Alta disponibilidade é uma necessidade hoje em dia, pois a maioria das organizações não pode perder seus dados. A Alta Disponibilidade, no entanto, sempre vem com um preço (que pode variar muito). Qualquer configuração que exija ação quase imediata normalmente exigiria um ambiente caro que espelharia precisamente a configuração de produção. Mas, existem outras opções que podem ser mais baratas. Eles podem não permitir uma mudança imediata para um cluster de recuperação de desastres, mas ainda permitirão a continuidade dos negócios (e não esgotarão o orçamento).
Um exemplo desse tipo de configuração é um ambiente de DR “cold-standby”. Ele permite que você reduza suas despesas enquanto ainda é capaz de criar um novo ambiente em um local externo caso ocorra um desastre. Nesta postagem do blog, demonstraremos como criar essa configuração.
A configuração inicial
Vamos supor que temos uma configuração padrão de Replicação MySQL Mestre/Escravo em nosso próprio datacenter. É uma configuração altamente disponível com ProxySQL e Keepalived para manipulação de IP virtual. O principal risco é que o datacenter fique indisponível. É um pequeno DC, talvez seja apenas um ISP sem BGP. E nessa situação, vamos supor que, se levar horas para trazer de volta o banco de dados, tudo bem, desde que seja possível trazê-lo de volta.
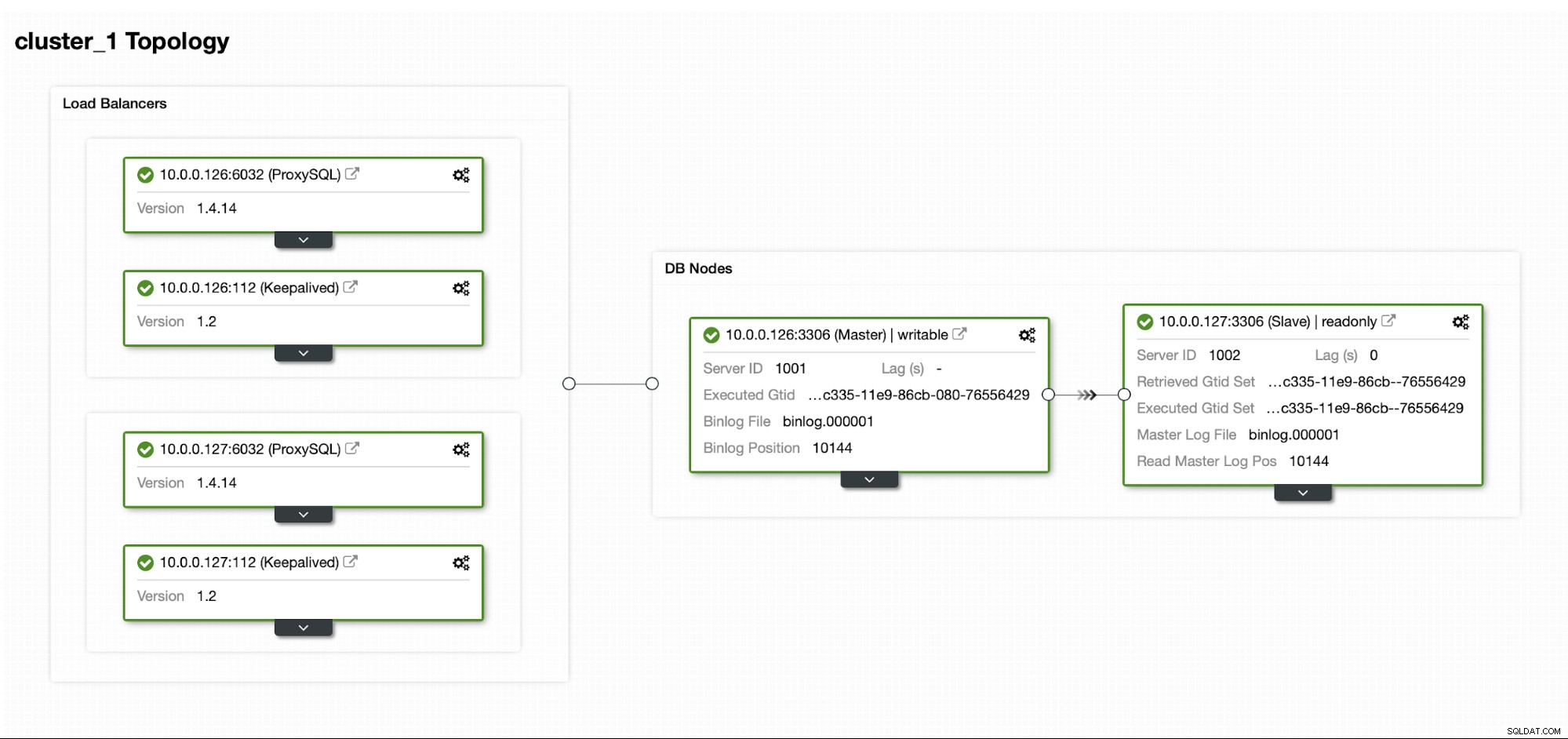
Para implantar este cluster usamos o ClusterControl, que você pode baixar gratuitamente. Para nosso ambiente de DR, usaremos o EC2 (mas também pode ser qualquer outro provedor de nuvem).
O desafio
O principal problema com o qual temos que lidar é como devemos garantir que temos dados atualizados para restaurar nosso banco de dados no ambiente de recuperação de desastres? Claro, idealmente teríamos um escravo de replicação funcionando no EC2... mas então temos que pagar por isso. Se estivermos apertados no orçamento, podemos tentar contornar isso com backups. Esta não é a solução perfeita, pois, na pior das hipóteses, nunca poderemos recuperar todos os dados.
Por “pior cenário” queremos dizer uma situação em que não teremos acesso aos servidores de banco de dados originais. Se pudéssemos alcançá-los, os dados não teriam sido perdidos.
