O melhor cenário é que, em caso de falha do banco de dados, você tenha um bom Plano de Recuperação de Desastres (DRP) e um ambiente altamente disponível com um processo de failover automático, mas… o que acontece se ele falhar por algum motivo inesperado? E se você precisar executar um failover manual? Neste blog, compartilharemos algumas recomendações a serem seguidas caso você precise fazer failover de seu banco de dados.
Verificações de verificação
Antes de realizar qualquer alteração, você precisa verificar algumas coisas básicas para evitar novos problemas após o processo de failover.
Status da replicação
Pode ser possível que, no momento da falha, o nó escravo não esteja atualizado, devido a uma falha de rede, carga alta ou outro problema, então você precisa ter certeza de que seu slave tem todas (ou quase todas) as informações. Se você tiver mais de um nó escravo, também deve verificar qual é o nó mais avançado e escolhê-lo para failover.
ex:Vamos verificar o status da replicação em um servidor MariaDB.
MariaDB [(none)]> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.100.110
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000014
Read_Master_Log_Pos: 339
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 635
Relay_Master_Log_File: binlog.000014
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_Errno: 0
Skip_Counter: 0
Exec_Master_Log_Pos: 339
Relay_Log_Space: 938
Until_Condition: None
Until_Log_Pos: 0
Master_SSL_Allowed: No
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_SQL_Errno: 0
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3001
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3001-20
Parallel_Mode: conservative
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0
1 row in set (0.000 sec)No caso do PostgreSQL, é um pouco diferente, pois você precisa verificar o status dos WALs e comparar os aplicados com os buscados.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Credenciais
Antes de executar o failover, você deve verificar se seu aplicativo/usuários poderão acessar seu novo mestre com as credenciais atuais. Se você não estiver replicando os usuários do banco de dados, talvez as credenciais tenham sido alteradas, portanto, você precisará atualizá-las nos nós escravos antes de qualquer alteração.
por exemplo:Você pode consultar a tabela de usuários no banco de dados mysql para verificar as credenciais do usuário em um MariaDB/MySQL Server:
MariaDB [(none)]> SELECT Host,User,Password FROM mysql.user;
+-----------------+--------------+-------------------------------------------+
| Host | User | Password |
+-----------------+--------------+-------------------------------------------+
| localhost | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | mysql | invalid |
| 127.0.0.1 | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.100 | cmon | *F80B5EE41D1FB1FA67D83E96FCB1638ABCFB86E2 |
| 127.0.0.1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| ::1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.112 | user1 | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 127.0.0.1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| ::1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 192.168.100.110 | rpl_user | *EEA7B018B16E0201270B3CDC0AF8FC335048DC63 |
+-----------------+--------------+-------------------------------------------+
12 rows in set (0.001 sec)No caso do PostgreSQL, você pode usar o comando ‘\du’ para conhecer os papéis, e também deve verificar o arquivo de configuração pg_hba.conf para gerenciar o acesso do usuário (não as credenciais). Então:
postgres=# \du
List of roles
Role name | Attributes | Member of
------------------+------------------------------------------------------------+-----------
admindb | Superuser, Create role, Create DB | {}
cmon_replication | Replication | {}
cmonexporter | | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
s9smysqlchk | Superuser, Create role, Create DB | {}E pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD
host replication cmon_replication localhost md5
host replication cmon_replication 127.0.0.1/32 md5
host all s9smysqlchk localhost md5
host all s9smysqlchk 127.0.0.1/32 md5
local all all trust
host all all 127.0.0.1/32 trustAcesso à rede/firewall
As credenciais não são o único problema possível ao acessar seu novo mestre. Caso o nó esteja em outro datacenter, ou você tenha um firewall local para filtrar o tráfego, você deve verificar se tem permissão para acessá-lo ou mesmo se tem a rota de rede para chegar ao novo nó mestre.
