Um ponto único de falha (SPOF) é um motivo comum pelo qual as organizações estão trabalhando para distribuir a presença de seus ambientes de banco de dados para outro local geograficamente. Faz parte dos planos estratégicos de Disaster Recovery e Business Continuity.
O planejamento de recuperação de desastres (DR) incorpora procedimentos técnicos que abrangem a preparação para questões imprevistas, como desastres naturais, acidentes (como erro humano) ou incidentes (como atos criminosos).
Na última década, distribuir seu ambiente de banco de dados em várias localizações geográficas tem sido uma configuração bastante comum, pois as nuvens públicas oferecem muitas maneiras de lidar com isso. O desafio vem na configuração de ambientes de banco de dados. Ele cria desafios quando você tenta gerenciar o(s) banco(s) de dados, mover seus dados para outra localização geográfica ou aplicar segurança com um alto nível de observabilidade.
Neste blog, mostraremos como você pode fazer isso usando o MySQL Replication. Abordaremos como você pode copiar seus dados para outro nó de banco de dados localizado em um país diferente, distante da geografia atual do cluster MySQL. Para este exemplo, nossa região de destino é baseada no leste americano, enquanto meu local está na Ásia, localizado nas Filipinas.
Por que preciso de um cluster de banco de dados de geolocalização?
Até mesmo a Amazon AWS, o principal provedor de nuvem pública, alega que sofre com o tempo de inatividade ou interrupções não intencionais (como a que aconteceu em 2017). Digamos que você esteja usando a AWS como seu datacenter secundário, além de seu local. Você não pode ter nenhum acesso interno ao hardware subjacente ou às redes internas que estão gerenciando seus nós de computação. Estes são serviços totalmente gerenciados pelos quais você pagou, mas você não pode evitar o fato de que ele pode sofrer uma interrupção a qualquer momento. Se essa localização geográfica sofrer uma interrupção, você poderá ter um longo tempo de inatividade.
Esse tipo de problema deve ser previsto durante o planejamento de continuidade de negócios. Deve ter sido analisado e implementado com base no que foi definido. A continuidade de negócios para seus bancos de dados MySQL deve incluir alto tempo de atividade. Alguns ambientes estão fazendo benchmarks e estabelecem um alto nível de testes rigorosos, incluindo o lado fraco, a fim de expor qualquer vulnerabilidade, quão resiliente ela pode ser e quão escalável sua arquitetura de tecnologia, incluindo sua infraestrutura de banco de dados. Para os negócios, especialmente aqueles que lidam com transações altas, é imperativo garantir que os bancos de dados de produção estejam disponíveis para os aplicativos o tempo todo, mesmo quando ocorrer uma catástrofe. Caso contrário, o tempo de inatividade pode ser experimentado e pode custar uma grande quantia de dinheiro.
Com esses cenários identificados, as organizações começam a estender sua infraestrutura para diferentes provedores de nuvem e colocar nós em diferentes geolocalizações para ter um tempo de atividade mais alto (se possível em 99,99999999999), menor RPO e sem SPOF.
Para garantir que os bancos de dados de produção sobrevivam a um desastre, um site de recuperação de desastres (DR) deve ser configurado. Os sites de produção e DR devem fazer parte de dois datacenters geograficamente distantes. Isso significa que um banco de dados em espera deve ser configurado no site de DR para cada banco de dados de produção para que as alterações de dados que ocorrem no banco de dados de produção sejam imediatamente sincronizadas com o banco de dados em espera por meio de logs de transação. Algumas configurações também usam seus nós DR para lidar com leituras, de modo a fornecer balanceamento de carga entre o aplicativo e a camada de dados.
A configuração arquitetônica desejada
Neste blog, a configuração desejada é uma implementação simples, mas muito comum hoje em dia. Veja abaixo a configuração arquitetônica desejada para este blog:
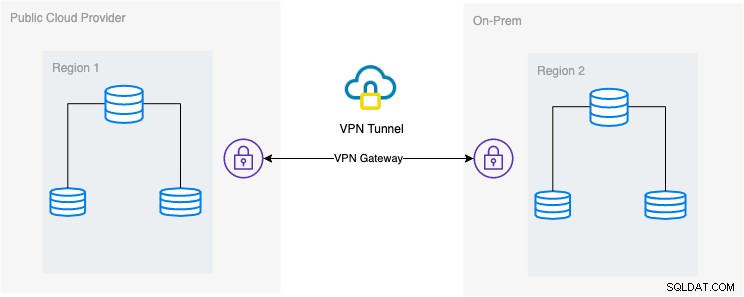
Neste blog, escolho o Google Cloud Platform (GCP) como público provedor de nuvem e usando minha rede local como meu ambiente de banco de dados local.
É obrigatório que, ao usar esse tipo de design, você sempre precise que o ambiente ou a plataforma se comuniquem de maneira muito segura. Usando VPN ou usando alternativas como AWS Direct Connect. Embora essas nuvens públicas hoje em dia ofereçam serviços de VPN gerenciados que você pode usar. Mas para esta configuração, usaremos o OpenVPN, pois não preciso de hardware ou serviço sofisticado para este blog.