A solução
Vamos usar o ClusterControl para configurar um agendamento de backup para reduzir a chance de perda de dados. Também usaremos o recurso ClusterControl para fazer upload de backups para a nuvem. Se o datacenter não estiver disponível, podemos esperar que o provedor de nuvem que escolhemos seja alcançável.
Configurando o agendamento de backup no ClusterControl
Primeiro, teremos que configurar o ClusterControl com nossas credenciais de nuvem.
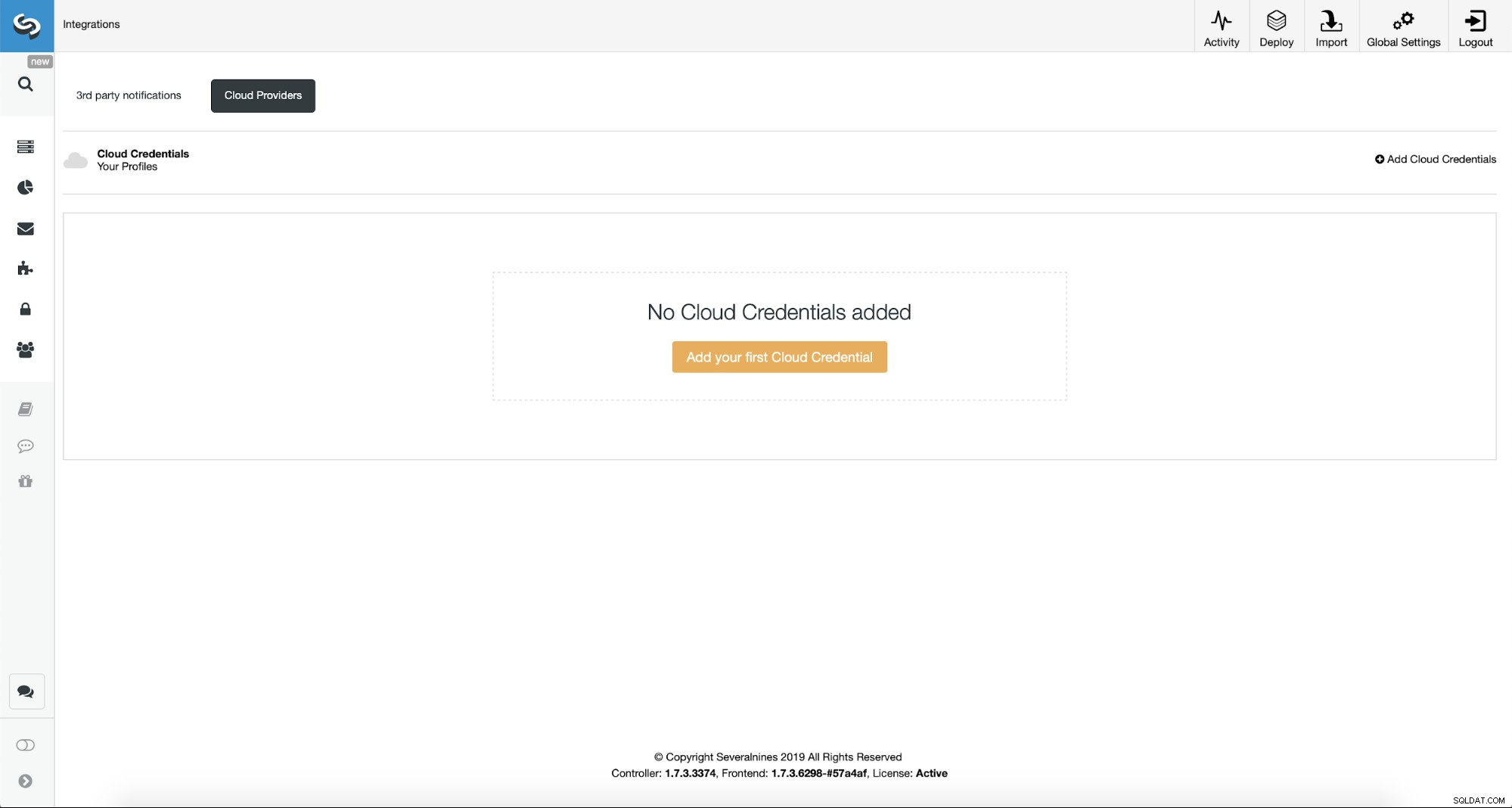
Podemos fazer isso usando “Integrações” no menu do lado esquerdo.