por exemplo:iptables. Vamos permitir o tráfego da rede 167.124.57.0/24 e verificar as regras atuais após adicioná-lo:
$ iptables -A INPUT -s 167.124.57.0/24 -m state --state NEW -j ACCEPT
$ iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- 167.124.57.0/24 0.0.0.0/0 state NEW
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destinationpor exemplo:rotas. Vamos supor que seu novo nó mestre esteja na rede 10.0.0.0/24, seu servidor de aplicação esteja em 192.168.100.0/24 e você possa acessar a rede remota usando 192.168.100.100, então em seu servidor de aplicação, adicione a rota correspondente:
$ route add -net 10.0.0.0/24 gw 192.168.100.100
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.100.1 0.0.0.0 UG 0 0 0 eth0
10.0.0.0 192.168.100.100 255.255.255.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1027 0 0 eth0
192.168.100.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0Pontos de ação
Após verificar todos os pontos mencionados, você deve estar pronto para realizar as ações de failover do seu banco de dados.
Novo endereço IP
Como você promoverá um nó escravo, o endereço IP do mestre será alterado, portanto, você precisará alterá-lo em seu aplicativo ou acesso de cliente.
Usar um Load Balancer é uma excelente maneira de evitar esse problema/alteração. Após o processo de failover, o Load Balancer detectará o mestre antigo como off-line e (depende da configuração) enviará o tráfego para o novo para gravar nele, para que você não precise alterar nada em sua aplicação.
por exemplo:Vejamos um exemplo de configuração do HAProxy:
listen haproxy_5433
bind *:5433
mode tcp
timeout client 10800s
timeout server 10800s
balance leastconn
option tcp-check
server 192.168.100.119 192.168.100.119:5432 check
server 192.168.100.120 192.168.100.120:5432 checkNeste caso, se um nó estiver inativo, o HAProxy não enviará tráfego para lá e enviará o tráfego apenas para o nó disponível.
Reconfigure os nós escravos
Se você tiver mais de um nó escravo, após promover um deles, deverá reconfigurar o restante dos escravos para se conectar ao novo mestre. Esta pode ser uma tarefa demorada, dependendo do número de nós.
Verifique e configure os backups
Depois de ter tudo no lugar (novo master promovido, slaves reconfigurados, escrita de aplicativos no novo master), é importante tomar as ações necessárias para evitar um novo problema, então os backups são obrigatórios este passo. Muito provavelmente você tinha uma política de backup em execução antes do incidente (se não, você precisa tê-la com certeza), então você deve verificar se os backups ainda estão em execução ou eles funcionarão na nova topologia. Pode ser possível que você tenha os backups em execução no mestre antigo ou usando o nó escravo que é mestre agora, portanto, você precisa verificar para garantir que sua política de backup ainda funcione após as alterações.
Monitoramento de banco de dados
Quando você executa um processo de failover, o monitoramento é obrigatório antes, durante e depois do processo. Com isso, você pode evitar um problema antes que ele piore, detectar um problema inesperado durante o failover ou até mesmo saber se algo deu errado depois dele. Por exemplo, você deve monitorar se seu aplicativo pode acessar seu novo mestre verificando o número de conexões ativas.
Principais métricas a serem monitoradas
Vamos ver algumas das métricas mais importantes a serem consideradas:
- Atraso de replicação
- Status da replicação
- Número de conexões
- Uso da rede/erros
- Carga do servidor (CPU, Memória, Disco)
- Banco de dados e logs do sistema
Reversão
Claro, se algo deu errado, você deve ser capaz de reverter. Bloquear o tráfego para o nó antigo e mantê-lo o mais isolado possível pode ser uma boa estratégia para isso, portanto, caso você precise reverter, terá o nó antigo disponível. Se a reversão for após alguns minutos, dependendo do tráfego, você provavelmente precisará inserir os dados desses minutos no mestre antigo, portanto, certifique-se de ter também seu nó mestre temporário disponível e isolado para pegar essas informações e aplicá-las novamente .