Melhor e mais eficiente maneira
Para ambientes de banco de dados MySQL/Percona/MariaDB, a maneira melhor e eficiente é fazer uma cópia de backup do seu banco de dados, enviar para o nó de destino a ser implantado ou instanciado. Existem diferentes maneiras de usar essa abordagem, você pode usar mysqldump, mydumper, rsync ou usar Percona XtraBackup/Mariabackup e transmitir os dados para o nó de destino.
Usando mysqldump
mysqldump cria um backup lógico de todo o seu banco de dados ou você pode escolher seletivamente uma lista de bancos de dados, tabelas ou até mesmo registros específicos que deseja despejar.
Um comando simples que você pode usar para fazer um backup completo pode ser,
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | mysql -h <target-host-db-node -u<user> -p<password> -vvv --show-warningsCom este comando simples, ele executará diretamente as instruções MySQL para o nó do banco de dados de destino, por exemplo, seu nó de banco de dados de destino em um Google Compute Engine. Isso pode ser eficiente quando os dados são menores ou você tem uma largura de banda rápida. Caso contrário, empacotar seu banco de dados em um arquivo e enviá-lo para o nó de destino pode ser sua opção.
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | gzip > mydata.db
$ scp mydata.db <target-host>:/some/pathEm seguida, execute mysqldump para o nó do banco de dados de destino como tal,
zcat mydata.db | mysqlA desvantagem de usar backup lógico usando mysqldump é que é mais lento e consome espaço em disco. Ele também usa um único thread para que você não possa executá-lo em paralelo. Opcionalmente, você pode usar mydumper especialmente quando seus dados são muito grandes. mydumper pode ser executado em paralelo, mas não é tão flexível em comparação com mysqldump.
Usando xtrabackup
xtrabackup é um backup físico onde você pode enviar os fluxos ou binários para o nó de destino. Isso é muito eficiente e é usado principalmente ao transmitir um backup pela rede, especialmente quando o nó de destino é de geografia ou região diferente. O ClusterControl usa o xtrabackup ao provisionar ou instanciar um novo escravo, independentemente de onde ele esteja localizado, desde que o acesso e a permissão tenham sido configurados antes da ação.
Se você estiver usando o xtrabackup para executá-lo manualmente, você pode executar o comando como tal,
## Nó de destino
$ socat -u tcp-listen:9999,reuseaddr stdout 2>/tmp/netcat.log | xbstream -x -C /var/lib/mysql## Nó de origem
$ innobackupex --defaults-file=/etc/my.cnf --stream=xbstream --socket=/var/lib/mysql/mysql.sock --host=localhost --tmpdir=/tmp /tmp | socat -u stdio TCP:192.168.10.70:9999Para elaborar esses dois comandos, o primeiro comando deve ser executado ou executado primeiro no nó de destino. O comando do nó de destino atende na porta 9999 e gravará qualquer fluxo recebido da porta 9999 no nó de destino. Depende dos comandos socat e xbstream, o que significa que você deve garantir que esses pacotes estejam instalados.
No nó de origem, ele executa o script perl innobackupex que invoca o xtrabackup em segundo plano e usa o xbstream para transmitir os dados que serão enviados pela rede. O comando socat abre a porta 9999 e envia seus dados para o host desejado, que é 192.168.10.70 neste exemplo. Ainda assim, certifique-se de ter socat e xbstream instalados ao usar este comando. Uma maneira alternativa de usar o socat é o nc, mas o socat oferece recursos mais avançados em comparação com o nc, como serialização, pois vários clientes podem ouvir em uma porta.
ClusterControl usa este comando ao reconstruir um escravo ou construir um novo escravo. É rápido e garante que a cópia exata de seus dados de origem será copiada para o nó de destino. Ao provisionar um novo banco de dados em uma localização geográfica separada, o uso dessa abordagem oferece mais eficiência e oferece mais velocidade para concluir o trabalho. Embora possa haver prós e contras ao usar backup lógico ou binário quando transmitido pela rede. Usar esse método é uma abordagem muito comum ao configurar um novo cluster de banco de dados de geolocalização para uma região diferente e criar uma cópia exata do seu ambiente de banco de dados.
