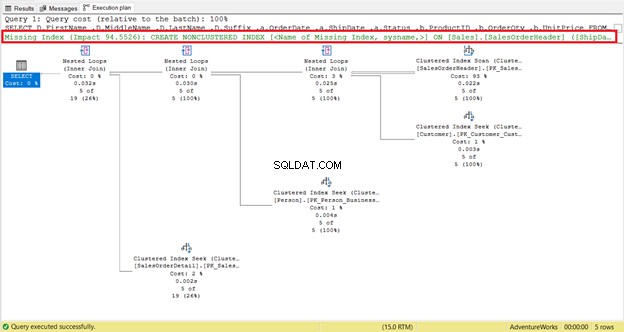
Para obter um código instantâneo para criar o índice, clique com o botão direito do mouse no Índice ausente mensagem (caixa em vermelho). Em seguida, selecione Detalhes do índice ausentes . Uma nova janela de consulta com o código para criar o índice ausente aparecerá. Crie o índice.
Esta parte é fácil de seguir. É um bom ponto de partida para alcançar uma execução mais rápida. Mas em alguns casos, não haverá efeito. Por quê? Algumas colunas necessárias para sua consulta não estão no índice. Portanto, ele será revertido para uma Verificação de Índice Clusterizado.
Você precisa inspecionar novamente o plano de execução após criar o índice para ver se as colunas incluídas são necessárias. Em seguida, ajuste o índice de acordo e execute novamente sua consulta. Depois disso, verifique novamente o plano de execução.
Mas e se não houver índice ausente?
Leia o Plano de Execução
Você precisa saber algumas coisas básicas para começar:
- Operadores
- Propriedades
- Direção de leitura
- Avisos
OPERADORES
O otimizador de consulta usa algum tipo de miniprograma chamado operadores. Você viu alguns deles na Figura 4 – Busca de índice agrupado , Verificação de índice clusterizado , Loops aninhados e Selecionar .
Para obter uma lista abrangente com nomes, ícones e descrições, você pode verificar esta referência da Microsoft.
PROPRIEDADES
Diagramas gráficos não são suficientes para entender o que está acontecendo nos bastidores. Você precisa se aprofundar nas propriedades de cada operador. Por exemplo, a Verificação de índice clusterizado na Figura 4 tem as seguintes Propriedades:
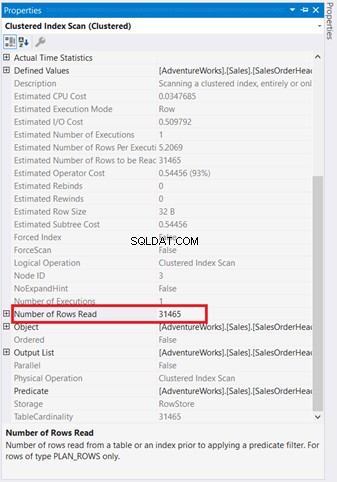
Se você examinar cuidadosamente, a Verificação de índice agrupado operador é terrível. Como mostra a Figura 5, ele leu 31.465 linhas, mas o conjunto de resultados final é de apenas 5 linhas. É por isso que há uma recomendação de índice na Figura 4 para reduzir o número de linhas lidas. As leituras lógicas da consulta também são altas e isso explica o porquê.
Para saber mais dessas propriedades, confira a lista de propriedades comuns do operador e propriedades do plano.
DIREÇÃO DE LEITURA
Geralmente, é como ler mangá japonês – da direita para a esquerda. Siga as setas que estão apontando para a esquerda. Aqui está um exemplo simples do dbForge Studio para SQL Server.
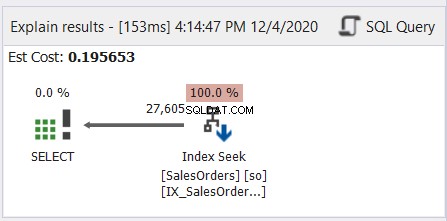
Como a Figura 6 demonstra, a seta aponta para a esquerda do operador Index Seek para o operador SELECT.