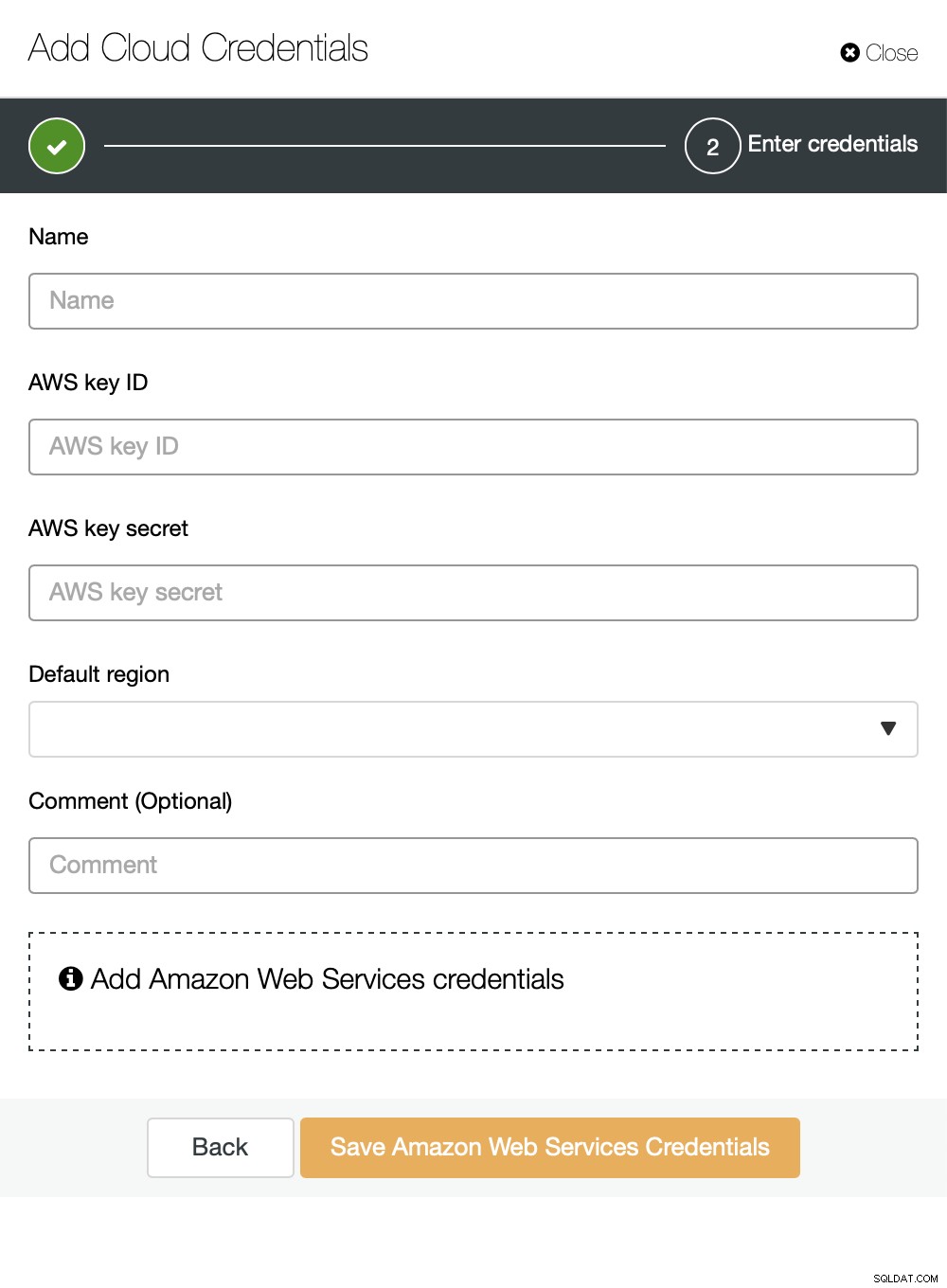
Você pode escolher Amazon Web Services, Google Cloud ou Microsoft Azure como a nuvem você deseja que o ClusterControl carregue backups. Continuaremos com a AWS, onde o ClusterControl usará o S3 para armazenar backups.
Depois, precisamos passar o ID da chave e o segredo da chave, escolha a região padrão e escolha um nome para esse conjunto de credenciais.
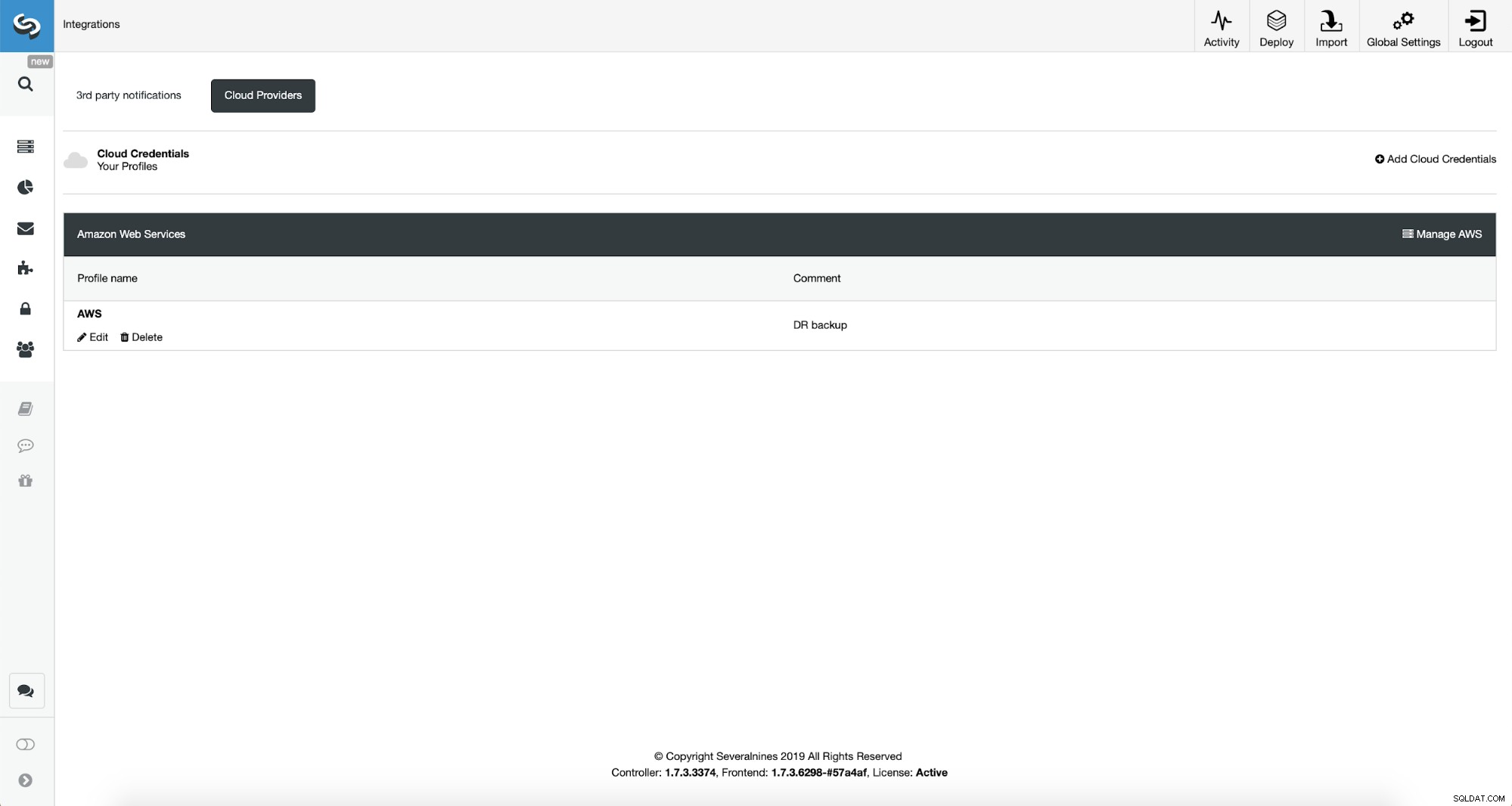
Uma vez feito isso, podemos ver as credenciais que acabamos de adicionar listadas em ClusterControl.