Eficiência, Observabilidade e Velocidade
As perguntas deixadas pela maioria das pessoas que não estão familiarizadas com essa abordagem sempre abrangem os problemas "COMO, O QUE, ONDE". Nesta seção, abordaremos como você pode configurar eficientemente seu banco de dados de geolocalização com menos trabalho para lidar e com observabilidade por que ele falha. Usar o ClusterControl é muito eficiente. Nesta configuração atual tenho, o seguinte ambiente como implementado inicialmente:
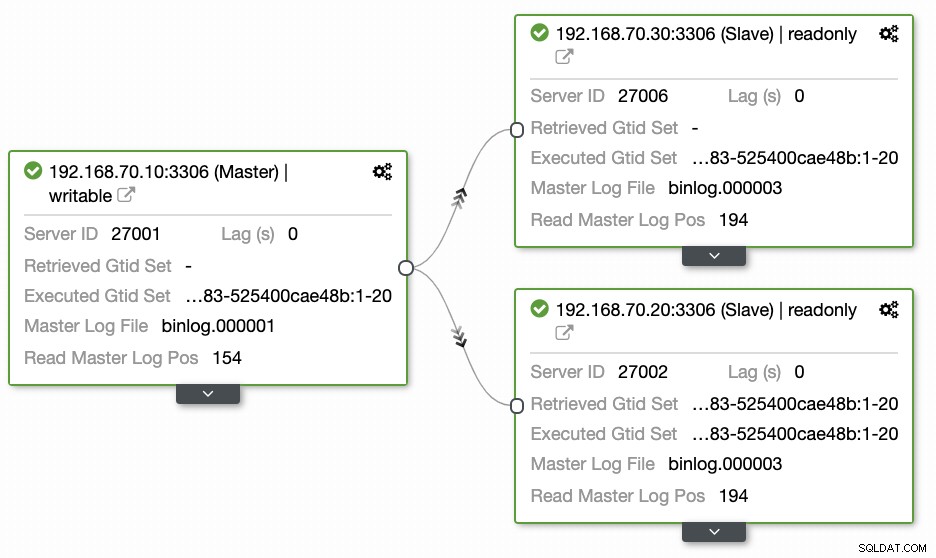
Estendendo o nó para o GCP
Começando a configurar seu cluster de banco de dados de geolocalização, para estender seu cluster e criar uma cópia de instantâneo de seu cluster, você pode adicionar um novo escravo. Conforme mencionado anteriormente, o ClusterControl usará o xtrabackup (mariabackup para MariaDB 10.2 em diante) e implantará um novo nó em seu cluster. Antes de registrar seus nós de computação do GCP como seus nós de destino, você precisa primeiro configurar o usuário do sistema apropriado igual ao usuário do sistema que você registrou no ClusterControl. Você pode verificar isso em seu /etc/cmon.d/cmon_X.cnf, onde X é o cluster_id. Por exemplo, veja abaixo:
# grep 'ssh_user' /etc/cmon.d/cmon_27.cnf
ssh_user=maximusmaximus (neste exemplo) deve estar presente em seus nós de computação do GCP. O usuário nos nós do GCP precisa ter privilégios de sudo ou superadministrador. Ele também deve ser configurado com um acesso SSH sem senha. Por favor, leia nossa documentação mais sobre o usuário do sistema e seus privilégios necessários.
Vamos ter um exemplo de lista de servidores abaixo (no console do GCP:painel do Compute Engine):
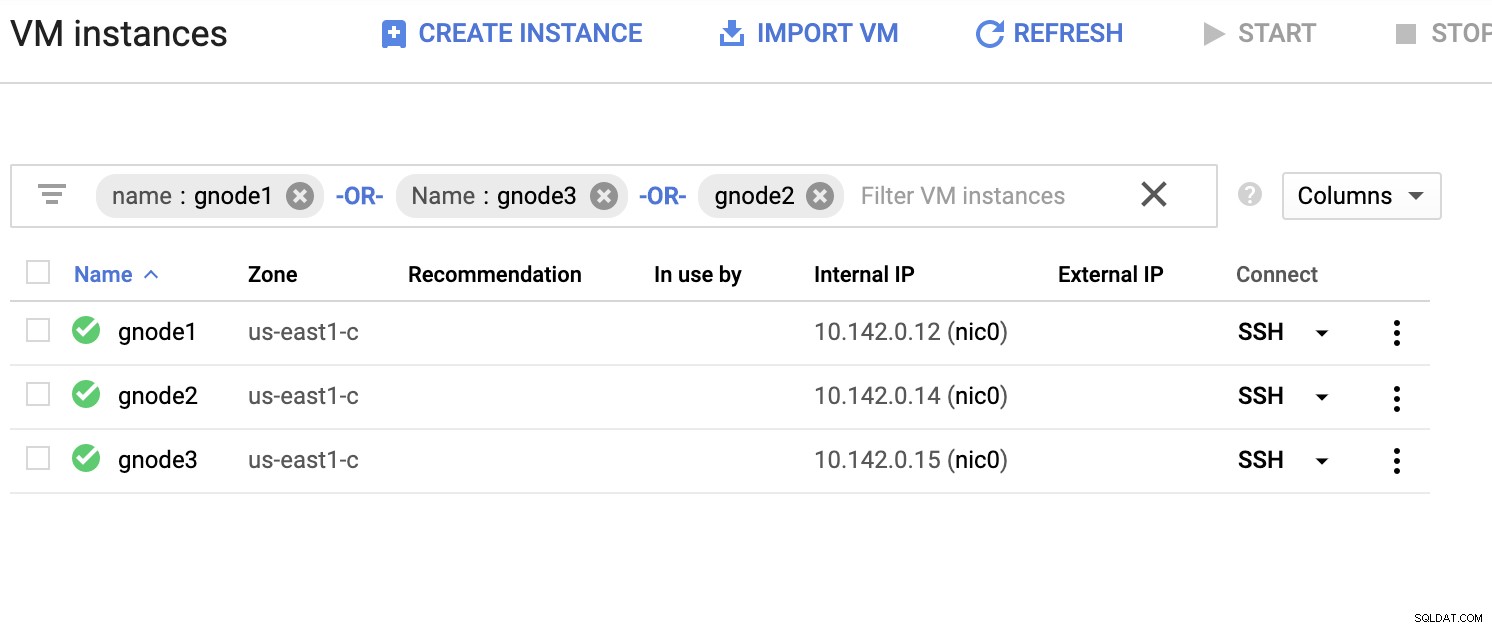
Na captura de tela acima, nossa região de destino é baseada em us-east região. Conforme observado anteriormente, minha rede local é configurada em uma camada segura passando pelo GCP (vice-versa) usando o OpenVPN. Portanto, a comunicação do GCP para minha rede local também é encapsulada no túnel VPN.