No entanto, a leitura da direita para a esquerda nem sempre é correta. Veja a Figura 7 com um exemplo do SSMS:
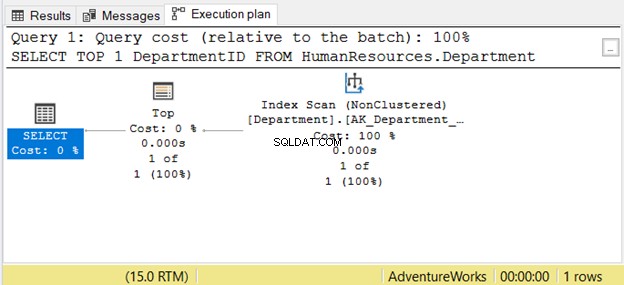
Se você ler da direita para a esquerda, verá que o Index Scan a saída do operador é 1 de 1 linha. Como ele poderia saber apenas 1 linha para buscar? É por causa do Top operador. Isso nos confundirá se lermos da direita para a esquerda.
Para entender melhor este caso, leia-o como “o operador SELECT usa Top para buscar 1 linha usando Index Scan”. Isso é da esquerda para a direita.
O que devemos usar? Direita para esquerda ou esquerda para direita?
É uma espécie de ambos - o que ajuda você a entender o plano.
Enquanto a seta nos dá a direção do fluxo de dados, sua espessura nos dá algumas dicas sobre o tamanho dos dados. Vamos nos referir à Figura 4 novamente.
A Verificação de Índice Agrupado indo para o Loop Aninhado tem uma seta mais grossa em comparação com os outros. As Propriedades detalhes da Verificação de índice na Figura 5 nos diga por que é grosso (31.465 linhas lidas para um resultado final de 5 linhas).
AVISO
Um ícone de aviso que aparece no operador do plano de execução nos informa que algo ruim aconteceu nesse operador. Isso pode dificultar a otimização da consulta SQL ao consumir mais recursos.
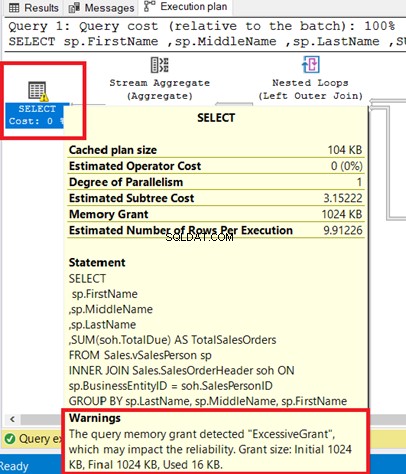
Você pode ver o aviso no operador SELECT. Passar o mouse para esse operador revela a mensagem de aviso. Um Concedo Excessivo causou este aviso.
Subsídio Excessivo acontece quando menos memória é usada do que foi reservada para a consulta. Para obter mais informações, consulte esta documentação da Microsoft.
A Figura 8 mostra a consulta usada como INNER JOIN de uma visualização para uma tabela. Você pode remover o aviso unindo as tabelas base em vez da exibição.
Agora que você tem uma ideia básica de leitura de planos de execução, como definir o que torna sua consulta lenta?
Conheça os 5 bandidos comuns do operador do plano
O atraso na execução da sua consulta é como um crime. Você precisa perseguir e prender esses bandidos.
1. Verificação de índice clusterizado ou não clusterizado
O primeiro ladino que todo mundo conhece é Clustered ou Verificação de índice não agrupado . Seu conhecimento comum na otimização de consultas SQL que as varreduras são ruins e as buscas são boas. Vimos um na Figura 4. Por causa do índice ausente, a Verificação de índice clusterizado lê 31.465 para obter 5 linhas.
No entanto, nem sempre é o caso. Considere 2 consultas na mesma tabela na Figura 9. Uma terá uma busca e outra terá uma varredura.
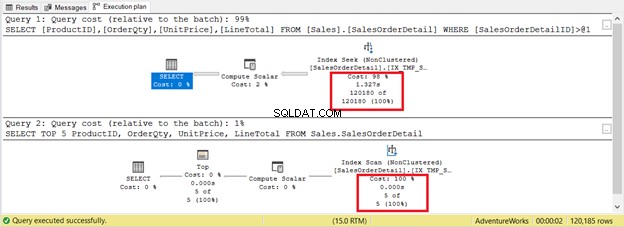
Se você basear os critérios apenas no número de registros, a varredura de índice vencerá com apenas 5 registros contra 120.180. A busca de índice levará mais tempo para ser executada.