Automatize o processo de failover com o ClusterControl
Vendo todas essas tarefas necessárias para realizar um failover, muito provavelmente você deseja automatizar e evitar todo esse trabalho manual. Para isso, você pode aproveitar alguns dos recursos que o ClusterControl pode oferecer para diferentes tecnologias de banco de dados, como recuperação automática, backups, gerenciamento de usuários, monitoramento, entre outros recursos, todos do mesmo sistema.
Com o ClusterControl você pode verificar o status da replicação e seu atraso, criar ou modificar credenciais, conhecer o status da rede e do host e ainda mais verificações.
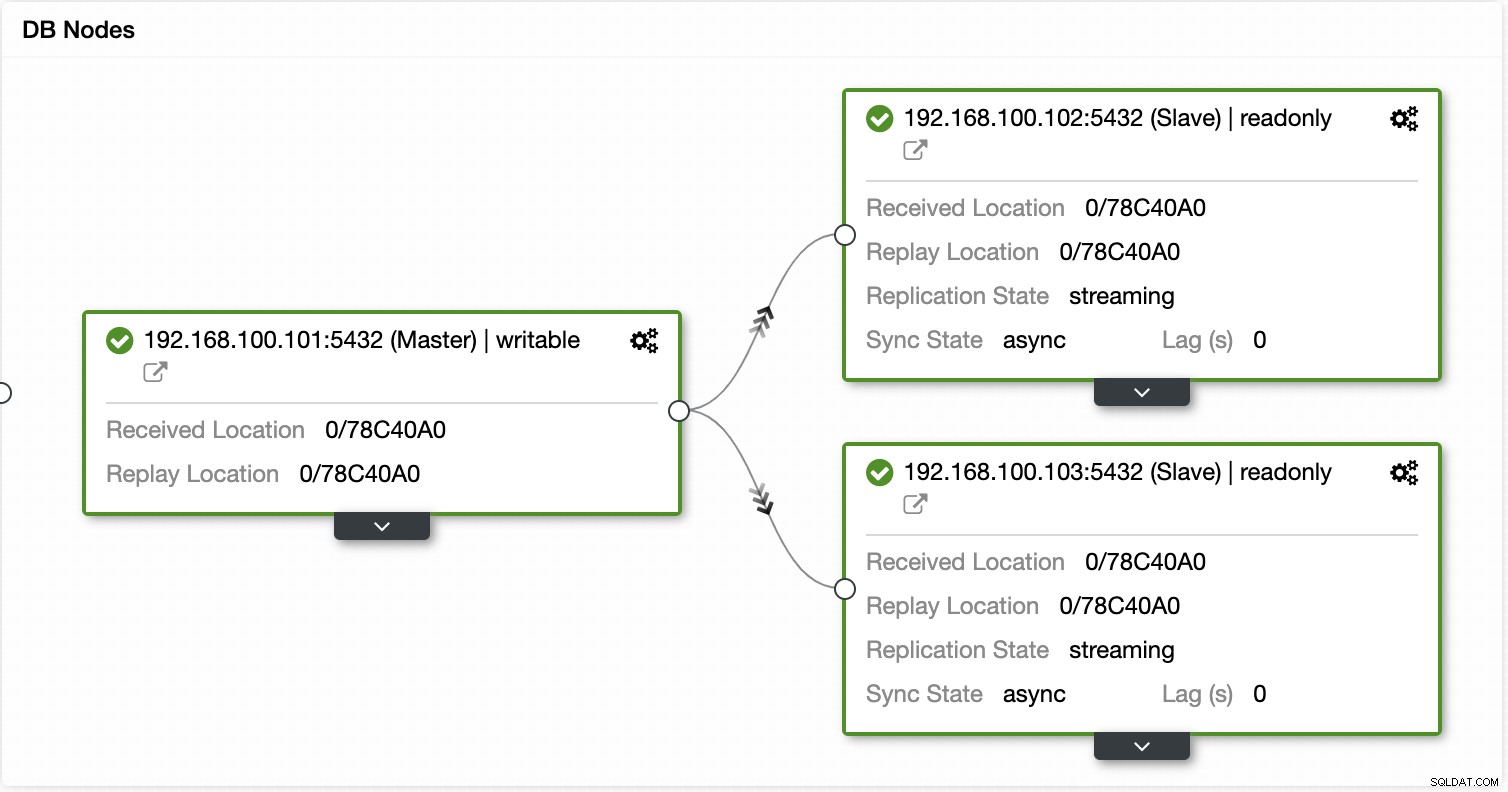
Usando o ClusterControl você também pode executar diferentes ações de cluster e nó, como promover escravo , reinicie o banco de dados e o servidor, adicione ou remova nós de banco de dados, adicione ou remova nós do balanceador de carga, reconstrua um escravo de replicação e muito mais.
