Em um blog anterior, anunciamos um novo recurso do ClusterControl 1.7.4 chamado Replicação de cluster para cluster. Ele automatiza todo o processo de configuração de um cluster de DR fora de seu cluster primário, com replicação no meio. Para obter informações mais detalhadas, consulte a entrada de blog mencionada acima.
Agora, neste blog, veremos como configurar esse novo recurso para um cluster existente. Para esta tarefa, vamos supor que você tenha o ClusterControl instalado e o Cluster Mestre foi implantado usando-o.
Requisitos para o cluster mestre
Existem alguns requisitos para que o cluster mestre funcione:
- Percona XtraDB Cluster versão 5.6.xe posterior, ou MariaDB Galera Cluster versão 10.xe posterior.
- GTID ativado.
- Registro binário ativado em pelo menos um nó de banco de dados.
- As credenciais de backup devem ser as mesmas no cluster mestre e no cluster escravo.
Preparando o cluster mestre
O cluster mestre precisa estar preparado para usar esse novo recurso. Requer configuração do lado do ClusterControl e do banco de dados.
Configuração de controle de cluster
No nó do banco de dados, verifique as credenciais do usuário de backup armazenadas em /etc/my.cnf.d/secrets-backup.cnf (para sistema operacional baseado em RedHat) ou em /etc/mysql/secrets-backup .cnf (para SO baseado em Debian).
$ cat /etc/my.cnf.d/secrets-backup.cnf
# Security credentials for backup.
[mysqldump]
user=backupuser
password=cYj0GFBEdqdreZEl
[xtrabackup]
user=backupuser
password=cYj0GFBEdqdreZEl
[mysqld]
wsrep_sst_auth=backupuser:cYj0GFBEdqdreZElNo nó ClusterControl, edite o arquivo de configuração /etc/cmon.d/cmon_ID.cnf (em que ID é o Número de ID do Cluster) e certifique-se de que ele contenha as mesmas credenciais armazenadas em secrets-backup. cnf.
$ cat /etc/cmon.d/cmon_8.cnf
backup_user=backupuser
backup_user_password=cYj0GFBEdqdreZEl
basedir=/usr
cdt_path=/
cluster_id=8
...Qualquer alteração neste arquivo requer uma reinicialização do serviço cmon:
$ service cmon restartVerifique os parâmetros de replicação do banco de dados para certificar-se de que você tenha ativado o GTID e o log binário.
Configuração do banco de dados
No nó do banco de dados, verifique o arquivo /etc/my.cnf (para sistema operacional baseado em RedHat) ou /etc/mysql/my.cnf (para sistema operacional baseado em Debian) para ver a configuração relacionada ao processo de replicação.
Percona XtraDB:
$ cat /etc/my.cnf
# REPLICATION SPECIFIC
server_id=4002
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
gtid_mode = ON
enforce_gtid_consistency = true
relay_log = relay-log
expire_logs_days = 7Cluster MariaDB Galera:
$ cat /etc/my.cnf
# REPLICATION SPECIFIC
server_id=9000
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
relay_log = relay-log
wsrep_gtid_domain_id=9000
wsrep_gtid_mode=ON
gtid_domain_id=9000
gtid_strict_mode=ON
gtid_ignore_duplicates=ON
expire_logs_days = 7Ao verificar os arquivos de configuração, você pode verificar se está habilitado na interface do ClusterControl. Vá para ClusterControl -> Selecione Cluster -> Nós. Lá você deve ter algo assim:

A função “Master” adicionada no primeiro nó significa que o log binário está ativado.
Ativando o registro binário
Se você não tiver o log binário habilitado, vá para ClusterControl -> Select Cluster -> Nodes -> Node Actions -> Enable Binary Logging.
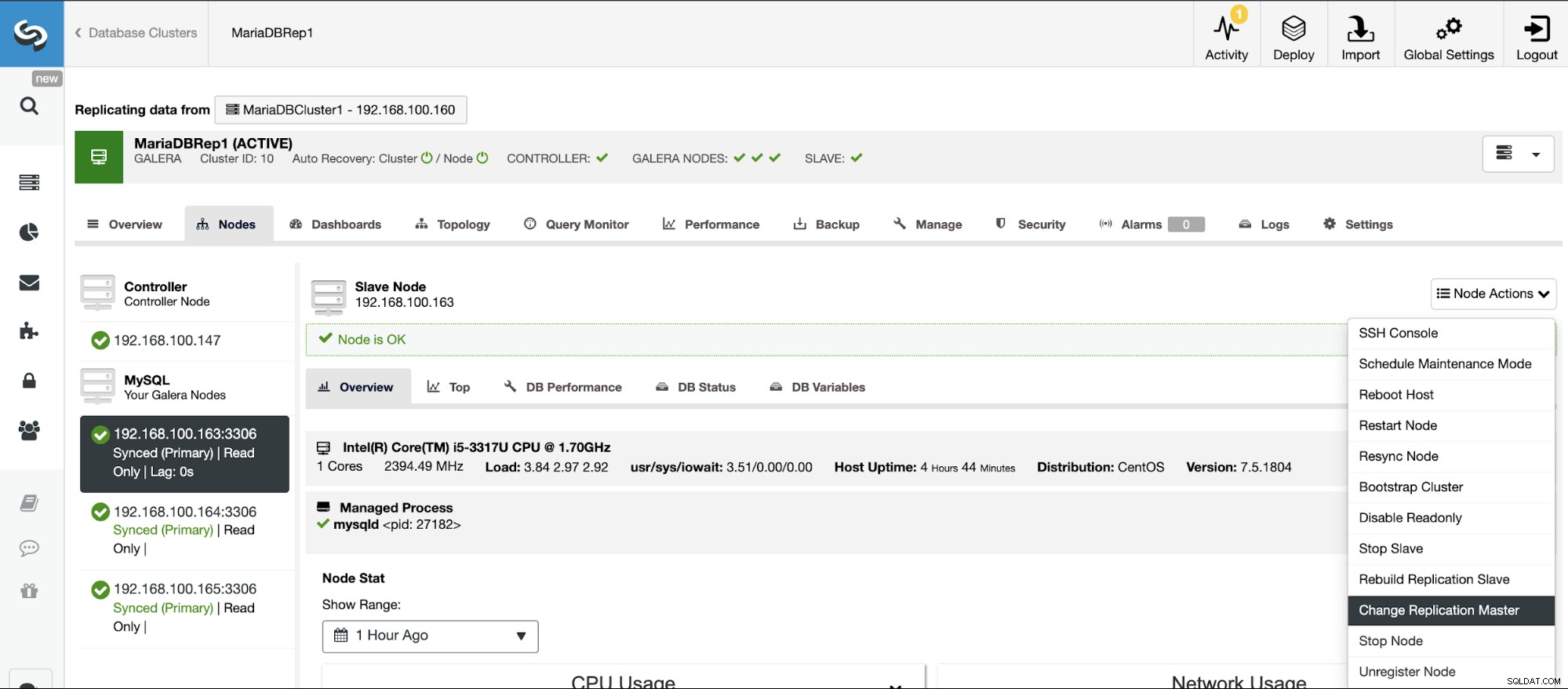
Depois, você deve especificar a retenção de log binário e o caminho para armazenar isto. Você também deve especificar se deseja que o ClusterControl reinicie o nó do banco de dados após configurá-lo ou se prefere reiniciá-lo por conta própria.