Aqui está outro exemplo em que digitalizar ou procurar quase não importa. Eles retornam os mesmos 6 registros da mesma tabela. As leituras lógicas são as mesmas e o tempo decorrido é zero em ambos os casos. A tabela é muito pequena com apenas 6 registros. Incluir o Plano de Execução Real e execute as instruções abaixo.
-- Run this with Include Actual Execution Plan
USE AdventureWorks
GO
SET STATISTICS IO ON
GO
SELECT AddressTypeID, Name
FROM Person.AddressType
WHERE AddressTypeID >= 1
ORDER BY AddressTypeID DESC
Em seguida, salve o plano de execução para comparação posterior. Clique com o botão direito do mouse no plano de execução> Salvar plano de execução como .
Agora, execute a consulta abaixo.
SELECT AddressTypeID, Name
FROM Person.AddressType
ORDER BY AddressTypeID DESC
SET STATISTICS IO OFF
GO
Em seguida, clique com o botão direito do mouse no Plano de execução e selecione Comparar plano de exibição . Em seguida, selecione o arquivo que você salvou anteriormente. Você deve ter a mesma saída da Figura 10 abaixo.
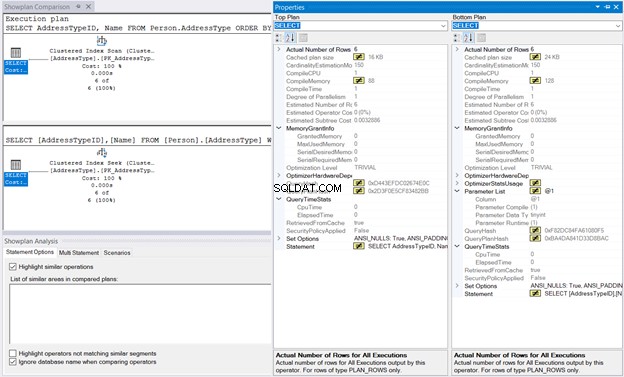
O MemoryGrant e QueryTimeStats são os mesmos. A CompileMemory de 128 KB usado na Pesquisa de índice agrupado em comparação com 88 KB da Verificação de índice clusterizado é quase desprezível. Sem esses números para comparar, a execução será a mesma.
2. Evitando verificações de tabela
Isso acontece quando você não tem um índice. Em vez de buscar valores usando um índice, o SQL Server verificará as linhas uma a uma até obter o que você precisa em sua consulta. Isso ficará muito atrasado em mesas grandes. A solução simples é adicionar o índice apropriado.
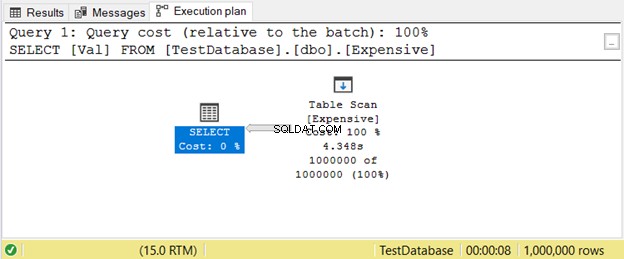
Aqui está um exemplo de um plano de execução com Table Scan operador na Figura 11.
3. Gerenciando o desempenho da classificação
Como vem do nome, altera a ordem das linhas. Esta pode ser uma operação cara.
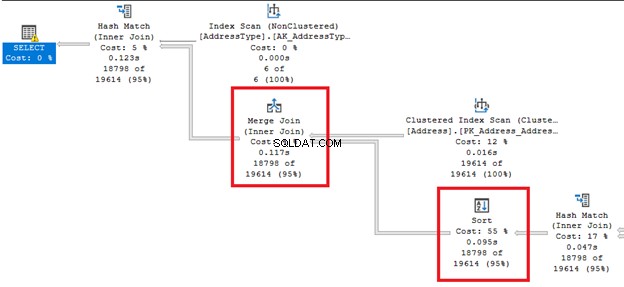
Olhe para aquelas linhas de seta gordas à direita e à esquerda de Classificar operador. Como o otimizador de consultas decidiu fazer uma junção de mesclagem , uma classificação É necessário. Observe também que possui o maior custo percentual de todas as operadoras (55%).
A classificação pode ser mais problemática se o SQL Server precisar ordenar as linhas várias vezes. Você pode evitar esse operador se sua tabela for pré-classificada com base no requisito de consulta. Ou você pode dividir uma única consulta em várias.