Agora, prosseguiremos com a configuração do agendamento de backup.
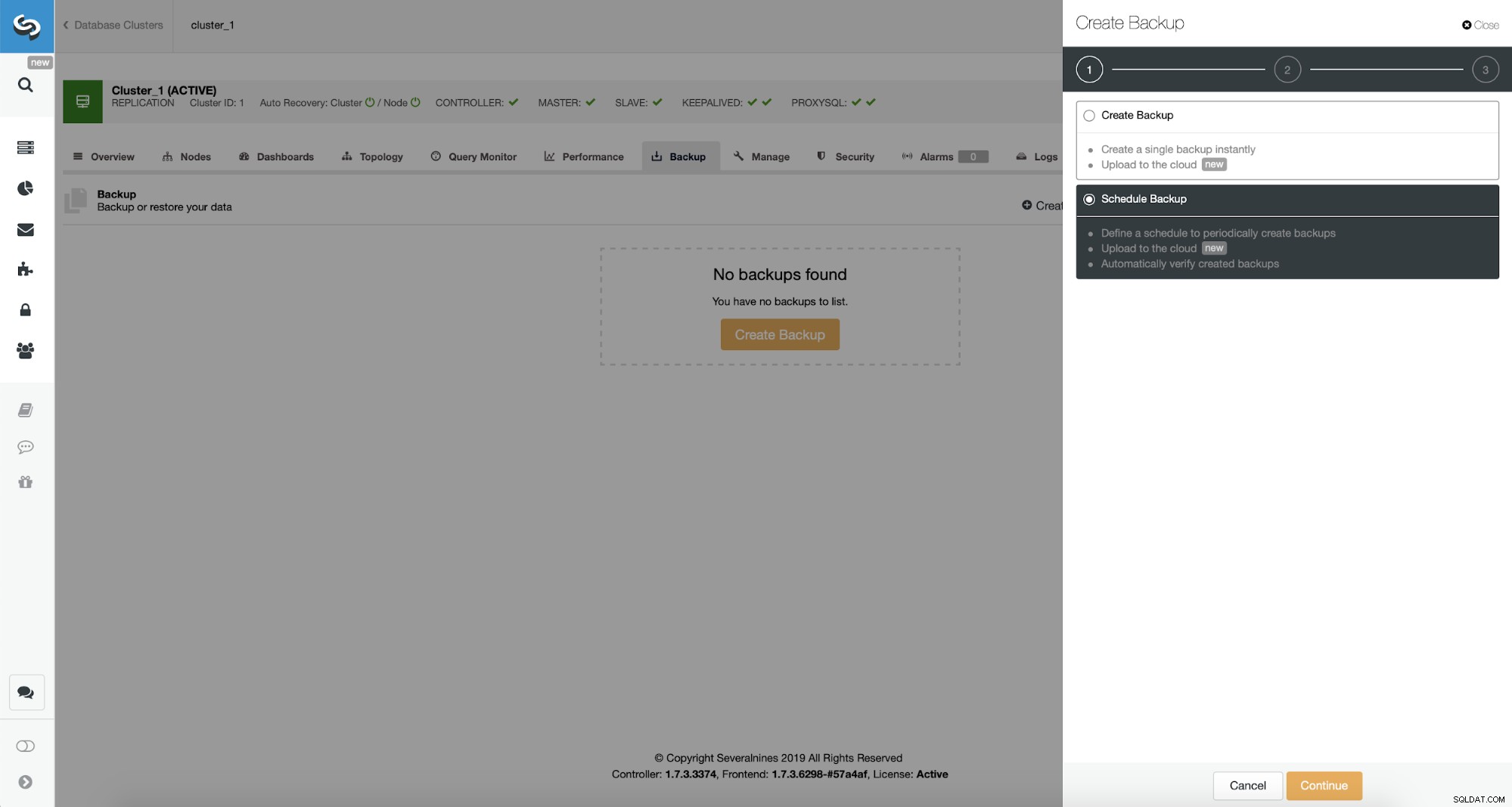
ClusterControl permite que você crie backup imediatamente ou agende-o. Vamos com a segunda opção. O que queremos é criar um cronograma a seguir:
- Backup completo criado uma vez por dia
- Backups incrementais criados a cada 10 minutos.
A ideia aqui é como segue. Na pior das hipóteses, perderemos apenas 10 minutos do tráfego. Se o datacenter ficar indisponível de fora, mas funcionar internamente, podemos tentar evitar qualquer perda de dados aguardando 10 minutos, copiando o backup incremental mais recente em algum laptop e, em seguida, podemos enviá-lo manualmente para nosso banco de dados de DR usando até mesmo tethering de telefone e uma conexão celular para contornar a falha do ISP. Se não conseguirmos obter os dados do datacenter antigo por algum tempo, isso visa minimizar a quantidade de transações que teremos que mesclar manualmente no banco de dados de DR.