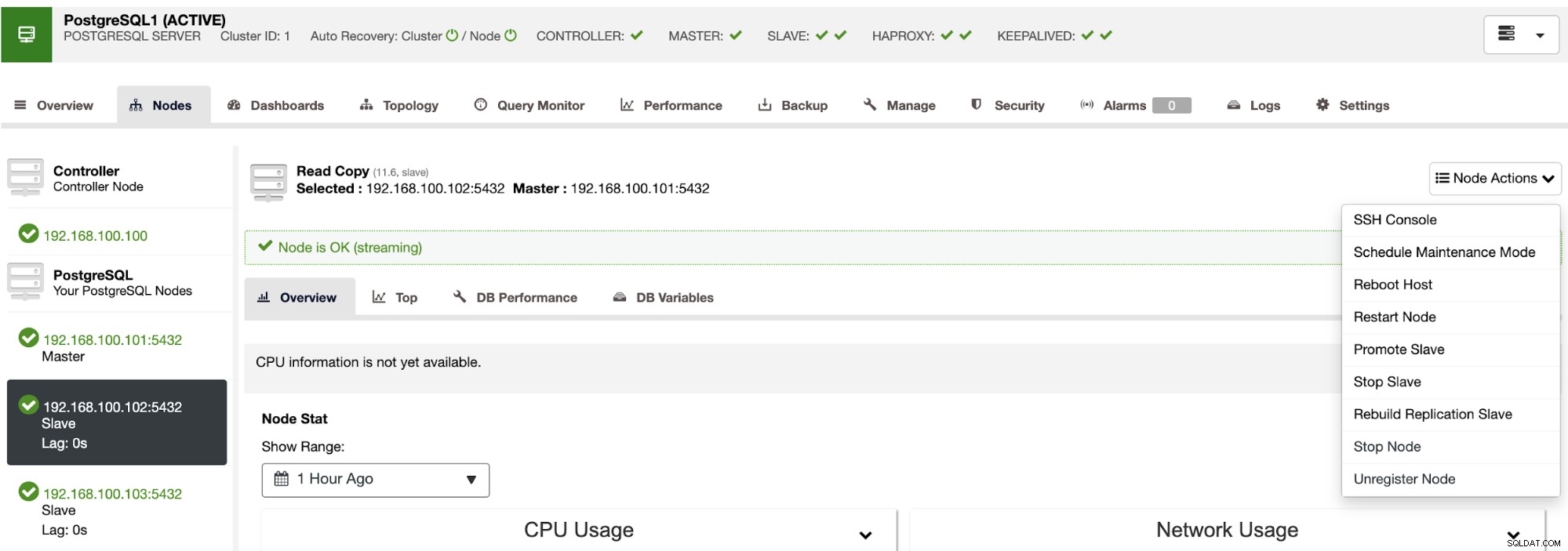
Usando essas ações, você também pode reverter seu failover, se necessário, reconstruindo e promovendo o mestre anterior.