4. Elimine pesquisas de chave
Na Figura 4 anterior, o SQL Server recomendou adicionar outro índice. Eu fiz isso, mas não me deu exatamente o que eu queria. Em vez disso, ele me deu uma Pesquisa de índice para o novo índice emparelhado com uma Pesquisa de chave operador.
Assim, o novo índice adicionou uma etapa extra.
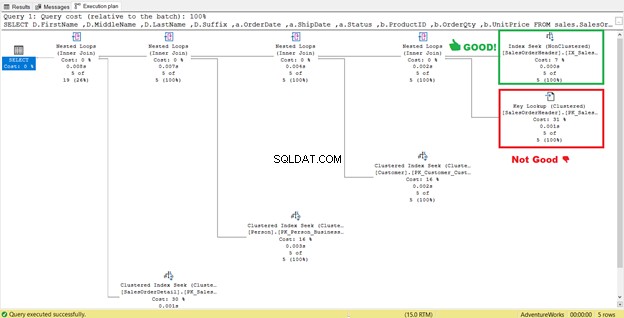
O que essa Pesquisa de chave operador faz?
O processador de consulta usou um novo índice não clusterizado em verde na Figura 13. Como nossa consulta requer colunas que não estão no novo índice, ela precisa obter esses dados com a ajuda de uma Pesquisa de chave do índice clusterizado. Como nós sabemos disso? Passando o mouse para a Pesquisa de chave revela algumas de suas propriedades e prova nosso ponto.
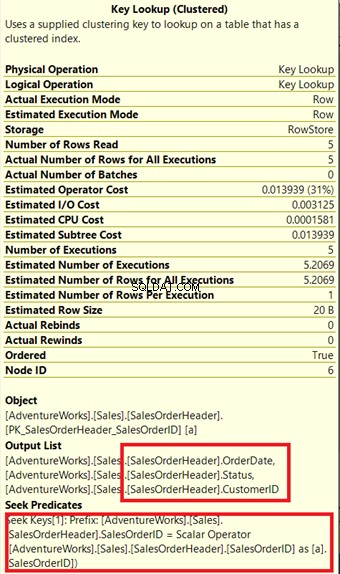
Na Figura 14, observe a Lista de Saídas. Precisamos recuperar 3 colunas usando o PK_SalesOrderHeader_SalesOrderID índice agrupado. Para remover isso, você precisa incluir essas colunas no novo índice. Aqui está o novo plano assim que essas colunas forem incluídas.
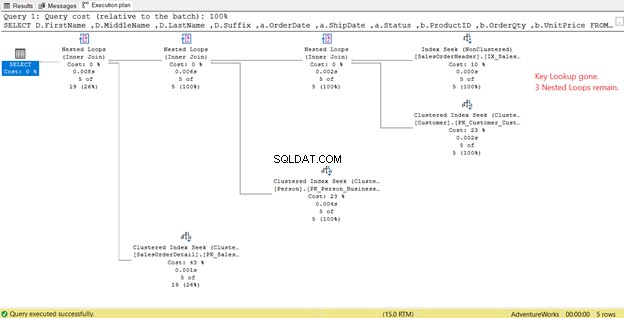
Na Figura 14, vimos 4 Loops aninhados . O quarto é necessário para a Pesquisa de chave adicionada . Mas depois de adicionar 3 colunas como colunas incluídas no novo índice, apenas 3 Loops aninhados permanecem e a Pesquisa de chave é removido. Não precisamos de etapas extras.
5. Paralelismo no Plano de Execução do SQL Server
Até agora, você viu planos de execução em execução em série. Mas aqui está o plano que aproveita a execução paralela. Isso significa que mais de 1 processador é utilizado pelo otimizador de consulta para executar a consulta. Quando usamos a execução paralela, vemos Paralelismo operadoras no plano, e outras mudanças também.
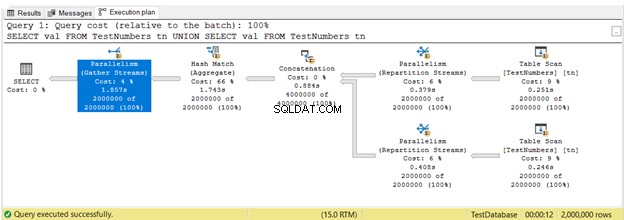
Na Figura 16, 3 Paralelismo operadores foram usados. Observe também que a Verificação de tabela ícone do operador é um pouco diferente. Isso acontece quando a execução paralela é usada.