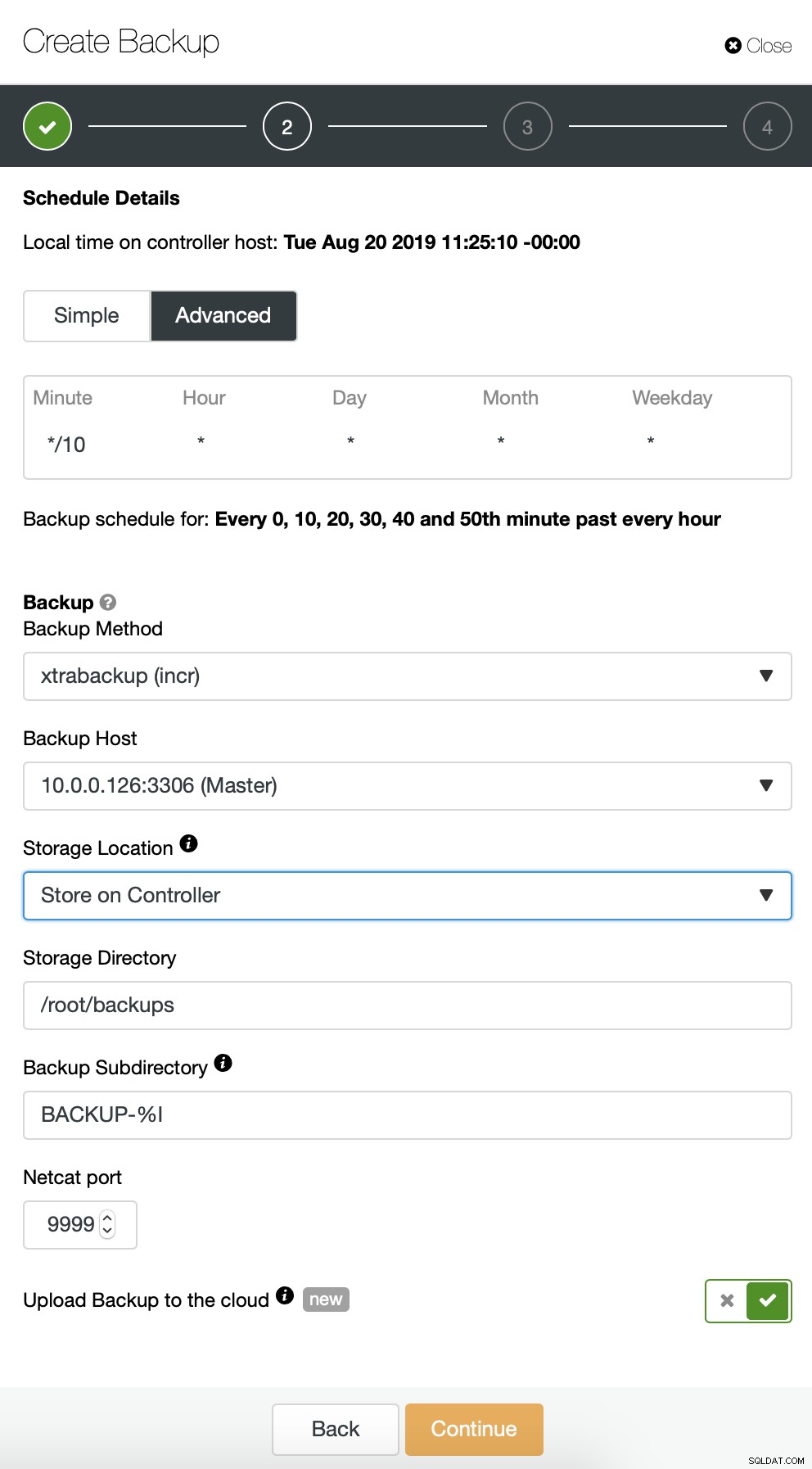
Começamos com o backup completo que acontecerá diariamente às 2h. Usaremos o master para fazer o backup, vamos armazená-lo no controlador no diretório /root/backups/. Também habilitaremos a opção “Fazer upload de backup para a nuvem”.
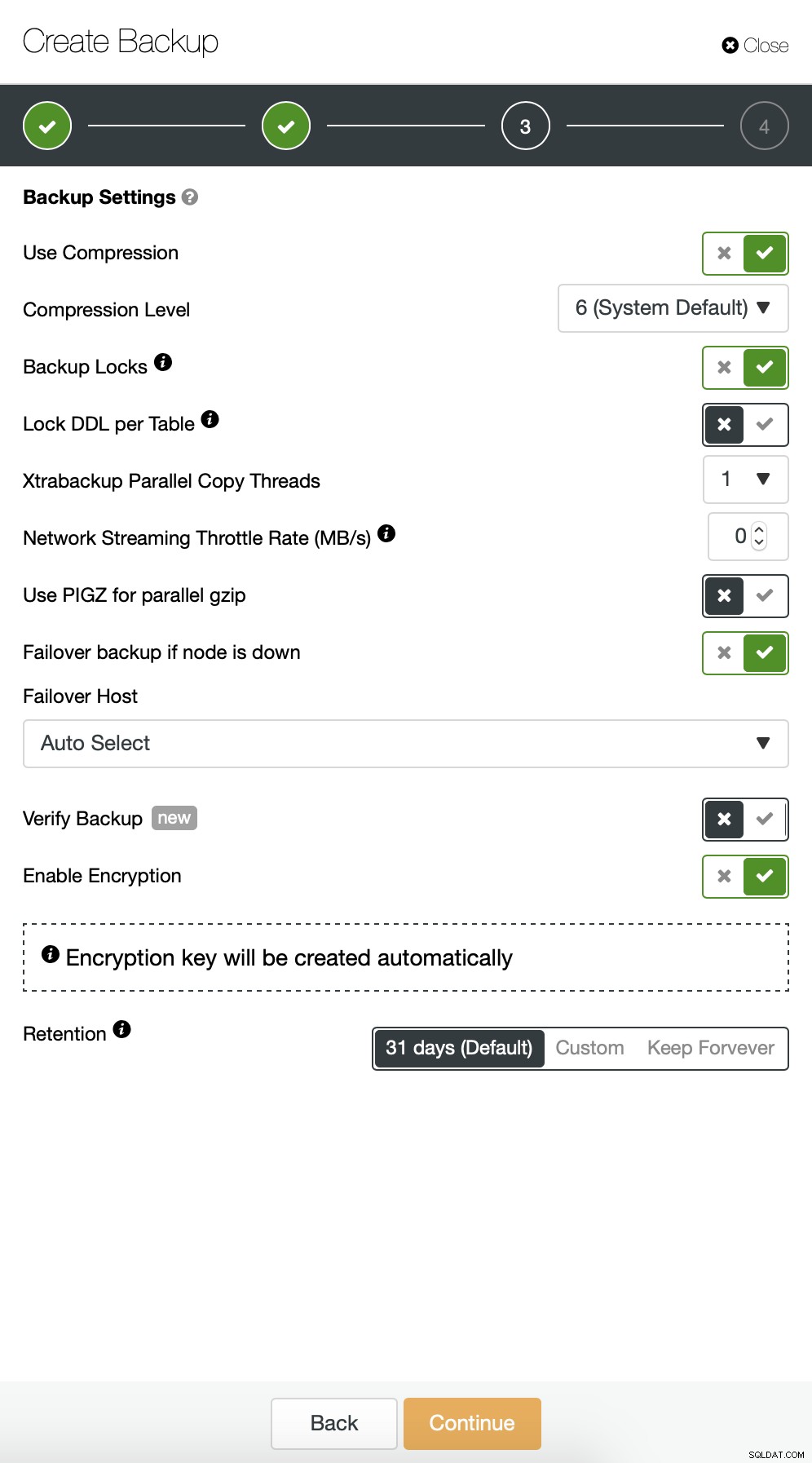
A seguir, queremos fazer algumas alterações na configuração padrão. Decidimos usar o host de failover selecionado automaticamente (caso nosso mestre não esteja disponível, o ClusterControl usará qualquer outro nó disponível). Também queríamos habilitar a criptografia, pois enviaremos nossos backups pela rede.