Lembre-se de que habilitar o log binário sempre requer uma reinicialização do serviço de banco de dados .
Criando o cluster escravo a partir da GUI do ClusterControl
Para criar um novo Cluster Slave, vá para ClusterControl -> Select Cluster -> Cluster Actions -> Create Slave Cluster.
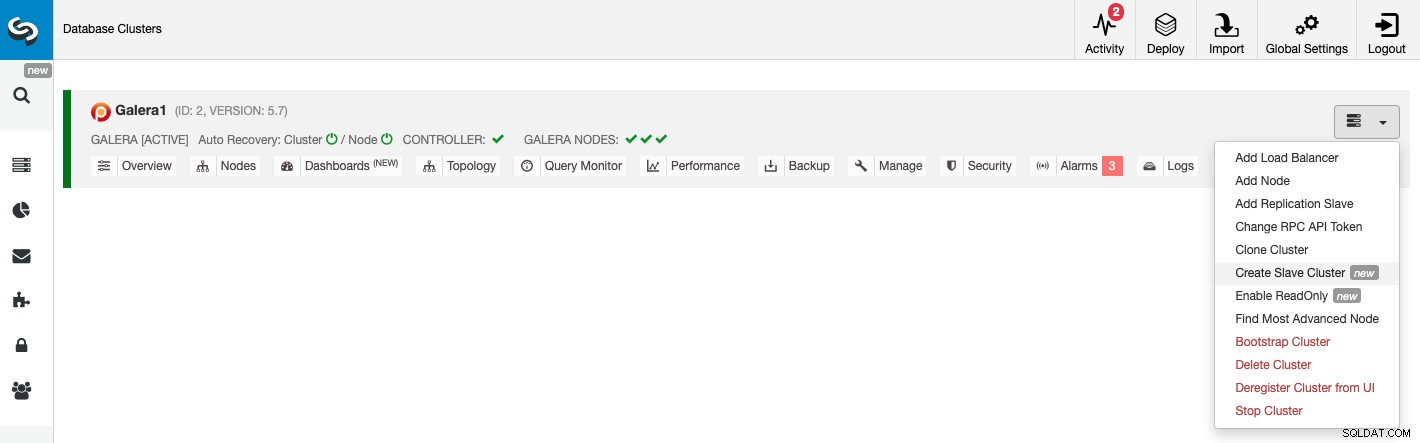
O cluster escravo pode ser criado por streaming de dados do cluster mestre atual ou usando um backup existente.
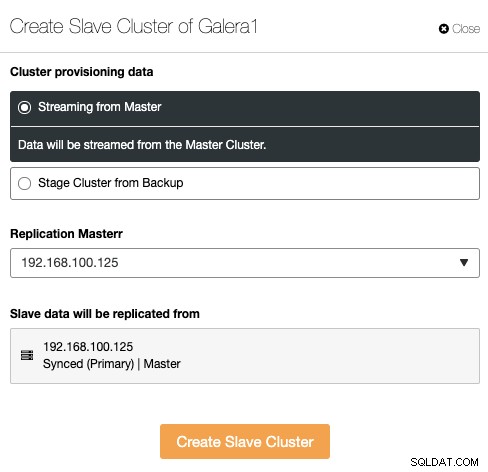
Nesta seção, você também deve escolher o nó mestre do cluster atual a partir do qual os dados serão replicados.
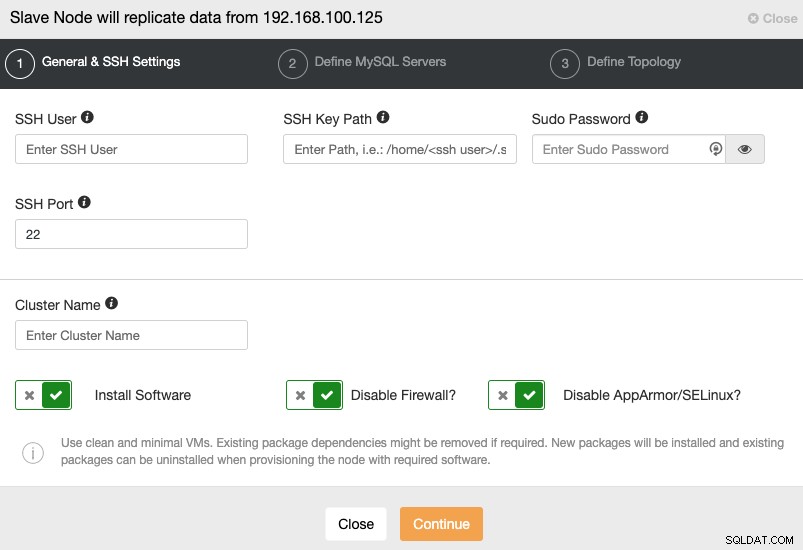
Quando você for para a próxima etapa, você deve especificar User, Key ou Senha e porta para conectar por SSH aos seus servidores. Você também precisa de um nome para o seu Slave Cluster e se quiser que o ClusterControl instale o software e as configurações correspondentes para você.