O paralelismo não é inerentemente ruim. Ele aumenta a velocidade das consultas utilizando mais núcleos de processador. No entanto, ele usa mais recursos da CPU. Quando muitas de suas consultas usam paralelismos, isso diminui a velocidade do servidor. Você pode querer verificar o limite de custo para a configuração de paralelismo em seu SQL Server.
5. Práticas recomendadas para otimização de consulta SQL
Até agora, lidamos com a otimização de consultas SQL com métodos que descobrem problemas difíceis de detectar. Mas existem maneiras de identificá-lo no código. Aqui estão alguns cheiros de código em SQL.
Usando SELECIONAR *
Com pressa? Então digitar * pode ser mais fácil do que especificar nomes de colunas. No entanto, há uma pegadinha. Colunas que você não precisa irão atrasar sua consulta.
Há prova. A consulta de exemplo que usei para a Figura 15 é esta:
USE AdventureWorks
GO
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Já otimizamos. Mas vamos mudar para SELECT *
USE AdventureWorks
GO
SELECT *
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
É mais curto, mas confira o Plano de Execução abaixo:
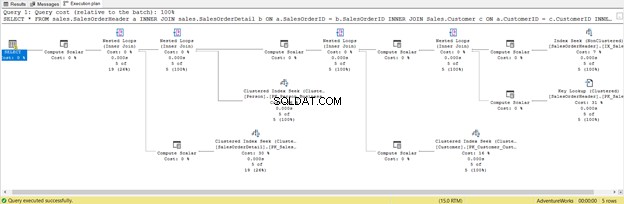
Esta é a consequência de incluir todas as colunas, mesmo aquelas que você não precisa. Ele retornou Pesquisa de chave e muito Compute Scalar . Em suma, essa consulta tem uma carga pesada e, como resultado, ficará atrasada. Observe também o aviso no operador SELECT. Não estava lá antes. Que desperdício!
Funções em uma cláusula WHERE ou JOIN
Outro cheiro de código é ter uma função na cláusula WHERE. Considere as 2 instruções SELECT a seguir com o mesmo conjunto de resultados. A diferença está na cláusula WHERE.
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE YEAR(a.ShipDate) = 2011
AND MONTH(a.ShipDate) = 7
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate BETWEEN '07/1/2011' AND '07/31/2011'
O primeiro SELECT usa as funções de data YEAR e MONTH para indicar datas de envio em julho de 2011. A segunda instrução SELECT usa o operador BETWEEN com literais de data.
A primeira instrução SELECT terá um plano de execução semelhante ao da Figura 4, mas sem a recomendação de índice. O segundo terá um plano de execução melhor semelhante ao da Figura 15.
O otimizado melhor é óbvio.
Uso de curingas
Quão curingas podem afetar nossa otimização de consulta SQL? Vamos ter um exemplo.
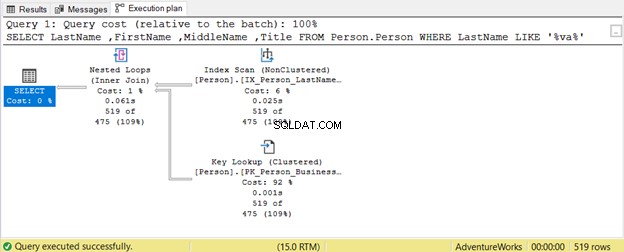
A consulta tenta procurar a presença de uma string dentro de Sobrenome em qualquer posição. Portanto, Sobrenome LIKE '%va%' . Isso é ineficiente em tabelas grandes porque as linhas serão inspecionadas uma a uma quanto à presença dessa string. É por isso que uma Verificação de índice é usado. Como nenhum índice inclui o Título coluna, uma Pesquisa de chave também é usado.
Isso pode ser corrigido pelo design.
O aplicativo de chamada exige isso? Ou será suficiente usar LIKE ‘va%’?
LIKE 'va%' usa uma busca de índice porque a tabela tem um índice em sobrenome , nome e nome do meio .
Você também pode adicionar mais filtros na cláusula WHERE para reduzir a leitura dos registros?
Suas respostas a essas perguntas ajudarão você a corrigir essa consulta.