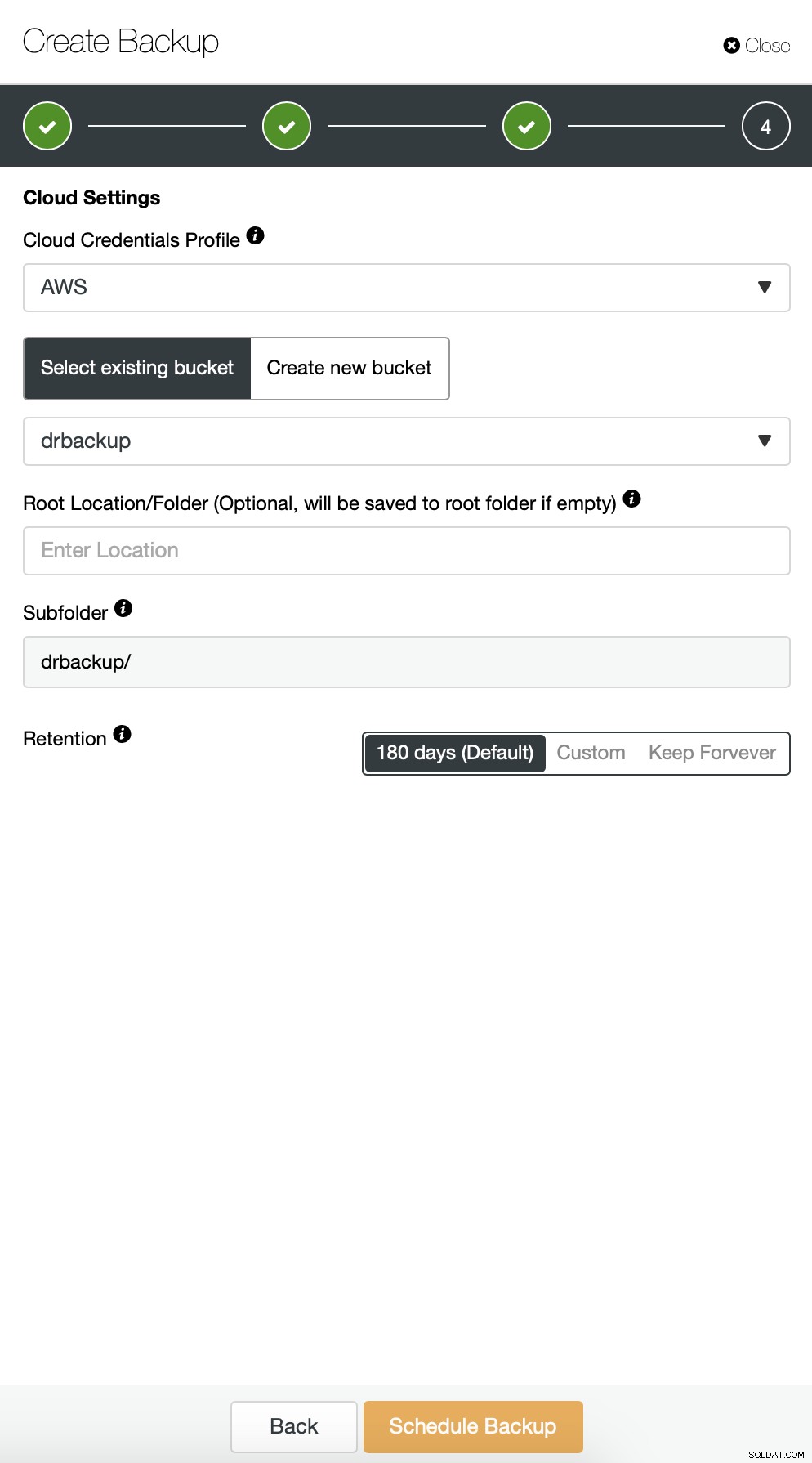
Então temos que escolher as credenciais, selecionar o bucket S3 existente ou criar um novo se necessário.