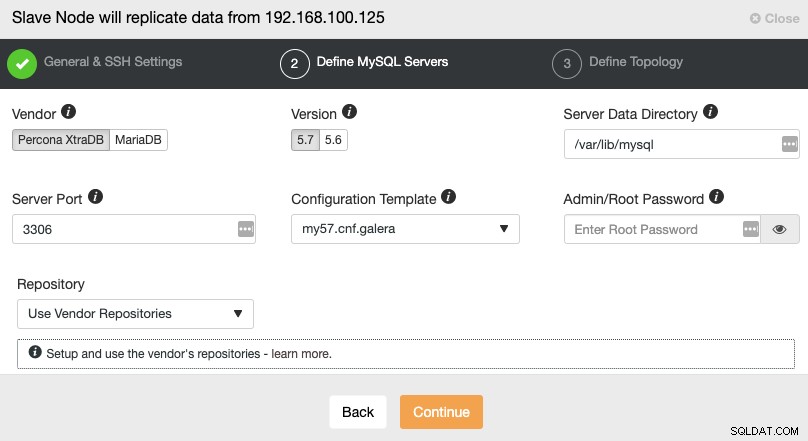
Após configurar as informações de acesso SSH, você deve definir o fornecedor do banco de dados e versão, datadir, porta do banco de dados e a senha do administrador. Certifique-se de usar o mesmo fornecedor/versão e credenciais usadas pelo cluster mestre. Você também pode especificar qual repositório usar.
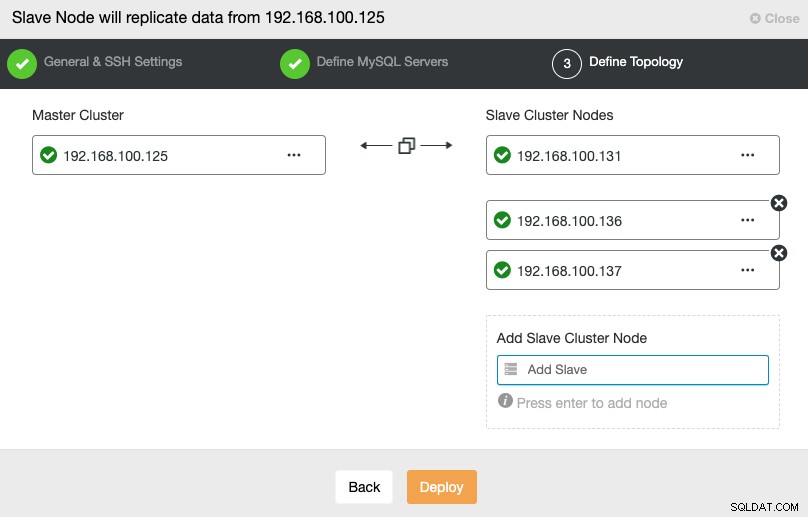
Nesta etapa, você precisa adicionar servidores ao novo cluster escravo. Para esta tarefa, você pode inserir o endereço IP ou o nome do host de cada nó do banco de dados.
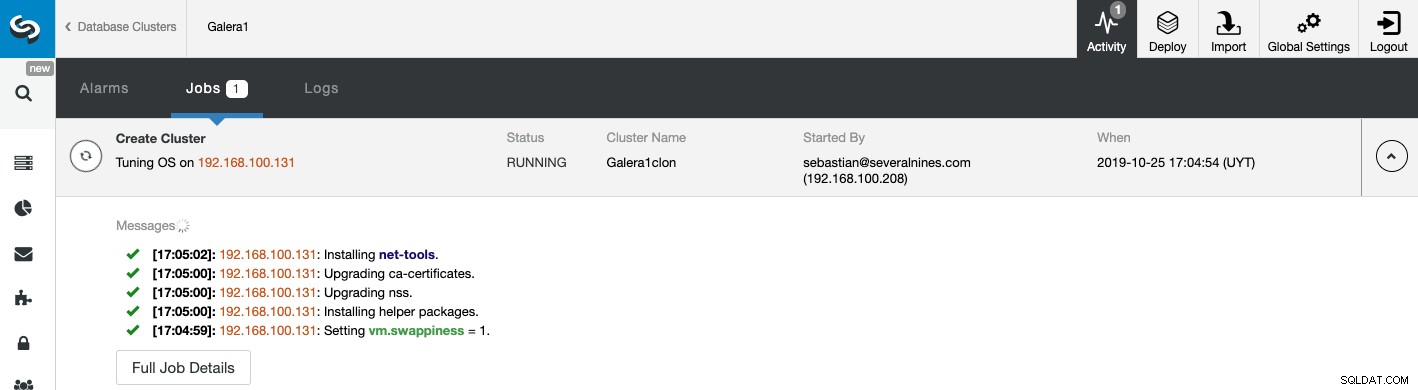
Você pode monitorar o status da criação do seu novo Slave Cluster a partir do Monitor de atividade do ClusterControl. Quando a tarefa estiver concluída, você poderá ver o cluster na tela principal do ClusterControl.