O ClusterControl possui serviços de monitoramento e alerta que ajudam você a saber o que está acontecendo ou mesmo se algo aconteceu anteriormente.
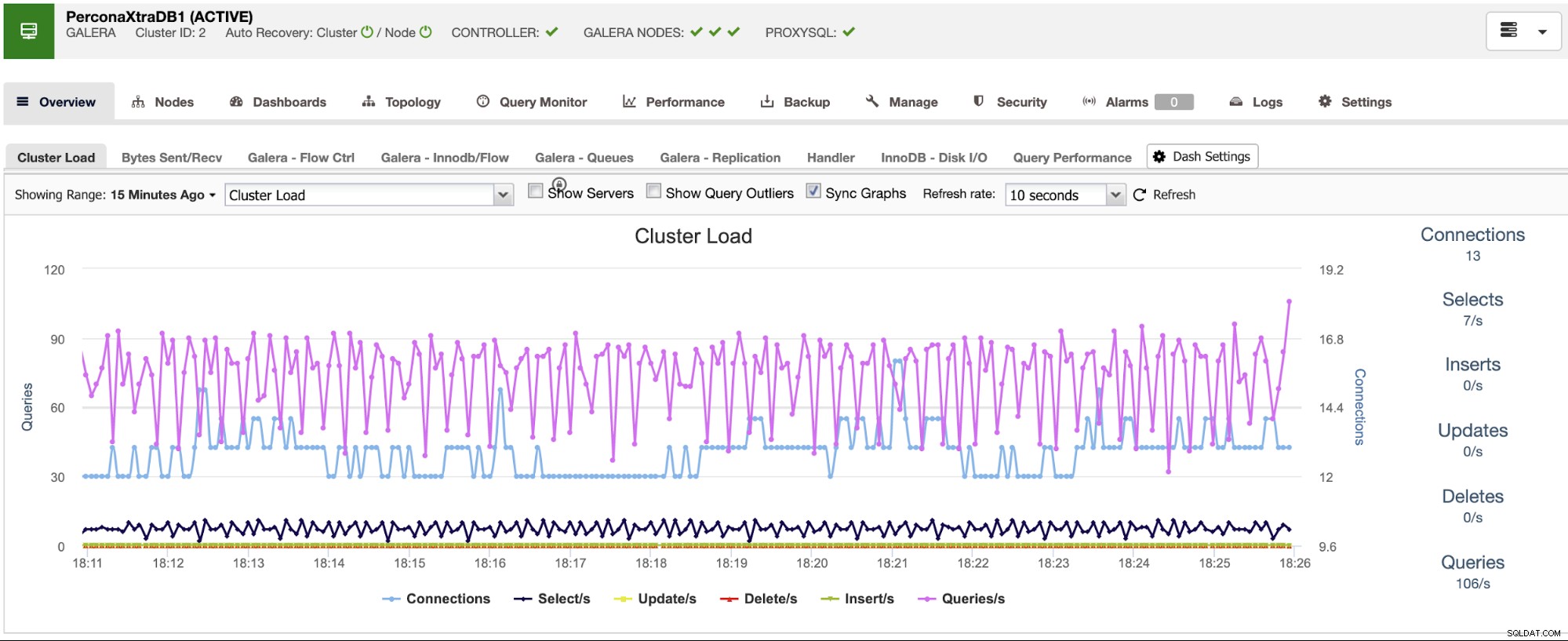
Você também pode usar a seção do painel para ter uma visualização mais amigável sobre o status de seus sistemas.
Conclusão
No caso de uma falha no banco de dados mestre, você desejará ter todas as informações no local para executar as ações necessárias o mais rápido possível. Ter um bom DRP é a chave para manter seu sistema funcionando o tempo todo (ou quase todo). Esse DRP deve incluir um processo de failover bem documentado para ter um RTO (objetivo de tempo de recuperação) aceitável para a empresa.