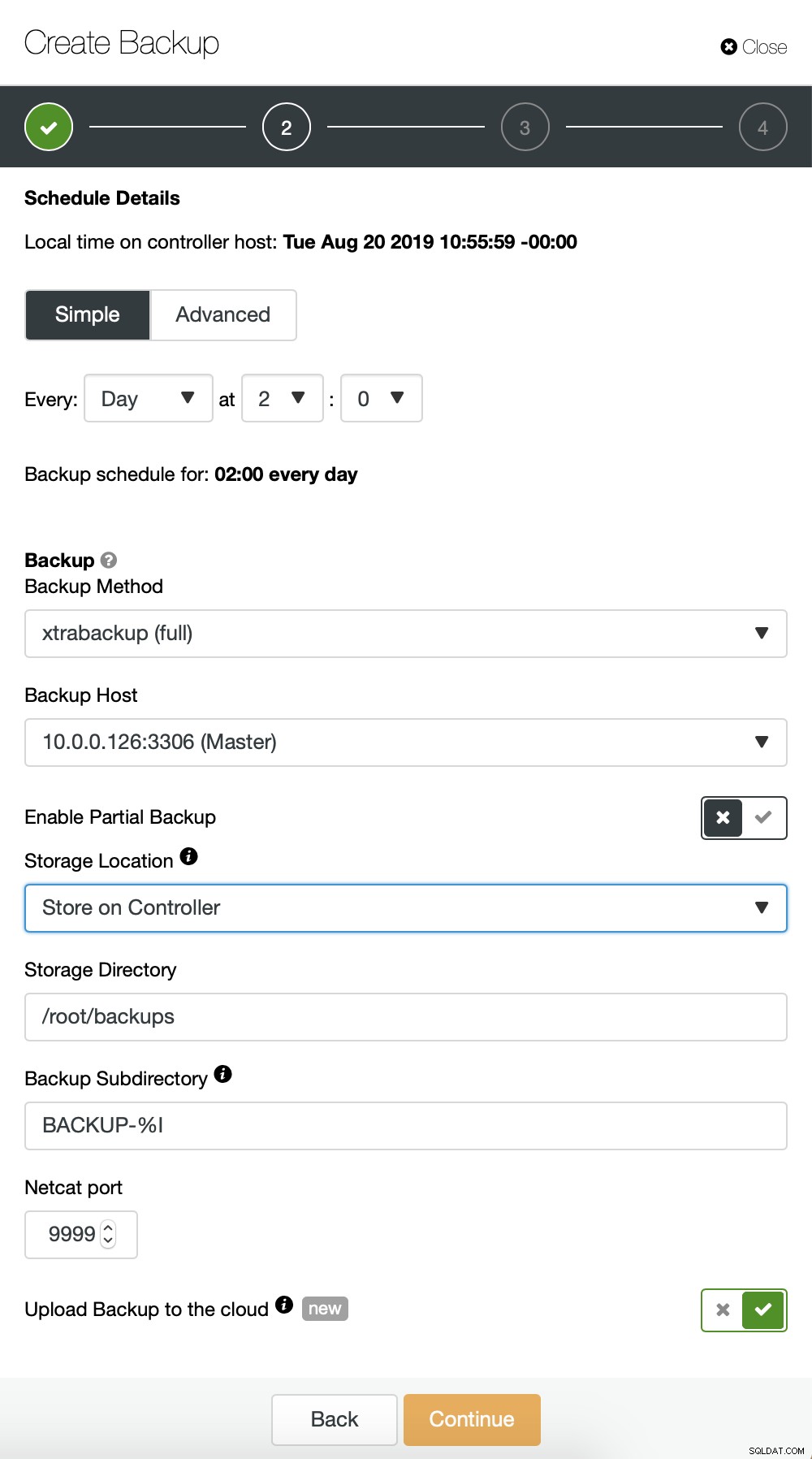
Estamos basicamente repetindo o processo para o backup incremental, desta vez usamos a caixa de diálogo "Avançado" para executar os backups a cada 10 minutos.
O restante das configurações é semelhante, também podemos reutilizar o bucket do S3.
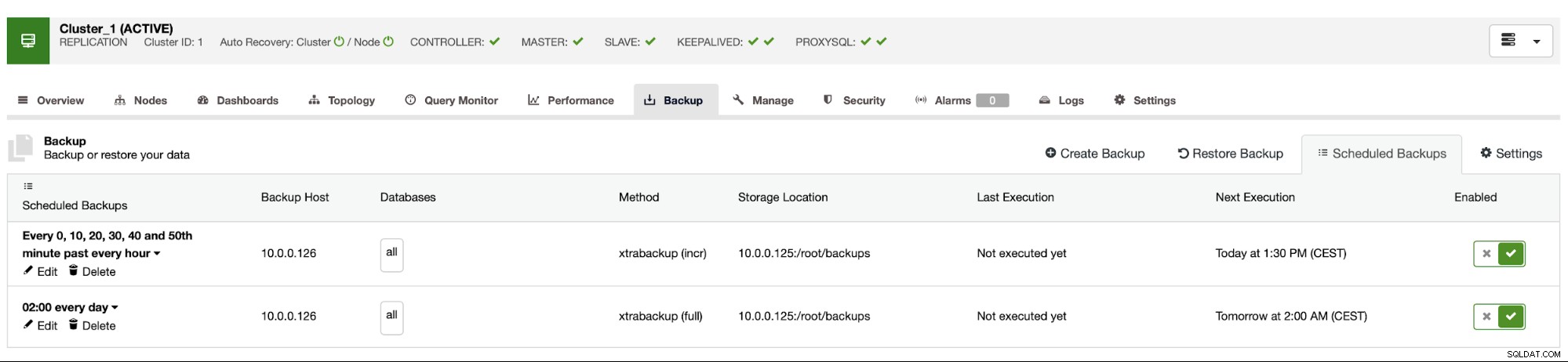
A programação de backup se parece com a acima. Não precisamos iniciar o backup completo manualmente, o ClusterControl executará o backup incremental conforme programado e, se detectar que não há backup completo disponível, ele executará um backup completo em vez do incremental.
Com essa configuração, podemos afirmar com segurança que podemos recuperar os dados em qualquer sistema externo com granularidade de 10 minutos.
Restauração de backup manual
Se acontecer de você precisar restaurar o backup na instância de recuperação de desastres, há algumas etapas a serem seguidas. É altamente recomendável testar esse processo de tempos em tempos, garantindo que ele funcione corretamente e você seja proficiente em executá-lo.