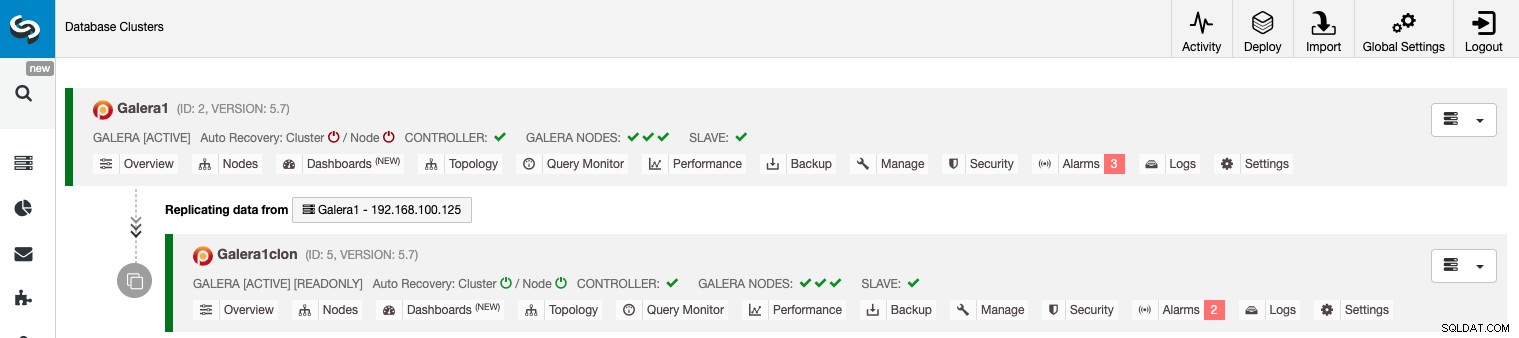
Gerenciando a replicação de cluster para cluster usando a GUI do ClusterControl
Agora que você tem sua replicação de cluster para cluster em execução, há diferentes ações a serem executadas nessa topologia usando o ClusterControl.
Configurar clusters ativos-ativos
Como você pode ver, por padrão o Slave Cluster é configurado no modo Read-Only. É possível desabilitar o sinalizador Read-Only nos nós um por um da UI ClusterControl, mas lembre-se de que o clustering Active-Active só é recomendado se os aplicativos estiverem apenas tocando conjuntos de dados disjuntos em qualquer cluster, pois o MySQL/MariaDB não oferecer qualquer Detecção ou Resolução de Conflitos.
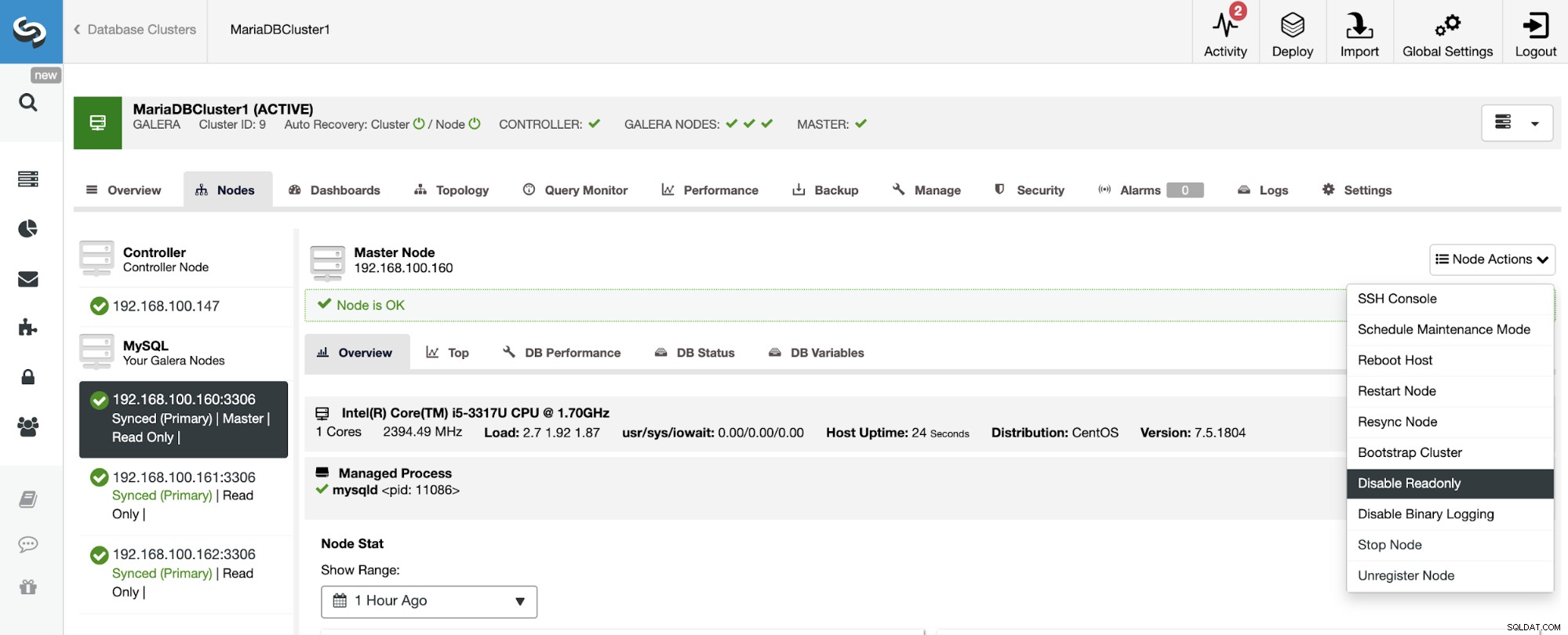
Para desabilitar o modo somente leitura, vá para ClusterControl -> Selecione Slave Cluster -> Nós. Nesta seção, selecione cada nó e use a opção Desativar somente leitura.
Reconstruindo um cluster escravo
Para evitar inconsistências, se você deseja reconstruir um cluster escravo, este deve ser um cluster somente leitura, isso significa que todos os nós devem estar no modo somente leitura.