Adicionar um nó escravo ao GCP
A captura de tela abaixo revela como você pode fazer isso. Veja imagens abaixo:
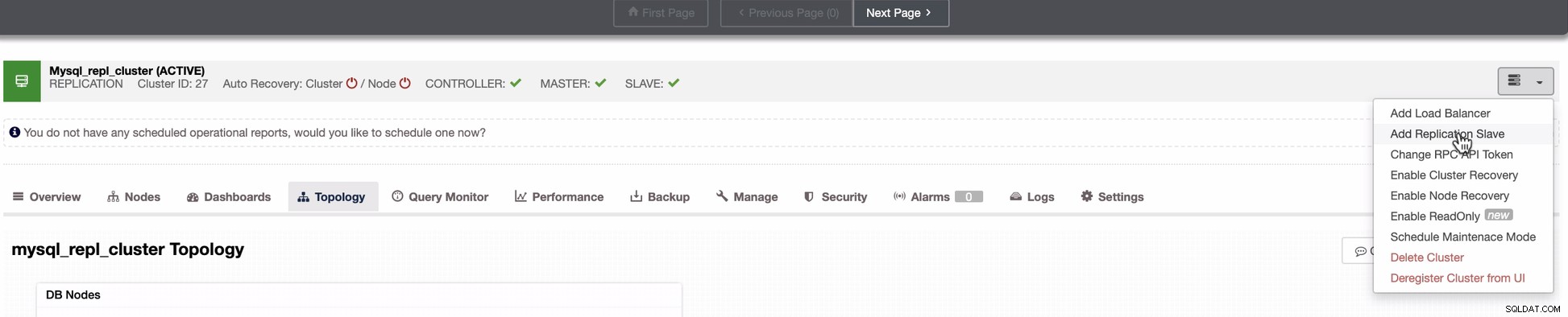
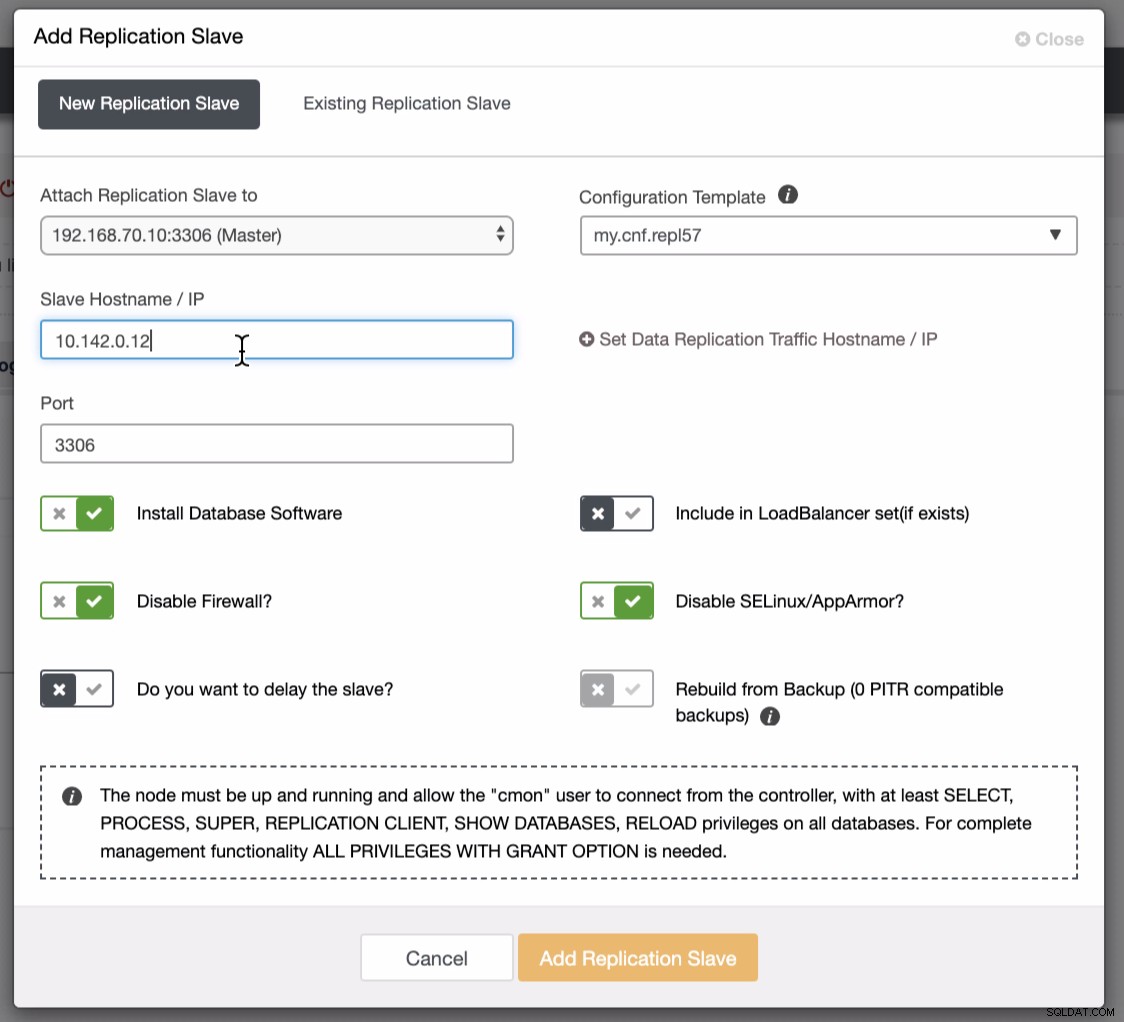
Como visto na segunda captura de tela, estamos segmentando o nó 10.142.0.12 e seu mestre de origem é 