Primeiro, temos que instalar a ferramenta de linha de comando da AWS em nosso servidor de destino:
example@sqldat.com:~# apt install python3-pip
example@sqldat.com:~# pip3 install awscli --upgrade --userDepois temos que configurá-lo com as credenciais adequadas:
example@sqldat.com:~# ~/.local/bin/aws configure
AWS Access Key ID [None]: yourkeyID
AWS Secret Access Key [None]: yourkeySecret
Default region name [None]: us-west-1
Default output format [None]: jsonAgora podemos testar se temos acesso aos dados em nosso bucket do S3:
example@sqldat.com:~# ~/.local/bin/aws s3 ls s3://drbackup/
PRE BACKUP-1/
PRE BACKUP-2/
PRE BACKUP-3/
PRE BACKUP-4/
PRE BACKUP-5/
PRE BACKUP-6/
PRE BACKUP-7/Agora, temos que baixar os dados. Criaremos um diretório para os backups - lembre-se, temos que baixar todo o conjunto de backups - começando de um backup completo até o último incremental que desejamos aplicar.
example@sqldat.com:~# mkdir backups
example@sqldat.com:~# cd backups/Agora existem duas opções. Podemos baixar backups um por um:
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-1/ BACKUP-1 --recursive
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
Completed 30.4 MiB/36.2 MiB (4.9 MiB/s) with 1 file(s) remaining
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-2/ BACKUP-2 --recursive
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256Também podemos, especialmente se você tiver um cronograma de rotação apertado, sincronizar todo o conteúdo do bucket com o que temos localmente no servidor:
example@sqldat.com:~/backups# ~/.local/bin/aws s3 sync s3://drbackup/ .
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-4/cmon_backup.metadata to BACKUP-4/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/cmon_backup.metadata to BACKUP-3/cmon_backup.metadata
download: s3://drbackup/BACKUP-6/cmon_backup.metadata to BACKUP-6/cmon_backup.metadata
download: s3://drbackup/BACKUP-5/cmon_backup.metadata to BACKUP-5/cmon_backup.metadata
download: s3://drbackup/BACKUP-7/cmon_backup.metadata to BACKUP-7/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 to BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256
download: s3://drbackup/BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256 to BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256 to BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256 to BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256 to BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256Como você se lembra, os backups são criptografados. Temos que ter uma chave de criptografia que é armazenada no ClusterControl. Certifique-se de ter sua cópia armazenada em algum lugar seguro, fora do datacenter principal. Se você não conseguir alcançá-lo, não poderá descriptografar os backups. A chave pode ser encontrada na configuração do ClusterControl:
example@sqldat.com:~# grep backup_encryption_key /etc/cmon.d/cmon_1.cnf
backup_encryption_key='aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM='Ele é codificado usando base64, portanto, temos que decodificá-lo primeiro e armazená-lo no arquivo antes de podermos começar a descriptografar o backup:
echo "aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM=" | openssl enc -base64 -d> pass
Agora podemos reutilizar este arquivo para descriptografar backups. Por enquanto, digamos que faremos um backup completo e dois incrementais.
mkdir 1
mkdir 2
mkdir 3
cat BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/1/
cat BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/2/
cat BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/3/Temos os dados descriptografados, agora temos que prosseguir com a configuração do nosso servidor MySQL. Idealmente, esta deve ser exatamente a mesma versão dos sistemas de produção. Usaremos o Percona Server para MySQL:
cd ~
wget https://repo.percona.com/apt/percona-release_latest.generic_all.deb
sudo dpkg -i percona-release_latest.generic_all.deb
apt-get update
apt-get install percona-server-5.7Nada complexo, apenas instalação normal. Quando estiver pronto e pronto, temos que pará-lo e remover o conteúdo de seu diretório de dados.
service mysql stop
rm -rf /var/lib/mysql/*Para restaurar o backup, precisaremos do Xtrabackup - uma ferramenta que CC usa para criá-lo (pelo menos para Perona e Oracle MySQL, MariaDB usa MariaBackup). É importante que esta ferramenta seja instalada na mesma versão dos servidores de produção:
apt install percona-xtrabackup-24Isso é tudo que temos que preparar. Agora podemos começar a restaurar o backup. Com backups incrementais, é importante ter em mente que você deve prepará-los e aplicá-los sobre o backup básico. O backup da base também deve ser preparado. É crucial executar a opção prepare com '--apply-log-only' para evitar que o xtrabackup execute a fase de reversão. Caso contrário, você não poderá aplicar o próximo backup incremental.
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/ --incremental-dir=/root/backups/2/
xtrabackup --prepare --target-dir=/root/backups/1/ --incremental-dir=/root/backups/3/No último comando, permitimos que o xtrabackup execute a reversão de transações não concluídas - não aplicaremos mais backups incrementais posteriormente. Agora é hora de preencher o diretório de dados com o backup, iniciar o MySQL e ver se tudo funciona conforme o esperado:
example@sqldat.com:~/backups# mv /root/backups/1/* /var/lib/mysql/
example@sqldat.com:~/backups# chown -R mysql.mysql /var/lib/mysql
example@sqldat.com:~/backups# service mysql start
example@sqldat.com:~/backups# mysql -ppass
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 6
Server version: 5.7.26-29 Percona Server (GPL), Release '29', Revision '11ad961'
Copyright (c) 2009-2019 Percona LLC and/or its affiliates
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show schemas;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| proxydemo |
| sbtest |
| sys |
+--------------------+
6 rows in set (0.00 sec)
mysql> select count(*) from sbtest.sbtest1;
+----------+
| count(*) |
+----------+
| 10506 |
+----------+
1 row in set (0.01 sec)Como você pode ver, tudo está bem. O MySQL foi iniciado corretamente e pudemos acessá-lo (e os dados estão lá!). Conseguimos com sucesso trazer nosso banco de dados de volta a funcionar em um local separado. O tempo total necessário depende estritamente do tamanho dos dados - tivemos que baixar os dados do S3, descriptografá-los e descompactá-los e, finalmente, preparar o backup. Ainda assim, essa é uma opção muito barata (você precisa pagar apenas pelos dados do S3) que oferece uma opção de continuidade de negócios caso ocorra um desastre.