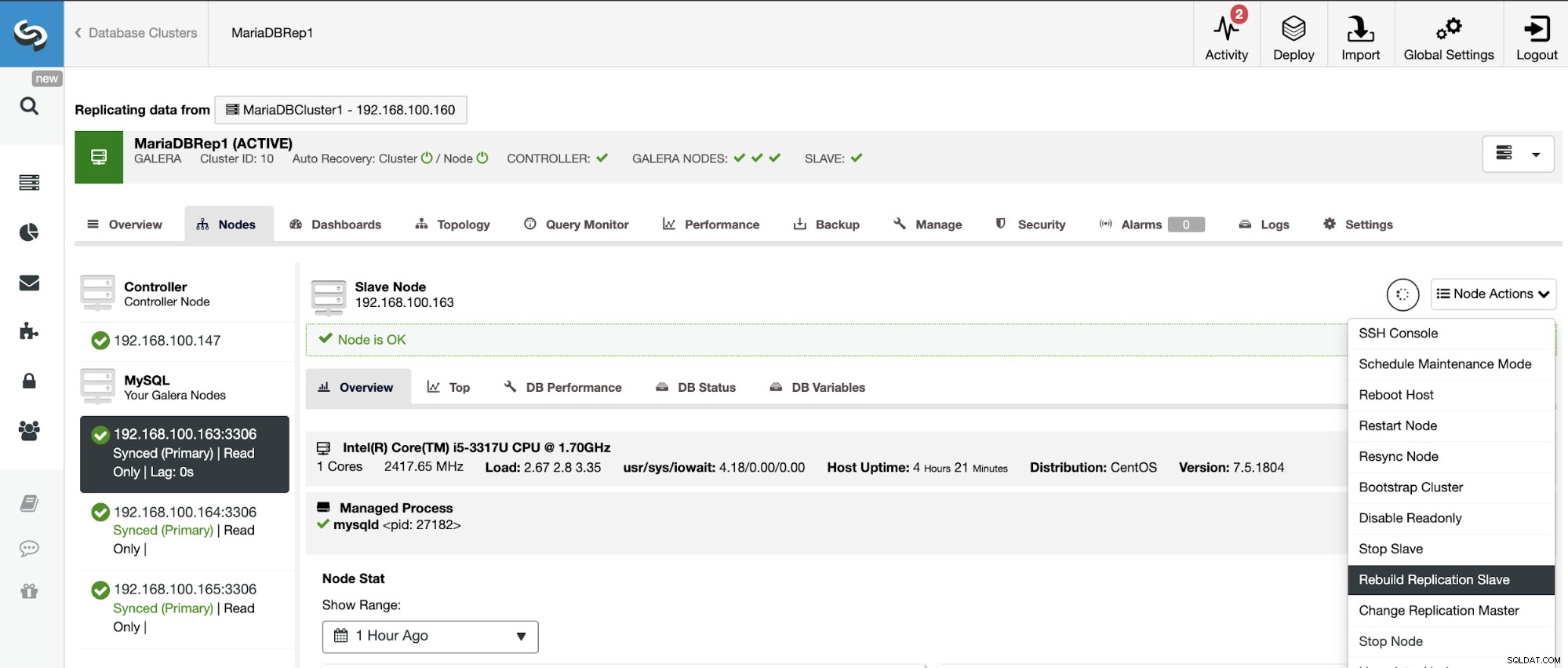
Vá para ClusterControl -> Select Slave Cluster -> Nodes -> Escolha o Nó conectado ao Cluster Mestre -> Ações do Nó -> Reconstruir Escravo de Replicação.
Alterações de topologia
Se você tiver a seguinte topologia:
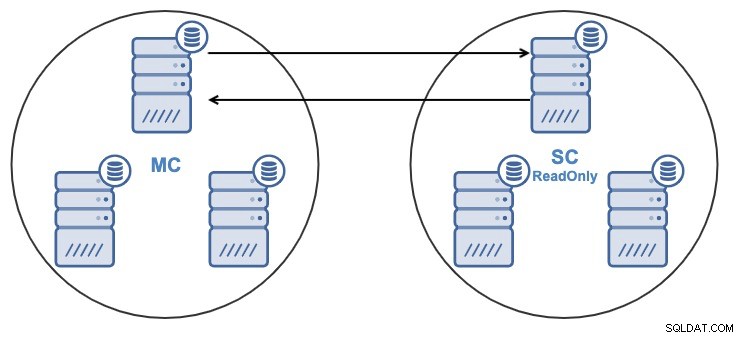
E por algum motivo, você deseja alterar o nó de replicação no mestre Cacho. É possível alterar o nó mestre usado pelo cluster escravo para outro nó mestre no cluster mestre.
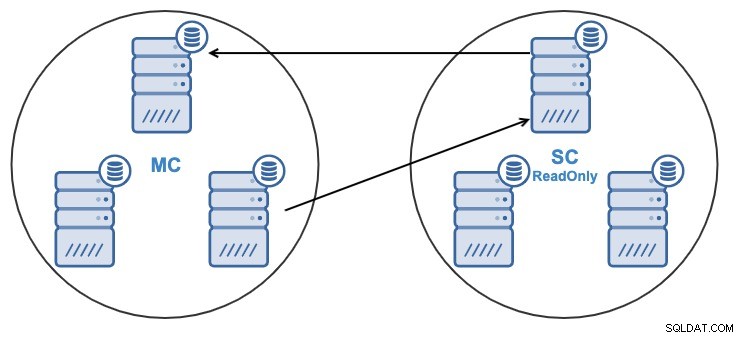
Para ser considerado um nó mestre, deve ter o log binário habilitado .
Vá para ClusterControl -> Select Slave Cluster -> Nodes -> Escolha o Nó conectado ao Cluster Mestre -> Ações do Nó -> Parar Escravo/Iniciar Escravo.