192.168.70.10. O ClusterControl é inteligente o suficiente para determinar firewalls, módulos de segurança, pacotes, configurações e configurações que precisam ser feitas. Veja abaixo um exemplo de registro de atividades de trabalho:
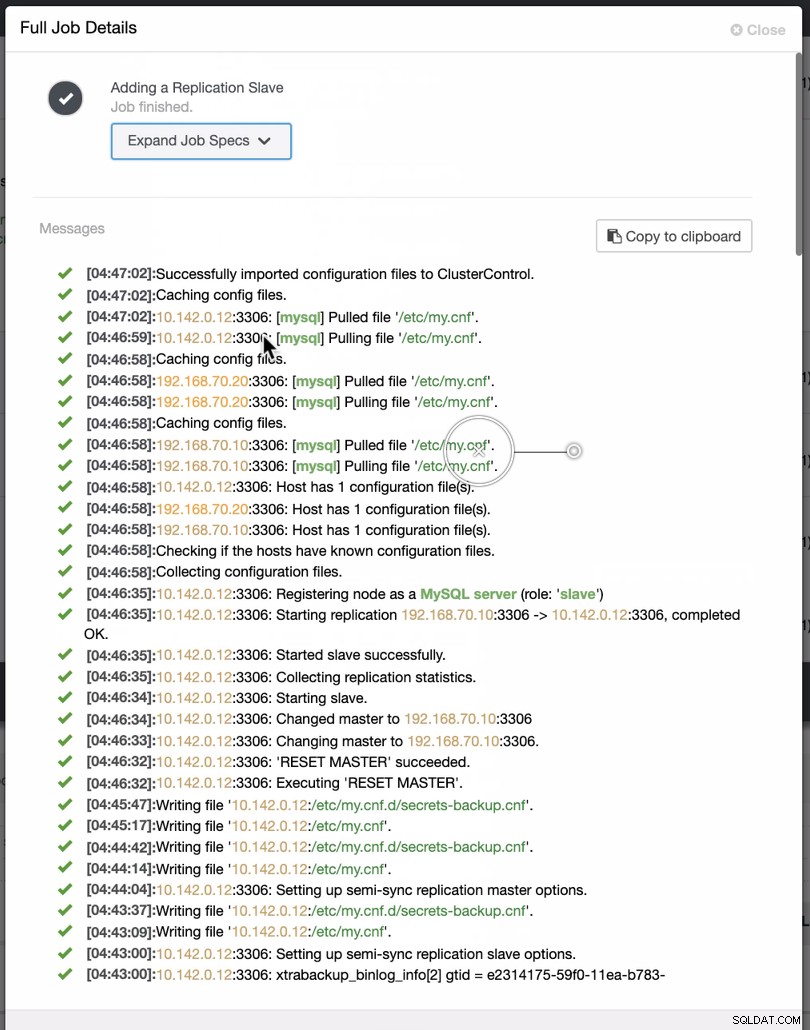
Uma tarefa bem simples, não é?