Conversão implícita
O SQL Server faz a conversão implícita nos bastidores para reconciliar os tipos de dados ao comparar valores. Por exemplo, é conveniente atribuir um número a uma coluna de string sem aspas. Mas há uma pegadinha. O efeito é semelhante quando você usa uma função em uma cláusula WHERE.
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
WHERE NationalIDNumber = 56920285
O NationalIDNumner é NVARCHAR(15), mas é igualado a um número. Ele será executado com êxito devido à conversão implícita. Mas observe o plano de execução na Figura 19 abaixo.
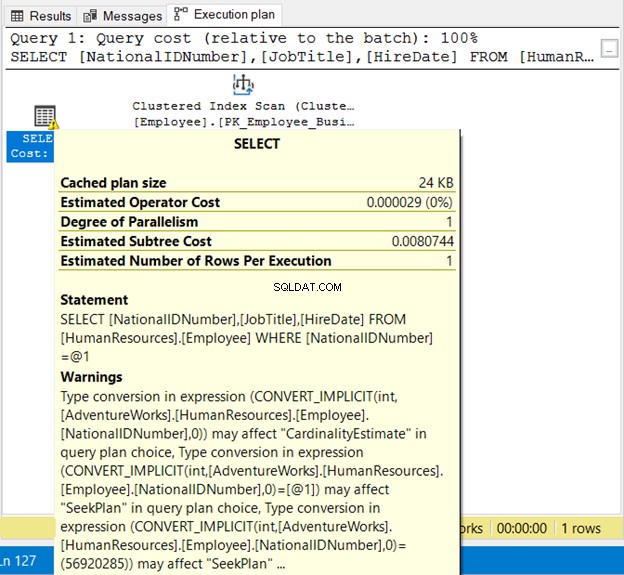
Vemos 2 coisas ruins aqui. Primeiro, o aviso. Em seguida, a Verificação de índice . A verificação do índice ocorreu devido à conversão implícita. Portanto, certifique-se de colocar as strings entre aspas ou testar valores literais com o mesmo tipo de dados da coluna.
Conclusões sobre otimização de consulta SQL
É isso. O básico da otimização de consultas SQL fez você se sentir um pouco pronto para suas consultas? Vamos fazer uma recapitulação.
- Se você deseja que suas consultas sejam otimizadas, comece com um bom design de banco de dados.
- Se o banco de dados já estiver em produção, identifique as consultas problemáticas usando os relatórios padrão do SQL Server.
- Saiba qual é o impacto da consulta lenta com leituras lógicas do STATISTICS IO.
- Aprofunde-se na história de sua consulta lenta com os planos de execução.
- Assista a 4 cheiros de código que tornam suas consultas mais lentas.
Existem outras dicas de otimização de consulta SQL para fazer uma consulta lenta ser executada rapidamente. Como eu disse no início, este é um grande tema. Então, deixe-nos saber na seção de comentários o que mais perdemos.
E se você gostou deste post, compartilhe-o em suas plataformas de mídia social favoritas.
Mais otimização de consulta SQL de artigos anteriores
Se você precisar de mais exemplos, aqui estão alguns posts úteis relacionados às técnicas de otimização de consulta no SQL Server.
- As subconsultas são ruins para o desempenho? Confira O Guia Fácil sobre Como Usar Subconsultas no SQL Server .
- Usar HierarchyID versus design pai/filho – o que é mais rápido? Visite Como usar o ID de hierarquia do SQL Server por meio de exemplos fáceis .
- As consultas de banco de dados de gráficos podem superar seus equivalentes relacionais em um sistema de recomendação em tempo real? Confira Como usar os recursos do banco de dados SQL Server Graph .
- O que é mais rápido:COALESCE ou ISNULL? Descubra em Principais respostas para 5 perguntas importantes sobre a função SQL COALESCE .
- SELECT FROM View vs. SELECT FROM Base Tables – Qual deles será executado mais rápido? Visite As 3 principais dicas que você precisa saber para escrever visualizações SQL mais rápidas .
- CTE x Tabelas temporárias x Subconsultas. Saiba qual deles vencerá em Tudo o que você precisa saber sobre SQL CTE em um ponto .
- Usando SQL SUBSTRING em uma cláusula WHERE – uma armadilha de desempenho? Veja se é verdade com exemplos em Como analisar strings como um profissional usando a função SQL SUBSTRING()?
- SQL UNION ALL é mais rápido que UNION. Saiba por que em SQL UNION Cheat Sheet com 10 dicas fáceis e úteis .