Parar/Iniciar Escravo de Replicação
Você pode parar e iniciar os escravos de replicação de maneira fácil usando o ClusterControl.
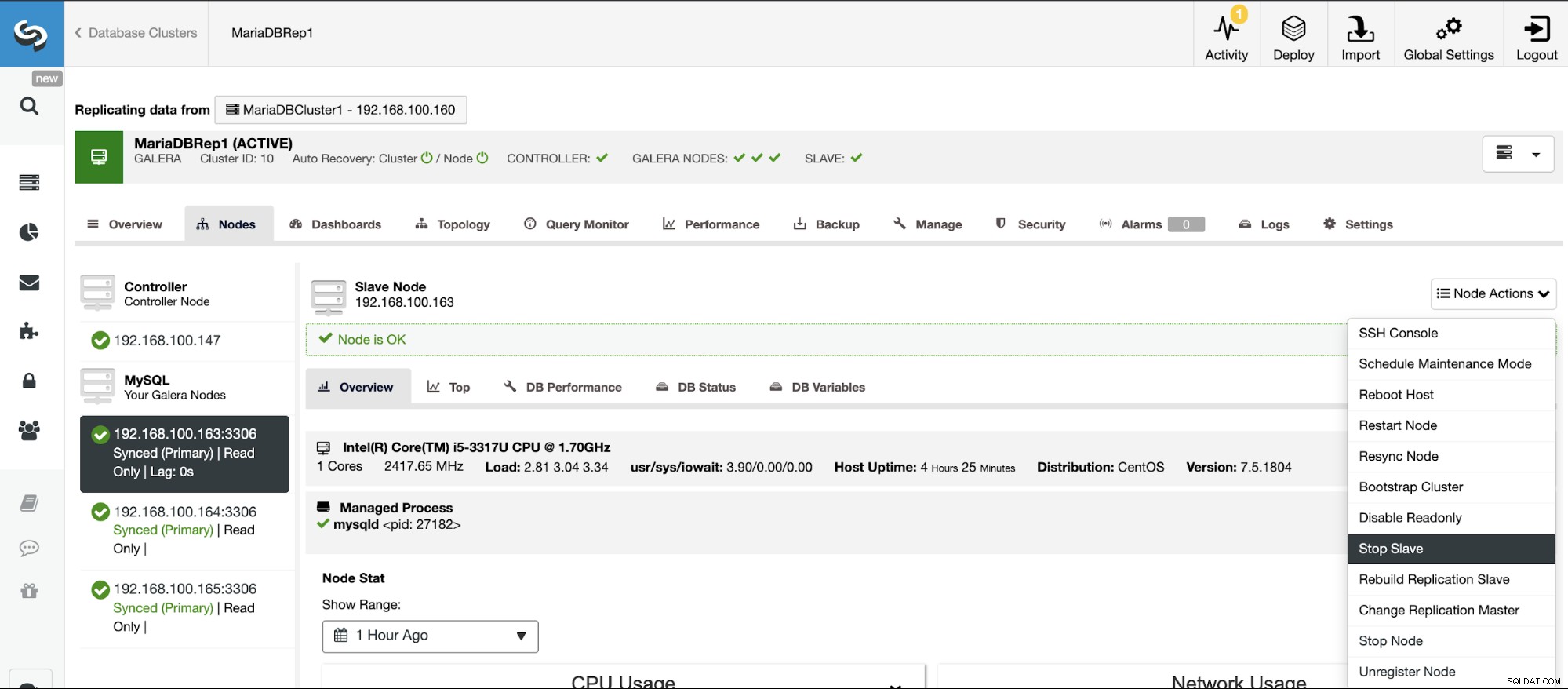
Vá para ClusterControl -> Select Slave Cluster -> Nodes -> Escolha o Nó conectado ao Cluster Mestre -> Ações do Nó -> Parar Escravo/Iniciar Escravo.
Redefinir escravo de replicação
Usando esta ação, você pode redefinir o processo de replicação usando RESET SLAVE ou RESET SLAVE ALL. A diferença entre eles é que RESET SLAVE não altera nenhum parâmetro de replicação como host mestre, porta e credenciais. Para deletar esta informação você deve usar RESET SLAVE ALL que remove toda a configuração de replicação, então usando este comando o link de Replicação Cluster-to-Cluster será destruído.
Antes de usar este recurso, você deve interromper o processo de replicação (consulte o recurso anterior).