Concluir o cluster MySQL do GCP
Precisamos adicionar mais dois nós ao cluster do GCP para ter uma topologia de equilíbrio, como fizemos na rede local. Para o segundo e o terceiro nó, verifique se o mestre deve apontar para o nó do GCP. Neste exemplo, o mestre é 10.142.0.12. Veja abaixo como fazer isso,
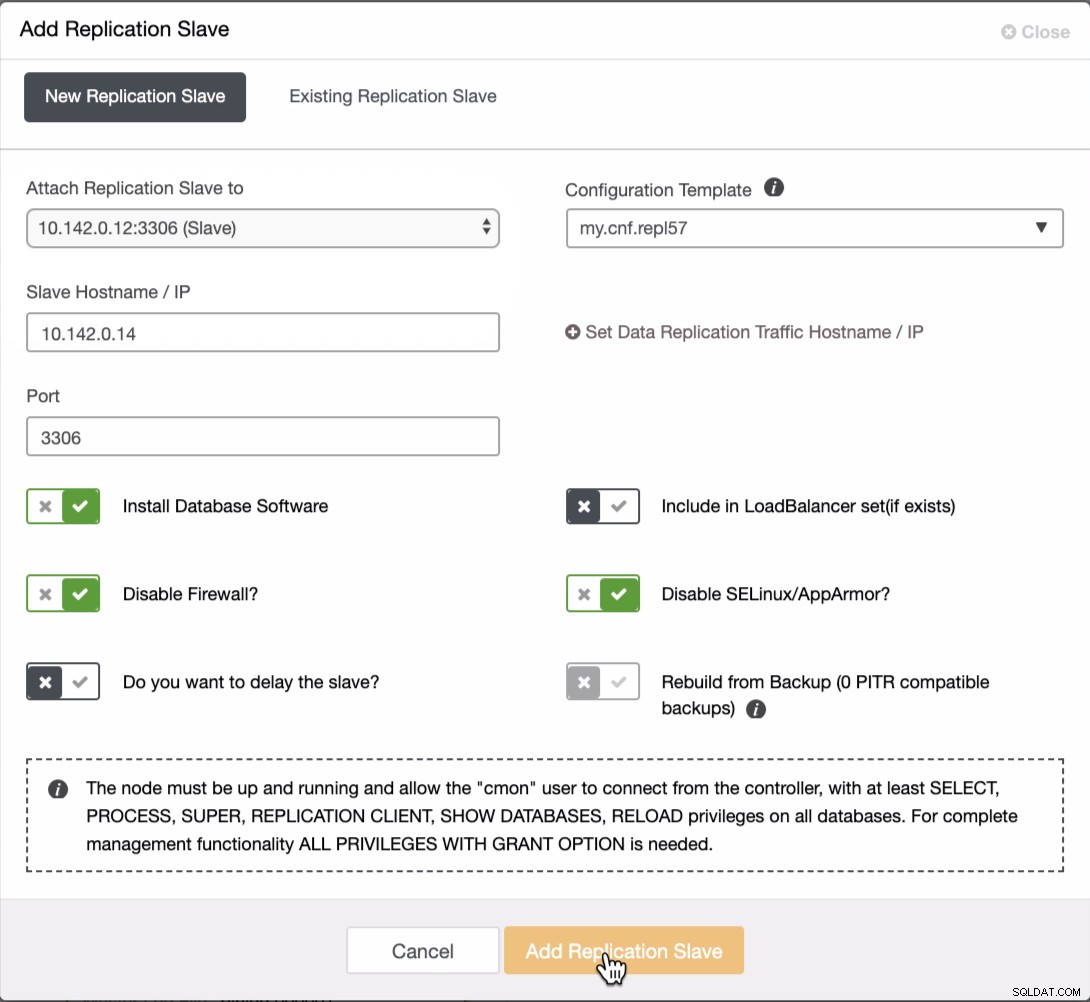
Como visto na captura de tela acima, selecionei o 10.142.0.12 (slave ) que é o primeiro nó que adicionamos ao cluster. O resultado completo é mostrado a seguir,
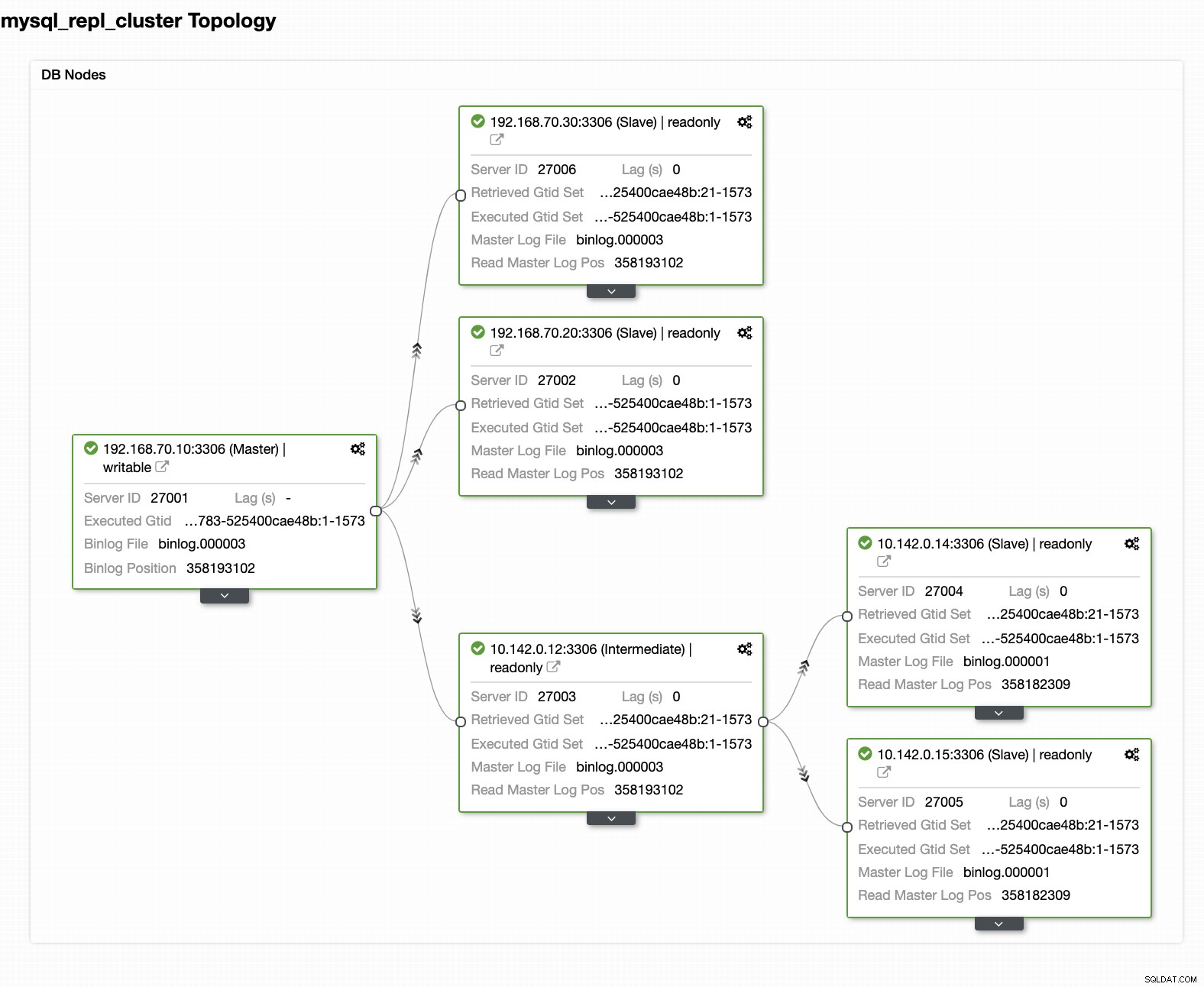
Sua configuração final do cluster de banco de dados de geolocalização
Na última captura de tela, esse tipo de topologia pode não ser sua configuração ideal. Principalmente, deve ser