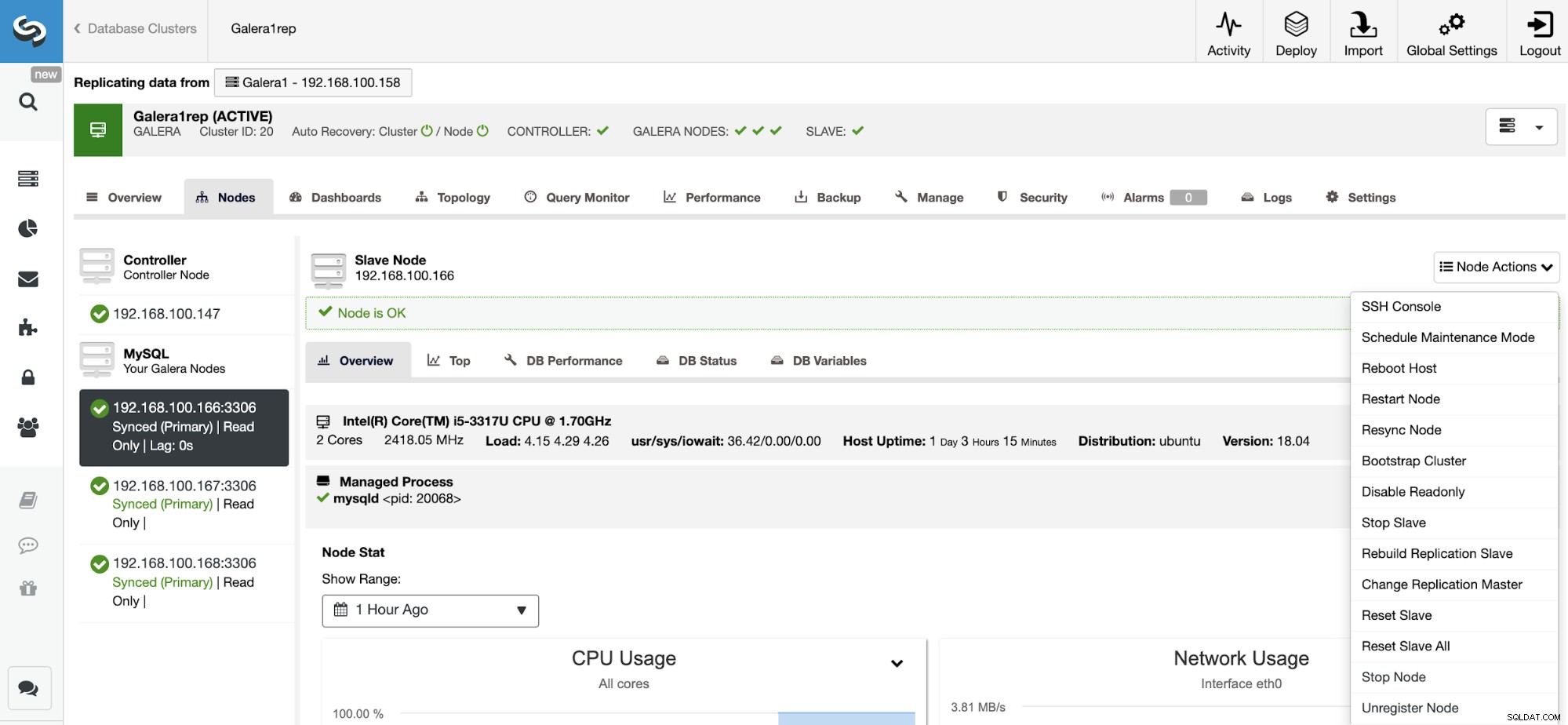
Vá para ClusterControl -> Select Slave Cluster -> Nodes -> Escolha o Nó conectado ao cluster mestre -> Ações do nó -> Reset Slave/Reset Slave All.
Gerenciando a replicação de cluster para cluster usando a CLI do ClusterControl
Na seção anterior, você viu como gerenciar uma replicação de cluster para cluster usando a interface do usuário do ClusterControl. Agora, vamos ver como fazer isso usando a linha de comando.
Observação:como mencionamos no início deste blog, presumiremos que você tenha o ClusterControl instalado e o cluster mestre foi implantado usando-o.
Criar o cluster escravo
Primeiro, vamos ver um exemplo de comando para criar um cluster escravo usando a CLI do ClusterControl:
$ s9s cluster --create --cluster-name=Galera1rep --cluster-type=galera --provider-version=10.4 --nodes="192.168.100.166;192.168.100.167;192.168.100.168" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=root --db-admin-passwd=xxxxxxxx --vendor=mariadb --remote-cluster-id=11 --logAgora que você tem seu processo de criação escravo em execução, vamos ver cada parâmetro usado:
- Cluster:para listar e manipular clusters.
- Criar:criar e instalar um novo cluster.
- Nome do cluster:o nome do novo cluster escravo.
- Tipo de cluster:o tipo de cluster a ser instalado.
- Versão do provedor:a versão do software.
- Nós:lista dos novos nós no cluster escravo.
- Os-user:o nome de usuário para os comandos SSH.
- Os-key-file:o arquivo de chave a ser usado para conexão SSH.
- Db-admin:o nome de usuário do administrador do banco de dados.
- Db-admin-passwd:a senha para o administrador do banco de dados.
- Remote-cluster-id:ID do cluster mestre para a replicação de cluster para cluster.
- Log:aguarde e monitore as mensagens de trabalho.
Usando o sinalizador --log, você poderá ver os logs em tempo real:
Verifying job parameters.
Checking ssh/sudo on 3 hosts.
All 3 hosts are accessible by SSH.
192.168.100.166: Checking if host already exists in another cluster.
192.168.100.167: Checking if host already exists in another cluster.
192.168.100.168: Checking if host already exists in another cluster.
192.168.100.157:3306: Binary logging is enabled.
192.168.100.158:3306: Binary logging is enabled.
Creating the cluster with the following:
wsrep_cluster_address = 'gcomm://192.168.100.166,192.168.100.167,192.168.100.168'
Calling job: setupServer(192.168.100.166).
192.168.100.166: Checking OS information.
…
Caching config files.
Job finished, all the nodes have been added successfully.Configurar clusters ativos-ativos
Como você viu anteriormente, você pode desabilitar o modo Read-Only no novo cluster desabilitando-o em cada nó, então vamos ver como fazer isso na linha de comando.
$ s9s node --set-read-write --nodes="192.168.100.166" --cluster-id=16 --logVamos ver cada parâmetro:
- Nó:para lidar com nós.
- Set-read-write:defina o nó para o modo Read-Write.
- Nós:o nó onde alterá-lo.
- ID do cluster:o ID do cluster no qual o nó está.
Então, você verá:
192.168.100.166:3306: Setting read_only=OFF.Reconstruindo um cluster escravo
Você pode reconstruir um cluster escravo usando o seguinte comando:
$ s9s replication --stage --master="192.168.100.157:3306" --slave="192.168.100.166:3306" --cluster-id=19 --remote-cluster-id=11 --logOs parâmetros são:
- Replicação:para monitorar e controlar a replicação de dados.
- Estágio:preparar/reconstruir um escravo de replicação.
- Mestre:o mestre de replicação no cluster mestre.
- Escravo:o escravo de replicação no cluster escravo.
- ID do cluster:o ID do cluster escravo.
- ID do cluster remoto:o ID do cluster mestre.