uma configuração de vários mestres, em que seu cluster de DR funciona como o cluster em espera, enquanto seu local funciona como o cluster ativo primário. Para fazer isso, é bem simples no ClusterControl. Veja as capturas de tela a seguir para atingir esse objetivo.
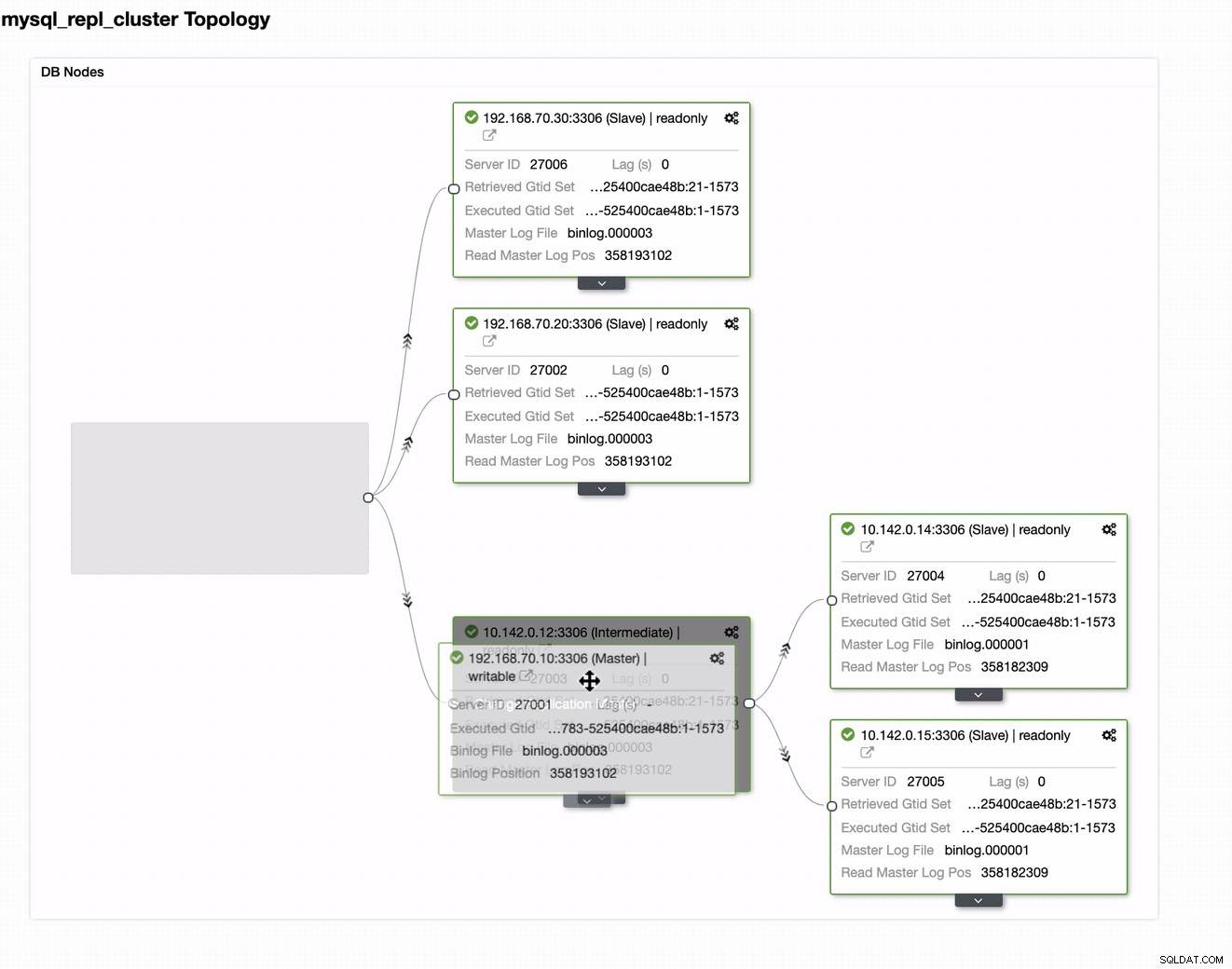
Você pode simplesmente arrastar seu mestre atual para o mestre de destino que deve ser configurado como um gravador de espera principal para o caso de seu local estar em perigo. Neste exemplo, arrastamos o host de segmentação 10.142.0.12 (nó de computação do GCP). O resultado final é mostrado abaixo:
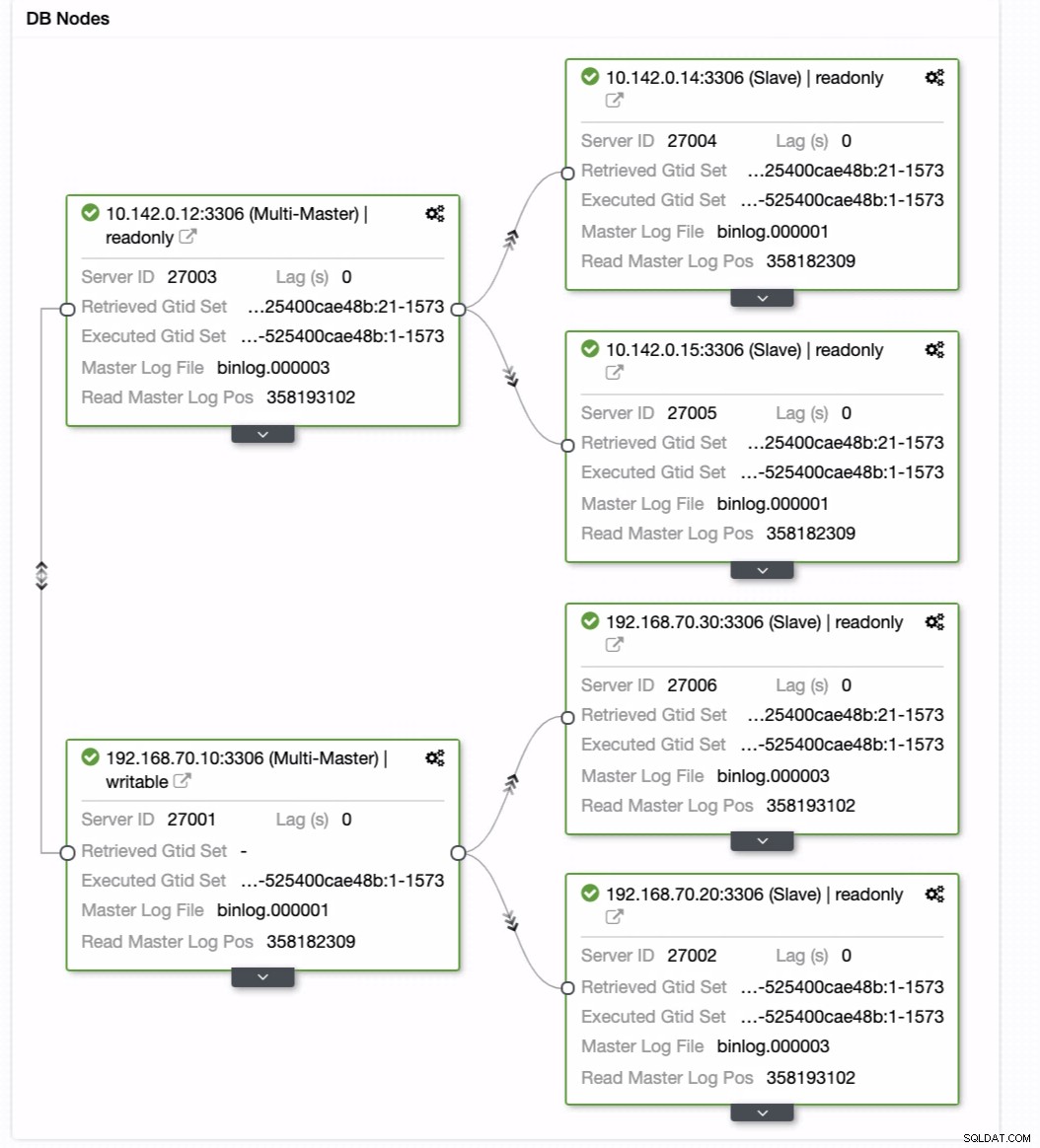
Então ele alcança o resultado desejado. Fácil e muito rápido de gerar seu cluster de banco de dados de localização geográfica usando a replicação MySQL.
Conclusão
Ter um cluster de banco de dados de localização geográfica não é novidade. Tem sido uma configuração desejada para empresas e organizações que evitam SPOF que desejam resiliência e um RPO menor.
As principais conclusões para essa configuração são segurança, redundância e resiliência. Ele também aborda o quão viável e eficiente você pode implantar seu novo cluster em uma região geográfica diferente. Embora o ClusterControl possa oferecer isso, esperamos que possamos ter mais melhorias nisso mais cedo, onde você pode criar com eficiência a partir de um backup e gerar seu novo cluster diferente no ClusterControl, portanto, fique atento.