- Log:aguarde e monitore as mensagens de trabalho.
O log de tarefas deve ser semelhante a este:
Rebuild replication slave 192.168.100.166:3306 from master 192.168.100.157:3306.
Remote cluster id = 11
Shutting down Galera Cluster.
192.168.100.166:3306: Stopping node.
192.168.100.166:3306: Stopping mysqld (timeout=60, force stop after timeout=true).
192.168.100.166: Stopping MySQL service.
192.168.100.166: All processes stopped.
192.168.100.166:3306: Stopped node.
192.168.100.167:3306: Stopping node.
192.168.100.167:3306: Stopping mysqld (timeout=60, force stop after timeout=true).
192.168.100.167: Stopping MySQL service.
192.168.100.167: All processes stopped.
…
192.168.100.157:3306: Changing master to 192.168.100.166:3306.
192.168.100.157:3306: Changed master to 192.168.100.166:3306
192.168.100.157:3306: Starting slave.
192.168.100.157:3306: Collecting replication statistics.
192.168.100.157:3306: Started slave successfully.
192.168.100.166:3306: Starting node
Writing file '192.168.100.167:/etc/mysql/my.cnf'.
Writing file '192.168.100.167:/etc/mysql/secrets-backup.cnf'.
Writing file '192.168.100.168:/etc/mysql/my.cnf'.Alterações de topologia
Você pode alterar sua topologia usando outro nó no cluster mestre do qual replica os dados, por exemplo, você pode executar:
$ s9s replication --failover --master="192.168.100.161:3306" --slave="192.168.100.163:3306" --cluster-id=10 --remote-cluster-id=9 --logVamos verificar os parâmetros usados.
- Replicação:para monitorar e controlar a replicação de dados.
- Failover:assuma o papel de mestre de um mestre com falha/antigo.
- Mestre:o novo mestre de replicação no cluster mestre.
- Escravo:o escravo de replicação no cluster escravo.
- ID do cluster:o ID do cluster escravo.
- ID do cluster remoto:o ID do cluster mestre.
- Log:aguarde e monitore as mensagens de trabalho.
Você verá este log:
192.168.100.161:3306 belongs to cluster id 9.
192.168.100.163:3306: Changing master to 192.168.100.161:3306
192.168.100.163:3306: My master is 192.168.100.160:3306.
192.168.100.161:3306: Sanity checking replication master '192.168.100.161:3306[cid:9]' to be used by '192.168.100.163[cid:139814070386698]'.
192.168.100.161:3306: Executing GRANT REPLICATION SLAVE ON *.* TO 'cmon_replication'@'192.168.100.163'.
Setting up link between 192.168.100.161:3306 and 192.168.100.163:3306
192.168.100.163:3306: Stopping slave.
192.168.100.163:3306: Successfully stopped slave.
192.168.100.163:3306: Setting up replication using MariaDB GTID: 192.168.100.161:3306->192.168.100.163:3306.
192.168.100.163:3306: Changing Master using master_use_gtid=slave_pos.
192.168.100.163:3306: Changing master to 192.168.100.161:3306.
192.168.100.163:3306: Changed master to 192.168.100.161:3306
192.168.100.163:3306: Starting slave.
192.168.100.163:3306: Collecting replication statistics.
192.168.100.163:3306: Started slave successfully.
192.168.100.160:3306: Flushing logs to update 'SHOW SLAVE HOSTS'Parar/Iniciar Escravo de Replicação
Você pode parar para replicar os dados do cluster mestre desta forma:
$ s9s replication --stop --slave="192.168.100.166:3306" --cluster-id=19 --logVocê verá isto:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Stopping slave.
192.168.100.166:3306: Successfully stopped slave.E agora, você pode iniciá-lo novamente:
$ s9s replication --start --slave="192.168.100.166:3306" --cluster-id=19 --logEntão, você verá:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Starting slave.
192.168.100.166:3306: Collecting replication statistics.
192.168.100.166:3306: Started slave successfully.Agora, vamos verificar os parâmetros usados.
- Replicação:para monitorar e controlar a replicação de dados.
- Parar/Iniciar:Para fazer o escravo parar/iniciar a replicação.
- Escravo:o nó escravo de replicação.
- ID do cluster:o ID do cluster no qual o nó escravo está.
- Log:aguarde e monitore as mensagens de trabalho.
Redefinir escravo de replicação
Usando este comando, você pode redefinir o processo de replicação usando RESET SLAVE ou RESET SLAVE ALL. Para obter mais informações sobre esse comando, verifique o uso dele na seção anterior do ClusterControl UI.
Antes de usar este recurso, você deve interromper o processo de replicação (consulte o comando anterior).
REINICIAR ESCRAVO:
$ s9s replication --reset --slave="192.168.100.166:3306" --cluster-id=19 --logO log deve ser assim:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Executing 'RESET SLAVE'.
192.168.100.166:3306: Command 'RESET SLAVE' succeeded.RESET SLAVE ALL:
$ s9s replication --reset --force --slave="192.168.100.166:3306" --cluster-id=19 --logE este log deve ser:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
192.168.100.166:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.Vamos ver os parâmetros usados para RESET SLAVE e RESET SLAVE ALL.
- Replicação:para monitorar e controlar a replicação de dados.
- Redefinir:redefina o nó escravo.
- Forçar:Usando este sinalizador, você usará o comando RESET SLAVE ALL no nó escravo.
- Escravo:o nó escravo de replicação.
- ID do cluster:o ID do cluster escravo.
- Log:aguarde e monitore as mensagens de trabalho.
Conclusão
Esse novo recurso ClusterControl permitirá que você crie replicação cluster a cluster rapidamente e a gerencie de maneira fácil e amigável. Esse ambiente melhorará sua topologia de banco de dados/cluster e seria útil para um plano de recuperação de desastres, ambiente de teste e ainda mais opções mencionadas no blog de visão geral.